neo4j vs python
1.将库中已经存在的两个节点,创建关系。
查询库中只有2个独立的节点。
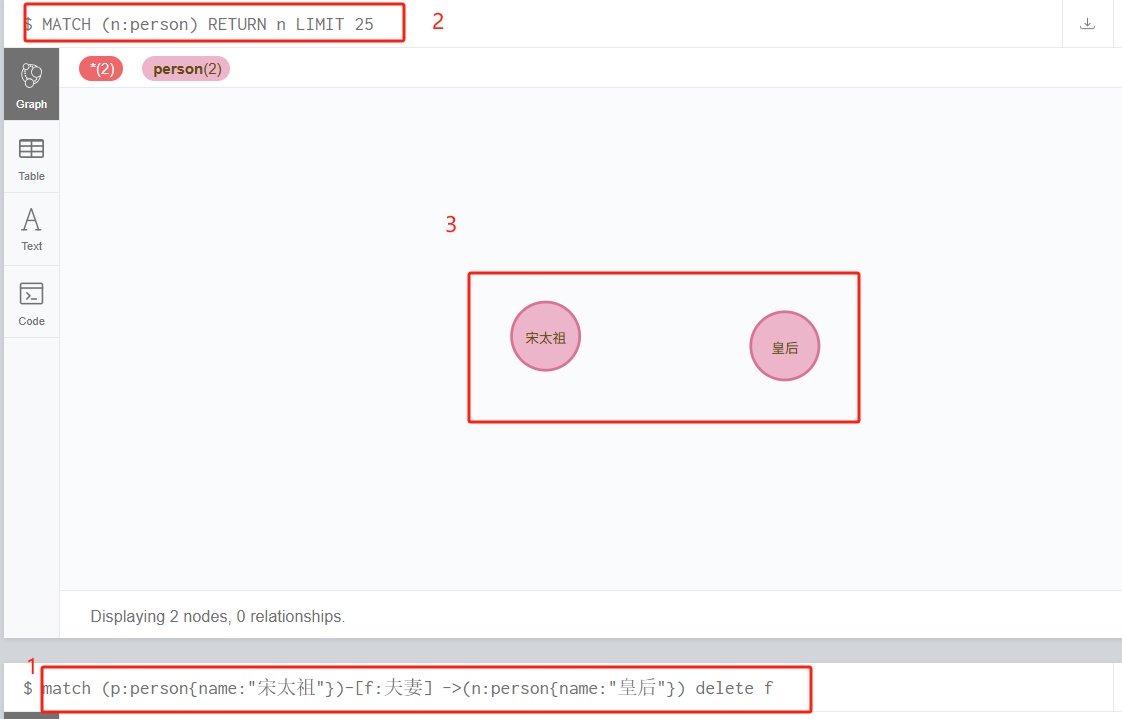
方式一,python,使用py2neo库
#coding:utf-8
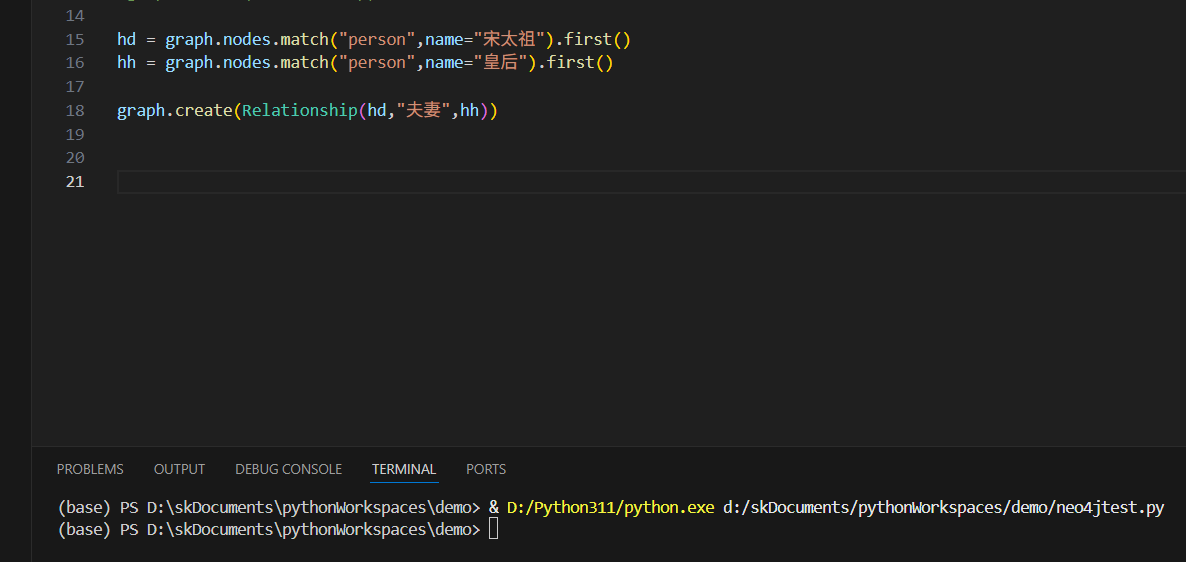
from py2neo import Graph,Node,Relationship,NodeMatcher##连接neo4j数据库,输入地址、用户名、密码
graph = Graph('bolt://xx.xx.xx.xx:7687',auth=("neo4j","neo4j1234"))hd = graph.nodes.match("person",name="宋太祖").first()
hh = graph.nodes.match("person",name="皇后").first()graph.create(Relationship(hd,"夫妻",hh))执行成功
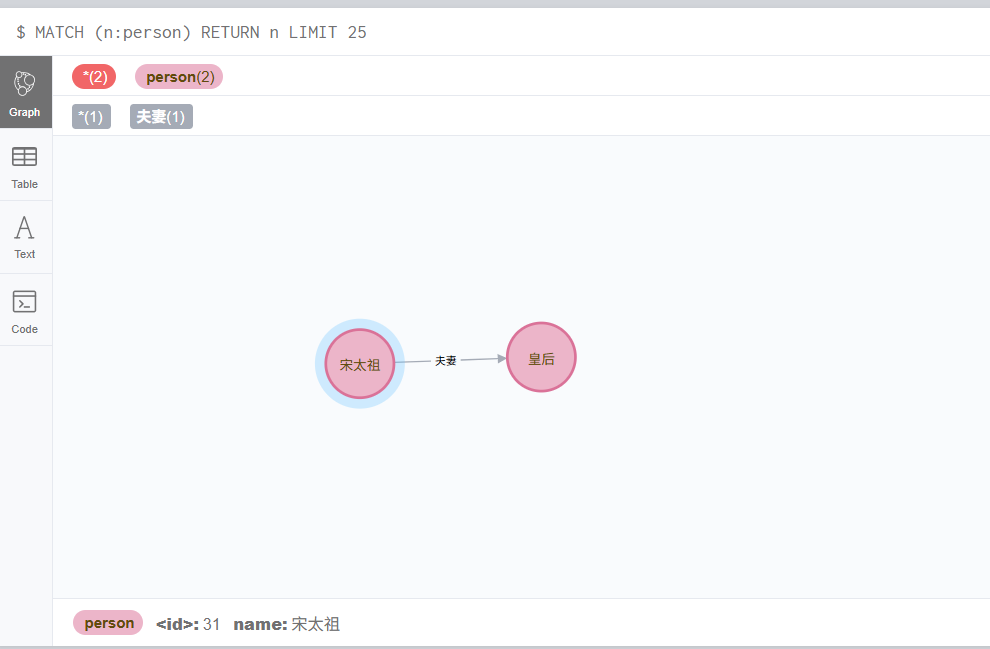
查看库
方式二:使用neo4j, 原生cypher语句
#coding:utf-8
from neo4j import GraphDatabase##获取已经存在的节点,创建关系
driver = GraphDatabase.driver('bolt://xx.xx.xx.xx:7687',auth=("neo4j","neo4j1234"))with driver.session() as session:hd = session.run("MATCH (a:person {name:'宋太祖'}) return a").single().get("a")hh = session.run("MATCH (b:person {name:'皇后'}) RETURN b").single().get("b")session.run("Match (a:person), (b:person) where a.name='皇后' and b.name='宋太祖' create (a) - [:老婆] -> (b)")
driver.close()
查看库
看着上面的脚本就奇怪,那获取节点干嘛呢,信息存入了变量里,后面又没用到这个变量。
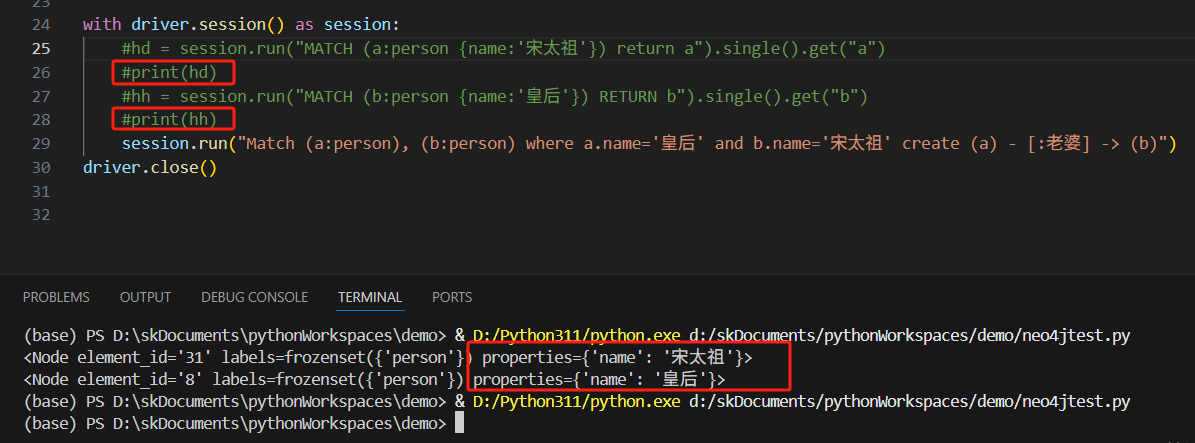
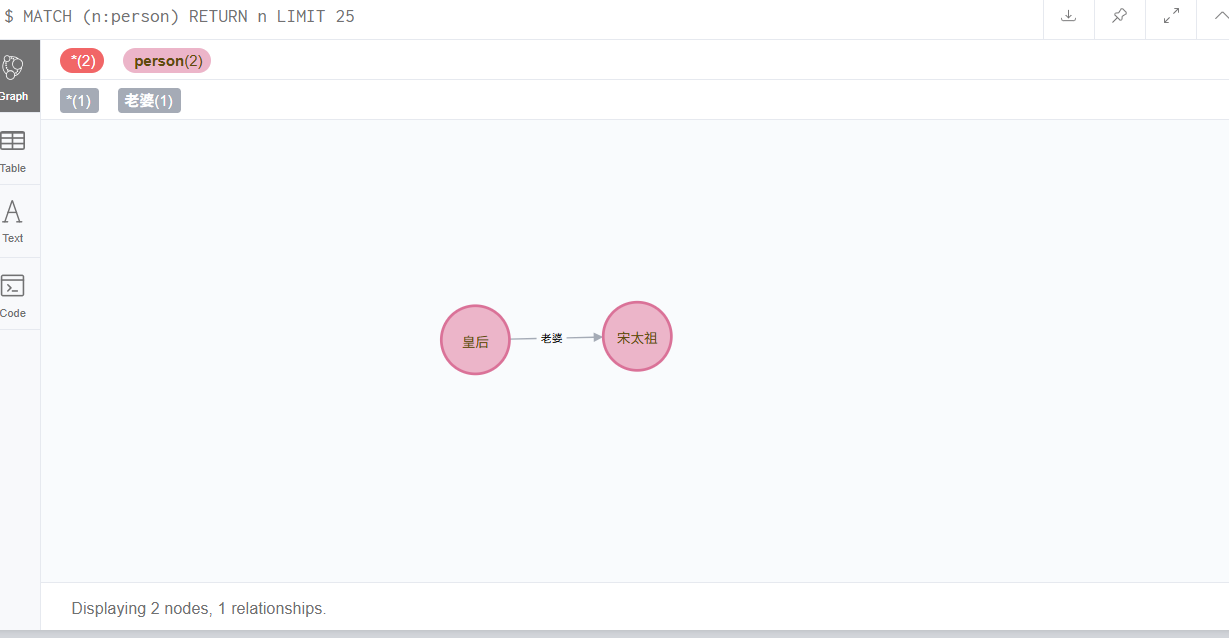
直接用最后面的cypher语句,不就能执行了嘛。执行一次,没报错,查看库
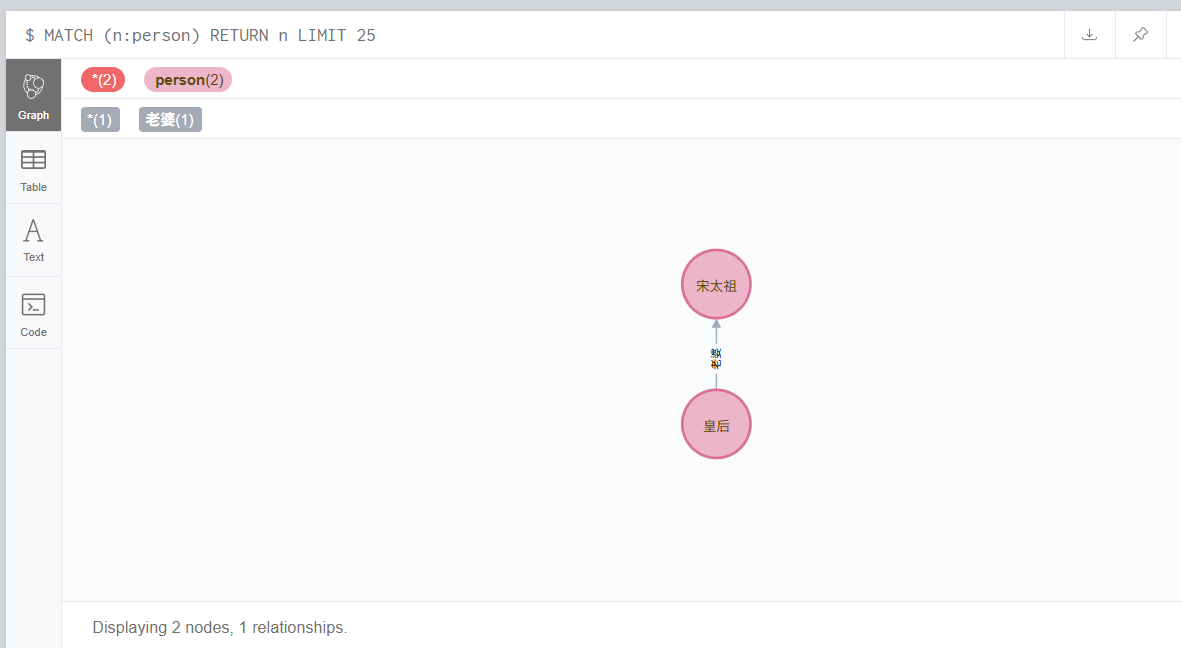
果然不需要那两句,直接match查询就可以。
总结
通过这两个方式也看出来了,还是用封装好的方法操作便捷,出错的概率也小。