Seaborn一个用于统计图形绘制的高级API
对于数据的可视化,并不存在一种普遍适用的最佳方式。
不同的问题最适合通过不同的图表来解答。
Seaborn 通过使用一个一致的数据集导向 API,使得在不同可视化表示之间进行切换变得容易。
relplot() 函数之所以被命名为这样,是因为它旨在呈现多种不同的统计关系。虽然散点图通常很有效,但当一个变量代表时间的度量时,用线条来表示这种关系会更好。relplot() 函数有一个方便的kind参数,让您能够轻松切换到这种替代表示形式。
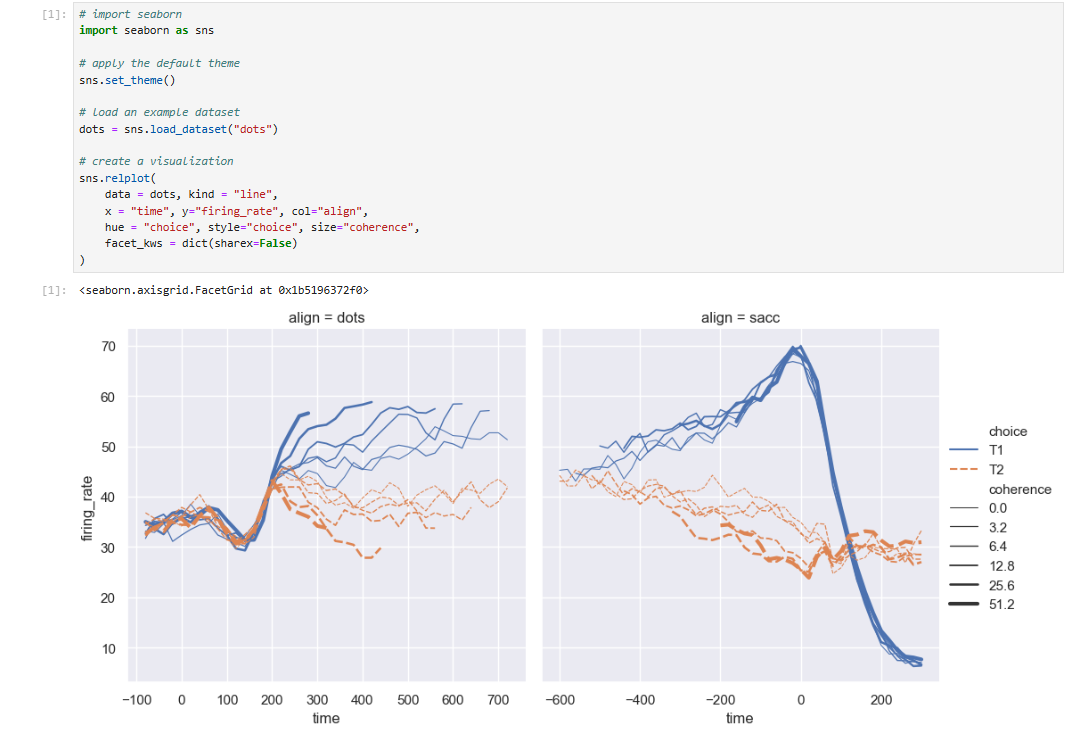
请注意,在散点图和折线图中,size 和 style 参数是如何被使用的,但它们对这两种可视化效果的影响是不同的:在散点图中是改变标记区域和符号,在折线图中则是改变线条宽度和虚线样式。
我们无需记住这些细节,这样我们就能专注于图表的整体结构以及我们希望它传达的信息。
统计估计
通常,我们会关注一个变量的平均值如何随其他变量的变化而变化。许多 seaborn 函数会自动执行必要的统计推断,以回答这些问题。
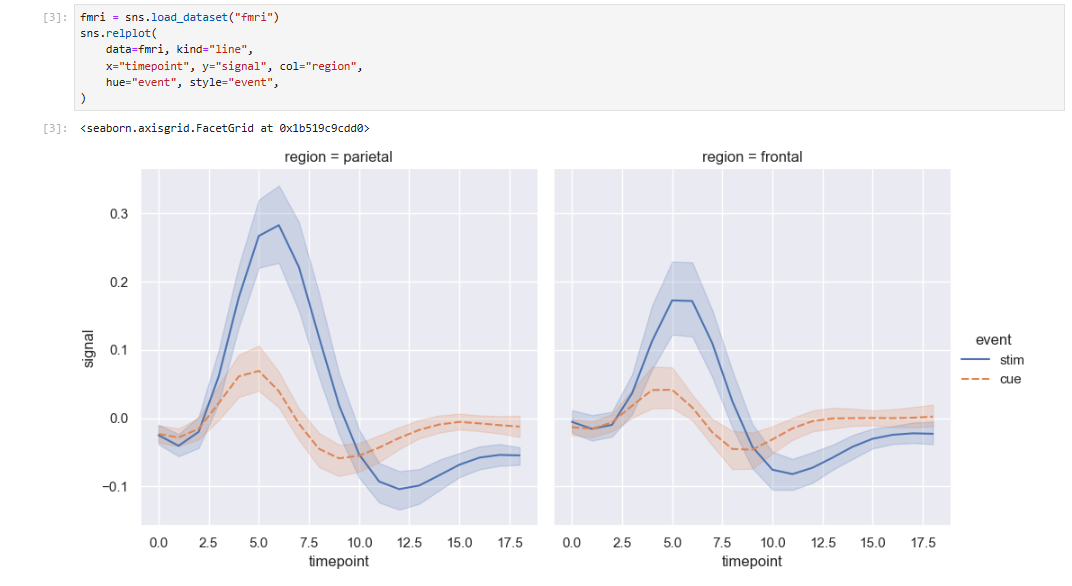
在进行统计值估算时,seaborn 会使用自助抽样法来计算置信区间,并绘制误差条来表示估算结果的不确定性。
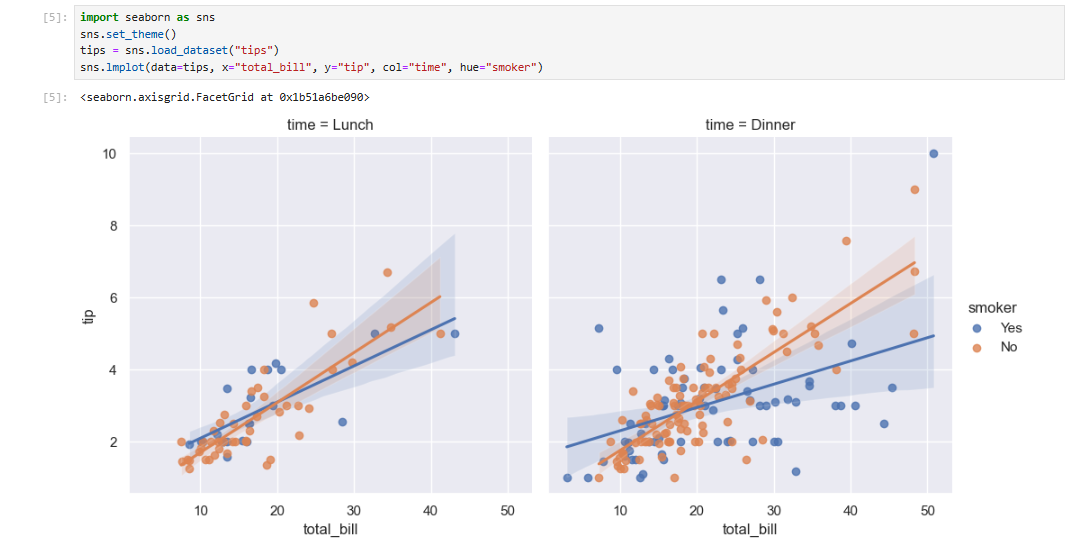
在 seaborn 中进行的统计估计超越了描述性统计范畴。例如,可以借助 lmplot() 函数在散点图中加入线性回归模型(及其不确定性)从而对其进行优化。
分布式表示形式
统计分析需要了解您数据集中的变量分布情况。seaborn 函数 displot() 支持多种可视化分布情况的方法。其中包括诸如直方图之类的经典技术,以及诸如核密度估计之类的计算密集型方法。
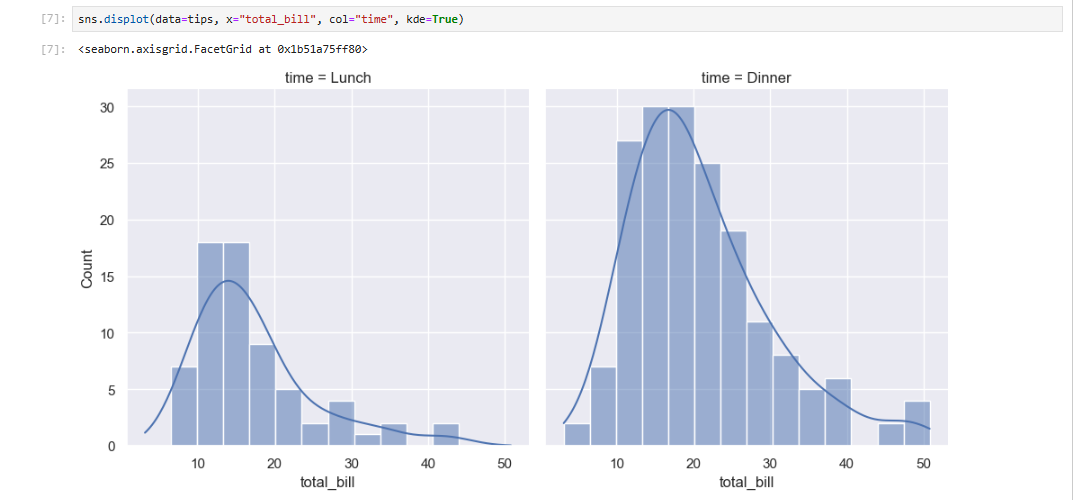
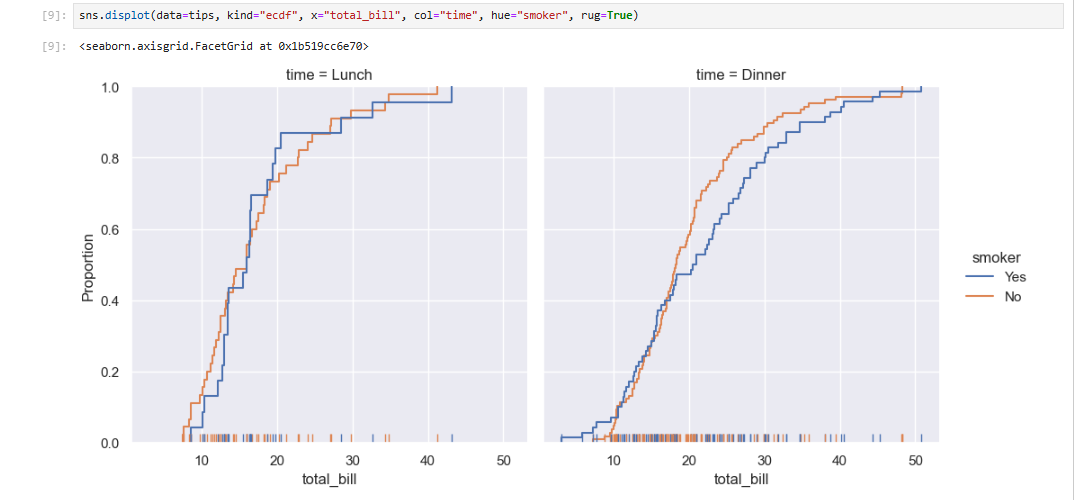
Seaborn 还试图推广一些功能强大但相对不为人熟知的技术,比如计算并绘制数据的经验累积分布函数。
分类数据的图表绘制
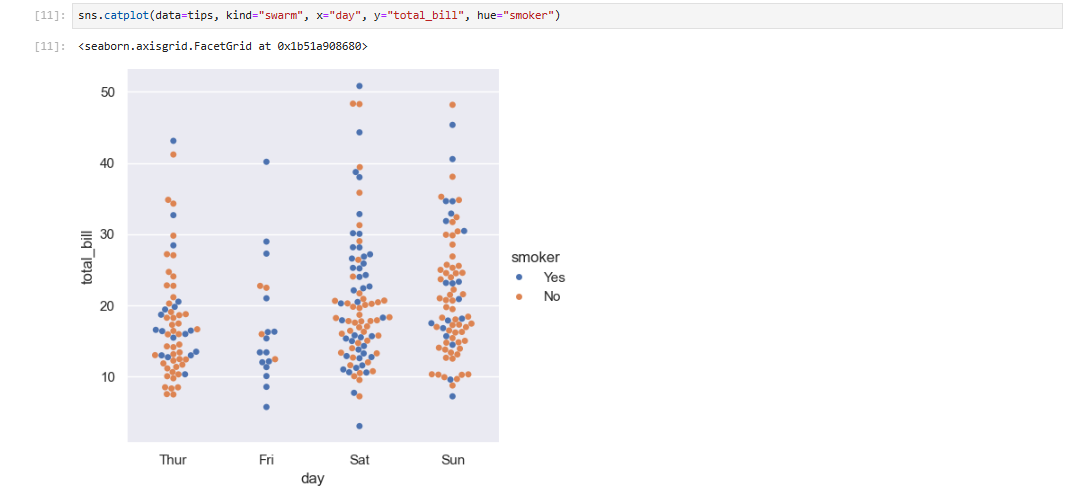
seaborn 中有几种专门的绘图类型旨在用于可视化分类数据。它们可以通过 catplot() 函数获取。这些绘图提供了不同程度的细节程度。在最精细的级别,您可能希望通过绘制“蜂巢”图来查看每一个观测值:这是一种散点图,它会调整分类轴上点的位置,以使它们不会重叠。
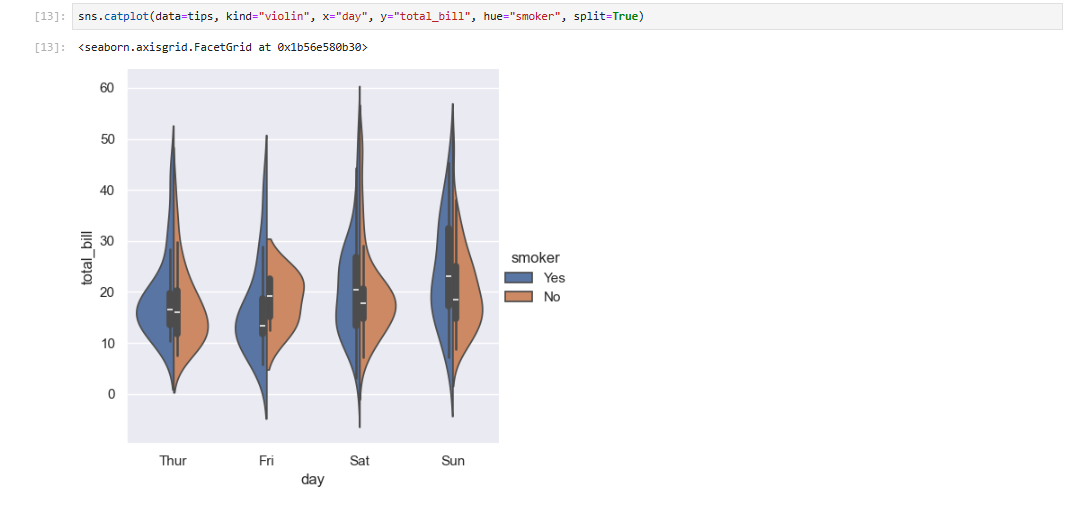
或者,您可以使用核密度估计来表示这些点所采样的原始分布情况
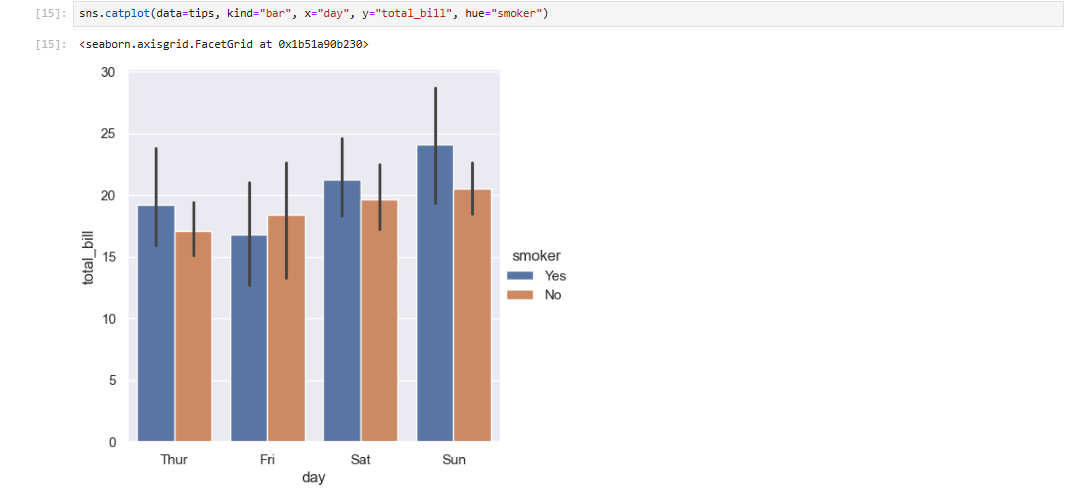
或者您也可以仅展示每个嵌套类别中的平均值及其置信区间