基于F5TTS的零样本语音合成
高效的文本转语音项目需要依赖稳定的环境和强大的模型支持。硬件和依赖配置到位,能够为语音生成任务带来流畅体验和更高质量输出。
本文以F5TTS为核心,从环境搭建、模型获取到各类API接口的调用流程进行梳理,覆盖多风格合成、语音对话和文本管理等常见场景,适用于自主学习和项目集成需求。
文章目录
- 项目准备
- 项目应用&拓展
- 总结
项目准备
使用 Anaconda 可以快速创建和管理 Python 环境,尤其适合初学者。配合 GPU 版本的 PyTorch,可充分利用显卡加速,显著提升深度学习任务的执行效率。
在使用 F5TTS 项目时,确保完成环境配置、下载源码和预训练模型,是项目顺利运行的关键。
| 需求 | 说明 |
|---|---|
| 配置要求 | 显存16G以上,显卡起步2080TI(N卡) |
| 环境安装 | Python初学者在不同系统上安装Python的保姆级指引 |
| Win10+Python3.9+GPU版Pytorch环境搭建最简流程 | |
| 项目源码 | F5TTS |
| 整合包使用 | AIGC工具平台-F5TTS零样本语音合成 |
模型下载
SWivid 的 F5-TTS 和 Qwen 推出的 Qwen2.5-3B-Instruct 是两个在语音生成与语言理解领域表现突出的开源模型。F5-TTS 聚焦于文本转语音技术,生成的语音自然、清晰,适合语音助手、智能客服、内容朗读等多种场景。相比之下,Qwen2.5-3B-Instruct 是一款结构紧凑但功能强大的指令微调语言模型,专为多轮对话、指令理解、语言生成等任务而优化,能以高效的参数规模提供出色的理解与生成能力。这两款模型都已开放下载,便于开发者集成到各类智能应用中。
| 模型名称 | 说明 | 下载地址 |
|---|---|---|
| models–SWivid–F5-TTS | 由 SWivid 开发的高质量文本转语音模型,语音自然流畅,适用于语音交互和内容创作等场景。 | https://huggingface.co/models/SWivid/F5-TTS |
| models–Qwen–Qwen2.5-3B-Instruct | Qwen 发布的指令微调语言模型,结构精简,适合对话、指令执行和语言理解任务,兼顾性能与效率。 | https://huggingface.co/models/Qwen/Qwen2.5-3B-Instruct |
启动webui会下载模型,或者复制到文件到自己的指定目录。

虚拟环境
在本项目中可以使用 Conda 来创建和管理虚拟环境。在项目的根目录中,通过 Conda 创建一个新的虚拟环境,假设环境名称为 venv,并使用 Python 3.10 版本。
conda create --name venv python=3.10
创建好环境后,通过以下命令激活虚拟环境。命令行前会显示虚拟环境名称 venv,表示当前环境已激活。
conda activate venv
在激活的虚拟环境中,按照项目提供的 requirements.txt 文件安装所需的 Python 包。
pip install -r requirements.txt
也可以执行整合包里的 install_toml.bat 进行安装,最后还要补充一个 torch 的 CUDA 版本。如果不使用GPU推理可以跳过。
pip install torch==2.1.1+cu118 torchaudio==2.1.1+cu118 --index-url https://download.pytorch.org/whl/cu118
项目应用&拓展
在虚拟环境中启动 WebUI 服务,或者在项目下执行 WebUI.bat 先进入虚拟环境在启动服务。
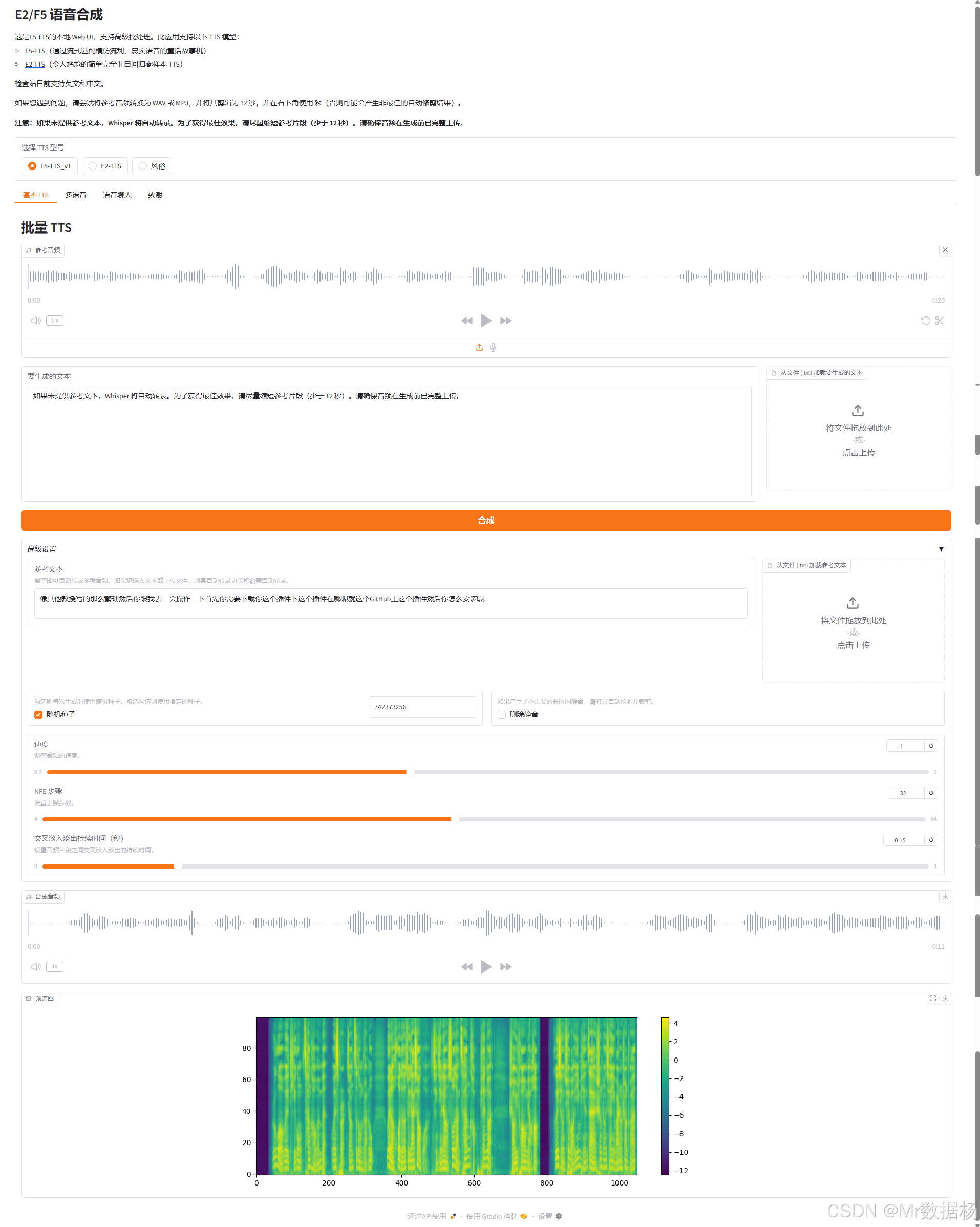
基于Gradio框架,实现了文本到语音(TTS)、多风格语音合成、AI语音对话等多项功能。用户可通过上传参考音频与文本,自由选择TTS模型,生成高质量普通或多角色语音。系统还支持情感/角色风格标签自动识别与批量生成,内嵌大模型对话接口,实现语音问答,适合播客、配音、智能助手等多种场景。所有功能均以API形式对外开放,便于集成自动化脚本和业务系统。
| 功能模块 | 主要用途 | 典型API请求入口 | 输入核心参数 | 输出主要内容 |
|---|---|---|---|---|
| 基础语音合成 Basic TTS | 按输入文本和参考音频合成高质量语音,支持参数控制 | /run/predict | 参考音频、参考文本、生成文本、模型、去静音、种子、速度等 | 语音数据、频谱图、参考文本、使用种子 |
| 多风格语音合成 Multi-TTS | 支持多角色/情感标签脚本、每种风格自定义参考音,批量生成语音 | /run/predict | 脚本文本、100组参考音频/风格、参考文本、去静音 | 拼接音频、风格参考文本、风格元信息 |
| 对话语音合成 Voice Chat | 用AI与用户语音对话,AI回复继承参考音色,多轮会话 | /run/predict | 聊天记录、参考音频、参考文本、去静音、随机种子、模型选择 | AI语音回复、参考文本、实际种子值 |
| 聊天大模型加载 ChatModel | 动态加载Qwen等对话大模型,为语音对话/配音等提供AI生成能力 | /run/predict | 模型名称 | 模型加载进度与结果提示 |
| 文本文件上传/加载 | 直接上传txt批量录入文本,便于长文本脚本和参考文本管理 | /run/predict | txt文件路径 | 文本内容字符串 |
基础语音合成(Basic TTS)
本模块用于根据输入的参考音频、参考文本与要生成的文本,合成高质量语音。支持模型切换、音频速度控制、去除静音、种子控制等高级参数。
基于API模式请求的样例(Python):
import requestsurl = "http://localhost:7860/run/predict"
payload = {"fn_index": 1, # 不同部署或gradio导出,索引会变化,请以实际API文档为准"data": ["/path/to/ref_audio.wav", # 参考音频文件路径"参考文本", # 可选,留空则自动转录"要生成的文本", # 要合成的文本False, # 是否去除静音True, # 是否随机种子0, # 种子,0为随机0.15, # 淡入淡出时长(秒)32, # NFE 步数1.0 # 语速]
}
response = requests.post(url, json=payload)
audio_data, spectrogram_path, ref_text_out, used_seed = response.json()["data"]
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| ref_audio_orig | str | 无 | 参考音频文件路径 |
| ref_text | str | “” | 参考文本,留空自动转录 |
| gen_text | str | 无 | 要生成的文本 |
| model | str | “F5-TTS_v1” | 使用的TTS模型名 |
| remove_silence | bool | False | 是否自动去除生成音频的静音 |
| seed | int | 0 | 随机种子,0为随机 |
| cross_fade_duration | float | 0.15 | 音频片段淡入淡出时长(秒) |
| nfe_step | int | 32 | 去噪步数,影响生成质量和速度 |
| speed | float | 1.0 | 语音生成速度 |
| show_info | callable | gr.Info | 消息显示回调,可默认 |
返回内容生成的音频数据(采样率与音频数组),生成的频谱图文件路径,参考文本内容(如果自动转录则为自动结果),使用的种子。
多风格语音合成(Multi-Speech-Type TTS)
用于批量生成多种风格/说话人/情感的语音。支持每种风格指定参考音频、文本和参数,输入文本可按块指定不同说话人或情感。
基于API模式请求的样例(Python):
import requestsurl = "http://localhost:7860/run/predict"
payload = {"fn_index": 2, # 多风格接口的索引需以部署实际为准"data": [# gen_text'{"name": "Speaker1_Happy", "seed": -1, "speed": 1} Hello!"\n{"name": "Speaker2_Sad", "seed": -1, "speed": 1} Sorry..."',# speech_type_names(长度固定100)["Regular", "Speaker1_Happy", "Speaker2_Sad", ...],# speech_type_audios(长度固定100)["/path/regular.wav", "/path/speaker1.wav", "/path/speaker2.wav", ...],# speech_type_ref_texts(长度固定100)["", "", "", ...],# remove_silenceTrue]
}
response = requests.post(url, json=payload)
data = response.json()["data"]
audio_data = data[0] # 合成的拼接音频
ref_texts = data[1:101] # 每种风格最终参考文本
meta_data = data[-1] # 每段风格合成的元信息(包含实际用seed和速度)
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| gen_text | str | 无 | 输入的脚本,需用{name}或JSON指定说话风格 |
| speech_type_names | list[str] | [“Regular”] | 所有说话风格名,最多支持100种 |
| speech_type_audios | list[str] | [None] | 每种说话风格的参考音频文件路径 |
| speech_type_ref_texts | list[str] | [“”] | 每种说话风格的参考文本,留空则自动转录 |
| remove_silence | bool | True | 是否自动去除静音 |
返回内容为拼接后的全部语音数据、每种风格的最终参考文本、每段语音的风格与参数元信息。
对话语音合成(Voice Chat)
允许上传参考音频和文本,与AI进行多轮语音对话。AI使用上传的参考音色回复,支持自定义system prompt和模型选择。
基于API模式请求的样例(Python):
import requestsurl = "http://localhost:7860/run/predict"
payload = {"fn_index": 3, # 以实际导出API索引为准"data": [# chatbot_interface[{"role": "user", "content": "你好"}],# ref_audio_chat"/path/to/ref_audio.wav",# ref_text_chat"你是谁",# remove_silence_chatTrue,# randomize_seed_chatTrue,# seed_input_chat0]
}
response = requests.post(url, json=payload)
audio_out, ref_text_out, used_seed = response.json()["data"]
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| chatbot_interface | list[dict] | [] | 聊天历史,[{role:…, content:…}]格式 |
| ref_audio_chat | str | 无 | 参考音频路径 |
| ref_text_chat | str | “” | 参考文本,留空则自动转录 |
| remove_silence_chat | bool | True | 是否去除静音 |
| randomize_seed_chat | bool | True | 是否使用随机种子 |
| seed_input_chat | int | 0 | 指定种子,0为随机 |
返回内容AI回复的语音数据(采样率和音频数组)、参考文本内容、实际使用的种子值。
聊天大模型加载(Chat Model Load)
用于动态加载支持的对话大模型(如 Qwen、Phi-4-mini 等)。加载后可供语音对话模块调用,支持多模型自由切换。
基于API模式请求的样例(Python):
import requestsurl = "http://localhost:7860/run/predict"
payload = {"fn_index": 4, # 以实际API索引为准"data": ["Qwen/Qwen2.5-3B-Instruct" # 模型名称]
}
response = requests.post(url, json=payload)
# 通常返回按钮和界面控制状态
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| chat_model_name | str | “Qwen/Qwen2.5-3B-Instruct” | 选择加载的chat模型名 |
返回内容模型加载进度、加载结果提示等。加载成功后即可调用语音对话API。
上传与加载文本文件(Text File Upload/Load)
支持将文本文件直接上传,自动读取内容填入对应文本框,实现脚本与参考文本批量录入。
基于API模式请求的样例(Python):
import requestsurl = "http://localhost:7860/run/predict"
payload = {"fn_index": 5, # 具体索引需以实际为准"data": ["/path/to/text_file.txt"]
}
response = requests.post(url, json=payload)
# 返回内容为文本内容字符串
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| file | str | 无 | 上传的txt文件路径 |
返回内容为读取到的全部文本内容字符串。
总结
F5TTS为文本转语音提供了丰富的API接口,支持多风格语音合成、AI语音对话及大模型加载,便于灵活调用与定制。配合Gradio WebUI,快速实现参考音频上传、风格切换与批量生成,适配多种实际应用。
项目框架持续迭代,未来可关注模型能力提升、风格多样化和API兼容性扩展,为个性化语音合成和交互带来更多可能性。