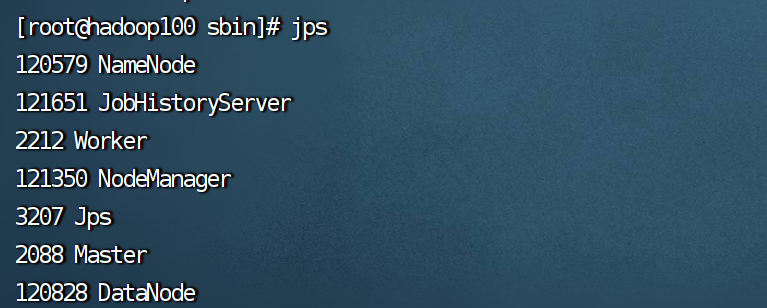
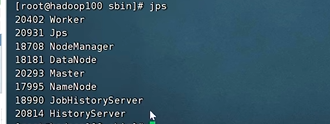
在spark里通过jps命令,看到的进程
在 Spark 和 Hadoop 生态系统中,通过jps命令看到的这些进程分别由不同的组件产生,并且具有各自特定的作用,以下是详细介绍:
- Worker
- 产生命令:通常是在启动 Spark 集群的工作节点时,由./start-all.sh等相关命令启动。

- 作用:负责执行 Spark 作业中的任务。它会向 Master 注册,并根据 Master 的调度接收并处理任务,利用所在节点的资源(如 CPU、内存等)来运行具体的计算任务。
- NodeManager
- 产生命令:由 Hadoop YARN 的myhadoop start等命令启动。
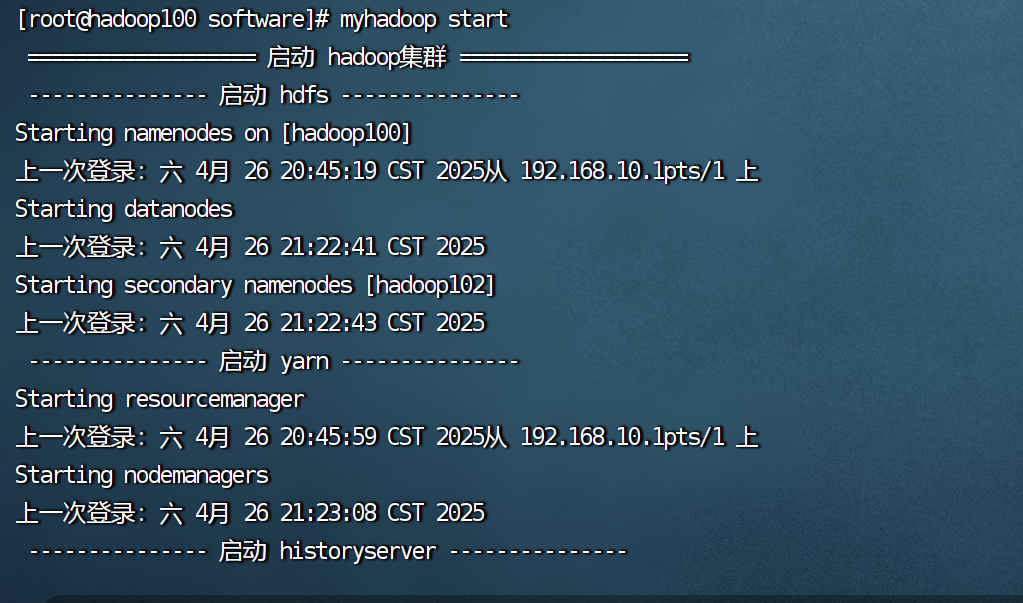
- 作用:是 Hadoop YARN 中的节点代理,负责管理单个节点上的资源和应用程序容器。它监控节点的资源使用情况(如 CPU、内存、磁盘等),并向 ResourceManager 汇报,同时按照 ResourceManager 的指令启动、停止和管理容器,以运行各种应用程序任务。
- DataNode
- 产生命令:通过 Hadoop 的myhadoop start等命令启动。
- 作用:是 Hadoop 分布式文件系统(HDFS)中的数据存储节点。它负责存储 HDFS 中的数据块,并根据客户端或 NameNode 的请求执行数据的读写操作。多个 DataNode 共同组成了 HDFS 的分布式存储系统,提供了数据的冗余存储和高可用性。

- Master
- 产生命令:一般通过 等命令启动。
./start-all.sh
- 作用:是 Spark 集群的主节点,负责管理整个集群的资源和任务调度。它接收来自客户端的作业提交请求,根据集群资源状况和作业的资源需求,将任务分配到各个 Worker 节点上执行,并监控集群中各个节点和任务的运行状态。
- 产生命令:一般通过
- NameNode
- 产生命令:由
myhadoop start
- 作用:是 HDFS 的核心组件,负责管理文件系统的命名空间,维护文件系统树以及文件树中所有的文件和目录的元数据信息,包括文件的权限、副本数量、数据块的位置等。它并不存储实际的数据,而是为客户端提供文件系统的目录结构和数据块映射信息,以便客户端能够正确地访问数据。
- 产生命令:由
- JobHistoryServer
- 产生命令:通过myhadoop start等命令启动。
- 作用:用于记录和查询 Spark 作业的历史信息。它收集并存储 Spark 作业的运行日志、任务执行情况、性能指标等数据,方便用户在作业运行完成后,通过 Web 界面或 API 来查看作业的详细执行过程和性能分析,有助于故障排查和性能优化。
- HistoryServer
- 产生命令:在 Hadoop 生态中,通常由 等命令启动(这里假设 Hadoop 相关环境变量已配置正确)。
./start-history-server.sh

- 作用:主要用于存储和查询 MapReduce 作业的历史记录。与 Spark 的 JobHistoryServer 类似,它收集 MapReduce 作业的运行信息,包括作业的提交时间、执行时间、任务的运行状态、输入输出统计等,以便用户可以查看过去运行的 MapReduce 作业的详细信息,用于分析作业性能、调试问题以及进行容量规划等。
- 产生命令:在 Hadoop 生态中,通常由
需要注意的是,具体的启动命令可能会因不同的集群部署方式、版本以及配置而有所差异。在实际使用中,应根据具体的环境和部署文档来准确启动和管理这些进程。