【图片识别改名】批量读取图片区域文字识别后批量改名,基于Python和腾讯云的实现方案
项目场景
- 办公文档管理:将扫描的发票、合同等文档按编号、日期自动重命名。例如,识别“编号:2023001 日期:20230403”生成“2023001_20230403.jpg”。
- 产品图片整理:电商产品图片按产品编号、名称自动命名。例如,识别“产品编号:P1001 产品名称:无线耳机”生成“P1001_无线耳机.jpg”。
- 证件照片归档:身份证、学生证等证件照片按姓名、学号等信息命名。例如,识别“姓名:张三 学号:20230001”生成“张三_20230001.jpg”。
- 会议资料整理:会议照片按会议名称、日期自动命名。例如,识别“会议:季度总结 日期:20230403”生成“季度总结_20230403.jpg”。

界面设计
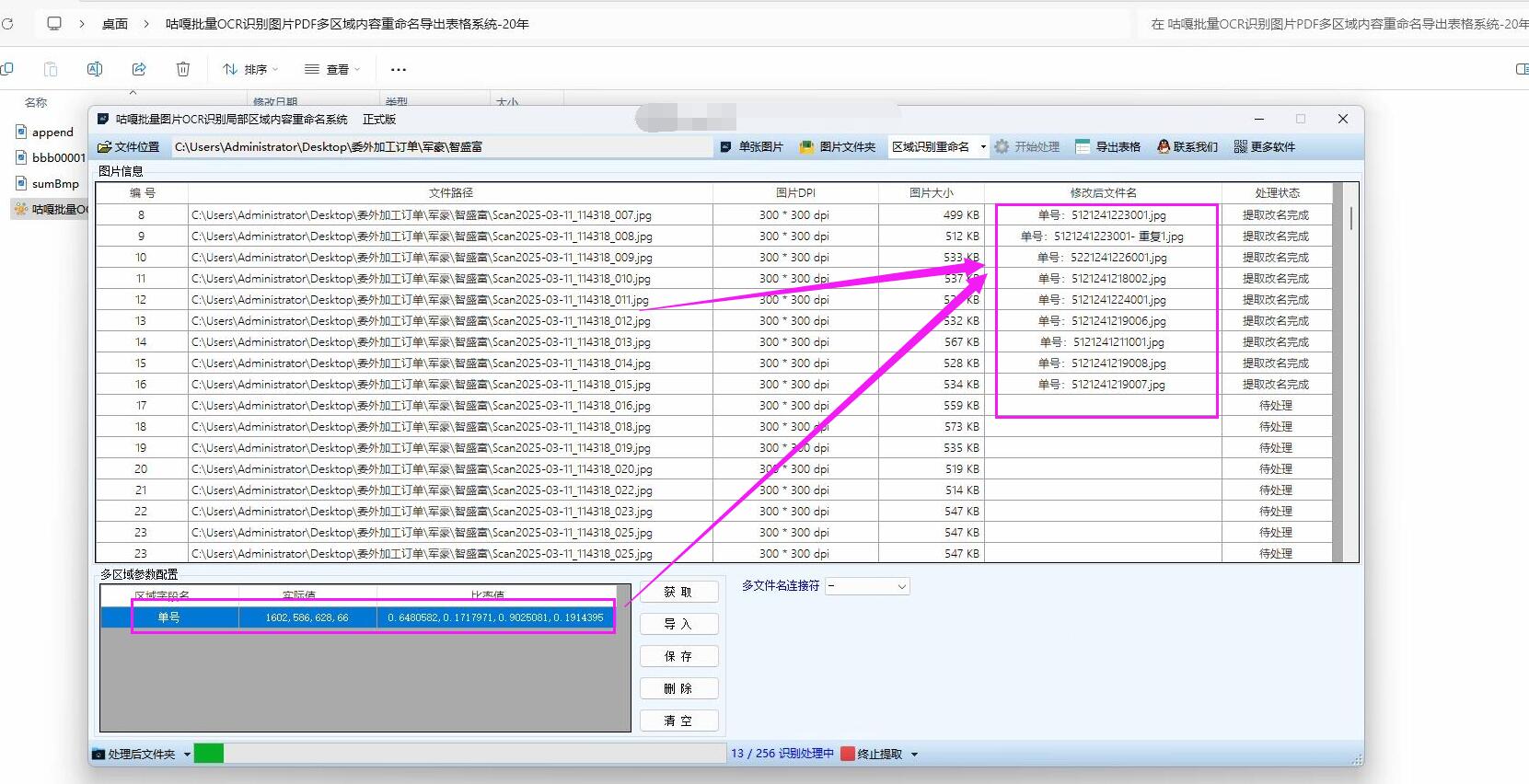
可以使用Python的tkinter库来设计一个简单的图形用户界面(GUI),以下是一个基本的界面设计思路:
- 标题:显示“批量图片文字识别与重命名工具”。
- API配置区域:包含输入框用于填写腾讯云的
SecretId和SecretKey,以及一个“保存配置”按钮。 - 关键字设置区域:输入框用于输入要识别的关键词,用逗号分隔,例如“编号,名称,日期”,并提供一个“设置关键词”按钮。
- 图片选择区域:一个按钮用于选择要处理的图片文件,支持多选,下方显示已选择的图片数量。
- 选项设置区域:包含“自动重命名文件”和“添加序号后缀”的复选框。
- 开始处理按钮:点击后开始进行文字识别和文件重命名操作。
- 进度条:显示处理进度。
- 结果区域:显示识别结果和重命名信息。
详细代码步骤
1. 安装必要的库
pip install pillow requests tkinter2. 代码实现
import os
import requests
from PIL import Image
from tkinter import Tk, Label, Entry, Button, Listbox, Checkbutton, IntVar, filedialog, messagebox, ttk# 腾讯云OCR API地址
OCR_API_URL = "https://ocr.tencentcloudapi.com"# 全局变量存储API密钥和关键词
SECRET_ID = ""
SECRET_KEY = ""
KEYWORDS = ""def set_api_config():global SECRET_ID, SECRET_KEYSECRET_ID = secret_id_entry.get()SECRET_KEY = secret_key_entry.get()if SECRET_ID and SECRET_KEY:messagebox.showinfo("提示", "API配置已保存")else:messagebox.showerror("错误", "请输入SecretId和SecretKey")def set_keywords():global KEYWORDSKEYWORDS = keywords_entry.get()if KEYWORDS:messagebox.showinfo("提示", "关键词已设置")else:messagebox.showerror("错误", "请输入要识别的关键词,用逗号分隔")def select_images():global image_pathsimage_paths = filedialog.askopenfilenames(filetypes=[("图片文件", "*.jpg;*.png")])if image_paths:image_count_label.config(text=f"已选择 {len(image_paths)} 张图片")else:messagebox.showerror("错误", "未选择任何图片")def recognize_and_rename():if not SECRET_ID or not SECRET_KEY or not KEYWORDS:messagebox.showerror("错误", "请先完成API配置和关键词设置")returnif not image_paths:messagebox.showerror("错误", "请先选择要处理的图片")returntotal = len(image_paths)progress["maximum"] = totalprogress["value"] = 0for i, image_path in enumerate(image_paths):try:# 读取图片with open(image_path, "rb") as f:image_data = f.read()# 构建请求参数params = {"Action": "GeneralBasicOCR","Version": "2018-11-19","Region": "ap-guangzhou","SecretId": SECRET_ID,"SecretKey": SECRET_KEY,"ImageBase64": image_data.hex()}# 发送请求response = requests.get(OCR_API_URL, params=params)result = response.json()if "TextDetections" in result:text = " ".join([item["DetectedText"] for item in result["TextDetections"]])# 根据关键词提取信息keyword_values = []for keyword in KEYWORDS.split(","):start_index = text.find(keyword)if start_index != -1:end_index = start_index + len(keyword)value = text[end_index:].split()[0](@ref)keyword_values.append(value)else:keyword_values.append("")# 生成新文件名new_name = "_".join(keyword_values) + os.path.splitext(image_path)[1]new_path = os.path.join(os.path.dirname(image_path), new_name)# 重命名文件os.rename(image_path, new_path)result_text.insert(tk.END, f"{image_path} -> {new_path}\n")else:result_text.insert(tk.END, f"{image_path} 识别失败\n")progress["value"] += 1root.update_idletasks()except Exception as e:result_text.insert(tk.END, f"{image_path} 处理出错: {str(e)}\n")progress["value"] += 1root.update_idletasks()messagebox.showinfo("完成", "处理完成")# 创建主窗口
root = Tk()
root.title("批量图片文字识别与重命名工具")# API配置区域
api_frame = LabelFrame(root, text="API配置")
api_frame.pack(pady=10, padx=10, fill="x")Label(api_frame, text="SecretId:").grid(row=0, column=0, padx=5, pady=5)
secret_id_entry = Entry(api_frame)
secret_id_entry.grid(row=0, column=1, padx=5, pady=5)Label(api_frame, text="SecretKey:").grid(row=1, column=0, padx=5, pady=5)
secret_key_entry = Entry(api_frame, show="*")
secret_key_entry.grid(row=1, column=1, padx=5, pady=5)save_api_button = Button(api_frame, text="保存配置", command=set_api_config)
save_api_button.grid(row=2, column=0, columnspan=2, pady=10)# 关键字设置区域
keyword_frame = LabelFrame(root, text="关键字设置")
keyword_frame.pack(pady=10, padx=10, fill="x")Label(keyword_frame, text="关键词:").grid(row=0, column=0, padx=5, pady=5)
keywords_entry = Entry(keyword_frame)
keywords_entry.grid(row=0, column=1, padx=5, pady=5)set_keyword_button = Button(keyword_frame, text="设置关键词", command=set_keywords)
set_keyword_button.grid(row=1, column=0, columnspan=2, pady=10)# 图片选择区域
image_frame = LabelFrame(root, text="图片选择")
image_frame.pack(pady=10, padx=10, fill="x")Label(image_frame, text="选择图片:").grid(row=0, column=0, padx=5, pady=5)
image_listbox = Listbox(image_frame)
image_listbox.grid(row=0, column=1, padx=5, pady=5)select_button = Button(image_frame, text="选择图片", command=select_images)
select_button.grid(row=1, column=0, columnspan=2, pady=10)image_count_label = Label(image_frame, text="未选择任何图片")
image_count_label.grid(row=2, column=0, columnspan=2, pady=5)# 选项设置区域
option_frame = LabelFrame(root, text="选项设置")
option_frame.pack(pady=10, padx=10, fill="x")auto_rename_var = IntVar()
auto_rename_checkbox = Checkbutton(option_frame, text="自动重命名文件", variable=auto_rename_var)
auto_rename_checkbox.grid(row=0, column=0, padx=5, pady=5)add_suffix_var = IntVar()
add_suffix_checkbox = Checkbutton(option_frame, text="添加序号后缀", variable=add_suffix_var)
add_suffix_checkbox.grid(row=1, column=0, padx=5, pady=5)# 开始处理按钮
start_button = Button(root, text="开始处理", command=recognize_and_rename)
start_button.pack(pady=20)# 进度条
progress = ttk.Progressbar(root, orient="horizontal", length=300, mode="determinate")
progress.pack(pady=10)# 结果区域
result_text = Text(root, height=10, width=50)
result_text.pack(pady=10)root.mainloop()