指针(5)
1.sizeof 和 strlen 的对比
1.1sizeof
sizeof 是操作符,sizeof 计算变量所占内存空间的大小,单位是字节,如果操作数是类型的话,计算的是使用类型创建的变量所占空间的大小。
sizeof 只关注占用内存的空间的大小,不在乎内存中存放的是什么数据。
int main()
{int a = 10;printf("%d\n", sizeof(a));printf("%d\n", sizeof a);printf("%d\n", sizeof(int));return 0;
}
//运行出的结果是一样的说明sizeof是操作符而不是函数,也进一步说明了sizeof不在意内存中存放的是什么内容
//只关注内存中所占用的空间的大小1.2.strlen
strlen 是库函数,功能是求字符串 \0 之前的字符串长度。函数规则如下:
size_t strlen ( const char * str );
strlen 函数会一直往后找 \0 ,所以可能出现越界的情况。
1.3 sizeof 和 strlen 的对比
sizeof:
1.sizeof 是操作符
2.sizeof计算操作数所占用内存的空间的大小,单位是字节
3.不关注内存中存放的是什么数据
strlen:
1.strlen 是库函数,头文件是 string.h
2.strlen 是求字符串的长度的,统计 \0 之前的字符个数
3.关注内存中是否有 \0,若没有,则会一直往后找,可能出现越界的情况
2.数组和指针题的解析
2.1一维数组
int main()
{int a[] = { 1,2,3,4 };//a 数组有4个元素,每个元素是 int 类型的数据printf("%d\n", sizeof(a));//16 sizeof(数组名)的情况是表示的是这个数组的大小,单位字节printf("%d\n", sizeof(a + 0));// 4/8 a代表首元素地址,a+0 还是首元素地址,printf("%d\n", sizeof(*a));// 4 a代表首元素地址,*a就是首元素,大小是4个字节printf("%d\n", sizeof(a + 1));// 4/8 a表示首元素地址,a+1代表的是第二个元素的地址,计算的就是第二个元素地址,大小是4/8printf("%d\n", sizeof(a[1]));//4 a[1]代表的是下表为1的第二个元素,元素的类型是int,大小是4字节printf("%d\n", sizeof(&a));// 4/8 &a表示的是取得是整个数组的地址,但根本上还是地址,所以大小为4/8printf("%d\n", sizeof(*&a));//16 //1.* 和 &的作用相互抵消 sizeof(a)取得就是 a 整个元素的大小//2.&a 的类型是数组指针 int (*)[4],*&a就是对数组指针进行解引用操作访问一个数组的大小printf("%d\n", sizeof(&a + 1));//4/8 &a+1跳过了整个数组后的一个地址,是地址大小就是4/8printf("%d\n", sizeof(&a[0]));//4/8 &a[0] 取得是下标为0的元素的地址,地址——4/8printf("%d\n", sizeof(&a[0] + 1));// 4/8 &a[0]+1 代表的是第二个元素的地址,大小 4/8return 0;
}2.2字符数组
代码1:
int main()
{char arr[] = { 'a','b','c','d','e','f' };//arr数组中有6个元素printf("%d\n", sizeof(arr));//6 计算的是整个元素的大小printf("%d\n", sizeof(arr + 0));//4/8 arr是首元素的地址 arr+0表达也是首元素的地址printf("%d\n", sizeof(*arr)); // 1 arr首元素的地址,*arr 就是第一个元素 大小是1个字节printf("%d\n", sizeof(arr[1]));//1 arr[1] 表示的是第二个元素,大小是1printf("%d\n", sizeof(&arr));// 4/8 取得是整个的元素的地址,大小是4/8printf("%d\n", sizeof(&arr + 1));// 4/8 &arr+1 跳过了整个数组,取得的还是地址 4/8printf("%d\n", sizeof(&arr[0] + 1));//4/8 &arr[0]+1 取得的是第二个元素的地址 大小是4/8return 0;}代码2:
int main()
{char arr[] = { 'a','b','c','d','e','f' };printf("%d\n", strlen(arr));//随机值 printf("%d\n", strlen(arr + 0));//随机值//printf("%d\n", strlen(*arr));//err arr 首元素地址 *arr首元素 是a—97//printf("%d\n", strlen(arr[1]));//err//上述两个例子存放的是两个ASCII码值,应该存放的是字符串,因为strlen要查找\0printf("%d\n", strlen(&arr));//随机值printf("%d\n", strlen(&arr + 1));//随机值printf("%d\n", strlen(&arr[0] + 1));//随机值return 0;
}代码3:
int main()
{char arr[] = "abcdef";printf("%zd\n", sizeof(arr));//6 整个数组的大小printf("%zd\n", sizeof(arr + 0));// arr 首元素地址 arr+0表示的也是首元素地址 是地址就是4/8个字节printf("%zd\n", sizeof(*arr));//arr 首元素地址,*arr首元素的大小 1printf("%zd\n", sizeof(arr[1]));//arr[1] - 'b' 大小为1printf("%zd\n", sizeof(&arr));//取得是整个数组的地址,是地址,大小就是4/8个字节printf("%zd\n", sizeof(&arr + 1));//跳过整个数组,指向了数组后边的地址 大小4/8字节printf("%zd\n", sizeof(&arr[0] + 1));//得到的是第二个元素的地址,是地址就是4/8字节return 0;
}代码4:
int main()
{char arr[] = "abcdef"; //arr数组内容:a b c d e f \0printf("%zd\n", strlen(arr));//arr首元素地址 往后找\0 统计个数为 6printf("%zd\n", strlen(arr + 0));//arr首元素地址 arr+0 也是首元素地址 6//printf("%zd\n", strlen(*arr));//arr首元素地址 *arr代表的是首元素 'a'-97 //在strlen中传的是 const char * str 而这里传的是97 是错误的 err//printf("%zd\n", strlen(arr[1]));//同样的,arr[1]-'b'-98 也是错误的 errprintf("%zd\n", strlen(&arr));//&arr 取得是整个数组的地址 指向的是数组的起始位置,往后找\0 6printf("%zd\n", strlen(&arr + 1));//&arr+1 跳过的是整个数组 在往后找\0 不确定 随机值 printf("%zd\n", strlen(&arr[0] + 1));//&arr[0] + 1 指向的是第二个元素地址,往后找\0 元素有5个 大小为 5return 0;
}代码5:
int main()
{char* p = "abcdef"; //内存中的内容:a b c d e f \0printf("%zd\n", sizeof(p));//p表示的是其实位置的地址,是地址大小就是4/8,不管你里面存放的是什么内容,只管大小,单位字节printf("%zd\n", sizeof(p + 1));//p 第一个元素的地址 p+1 第二个元素的地址 是地址大小就是 4/8printf("%zd\n", sizeof(*p));//*p - a 大小为 1printf("%zd\n", sizeof(p[0]));//p[0]-->*(p+0)-'a',大小为 1printf("%zd\n", sizeof(&p));//二级指针 取得是一级指针p(指针变量)的地址 是地址就是 4/8printf("%zd\n", sizeof(&p + 1));//&p + 1是指向的是p指针变量的后面的空间 但是仍然是地址,是地址就是 4 /8printf("%zd\n", sizeof(&p[0] + 1));//&p[0] + 1代表的是第二个元素地址,是地址大小就是 4/8return 0;
}代码6:
int main()
{char* p = "abcdef"; //内存中的内容:a b c d e f \0printf("%zd\n", strlen(p));// 6 p表示的是起始位置的地址,往后找\0,统计 \0 之前的个数 就是 6printf("%zd\n", strlen(p + 1));// 5 p+1 就是起始位置的地址+1表示的是第二个元素的地址,往后找\0,有 5 个元素//printf("%zd\n", strlen(*p));//error p 表示的是起始位置的地址 *p -- 'a' 对应的ASCII码值是97,但是strlen函数参数里面接收的是地址 所以会出现错误//printf("%zd\n", strlen(p[0]));//error p[0] 表示的是 'a'--对应的ASCII码值是 97 ,会出现错误 printf("%zd\n", strlen(&p));//随机值printf("%zd\n", strlen(&p + 1));//随机值 &p + 1 跳过的是abcdef\0所有的内容,不知道后面什么时候会出现\0printf("%zd\n", strlen(&p[0] + 1));//5 &p[0] + 1 表示的是第二个元素的地址,往后找\0,会有5个元素return 0;
}2.3二维数组
数组名的理解:
1.sizeof(数组名) 计算的是整个数组的大小
2.&数组名 取得是整个数组的地址,但是在屏幕上输出的结果同首元素的地址一样
其余情况数组名代表的都是首元素的地址
int main()
{int a[3][4] = {0};printf("%zd\n",sizeof(a));//计算的是整个数组的大小 12*4=48printf("%zd\n",sizeof(a[0][0]));//a[0][0]代表的是第0行的下标为0的元素 大小为 4printf("%zd\n",sizeof(a[0]));//a[0]是二维数组的元素下标为0的行的数组名,代表的是a[0]这一行的大小:4*4=16printf("%zd\n",sizeof(a[0]+1));//a[0]代表的是下标为0的行的地址,这里表示数组首元素a[0][0] a[0]+1代表的是a[0][1]的地址//也是地址,是地址大小就是4/8printf("%zd\n",sizeof(*(a[0]+1)));// a[0]+1代表的是a[0][1]的地址 *(a[0]+1)表示的是a[0][1] 大小是4 printf("%zd\n",sizeof(a+1));//a+1 首元素(第一行)的地址+1表示的是 a[1](第二行)的地址,是地址的大小就是 4/8printf("%zd\n",sizeof(*(a+1)));//*(a+1)=a[1] 就是第二行的数组名 sizeof(数组名) 计算的是第二行的数据的大小 4*4 =16printf("%zd\n",sizeof(&a[0]+1));//&a[0]+1 中的&a[0]代表的是二维数组中首元素(第一行)的名称, +1表示的是第二行的地址//是地址,大小就是 4/8printf("%zd\n",sizeof(*(&a[0]+1)));// &a[0]+1 表示的是a[1](第二行)的地址,*(&a[0]+1)) 后计算大小:4*4=16printf("%zd\n",sizeof(*a));//a表示的是首元素(第一行)地址 *a 表示的就是a[0](第一行),大小为 4*4=16printf("%zd\n",sizeof(a[3]));//a[3]表示的是下标为3的行,虽然本数组只有3行,下标为2,但是sizeof是根据类型来判断大小的,//sizeof(表达式)不存在越界,内部的表达式是不会真实计算的,只要知道类型就可以计算出大小,在一个二维整型数组中不存在的行数,//也是会计算出结果的,按照已经存在的行数来计算,在strlen中是不会出现这种情况的,因为在strlen中传的是字符串而不是整型数组//大小为 4*4=16return 0;
}3.指针运算题的解析
3.1 题目1
int main()
{int a[5] = { 1, 2, 3, 4, 5 };int* ptr = (int*)(&a + 1);printf("%d,%d", *(a + 1), *(ptr - 1)); // 2 5return 0;
}
//程序的结果是什么???
3.2 题目2
//在X86环境下
//假设结构体的⼤⼩是20个字节
//程序输出的结果是啥?
struct Test
{int Num;char* pcName;short sDate;char cha[2];short sBa[4];
}*p = (struct Test*)0x100000;int main()
{printf("%p\n", p + 0x1); //+0x1 = +1 指针+1 跳过了20字节 所以这里的+1是加了20,结果为: 0x100014printf("%p\n", (unsigned long)p + 0x1);//unsigned long 转换为整型 +1 是真正的 +1,结果为: 0x100001printf("%p\n", (unsigned int*)p + 0x1);//(unsigned int*) 转换为整型指针数据类型 +1 实际上是+4,结果为:0x100004return 0;
}3.3 题目3
int main()
{//逗号表达式: 1 3 5 所以数组的真正内容是:1 3 5int a[3][2] = { (0, 1), (2, 3), (4, 5) }; // 0 0 0//初始化数组用 { } // 0 0 0int* p;p = a[0];// 第一行的数组名,表示首元素的地址printf("%d", p[0]); //1return 0;
}3.4 题目4
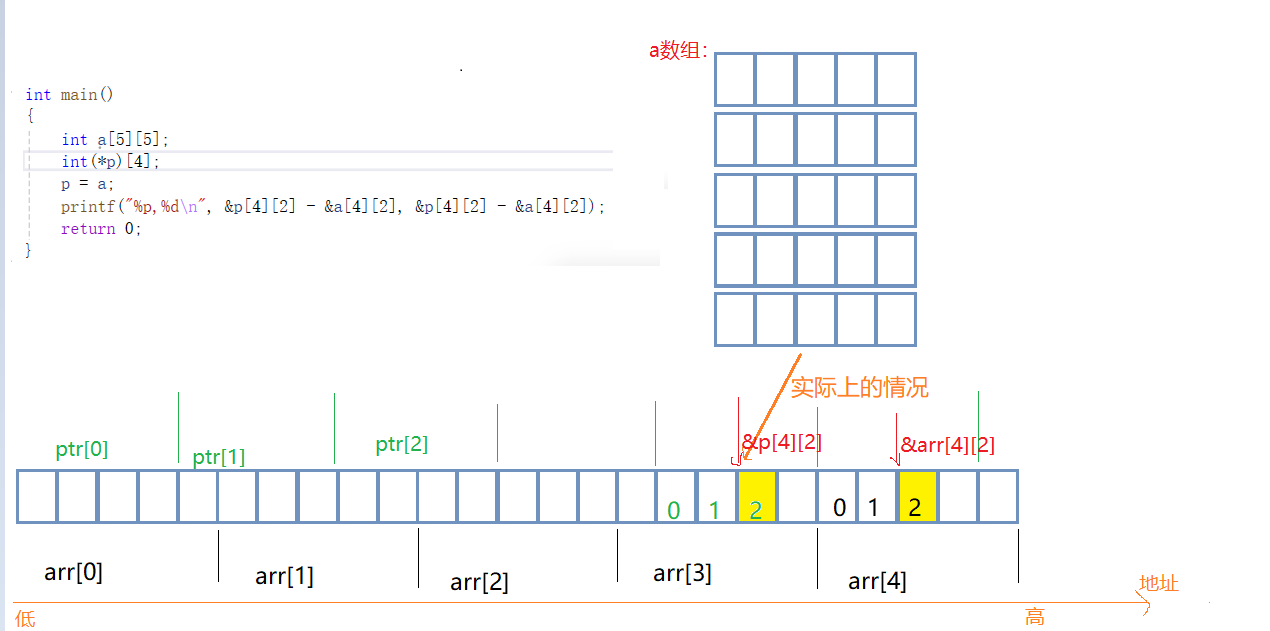
//假设环境是x86环境,程序输出的结果是啥?
int main()
{int a[5][5];int(*p)[4];p = a;printf("%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]); //-4 原码:10000000000000000000000000000100//%p 打印出来的是补码 -4 的补码:FFFFFFFC // 反码:11111111111111111111111111111011 //%d 打印出来的是原码 -4 中的 - (负号) 是因为低地址-高地址 // 补码:1111 1111 1111 1111 1111 1111 1111 1100//指针 - 指针 的绝对值表示的是 两个地址之间的元素个数 // F F F F F F F C //输出结果://FFFFFFFC //-4return 0;
}
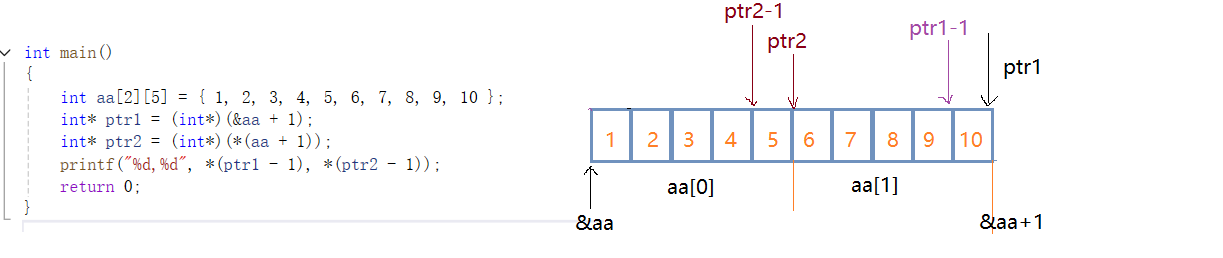
3.5 题目5
int main()
{int aa[2][5] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };int* ptr1 = (int*)(&aa + 1);int* ptr2 = (int*)(*(aa + 1));printf("%d,%d", *(ptr1 - 1), *(ptr2 - 1));// 10 5return 0;
}
3.6 题目6
int main()
{char* a[] = { "work","at","alibaba" };char** pa = a;pa++;printf("%s\n", *pa);//输出结果:atreturn 0;
}3.7 题目7
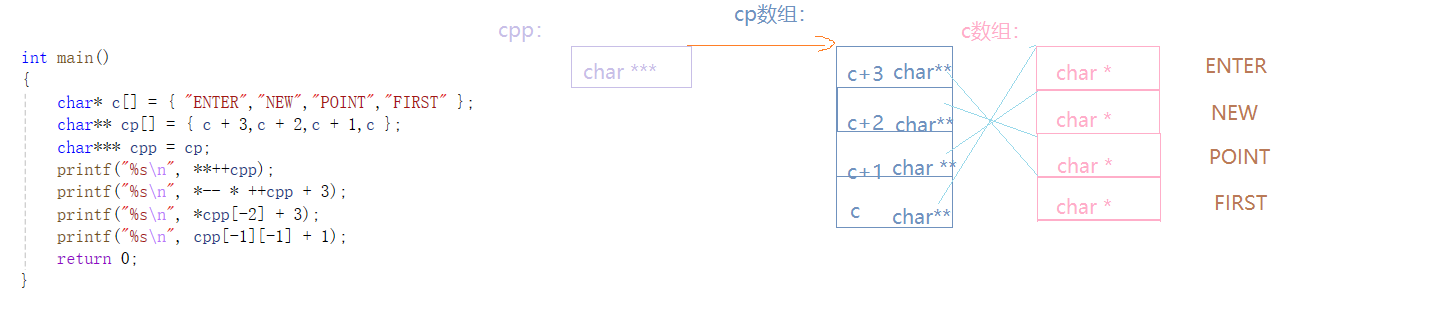
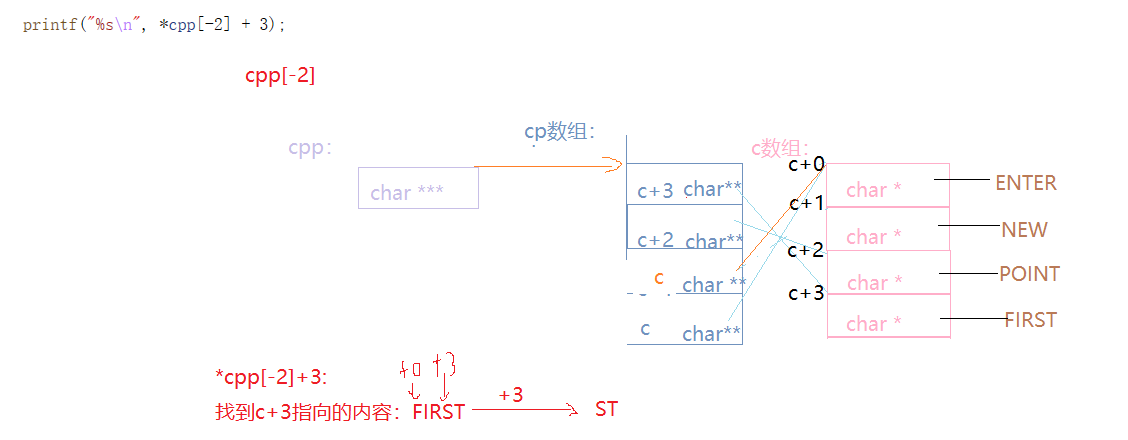
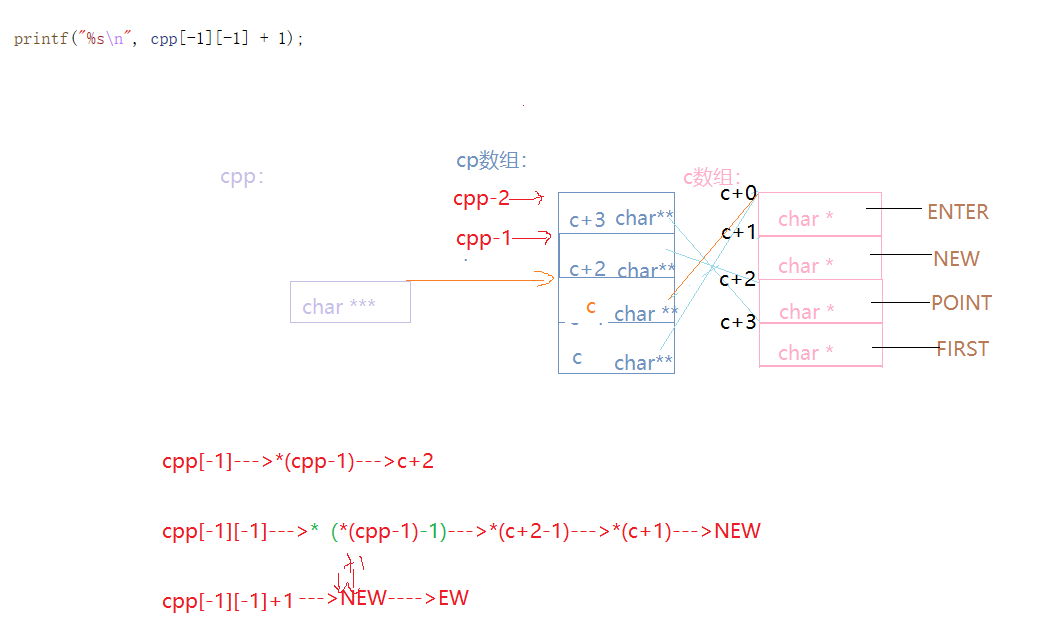
int main()
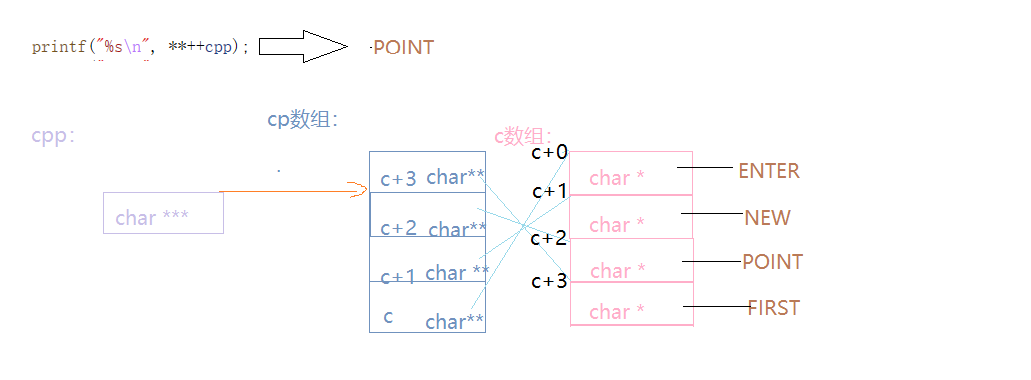
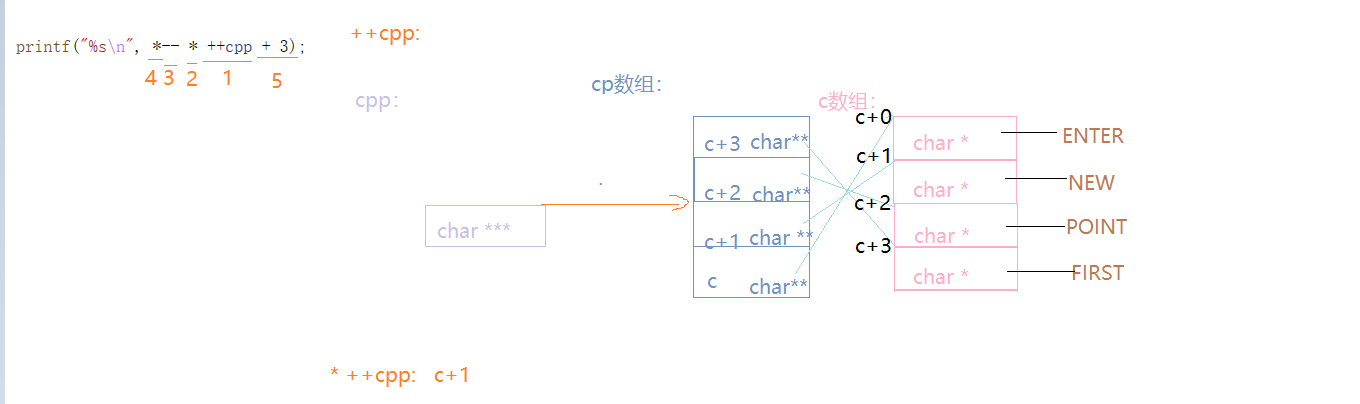
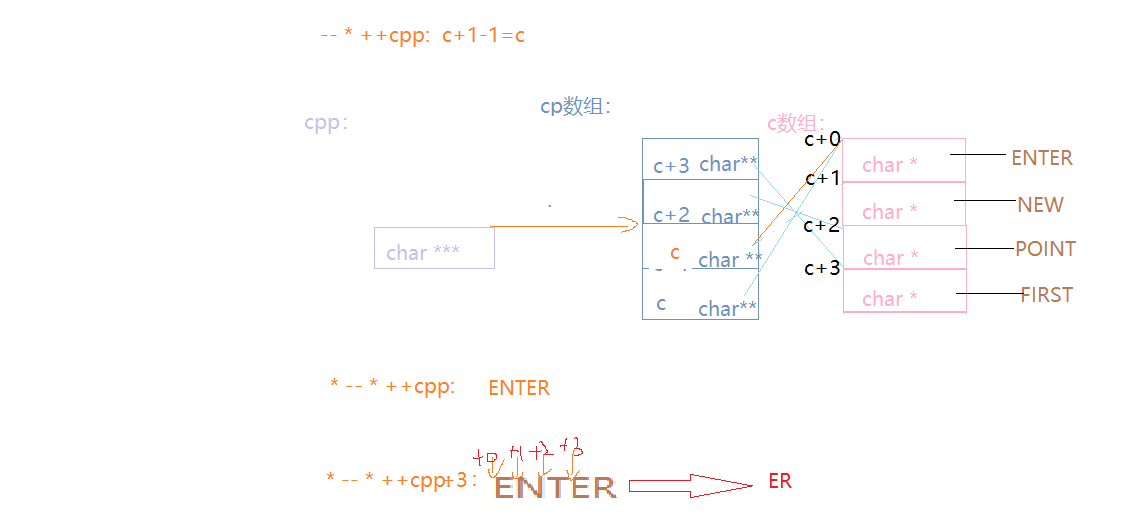
{char* c[] = { "ENTER","NEW","POINT","FIRST" };char** cp[] = { c + 3,c + 2,c + 1,c };char*** cpp = cp;printf("%s\n", **++cpp);//POINTprintf("%s\n", *-- * ++cpp + 3);//ERprintf("%s\n", *cpp[-2] + 3);//STprintf("%s\n", cpp[-1][-1] + 1);//EWreturn 0;
}