Sce2DriveX: 用于场景-到-驾驶学习的通用 MLLM 框架——论文阅读
《Sce2DriveX: A Generalized MLLM Framework for Scene-to-Drive Learning》2025年2月发表,来自中科院软件所和中科院大学的论文。
端到端自动驾驶直接将原始传感器输入映射到低级车辆控制,是Embodied AI的重要组成部分。尽管在将多模态大语言模型(MLLM)应用于高级交通场景语义理解方面取得了成功,但将这些概念语义理解有效地转化为低级运动控制命令并在跨场景驾驶中实现泛化和共识仍然具有挑战性。我们介绍了Sce2DriveX,一个类人驱动的思维链(CoT)推理MLLM框架。Sce2DriveX利用来自局部场景视频和全局BEV地图的多模态联合学习,深入了解长距离时空关系和道路拓扑,增强其在3D动态/静态场景中的综合感知和推理能力,实现跨场景的驾驶泛化。在此基础上,它重建了人类驾驶固有的内隐认知链,涵盖场景理解、元动作推理、行为解释分析、运动规划和控制,从而进一步弥合了自动驾驶与人类思维过程之间的差距。为了提高模型性能,我们开发了第一个为3D空间理解和长轴任务推理量身定制的广泛的视觉问答(VQA)驾驶指令数据集。大量实验表明,Sce2DriveX从场景理解到端到端驾驶都达到了最先进的性能,并在CARLA Bench2Drive基准上实现了稳健的泛化。
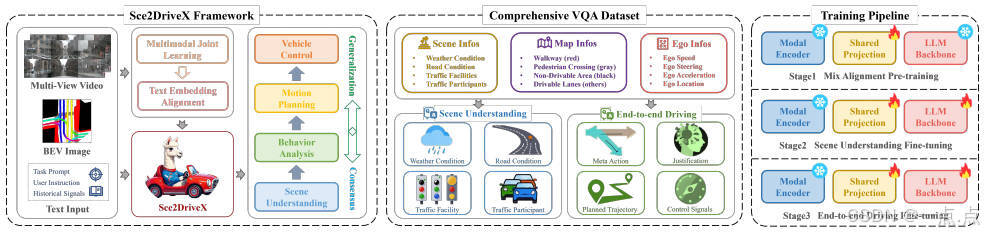
1. 研究背景与问题
自动驾驶作为具身智能(Embodied AI)的核心应用,面临两大核心挑战:
-
泛化能力不足:现有模型难以适应动态多变的交通场景(如天气变化、复杂道路拓扑、参与者行为差异等)。
-
与人类认知脱节:传统方法依赖刚性规则或小型模型,缺乏对驾驶过程的渐进式推理(Chain-of-Thought, CoT),导致决策逻辑不透明,难以与人类驾驶思维对齐。
2. 核心方法:Sec2DriveX框架
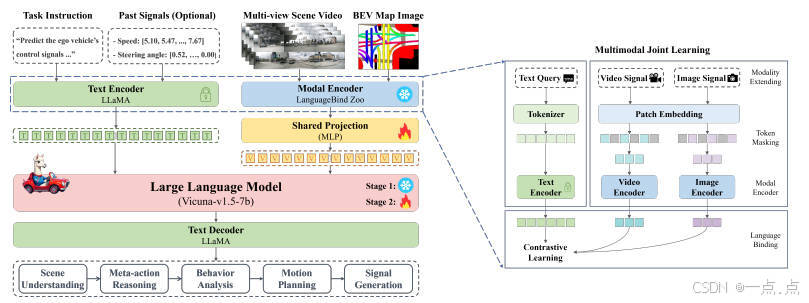
2.1 框架设计
Sec2DriveX是一个基于多模态大语言模型(MLLM)的端到端自动驾驶框架,核心目标是通过全局-局部感知与人类认知链建模,实现从场景理解到低层控制信号的闭环。其架构包含以下关键组件:
-
多模态输入:
-
局部场景视频:捕捉动态时空信息(如交通参与者运动)。
-
全局BEV地图:提供道路拓扑、车道结构等静态信息。
-
-
模态对齐:通过视频编码器(OpenCLIP)和图像编码器提取特征,映射至统一视觉特征空间。
-
LLM主干(Vicuna-v1.5-7b):整合多模态特征与文本指令,生成包含场景理解、元动作推理、行为解释、运动规划和控制信号的自然语言响应。
-
链式推理(CoT):模仿人类驾驶的渐进式逻辑,依次完成“场景→元动作→行为→轨迹→控制”的推理链。
2.2 数据集构建
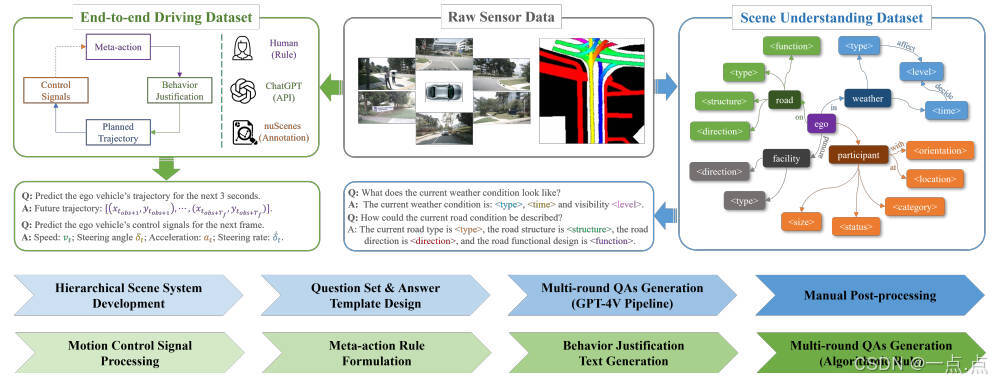
论文提出首个综合VQA驾驶指令数据集,覆盖以下内容:
-
层次化场景理解:
-
四类场景元素:天气、道路、设施、交通参与者(含3D静态属性与2D动态行为)。
-
自动化标注:通过ChatGPT生成多轮QA对,结合人工修正避免幻觉问题。
-
-
可解释端到端驾驶:
-
元动作规则:定义64种组合(如横向/纵向速度层级、转向层级),模拟人类驾驶意图。
-
行为解释文本:基于场景QA与元动作,由ChatGPT生成决策逻辑描述。
-
控制信号:解析nuScenes原始数据,生成轨迹(位置序列)与低层控制信号(加速度、转向角)。
-
2.3 三阶段训练流程
-
混合对齐预训练:在CC3M(图像-文本)和WebVid-10M(视频-文本)上对齐多模态特征,冻结编码器权重,仅训练共享投影层。
-
场景理解微调:使用层次化场景数据集,增强模型对3D空间关系的感知能力。
-
端到端驾驶微调:在可解释驾驶数据集上优化长轴任务推理(如轨迹规划与控制生成)。
3. 实验与性能验证
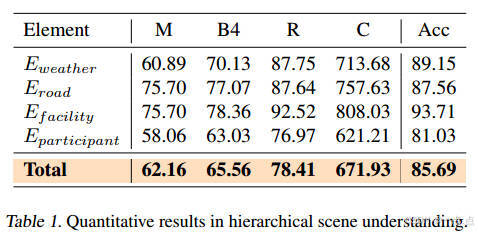
3.1 场景理解任务
-
指标:BLEU4、ROUGE、CIDEr等文本生成指标,以及分类准确率(Acc)。
-
结果(表1):
-
综合准确率85.69%,其中交通设施识别准确率最高(93.71%)。
-
CIDEr分数达671.93,表明生成描述与真实标注高度一致。
-
3.2 端到端驾驶任务
-
运动规划(表2):
-
3秒轨迹的L2误差0.36m,显著优于传统方法(UniAD: 1.03m)和MLLM基线(DriveVLM: 0.40m)。
-
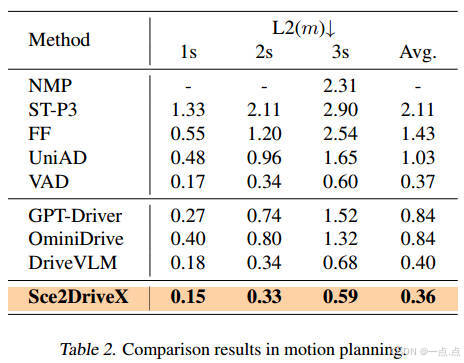
-
控制信号生成(表3):
-
加速度RMSE为0.241 m/s²,转向角误差0.427°,均优于DriveGPT4和RAG-Driver。
-
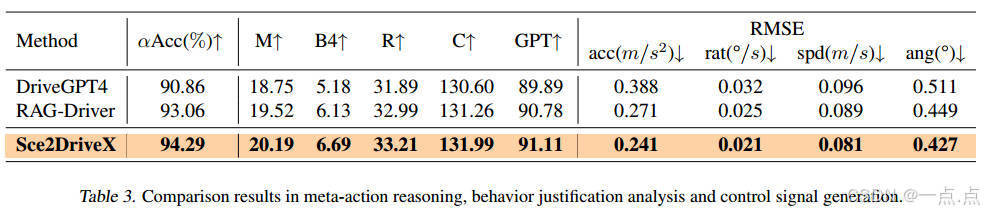
-
可解释性:GPT评分91.11(满分100),表明生成的行为解释更符合人类逻辑。
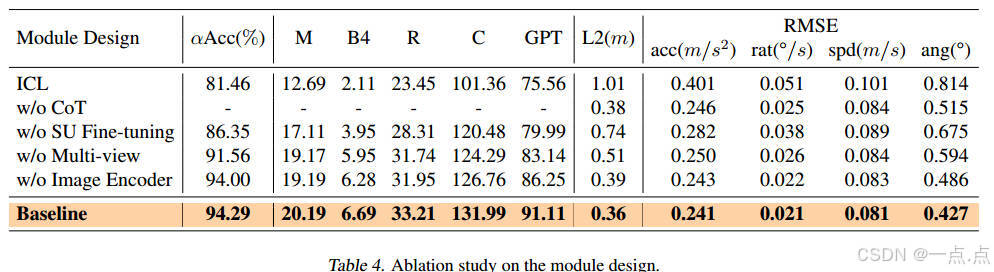
3.3 消融实验(表4)
-
多视图输入:移除后轨迹误差增加42%(0.51m→0.36m)。
-
场景理解微调:省略后元动作准确率下降8.9%(94.29%→86.35%)。
-
CoT模块:移除导致行为解释质量显著下降(GPT评分从91.11→75.56)。
4. 创新点与局限性
4.1 创新贡献
-
技术框架:
-
首次将MLLM的链式推理(CoT)与自动驾驶的全局-局部感知结合,实现“感知-推理-控制”一体化。
-
提出基于多视图视频与BEV地图的多模态对齐方法,增强时空关系建模。
-
-
数据集:
-
构建首个针对3D空间理解与长轴任务推理的VQA驾驶指令数据集,填补领域空白。
-
-
训练策略:
-
三阶段训练流程(预训练→场景微调→驾驶微调)有效平衡通用性与任务适配性。
-
4.2 局限性
-
实时性:未明确模型推理速度,可能限制实际部署。
-
泛化性:实验基于nuScenes和仿真数据(Bench2Drive),真实复杂场景(如极端天气、突发障碍)验证不足。
-
数据依赖:依赖ChatGPT生成标注,可能存在隐含偏差。
5. 未来方向
-
实时性优化:设计轻量级架构或模型压缩技术,提升推理效率。
-
多模态扩展:融合激光雷达、毫米波雷达等传感器数据,增强环境感知鲁棒性。
-
跨场景验证:在真实路测场景(如城市道路、高速公路)中评估泛化能力。
-
人机交互增强:结合人类反馈强化学习(RLHF),进一步对齐决策逻辑与人类偏好。
6. 总结
Sec2DriveX通过多模态大语言模型与链式推理的深度融合,为自动驾驶提供了一种可解释、泛化性强的端到端解决方案。其核心价值在于:
-
认知对齐:模仿人类驾驶的渐进式推理逻辑,提升决策透明度。
-
技术突破:在运动规划与控制信号生成任务中实现SOTA性能。
-
领域推动:构建的数据集与训练框架为后续研究提供了重要基准。
尽管存在实时性与真实场景验证的局限,Sec2DriveX为MLLM在自动驾驶中的应用开辟了新范式,有望推动智能驾驶系统向更安全、更可信的方向发展。
如果此文章对您有所帮助,那就请点个赞吧,收藏+关注 那就更棒啦,十分感谢!!!