强化学习之基于无模型的算法之时序差分法
2、时序差分法(TD)
核心思想
TD 方法通过 引导值估计来学习最优策略。它利用当前的估计值和下一个时间步的信息来更新价值函数, 这种方法被称为“引导”(bootstrapping)。而不需要像蒙特卡罗方法那样等待一个完整的 episode 结束才进行更新,也不需要像动态规划方法那样已知环境的转移概率。
状态价值函数更新
以最基本的 TD(0) 为例,状态价值函数 V( s) 的更新公式为:
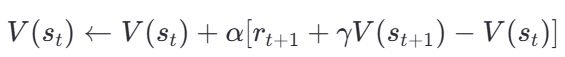
其中:
- st:当前状态;
- rt+1:从状态 stst 转移到下一状态 st+1st+1 所获得的奖励;
- γ:折扣因子,用于衡量未来奖励的重要性;
- α:学习率,控制更新的步长。
动作价值函数更新
对于动作价值函数 Q(s,a) Q( s, a),常见的 TD 更新方式如 Q-learning:
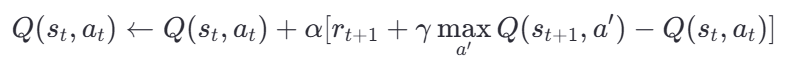
其中:
- maxa′Q(st+1,a′):在状态st+1 下所有可能动作的最大 Q 值。
算法特点
在线学习
TD 方法可以在与环境交互的过程中实时学习,每经历一个时间步即可进行一次价值函数更新,无需等到整个 episode 结束,适合实时性要求高的场景。
样本效率高
相比蒙特卡罗方法,TD 方法利用了环境的时序信息,通过“引导”机制减少对大量样本的依赖,在样本有限的情况下也能取得较好的学习效果。
融合两者优点
- 不需要环境模型(类似蒙特卡罗);
- 利用贝尔曼方程进行更新(类似动态规划);
- 克服了蒙特卡罗方法中对完整 episode 的依赖,提高学习效率。
局限性
- 收敛性问题:在复杂环境中可能出现收敛慢或不收敛的问题,尤其在状态空间大或奖励稀疏时表现不佳。
- 对超参数敏感:算法性能受学习率 α、折扣因子 γ 等影响较大,需多次实验调参。
- 模型泛化能力有限:通常只能针对特定环境学习最优策略,环境变化后需重新训练。
1)TD learning of state values
核心思想
TD(0) 是最基础的状态值学习方法。它通过比较当前状态的价值估计与基于后续状态的价值估计来更新当前状态的价值估计。
算法公式:
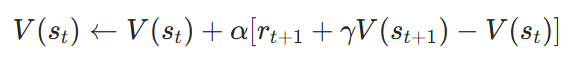
- TD Target:rt+1+γV(st+1)(基于下一状态的预估价值)。
- TD Error:δt=rt+1+γV(st+1)−V(st)(当前估计的偏差)。
2)TD learning of action values : Sarsa
核心思想
Sarsa 是一种在线策略(on - policy)的 TD 算法, 它直接使用行为策略生成的数据进行评估和改进该策略, 估计动作价值函数 Q(s, a) 。
算法公式:
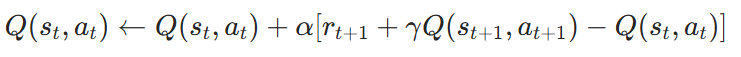
- 策略依赖:动作 at+1 由当前策略(如ε-贪婪策略)生成。
伪代码
对于每一个 episode,执行以下操作:
如果当前状态 s t 不是目标状态,执行以下步骤:
经验收集(Collect the experience)
获取经验元组( s t, a t, r t+1, s t+1, a t+1):
具体来说,按照当前策略 π t( s t) 选择并执行动作 a t,得到奖励 r t+1 和下一状态 s t+1;
然后按照当前策略 π t( s t+1) 选择下一个动作 a t+1。
Q 值更新(Update q-value)(根据上述公式)
策略更新(Update policy)(使用ε-贪婪策略)
实现代码
import time
import numpy as np
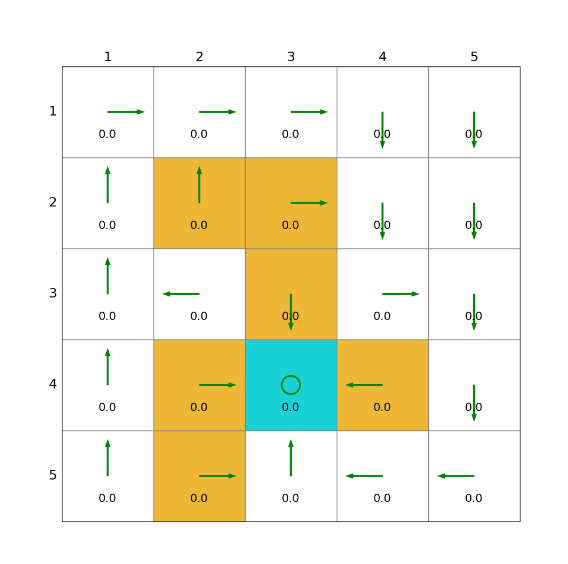
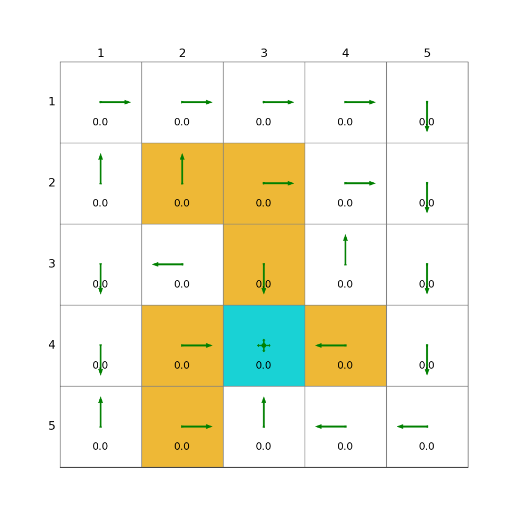
import grid_envclass Solve:def __init__(self, env: grid_env.GridEnv):self.gama = 0.9 #折扣因子,表示未来奖励的衰减程度self.env = envself.action_space_size = env.action_space_size #动作空间大小self.state_space_size = env.size ** 2 #状态空间大小self.reward_space_size, self.reward_list = len(self.env.reward_list), self.env.reward_list #奖励self.state_value = np.zeros(shape=self.state_space_size) #状态值self.qvalue = np.zeros(shape=(self.state_space_size, self.action_space_size)) #动作值self.mean_policy = np.ones(shape=(self.state_space_size, self.action_space_size)) / self.action_space_size #平均策略,表示采取每个动作概率相等self.policy = self.mean_policy.copy()def sarsa(self, alpha=0.1, epsilon=0.1, num_episodes=80):while num_episodes > 0:done = Falseself.env.reset()next_state = 0num_episodes -= 1total_rewards = 0episode_length = 0while not done:state = next_stateaction = np.random.choice(np.arange(self.action_space_size),p=self.policy[state]) #按照当前策略选择动作_, reward, done, _, _ = self.env.step(action) #根据当前动作得到下一状态和奖励,在self.env.agent_locationepisode_length += 1total_rewards += rewardnext_state = self.env.pos2state(self.env.agent_location) #下一动作next_action = np.random.choice(np.arange(self.action_space_size),p=self.policy[next_state]) #按照当前策略选择下一动作target = reward + self.gama * self.qvalue[next_state, next_action]error = target - self.qvalue[state, action] #估计偏差self.qvalue[state, action] = self.qvalue[state, action] + alpha * error #q值更新qvalue_star = self.qvalue[state].max()action_star = self.qvalue[state].tolist().index(qvalue_star)for a in range(self.action_space_size): #策略更新if a == action_star:self.policy[state, a] = 1 - (self.action_space_size - 1) / self.action_space_size * epsilonelse:self.policy[state, a] = 1 / self.action_space_size * epsilondef show_policy(self):# 可视化策略(Policy):将智能体的策略(每次行动的方向标注为箭头)以图形化的方式渲染到环境中for state in range(self.state_space_size):for action in range(self.action_space_size):policy = self.policy[state, action]self.env.render_.draw_action(pos=self.env.state2pos(state),toward=policy * 0.4 * self.env.action_to_direction[action],radius=policy * 0.1)def show_state_value(self, state_value, y_offset=0.2):# 可视化状态价值函数(State - ValueFunction):将每个状态的价值(长期累积奖励的预期)以文本形式渲染到环境中。for state in range(self.state_space_size):self.env.render_.write_word(pos=self.env.state2pos(state), word=str(round(state_value[state], 1)),y_offset=y_offset,size_discount=0.7)if __name__ == "__main__":env = grid_env.GridEnv(size=5, target=[2, 3],forbidden=[[2, 2], [2, 1], [1, 1], [3, 3], [1, 3], [1, 4]],render_mode='')solver = Solve(env)solver.sarsa()solver.show_policy()solver.show_state_value(solver.state_value, y_offset=0.25)solver.env.render()效果
3)TD learning of action values: Expected Sarsa
核心思想
Expected Sarsa 也是一种用于学习动作价值函数 Q(s, a))的 TD 算法。与 Sarsa 不同的是,它在更新时考虑了下一个状态下所有可能动作的期望价值,而不是仅仅使用一个特定的动作。
算法公式:
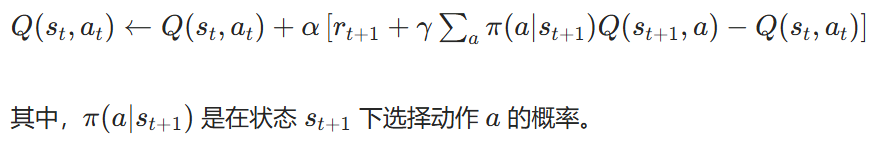
伪代码
和Sarsa类似,只是在Q 值更新时使用的是期望价值。
实现代码
import matplotlib.pyplot as plt
import numpy as np
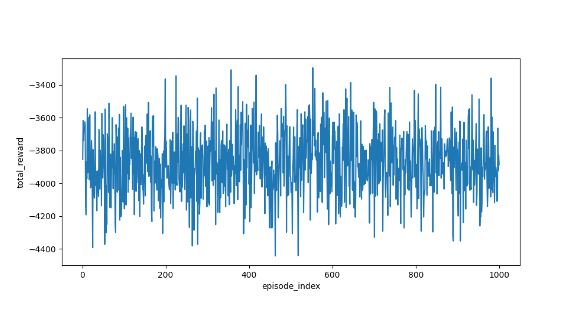
import grid_envclass Solve:def __init__(self, env: grid_env.GridEnv):self.gama = 0.9 #折扣因子,表示未来奖励的衰减程度self.env = envself.action_space_size = env.action_space_size #动作空间大小self.state_space_size = env.size ** 2 #状态空间大小self.reward_space_size, self.reward_list = len(self.env.reward_list), self.env.reward_list #奖励self.state_value = np.zeros(shape=self.state_space_size) #状态值self.qvalue = np.zeros(shape=(self.state_space_size, self.action_space_size)) #动作值self.mean_policy = np.ones(shape=(self.state_space_size, self.action_space_size)) / self.action_space_size #平均策略,表示采取每个动作概率相等self.policy = self.mean_policy.copy()def expected_sarsa(self, alpha=0.1, epsilon=1, num_episodes=1000):init_num = num_episodesqvalue_list = [self.qvalue, self.qvalue + 1]episode_index_list = []reward_list = []length_list = []while num_episodes > 0:if epsilon > 0.1:epsilon -= 0.01episode_index_list.append(init_num - num_episodes)done = Falseself.env.reset()next_state = 0total_rewards = 0episode_length = 0num_episodes -= 1while not done:state = next_stateaction = np.random.choice(np.arange(self.action_space_size),p=self.policy[state])_, reward, done, _, _ = self.env.step(action)next_state = self.env.pos2state(self.env.agent_location)expected_qvalue = 0episode_length += 1total_rewards += rewardfor next_action in range(self.action_space_size):expected_qvalue += self.qvalue[next_state, next_action] * self.policy[next_state, next_action]target = reward + self.gama * expected_qvalueerror = target - self.qvalue[state, action]self.qvalue[state, action] = self.qvalue[state, action] + alpha * errorqvalue_star = self.qvalue[state].max()action_star = self.qvalue[state].tolist().index(qvalue_star)for a in range(self.action_space_size):if a == action_star:self.policy[state, a] = 1 - (self.action_space_size - 1) / self.action_space_size * epsilonelse:self.policy[state, a] = 1 / self.action_space_size * epsilonqvalue_list.append(self.qvalue.copy())reward_list.append(total_rewards)length_list.append(episode_length)fig = plt.figure(figsize=(10, 10))self.env.render_.add_subplot_to_fig(fig=fig, x=episode_index_list, y=reward_list, subplot_position=211,xlabel='episode_index', ylabel='total_reward')self.env.render_.add_subplot_to_fig(fig=fig, x=episode_index_list, y=length_list, subplot_position=212,xlabel='episode_index', ylabel='total_length')fig.show()def show_policy(self):# 可视化策略(Policy):将智能体的策略(每次行动的方向标注为箭头)以图形化的方式渲染到环境中for state in range(self.state_space_size):for action in range(self.action_space_size):policy = self.policy[state, action]self.env.render_.draw_action(pos=self.env.state2pos(state),toward=policy * 0.4 * self.env.action_to_direction[action],radius=policy * 0.1)def show_state_value(self, state_value, y_offset=0.2):# 可视化状态价值函数(State - ValueFunction):将每个状态的价值(长期累积奖励的预期)以文本形式渲染到环境中。for state in range(self.state_space_size):self.env.render_.write_word(pos=self.env.state2pos(state), word=str(round(state_value[state], 1)),y_offset=y_offset,size_discount=0.7)if __name__ == "__main__":env = grid_env.GridEnv(size=5, target=[2, 3],forbidden=[[2, 2], [2, 1], [1, 1], [3, 3], [1, 3], [1, 4]],render_mode='')solver = Solve(env)solver.expected_sarsa()solver.show_policy()solver.show_state_value(solver.state_value, y_offset=0.25)solver.env.render()效果
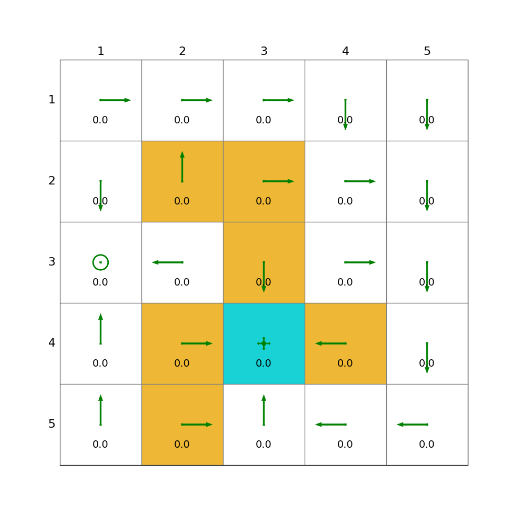
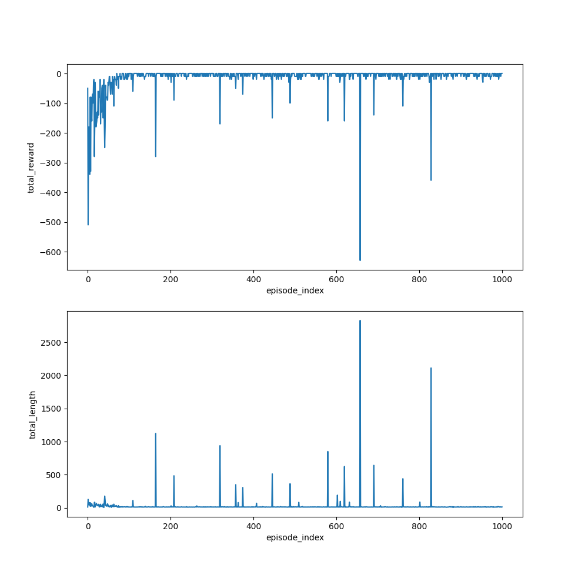
4)TD learning of action values: n-step Sarsa
核心思想
n - step Sarsa 是 Sarsa 算法的扩展,它不仅仅考虑下一个时间步的信息,而是考虑未来 n 个时间步的奖励和状态。这种方法结合了短期和长期的信息,以更准确地估计动作价值。
算法公式:

特点
- 平衡短期和长期信息:通过调整 n 的值,可以在短期和长期奖励之间进行权衡。当 (n = 1) 时,n - step Sarsa 退化为普通的 Sarsa 算法;当 n 趋近于无穷大时,它类似于蒙特卡罗方法。
- 可以提高学习的稳定性和效率,尤其是在环境动态变化的情况下。
伪代码
和Sarsa类似,只是在 Q 值更新时使用的上述公式。
实现代码
import matplotlib.pyplot as plt
import numpy as np
import grid_envclass Solve:def __init__(self, env: grid_env.GridEnv):self.gama = 0.9 #折扣因子,表示未来奖励的衰减程度self.env = envself.action_space_size = env.action_space_size #动作空间大小self.state_space_size = env.size ** 2 #状态空间大小self.reward_space_size, self.reward_list = len(self.env.reward_list), self.env.reward_list #奖励self.state_value = np.zeros(shape=self.state_space_size) #状态值self.qvalue = np.zeros(shape=(self.state_space_size, self.action_space_size)) #动作值self.mean_policy = np.ones(shape=(self.state_space_size, self.action_space_size)) / self.action_space_size #平均策略,表示采取每个动作概率相等self.policy = self.mean_policy.copy()def nsteps_sarsa(self, alpha=0.1, epsilon=1, num_episodes=1000, n=10):init_num = num_episodesqvalue_list = [self.qvalue.copy()]episode_index_list = []reward_list = []length_list = []while num_episodes > 0:if epsilon > 0.1:epsilon -= 0.01episode_index_list.append(init_num - num_episodes)done = Falseself.env.reset()next_state = 0total_rewards = 0episode_length = 0num_episodes -= 1# 存储轨迹信息(状态、动作、奖励)trajectory = []while not done:state = next_stateaction = np.random.choice(np.arange(self.action_space_size), p=self.policy[state])_, reward, done, _, _ = self.env.step(action)next_state = self.env.pos2state(self.env.agent_location)trajectory.append((state, action, reward))total_rewards += rewardepisode_length += 1# 计算 n-step 回报T = len(trajectory) # 轨迹长度for t in range(T):# 获取当前状态、动作、奖励state, action, reward = trajectory[t]target = 0# 计算 n-step 回报if t + n < T:# 如果轨迹足够长,计算 n-step 回报for i in range(n-1,-1,-1):next_reward_n = trajectory[t + i][2]target = target*self.gama + next_reward_nnext_state_n = trajectory[t + n][0]next_action_n = trajectory[t + n][1]q_next = self.qvalue[next_state_n, next_action_n]target = target + q_nextelse:for i in range(T-t-1,-1,-1):next_reward_n = trajectory[t + i][2]target = target * self.gama + next_reward_nnext_state_n = trajectory[T-t-1][0]next_action_n = trajectory[T-t-1][1]q_next = self.qvalue[next_state_n, next_action_n]target = target + q_next# 更新 Q 值error = target - self.qvalue[state, action]self.qvalue[state, action] += alpha * error# 更新策略qvalue_star = self.qvalue[state].max()action_star = self.qvalue[state].tolist().index(qvalue_star)for a in range(self.action_space_size):if a == action_star:self.policy[state, a] = 1 - (self.action_space_size - 1) / self.action_space_size * epsilonelse:self.policy[state, a] = 1 / self.action_space_size * epsilonqvalue_list.append(self.qvalue.copy())reward_list.append(total_rewards)length_list.append(episode_length)fig = plt.figure(figsize=(10, 10))self.env.render_.add_subplot_to_fig(fig=fig, x=episode_index_list, y=reward_list, subplot_position=211,xlabel='episode_index', ylabel='total_reward')self.env.render_.add_subplot_to_fig(fig=fig, x=episode_index_list, y=length_list, subplot_position=212,xlabel='episode_index', ylabel='total_length')fig.show()def show_policy(self):# 可视化策略(Policy):将智能体的策略(每次行动的方向标注为箭头)以图形化的方式渲染到环境中for state in range(self.state_space_size):for action in range(self.action_space_size):policy = self.policy[state, action]self.env.render_.draw_action(pos=self.env.state2pos(state),toward=policy * 0.4 * self.env.action_to_direction[action],radius=policy * 0.1)def show_state_value(self, state_value, y_offset=0.2):# 可视化状态价值函数(State - ValueFunction):将每个状态的价值(长期累积奖励的预期)以文本形式渲染到环境中。for state in range(self.state_space_size):self.env.render_.write_word(pos=self.env.state2pos(state), word=str(round(state_value[state], 1)),y_offset=y_offset,size_discount=0.7)if __name__ == "__main__":env = grid_env.GridEnv(size=5, target=[2, 3],forbidden=[[2, 2], [2, 1], [1, 1], [3, 3], [1, 3], [1, 4]],render_mode='')solver = Solve(env)solver.nsteps_sarsa()solver.show_policy()solver.show_state_value(solver.state_value, y_offset=0.25)solver.env.render()效果
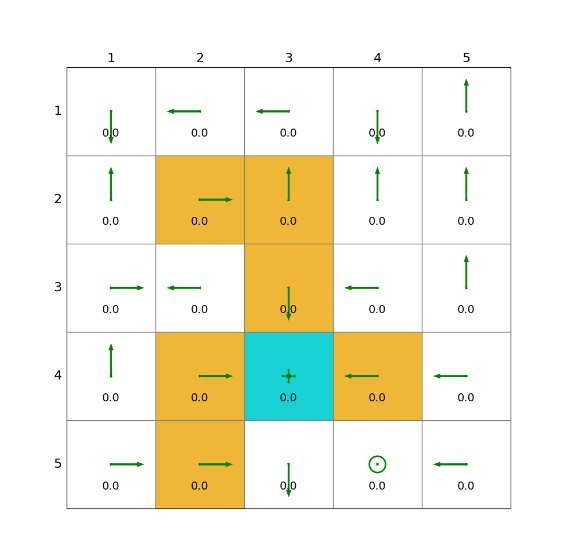
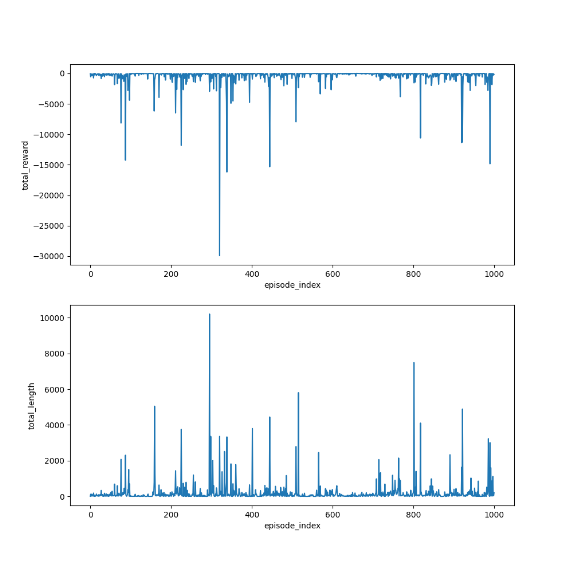
5)TD learning of optimal action values: Q-learning
核心思想
Q - learning 是一种异策略(off - policy)的 TD 算法,直接学习最优动作价值函数Q*(s, a)。异策略意味着它使用一个行为策略来生成行为,而使用另一个目标策略(通常是贪心策略)来更新动作价值。
算法公式:
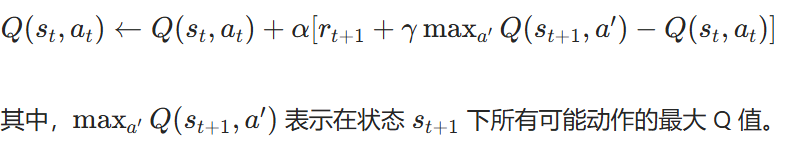
伪代码
1)在线版本的Q-learning(on-policy)
对于每一个 episode,执行以下操作:
如果当前状态st 不是目标状态,执行以下步骤:
经验收集(Collect the experience)
获取经验元组(st,at,rt+1,st+1):
具体来说,按照当前策略πt(st) 选择并执行动作at,得到奖励rt+1 和下一状态 st+1。
Q 值更新(Update q-value):按照上述公式
策略更新(Update policy):用ε 贪婪策略
2)离线版本的Q-learning(off-policy)
对于由行为策略 πb 生成的每一个 episode {s0,a0,r1,s1,a1,r2,…},执行以下操作:
对于该 episode 中的每一步t=0,1,2,…,执行以下操作:
Q 值更新(Update q-value):按照上述公式
策略更新(Update policy):用贪婪策略
实现代码
import matplotlib.pyplot as plt
import numpy as np
import grid_envclass Solve:def __init__(self, env: grid_env.GridEnv):self.gama = 0.9 #折扣因子,表示未来奖励的衰减程度self.env = envself.action_space_size = env.action_space_size #动作空间大小self.state_space_size = env.size ** 2 #状态空间大小self.reward_space_size, self.reward_list = len(self.env.reward_list), self.env.reward_list #奖励self.state_value = np.zeros(shape=self.state_space_size) #状态值self.qvalue = np.zeros(shape=(self.state_space_size, self.action_space_size)) #动作值self.mean_policy = np.ones(shape=(self.state_space_size, self.action_space_size)) / self.action_space_size #平均策略,表示采取每个动作概率相等self.policy = self.mean_policy.copy()def q_learning_on_policy(self, alpha=0.001, epsilon=0.4, num_episodes=1000):init_num = num_episodesqvalue_list = [self.qvalue, self.qvalue + 1]episode_index_list = []reward_list = []length_list = []while num_episodes > 0:episode_index_list.append(init_num - num_episodes)done = Falseself.env.reset()next_state = 0total_rewards = 0episode_length = 0num_episodes -= 1while not done:state = next_stateaction = np.random.choice(np.arange(self.action_space_size),p=self.policy[state])_, reward, done, _, _ = self.env.step(action)next_state = self.env.pos2state(self.env.agent_location)episode_length += 1total_rewards += rewardnext_qvalue_star = self.qvalue[next_state].max()target = reward + self.gama * next_qvalue_starerror = self.qvalue[state, action] - targetself.qvalue[state, action] = self.qvalue[state, action] - alpha * errorqvalue_star = self.qvalue[state].max()action_star = self.qvalue[state].tolist().index(qvalue_star)for a in range(self.action_space_size):if a == action_star:self.policy[state, a] = 1 - (self.action_space_size - 1) / self.action_space_size * epsilonelse:self.policy[state, a] = 1 / self.action_space_size * epsilonqvalue_list.append(self.qvalue.copy())reward_list.append(total_rewards)length_list.append(episode_length)fig = plt.figure(figsize=(10, 10))self.env.render_.add_subplot_to_fig(fig=fig, x=episode_index_list, y=reward_list, subplot_position=211,xlabel='episode_index', ylabel='total_reward')self.env.render_.add_subplot_to_fig(fig=fig, x=episode_index_list, y=length_list, subplot_position=212,xlabel='episode_index', ylabel='total_length')fig.show()def q_learning_off_policy(self, alpha=0.01, num_episodes=1000, episode_length=1000):qvalue_list = [self.qvalue, self.qvalue + 1]episode_index_list = []reward_list = []length_list = []init_num = num_episodeswhile num_episodes > 0:num_episodes -= 1total_rewards = 0episode_index_list.append(init_num - num_episodes)start_state = self.env.pos2state(self.env.agent_location)start_action = np.random.choice(np.arange(self.action_space_size),p=self.mean_policy[start_state])episode = self.obtain_episode(self.mean_policy.copy(), start_state=start_state, start_action=start_action,length=episode_length)for step in range(len(episode) - 1):reward = episode[step]['reward']state = episode[step]['state']action = episode[step]['action']next_state = episode[step + 1]['state']next_qvalue_star = self.qvalue[next_state].max()target = reward + self.gama * next_qvalue_starerror = self.qvalue[state, action] - targetself.qvalue[state, action] = self.qvalue[state, action] - alpha * erroraction_star = self.qvalue[state].argmax()self.policy[state] = np.zeros(self.action_space_size)self.policy[state][action_star] = 1total_rewards += rewardqvalue_list.append(self.qvalue.copy())reward_list.append(total_rewards)length_list.append(len(episode))fig = plt.figure(figsize=(10, 10))self.env.render_.add_subplot_to_fig(fig=fig, x=episode_index_list, y=reward_list, subplot_position=211,xlabel='episode_index', ylabel='total_reward')fig.show()def obtain_episode(self, policy, start_state, start_action, length):f""":param policy: 由指定策略产生episode:param start_state: 起始state:param start_action: 起始action:param length: episode 长度:return: 一个 state,action,reward,next_state,next_action 序列"""self.env.agent_location = self.env.state2pos(start_state)episode = []next_action = start_actionnext_state = start_statewhile length > 0:length -= 1state = next_stateaction = next_action_, reward, done, _, _ = self.env.step(action)next_state = self.env.pos2state(self.env.agent_location)next_action = np.random.choice(np.arange(len(policy[next_state])),p=policy[next_state])episode.append({"state": state, "action": action, "reward": reward, "next_state": next_state,"next_action": next_action})return episodedef show_policy(self):# 可视化策略(Policy):将智能体的策略(每次行动的方向标注为箭头)以图形化的方式渲染到环境中for state in range(self.state_space_size):for action in range(self.action_space_size):policy = self.policy[state, action]self.env.render_.draw_action(pos=self.env.state2pos(state),toward=policy * 0.4 * self.env.action_to_direction[action],radius=policy * 0.1)def show_state_value(self, state_value, y_offset=0.2):# 可视化状态价值函数(State - ValueFunction):将每个状态的价值(长期累积奖励的预期)以文本形式渲染到环境中。for state in range(self.state_space_size):self.env.render_.write_word(pos=self.env.state2pos(state), word=str(round(state_value[state], 1)),y_offset=y_offset,size_discount=0.7)if __name__ == "__main__":env = grid_env.GridEnv(size=5, target=[2, 3],forbidden=[[2, 2], [2, 1], [1, 1], [3, 3], [1, 3], [1, 4]],render_mode='')solver = Solve(env)# solver.q_learning_on_policy()solver.q_learning_off_policy()solver.show_policy()solver.show_state_value(solver.state_value, y_offset=0.25)solver.env.render()效果
1)在线版本的Q-learning
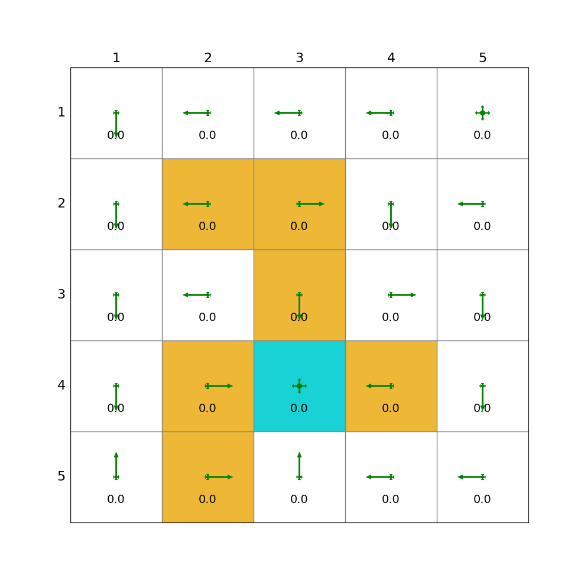
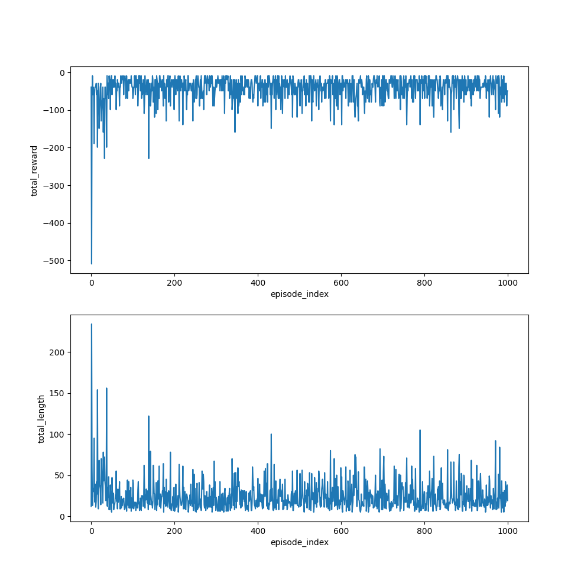
2)离线版本的Q-learning(off-policy)