做大模型应用所需的一点点基础数学理论
1.神经网络的基本理解
神经网络的灵感来源于生物学,人工智能的进步与生物学发展紧密相关。其核心组成部分神经元,通过模拟生物神经元的工作方式进行信息处理。
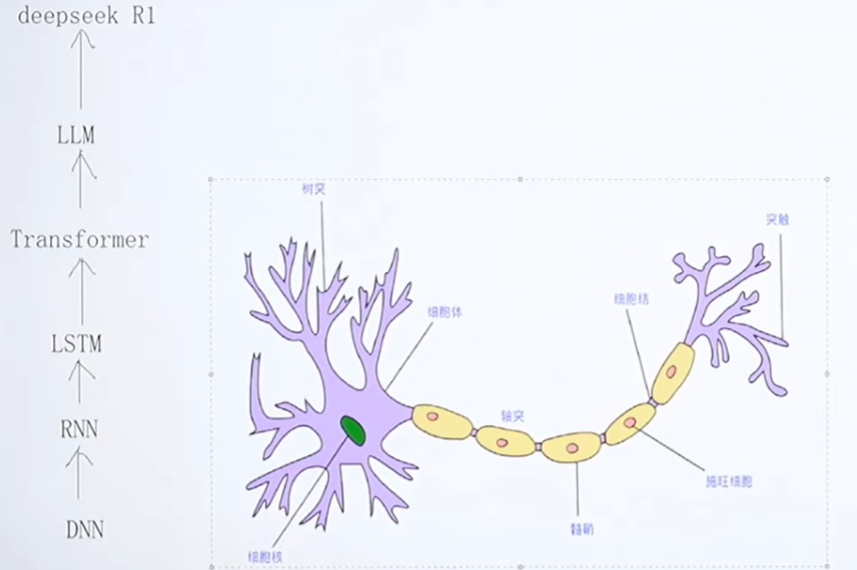
神经网络由一系列神经元构成
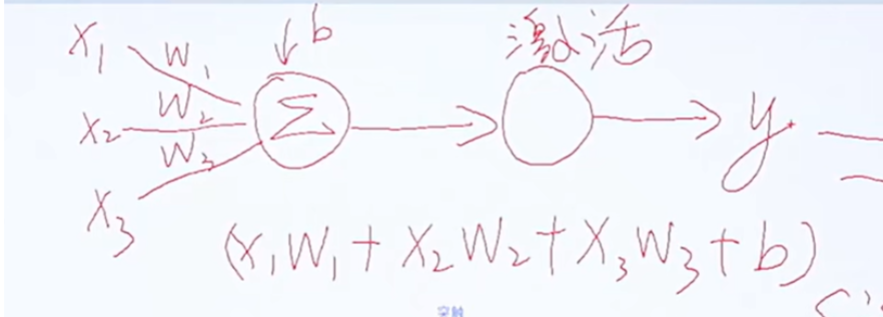
激活函数是神经网络中的关键,属于非线性化函数。它能针对不同输入值x产生不同输出值y,通过训练不断调整权重值(w)和偏移参数(b),实现预期的分类效果。
深度神经网络包含多层神经元。训练时,投喂大量数据样本,不断修正权重值(参数),使整个运算功能达到预期值。
训练过程:训练模型中的参数(w和b)让模型中每一层的权重值趋向合理值
训练一个神经网络的步骤:
1.首先搭建好神经网络,之后给予其大量参数,参数初始状态均为随机值
2.投喂数据不断训练,让所有的参数尽可能趋向于合理化
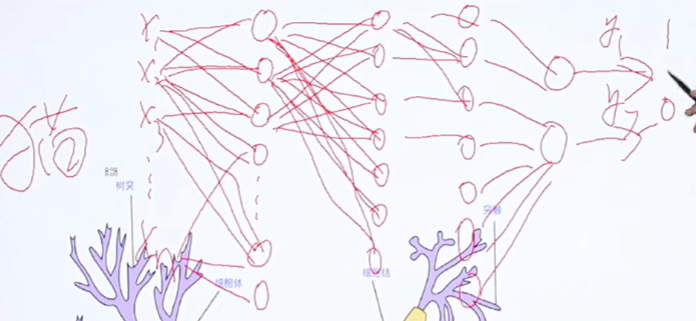
2.参数训练原理
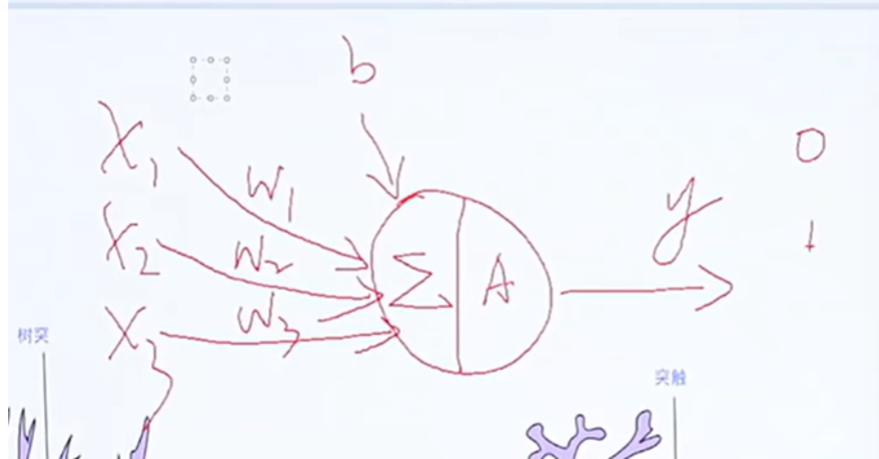
输入的原始数据会经历累加和激活两种运算方式
目标举例:输入某组组合数x,使其经过运算后得到的y值接近于0,输入另一组组合数x,使其经过运算后得到的y值趋近于1
实现方式:使用某种方式调整权重参数w和偏移参数b使其达到预期的结果
具体实现方式:梯度下降算法
3.梯度下降算法的原理
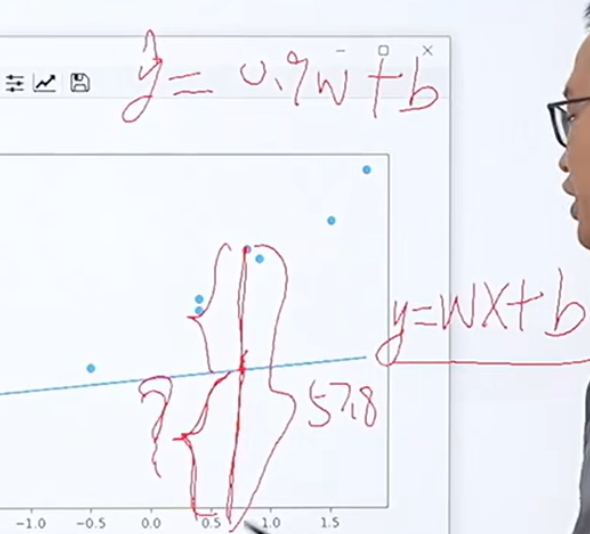
背景:现在我们有一堆离散的点,我们现在相找出一条线去拟合这些点,因此,我们需要通过梯度下降算法不断训练去找到那条线 设直线为y=wx+b,此时,我们要控制的参数是w和b,我们要找的拟合线的方式是找到一条目标线,使得目标线到所有点的距离和值最小。
设直线为y=wx+b,此时,我们要控制的参数是w和b,我们要找的拟合线的方式是找到一条目标线,使得目标线到所有点的距离和值最小。
现在我们对某个点进行分析:假设我现在取x=0.9的点,则此时y的预测值为0.9w+b,将其实际值减去预测值则为某个点到直线的距离,为了消除正负的影响,将得到的结果用平方标识,将所有点得到的(预测值-实际值)平方进行累加和则得到损失值
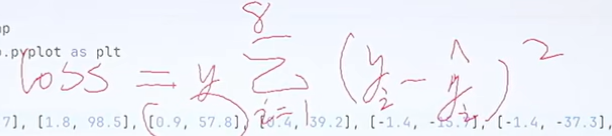
上述结果为损失值,对于损失值,越小则越好,损失值我们同时可以看作是一个关于w和b的函数
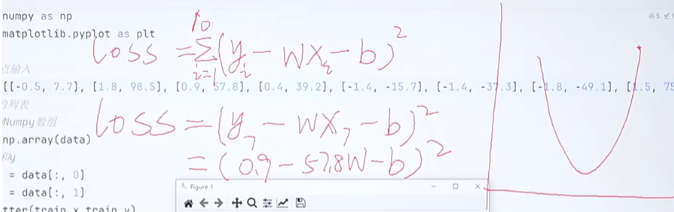
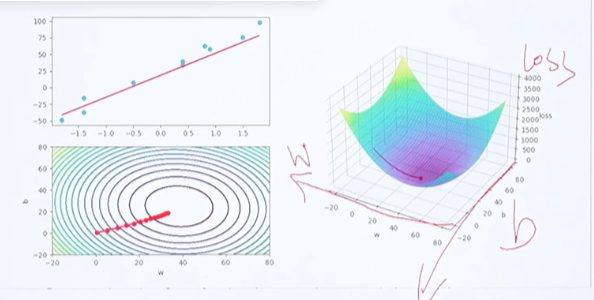
假设我们把b看作常数,此时,loss则可以看作是关于w的一个二次函数
此时,我们把w往w在这一点的函数切线方向去变则会得到更小的loss值,可以loss对w求偏导

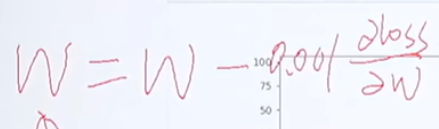
w减去一个参数乘上求导计算得到的斜率
w往切线方向(即往loss减小的方向去更新)
上面的过程调整的参数数量是2个,而我们做大模型调整往往调整的是大量参数而得到最优解,在此过程中,我们用到的也是梯度下降算法