大模型扫盲之推理性能指标全面详解
在大语言模型推理过程中,我们希望充分发挥GPU的全部性能。为此,我们需要判断推理过程是受计算能力限制还是受内存限制,这样才能在正确的方向上进行优化。通过计算特定GPU上每字节可能的操作数,并将其与模型注意力层的算术强度进行比较,就能找出瓶颈所在:是计算还是内存。利用这些信息,我们可以为模型推理选择合适的GPU,并且如果应用场景允许,还可以使用批处理等技术来更好地利用GPU资源。
本文将帮助你理解分析Transformer推理背后的数学原理。我们将以在A10 GPU上运行Llama 2模型为例,具体涵盖以下内容:
- 读取关键GPU规格,了解硬件性能
- 计算GPU的操作字节比(ops:byte)
- 计算大语言模型的算术强度
- 对比操作字节比和算术强度,判断推理是受计算还是内存限制
- 针对受内存限制和计算限制的推理,提供实用的优化策略
此外,还将通过实际的模型基准测试来验证分析。
GPU规格
假设我们选择A10 GPU,它在性能较为基础的T4和功能强大(但价格昂贵)的A100之间,是一个不错的折中选择。下表列举了A10的一些关键规格:
| 规格 | 参数 |
|---|---|
| FP32 | 31.2 TF |
| TF32 Tensor Core | 62.5 TF | 125 TF* |
| BFLOAT16 Tensor Core | 125 TF | 250 TF* |
| FP16 Tensor Core | 125 TF | 250 TF* |
| INT8 Tensor Core | 250 TOPS | 500 TOPS* |
| INT4 Tensor Core | 500 TOPS | 1000 TOPS* |
| GPU内存 | 24 GB GDDR6 |
| GPU内存带宽 | 600 GB/s |
| 最大TDP功耗 | 150W |
在推理过程中,我们主要关注以下三个参数:
- FP16 Tensor Core:这是我们的计算带宽。对于半精度(也称为FP16)模型,我们拥有125 TFLOPS(万亿次浮点运算每秒)的可用计算能力。半精度是一种二进制数字格式,每个数字占用16位,而全精度则是每个数字占用32位的二进制格式。对于许多机器学习应用来说,使用半精度是一个实际的选择,因为它在不损失太多精度的情况下占用更少的内存。在本文中,我们忽略数据手册中与稀疏性相关的值(用星号表示)。
- GPU内存:我们可以通过将参数数量(以十亿为单位)乘以2,快速估算模型占用的内存大小(以GB为单位)。这个方法基于一个简单的公式:在半精度下,每个参数使用16位(即2字节)内存,因此以GB为单位的内存使用量大约是参数数量的两倍。例如,一个有70亿参数的模型大约会占用14 GB内存。这为什么重要呢?因为A10的VRAM为24 GB,我们可以轻松运行一个70亿参数的模型,并且还剩下大约10 GB内存作为缓冲区。这些剩余内存在模型执行过程中起着重要作用,我们稍后会详细阐述。
- GPU内存带宽:我们每秒可以将600 GB的数据从GPU内存(也称为HBM或高带宽内存)传输到片上处理单元(也称为SRAM或共享内存)。
计算操作字节比(ops:byte)
利用这些参数,我们可以计算硬件的操作字节比。这个比值表示我们每访问1字节内存,能够完成多少浮点运算(FLOPS)。
根据规格表中的数据,我们计算A10的操作字节比:
ops_to_byte_A10= compute_bw / memory_bw = 125 TF / 600 GB/S = 208.3 ops / byte
这意味着,为了充分利用我们的计算资源,每访问1字节内存,我们必须完成208.3次浮点运算。
如果我们发现每字节只能完成少于208.3次运算,那么我们的系统性能受内存限制**(memory bound)**。这本质上意味着系统的速度和效率受到数据传输速率或输入输出操作处理能力的限制。
如果我们希望每字节完成超过208.3次浮点运算,那么我们的系统受计算能力限制**(compute bound)**。在这种情况下,限制系统性能的不是内存,而是芯片所拥有的计算单元数量。
了解系统是受计算能力限制还是内存限制至关重要,这样我们才能明确应该针对计算还是带宽进行特定有效的优化。
计算算术强度(arithmetic intensity)
为了确定我们的系统是受内存限制还是计算能力限制,我们需要计算70亿参数大语言模型的算术强度,然后将其与我们刚刚计算出的GPU操作字节比进行比较。算术强度是指算法执行的计算操作数除以所需的字节访问数,是一种与硬件无关的度量。
70亿参数大语言模型中计算量最大的部分是注意力层,它确保根据先前token的相关性对下一个token进行加权预测。由于注意力层在推理过程中计算需求最高,我们将在这里计算算术强度。
要理解注意力层,我们需要更具体地了解模型的内部工作原理。在从Transformer模型进行采样时,有两个阶段:
- 预填充(Prefill):在第一阶段,模型并行读取输入的提示token,填充键值(KV)缓存。KV缓存可以看作是模型的状态,包含在注意力操作中。在预填充阶段,不会生成任何token。
- 自回归采样(Autoregressive sampling):也叫decoding,在第二阶段,我们利用当前状态(存储在KV缓存中)来采样和解码下一个token。为了避免为每个新token重新计算缓存,我们在存储方面付出了一点代价。如果没有KV缓存,每生成一个新token都需要更长的时间,因为我们必须将之前看到的所有token都输入到模型中进行计算。
拆解注意力公式
以下是大语言模型推理中注意力的计算公式。我们将逐步分析这个公式,确定哪些部分需要内存移动,哪些部分需要计算操作,然后通过比较来找到我们需要的算术强度。
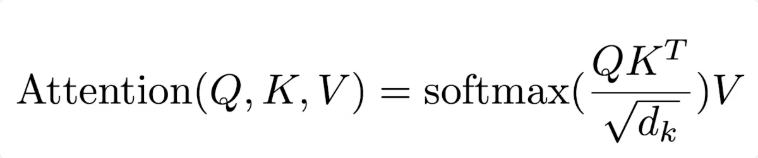
FlashAttention论文的作者对标准注意力算法有一个很好的实现,这种框架将使我们更容易计算算法中的内存和计算需求。

这里省略了除以sqrt(d_k)的步骤,并不影响整体分析。
所有三个步骤都遵循相同的模式:从内存加载值,进行计算,然后将计算结果存储回内存。在算法中:
N是大语言模型的序列长度,它设置了上下文窗口。对于Llama 2 7B模型,N = 4096。d是单个注意力头的维度。对于Llama 2 7B模型,d = 128。Q、K和V都是用于计算注意力的矩阵,它们的维度是N乘以d,在我们的例子中是4096x128。S和P是在计算过程中得到的矩阵,它们的维度是N乘以N,即4096x4096。O是注意力计算结果的输出矩阵,维度是N乘以d,也就是4096x128。- HBM是高带宽内存。从规格表中我们知道,A10上有24 GB的HBM,运行速度为600 GB/s。
基于这些参数,让我们拆解标准注意力算法的每一行实现,然后将它们相加,以计算运行该算法的总计算量和内存成本。
| 算法行 | 从内存加载 | 计算 | 存储到内存 |
|---|---|---|---|
| 第1行 | size_fp16 * (size_Q + size_K) = 2 * 2 * (N * d) | cost_dot_product_QK * size_S = (2 * d) * (N * N) | size_fp16 * size_S = 2 * (N * N) |
| 第2行 | size_fp16 * size_S = 2 * (N * N) | cost_softmax * size_P = 3 * (N * N) | size_fp16 * size_P = 2 * (N * N) |
| 第3行 | size_fp16 * (size_P + size_V) = 2 * ((N*N) + (N * d)) | cost_dot_product_PV * size_O = (2 * N) * (N * d) | size_fp16 * size_O = 2 * (N * d) |
我们通过将第一列和第三列(从内存加载和存储到内存的部分)相加来计算总内存移动量:
total_memory_movement_in_bytes:= (2 * 2 * (N * d)) + (2 * (N * N)) + (2 * ((N*N) + (N * d))) + (2 * (N * N)) + (2 * (N * N)) + (2 * (N * d))= 8N^2 + 8Nd bytes
通过将第二列(对加载数据的计算量)相加来计算总计算量:
total_compute_in_floating_point_ops: = ((2 * d) * (N * N)) + (3 * (N * N)) + ((2 * N) * (N * d))= 4(N^2)d + 3N^2 ops
算术强度可以按如下方式计算:
arithmetic_intensity_llama ~= total compute / total memory movement= 4d(N^2) + 3N^2 ops / 8N^2 + 8Nd bytes= 62 ops/byte for Llama 2 7B
发现推理瓶颈
Llama 2 7B模型的算术强度是每字节62次操作,远低于A10的操作字节比208.3。
因此,在自回归阶段,我们的模型受内存限制**(memory bound)**。换句话说,在将1字节数据从内存传输到计算单元的时间内,我们本可以完成比这多得多的计算。
所以decoding阶段的优化一般要想办法提高带宽利用率。
在GPU上对受内存限制的进程进行批处理
一种解决方案是利用额外的片上内存,对模型进行批量前向传递。也就是说,我们可以等待几百毫秒,积累几个请求,然后一次性处理这些请求,而不是在请求到达时立即处理。这样可以重用已经加载到GPU的SRAM中的模型部分。
批处理通过在相同的内存加载和存储次数下进行更多计算,提高了模型的算术强度,从而降低了模型受内存限制的程度。
我们可以将批处理的大小设置为多少呢?回想一下,在加载70亿参数的模型后,A10上还剩下10 GB内存:
24 GB - (2 * 7GB) = 10GB
现在的问题是,我们可以在剩余的GPU内存中一次性容纳多少个序列?
为了计算这个数字,我们需要回到KV cache。在注意力层的预填充步骤中,我们根据提示(即输入序列)填充KV缓存。
KV缓存包含我们在注意力计算中使用的矩阵K和V。为了计算KV缓存的大小,我们需要一些之前提到的值和几个新的值:
d(也可以表示为d_head)是单个注意力头的维度。对于Llama 2 7B模型,d = 128。n_heads是注意力头的数量。对于Llama 2 7B模型,n_heads = 32。n_layers是注意力块出现的次数。对于Llama 2 7B模型,n_layers = 32。d_model是模型的维度,d_model = d_head * n_heads。对于Llama 2 7B模型,d_model = 4096。
值得注意的是,d_model与N(上下文窗口长度)相同只是巧合。正如Llama论文所示,其他大小的Llama 2模型具有更大的d_model(见“维度”列)。
在半精度(FP16)下,每个浮点数需要2字节存储。有2个矩阵,为了计算KV缓存的大小,我们将它们都乘以n_layers和d_model,得到以下公式:
kv_cache_size= (2 * 2 * n_layers * d_model) bytes/token= (4 * 32 * 4096) bytes/token= 524288 bytes/token~ 0.00052 GB/token
鉴于KV缓存每个token需要524288字节,那么从token数量的角度来看,KV缓存可以有多大呢?
kv_cache_tokens= 10 GB / 0.00052 GB/token= 19,230 tokens
我们的KV缓存可以轻松容纳19230个token。因此,对于Llama 2标准的4096 token序列长度,我们的系统有足够的带宽同时处理4个序列的批处理。
为了充分利用算力,在推理过程中,我们希望一次批处理4个请求来填充KV缓存,这将提高我们的吞吐量。
如果你使用大语言模型异步处理大量文档队列,批处理是一个很好的选择。与逐个处理每个元素相比,你将更快地处理队列,并且可以安排推理调用,以便快速填充批次,最大程度地减少对延迟的影响。
评估用于大语言模型推理的GPU
在某些情况下,批处理可能并不适用。例如,如果你正在构建一个面向用户的聊天机器人,你的产品对延迟更加敏感,因此你不能在运行推理之前等待批次填充。在这种情况下,我们该怎么办呢?
一种选择是认识到我们无法充分利用GPU的片上内存,因此可以选择较小的GPU。例如,我们可以选择T4 GPU,它有16 GB的VRAM。这仍然可以容纳我们的70亿参数模型,但剩余的容量要少得多,只有2 GB用于批处理和KV缓存。
然而,T4 GPU通常比A10慢,而A100虽然功能更强大,但价格也更高。我们可以通过计算一些简单的推理时间下限来量化这些差异。
在每个GPU上生成单个token
回想一下,在生成过程的自回归部分,如果批大小为1,我们的系统受内存带宽限制。让我们使用以下公式快速计算生成单个token所需的时间:
time/token = total number of bytes moved (the model weights) / accelerator memory bandwidth
- 在T4上:
(2 * 7B) bytes / (300 GB/s) = 46 ms/token - 在A10上:
(2 * 7B) bytes / (600 GB/s) = 23 ms/token - 在A100 SXM 80 GB上:
(2 * 7B) bytes / (2039 GB/s) = 6 ms/token
这些估计表明,A10的速度是T4的两倍,A100的速度几乎是A10的四倍(因此是T4的八倍)。
这些数字只是近似值,因为它们假设推理过程中GPU内部没有通信、每次前向传递没有开销,并且计算过程中完全并行化。
在每个GPU上使用批处理的提示token进行预填充
我们还可以计算假设将所有提示token批处理为一次前向传递时的预填充时间。为了简单起见,假设提示有350个token,并且限制瓶颈是计算能力,而不是内存。
Prefill time = number of tokens * ( number of parameters / accelerator compute bandwidth)
- 在T4上:
350 * (2 * 7B) FLOP / 65 TFLOP/s = 75 ms - 在A10上:
350 * (2 * 7B) FLOP / 125 TFLOP/s = 39 ms - 在A100 SXM 80 GB上:
350 * (2 * 7B) FLOP / 312 TFLOP/s = 16 ms
估计每个GPU上的总生成时间
假设我们允许生成150个完成token(并且不考虑任何停止token),我们的总生成时间如下:
Total generation time = prefill time + number of tokens * time/token
- 在T4上:
75 ms + 150 tokens * 46 ms/token = 6.98 s - 在A10上:
39 ms + 150 tokens * 23 ms/token = 3.49 s - 在 A100 SXM 80GB 上:
16 ms + 150 tokens * 6 ms/token = 0.92 s
考虑到GPU的价格,我们可以观察推理在速度和成本之间的大致权衡。具体数值会因计算中使用的token数量而略有不同。
| GPU | 推理时间 | 标价 | 相对T4的加速倍数 | 相对T4的成本倍数 |
|---|---|---|---|---|
| T4 | 6.98秒 | 0.01052美元/分钟 | 不适用 | 不适用 |
| A10 | 3.49秒 | 0.02012美元/分钟 | 约2倍 | 约2倍 |
| A100 | 0.92秒 | 0.10240美元/分钟 | 约7.5倍 | 约10倍 |