[轻量化超分]CAMixerSR: Only Details Need More “Attention“
CAMixerSR: Only Details Need More “Attention”,CVPR 2024
只有细节需要更多的“关注”
2024 年 2 月 29 日
paper&code
文章目录
- 简要介绍
- CAMixer
- Predictor
- Attention
- 卷积
- 参数量分析
- CAMixerSR
- Experiment
- 主要借鉴
- 消融实验
- 实验配置
- 训练
- 定量分析
- 效果可视化
简要介绍
针对高分辨率的图像,以往有两个独立的改进方式:通过内容感知路加速现有网络、改进token Mixer来设计更好的超分网络。但它们会遇到不可避免的缺陷(例如,content-aware routing和Non-Discriminative Processing),从而限制了质量-复杂性权衡的进一步改进。
为了消除这些缺点,我们提出内容感知混合器 (CAMixer) 来集成这些方案,它为简单的上下文分配卷积,为稀疏纹理分配额外的可变形窗口注意。具体来说,CAMixer 使用可学习的预测器来生成多个 bootstraps,包括用于窗口扭曲的偏移量、用于对窗口进行分类的掩码以及赋予卷积动态属性的卷积注意力,从而调节注意力以自适应地包含更多有用的纹理,并提高卷积的表示能力。进一步引入了全局分类损失,以提高预测变量的准确性。
Content-aware routing: 基于“内容感知路由”(content-aware routing)的方法旨在根据图像不同区域的特征(如复杂度、纹理细节)动态分配计算资源。
Non-Discriminative Processing: 基于“Token Mixer 优化”(如自注意力、动态卷积)的方法通过改进网络中的特征混合机制提升性能。这类方法通常对整张图像或所有区域采用统一处理策略。
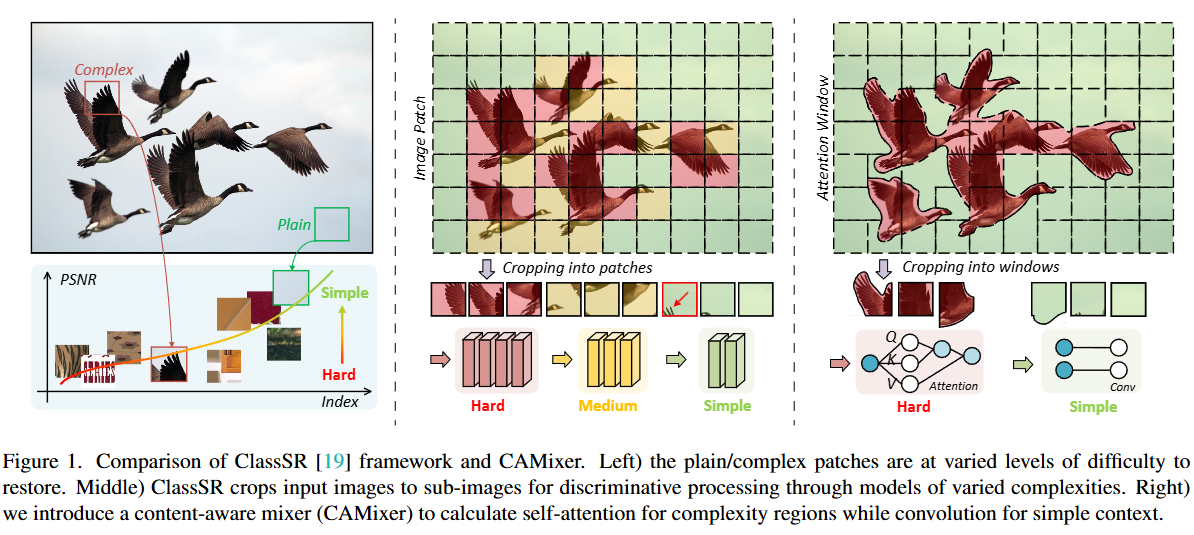
左)普通/复杂的token恢复的难度不同。中间)ClassSR将图像输入到子图像中,以通过各种复杂性模型进行判别处理。右边)我们设计了一个内容感知的混合器(CAMixerSR),以计算复杂区域的Self attention,同时卷积操作用于简单的上下文。
CAMixer
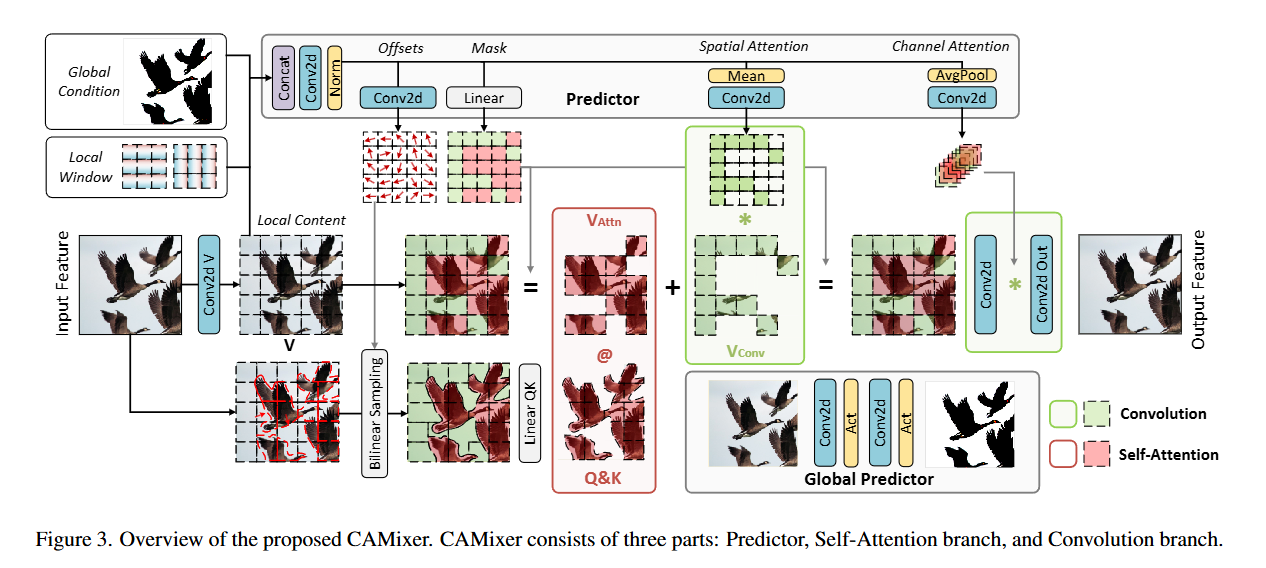
CAMixer主要由三部分组成:Predictor,Attention分支和卷积分支。
输入的特征首先经point-wise卷积投影得到value
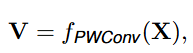
Predictor
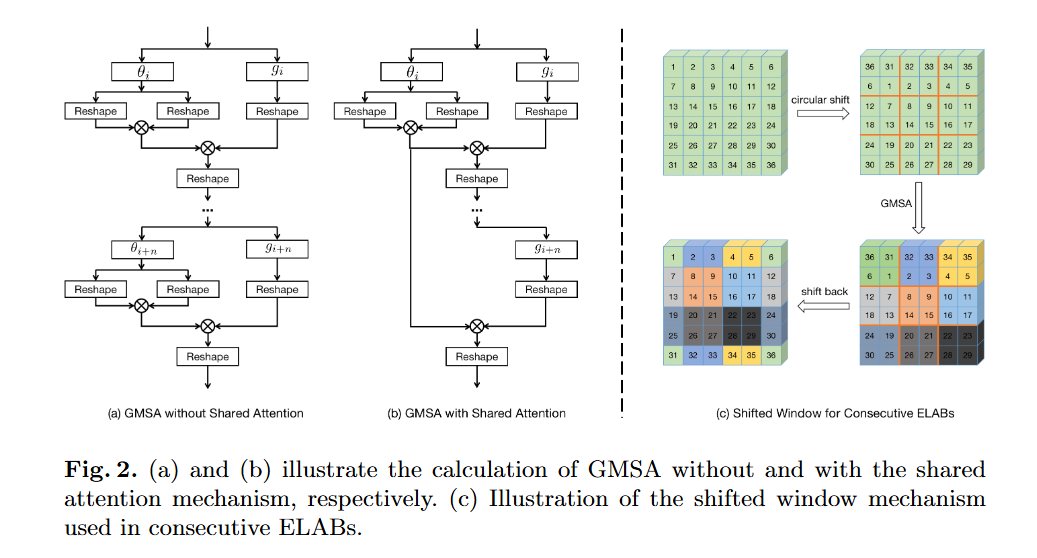
基于局部condition C l = V C_{l} = V Cl=V,全局condition C g ∈ R 2 × H × W C_{g}\in \mathbb{R}^{2×H×W} Cg∈R2×H×W,线性位置编码 C w ∈ R 2 × H × W C_{w}\in \mathbb{R}^{2×H×W} Cw∈R2×H×W,Predictor首先计算共享的中间特征映射 F F F,然后生成偏移量图,再生成简单的空间/通道掩码和简单的空间/通道注意力
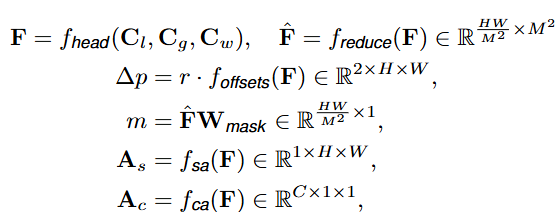
其中 Δ p \Delta p Δp是用于warp具有更复杂结构的窗口与内容相关的偏移矩阵。 r r r是控制偏移范围的标量。 F ^ \hat{F} F^是根据注意力窗口尺寸 M M M的减少重新排列的中间特征。 m m m是决定裁剪窗口由注意力还是卷积计算的mask。 A s A_{s} As和 A c A_{c} Ac是空间和通道attention来增强卷积分支。
Attention
对复杂区域计算空间attention,使用偏移 Δ p \Delta p Δp通过双线性插值 φ ( . ) \varphi (.) φ(.)调节原始输入 X X X,以在所选窗口中包含更多的有用的内容
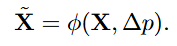
然后重新排列 X ~ , V \tilde{X}, V X~,V根据窗口形状 M × M M×M M×M。在训练阶段,我们使用Gumble Softmax[15,29]来计算二元 mask M = G u m b l e S o f t M a x ( M ) M = Gumble SoftMax(M) M=GumbleSoftMax(M)用于困难和简单的token采样。在推理期间,将mask m m m通过Argsort(m)降序,获得前K个窗口的索引 I h a r d I_{hard} Ihard用于稀疏attention,而其他 I s i m p l e I_{simple} Isimple用于卷积,其中 K = ∑ M K =\sum M K=∑M。
根据索引将 X ~ , V \tilde{X}, V X~,V进行划分
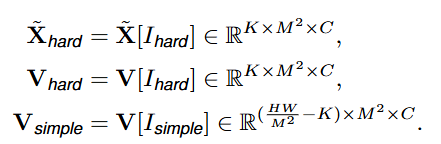
训练阶段:Gumbel Softmax生成二元掩码
Gumble Softmax[15,29]计算二元 mask M = G u m b l e S o f t M a x ( M ) M = Gumble SoftMax(M) M=GumbleSoftMax(M):1. 每个窗口生成重要性分数 2. 添加Gumbel噪声,Softmax与温度退火(确保过程可微)3. 掩码 M 的每个元素表示对应窗口被选中的概率
推理阶段:确定性稀疏注意力选择
固定mask基于训练阶段学习到的重要性得分 m m m通过排序选择关键窗口:1. 降序排列,得到索引序列 argsort(m) 2. 前K个窗口选择处理方式 3. 剩余窗口处理
Q和K通过Linear生成
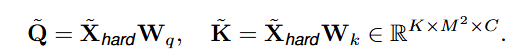
复杂窗口 V h a r d V_{hard} Vhard的Self-attention可以计算
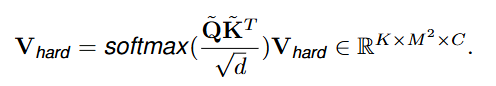
用于轻量操作的 V s i m p l e V_{simple} Vsimple,使用重新排列的 A s A_{s} As通过逐元素乘法实现简单的attention
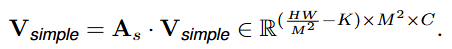
将 V h a r d V_{hard} Vhard和 V s i m p l e V_{simple} Vsimple整合在一起得到attention的分支 V a t t n V_{attn} Vattn
卷积
利用深度可分离卷积和预先生成的通道注意力来捕获局部相关性,可以表示为
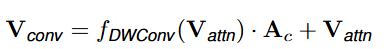
参数量分析

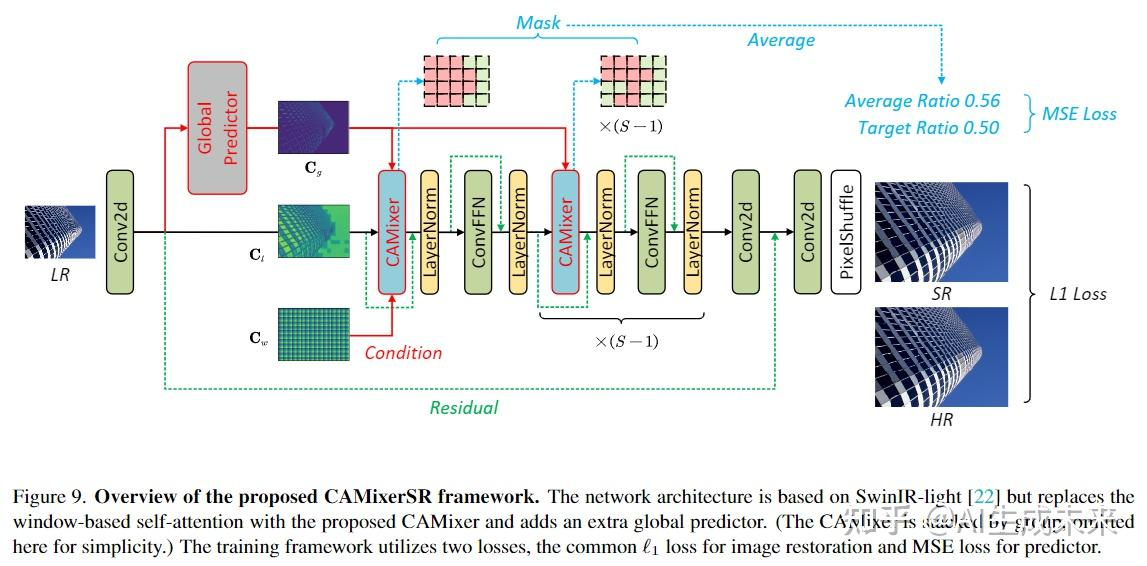
CAMixerSR
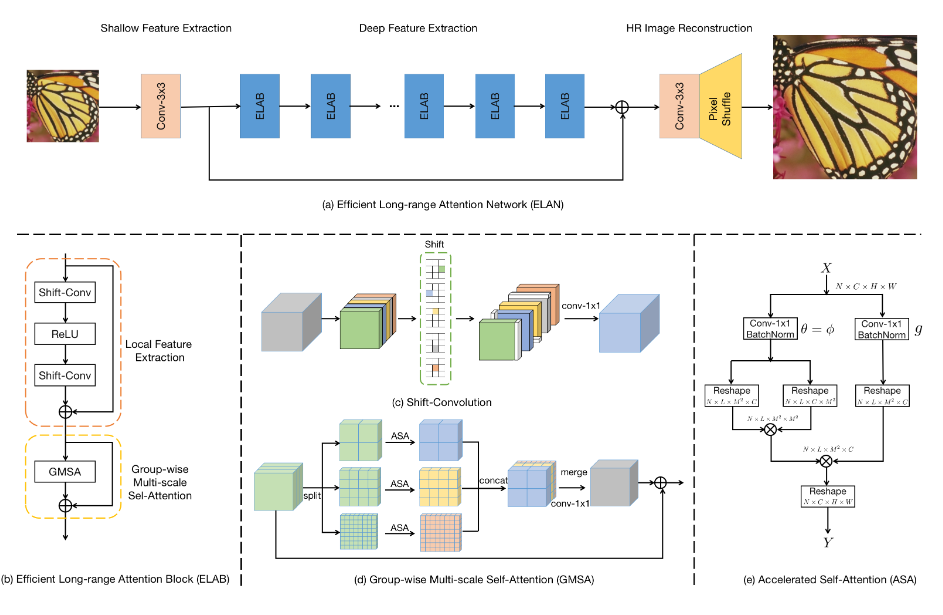
最后,修改Swinir-light [21]来构建camixersr。通常,CamixersR由四个组合组成,三个来自Swinir:浅特征提取器,深度提取器,重建模块以及图3中显示的其他全局预测器模块。
Experiment
CVPR 2024 | CAMixerSR:2K/8K/轻量级/全景图像超分又快又强!(字节&南开)
主要借鉴
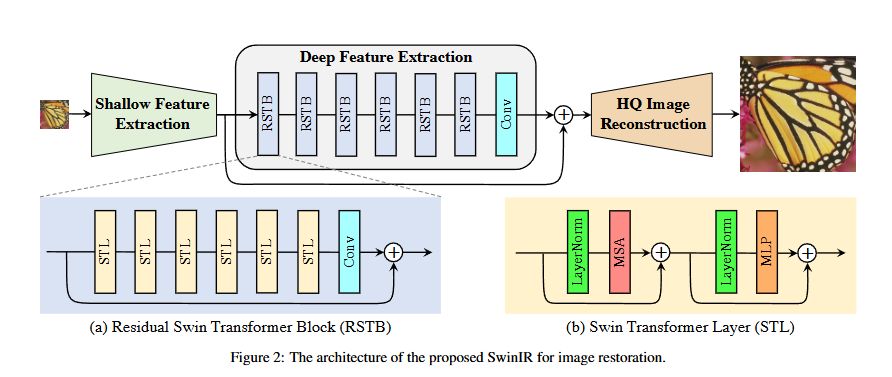
SwinIR [21] and ELAN [42],
SwinIR
ELAN
消融实验
Self-Attention.
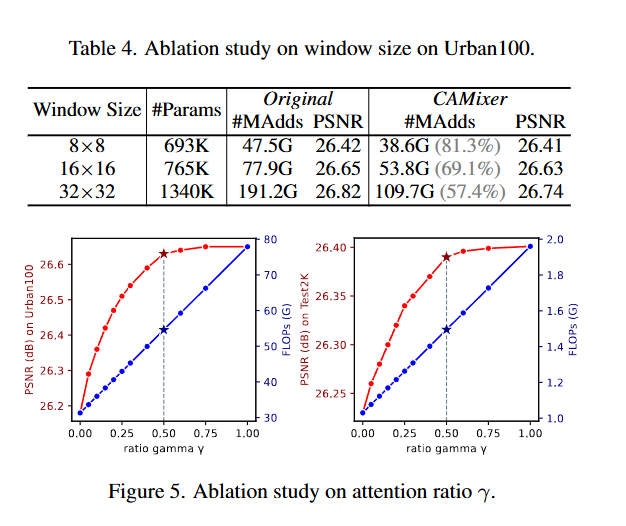
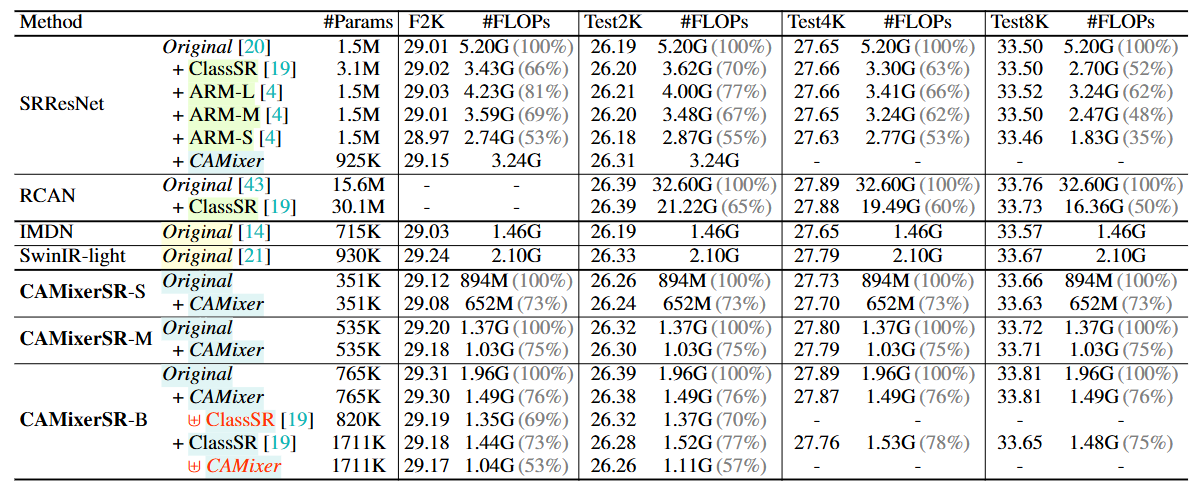
窗口大小为32的模型约为窗口16的2倍,而在Urban100上提升了0.17dB。窗口大小为16的模型比窗口8的模型提升了0.23dB,但只增加了16G MAdds。此外,当将γ设置为0.5时,32×32窗口的性能下降比其他两个模型更大,因为较大的窗口难以分类。因此,我们使用16×16窗口来更好地权衡性能和计算。此外,在下图5中比较了不同的自注意力比率γ。对于轻量级SR和2K SR,计算量呈线性增长,而当γ < 0.5时,PSNR增长更快,但当γ > 0.5时增长较慢。因此,手动选择γ = 0.5,其中PSNR几乎与γ = 1.0相同,但SA的计算量减少了一半。
实验配置
训练
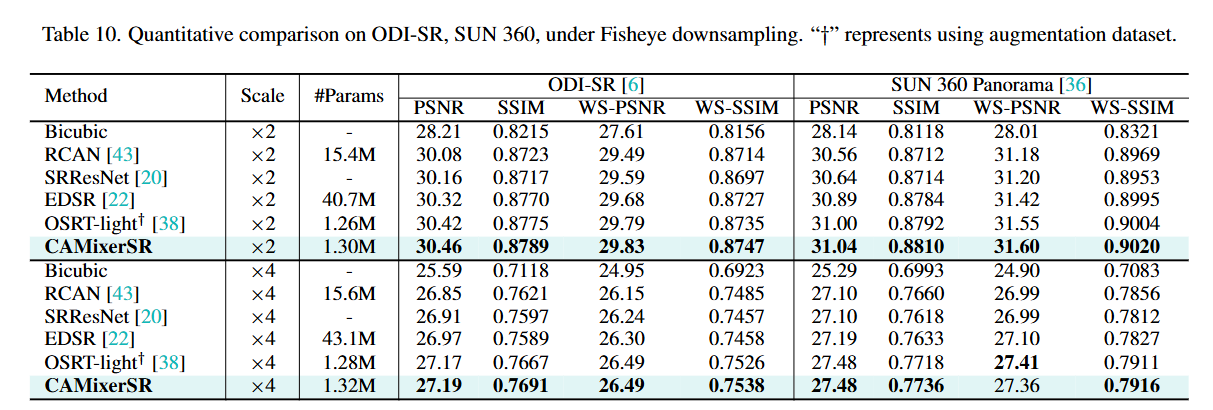
在三个具有挑战性的超分辨率(SR)任务上训练了提出的框架:轻量级SR、大图像SR和全方位图像(ODI)SR。对于前两个任务,使用DIV2K作为训练集。对于ODISR,利用了清理后的ODISR数据集。
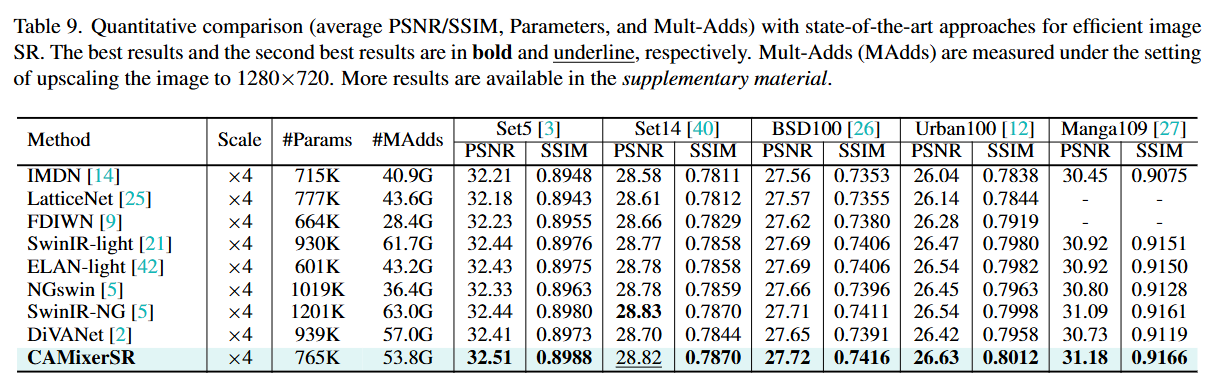
定量分析
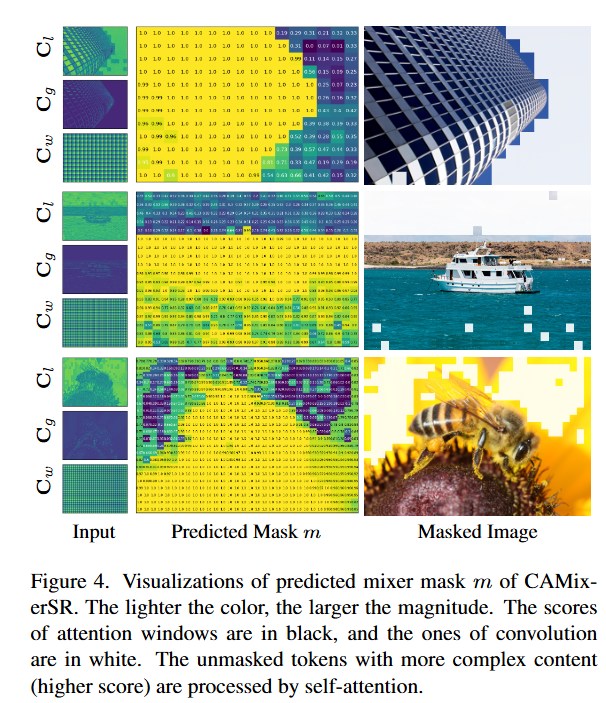
效果可视化
