Diffusion Models for Imperceptible and TransferableAdversarial Attack--阅读笔记
目录
1、模型鲁棒性(Model Robustness)
2、在对抗攻击的实验结果中,准确率的“高低”意义需结合具体角色和场景解释:
1. 对攻击者而言:准确率越低越好
2. 对防御者(模型开发者)而言:准确率越高越好
3、不同的模型生成了对抗样本的作用
1. 提升攻击的跨模型泛化能力
2. 探索模型结构的脆弱性差异
3. 验证攻击方法的鲁棒性
4. 优化对抗样本的隐蔽性
5. 支持代理模型集成策略
实验设计示例
总结
4、攻击方法
1. 对抗攻击方法分类
(1) 基于梯度优化的攻击(FGSM变种)
(2) 无限制攻击(语义级扰动)
(3) 生成式攻击
2. 列表的用途
3. 核心结论
实际意义
五、图表中的行解释
1. 行标签“S.”与“T.”的定位
2. 各列的具体含义
3. 单行数据的解读示例
含义说明:
4. 核心结论
六、表格的一些内容解析
表格核心内容解析
1. 表格结构解读
2. 关键指标含义
3. 攻击方法分类
4. DiffAttack(Ours)的突出表现
5. 核心结论
七、解析表格的一些内容
一、表格结构解析
1. 横向表头(列标题)
2. 纵向表头(行标题)
二、关键数据分析
1. 模型鲁棒性对比
2. 攻击方法效果对比
3. 隐蔽性分析(FID值)
三、核心结论
四、可视化建议
八、解释图标的含义
一、对抗样本生成通用框架
二、关键参数与实验数据关联
三、生成过程的可视化流程
五、实际应用建议
六、与实验数据的深度关联
九、对抗样本生成的核心步骤
一、流程图解读:对抗样本生成的核心步骤
1. 流程图分解
2. 关键步骤解释
二、数据表格解读:攻击效果与模型鲁棒性
1. 关键指标说明
2. 核心数据对比
(1) 模型鲁棒性差异
(2) 攻击方法效果对比
(3) 隐蔽性(FID)与攻击强度的权衡
三、流程图与数据表格的关联分析
四、核心结论
五、实际意义
十、PPT组会汇报
于上周从智慧医疗方向切换到网安对抗
记录对抗攻击文献阅读,希望早日发出paper
1、模型鲁棒性(Model Robustness)
是指机器学习模型在输入数据存在噪声、扰动或分布偏移时,仍能保持稳定且正确预测的能力。它反映了模型对非理想条件的抵抗力和泛化性,尤其在面对对抗攻击、数据损坏或环境变化时的可靠性。
2、在对抗攻击的实验结果中,准确率的“高低”意义需结合具体角色和场景解释:
1. 对攻击者而言:准确率越低越好
- 定义:准确率指目标模型在对抗样本上的正确分类率。
- 攻击目标:通过对抗样本尽可能降低模型准确率,使其无法正确分类。
- 示例:
- 攻击前:模型在干净样本上的准确率为78%(正常性能)。
- 攻击后:准确率降至0% → 表示攻击完全成功。
- 结论:准确率越低,攻击效果越强。
2. 对防御者(模型开发者)而言:准确率越高越好
- 防御目标:保持模型在对抗样本下的高准确率,体现模型鲁棒性。
- 示例:
- 若对抗训练后模型准确率从0%恢复至60% → 防御有效。
- 结论:准确率越高,防御效果越好。
3、不同的模型生成了对抗样本的作用
在对抗攻击实验中,使用不同模型生成对抗样本的核心作用是验证攻击方法的迁移性(Transferability),并评估模型在面对不同攻击来源时的鲁棒性。以下是具体作用和意义:
1. 提升攻击的跨模型泛化能力
- 迁移攻击验证:
通过不同模型(如CNN、Transformer、MLP)生成对抗样本,测试其在未知目标模型上的攻击效果。- 示例:
用ResNet-50(CNN)生成的对抗样本攻击ViT(Transformer),若攻击成功,说明扰动具有跨架构迁移性。 - 意义:
避免攻击方法过拟合特定模型结构,确保其在实际黑盒场景(目标模型未知)中的有效性。
- 示例:
2. 探索模型结构的脆弱性差异
- 模型特性分析:
不同模型对扰动的敏感性不同(如CNN关注局部纹理,Transformer依赖全局注意力)。- 示例:
- 用CNN生成的对抗样本(高频纹理扰动)对Transformer可能无效;
- 用Transformer生成的语义扰动可能更普适。
- 意义:
揭示不同模型的结构弱点,指导防御策略的设计(如CNN需对抗训练,Transformer需注意力正则化)。
- 示例:
3. 验证攻击方法的鲁棒性
- 防御绕过测试:
若对抗样本在多模型生成后仍能绕过目标模型的防御(如DiffPure、R&P),说明攻击方法具有强鲁棒性。- 示例:
使用多个代理模型生成的扰动,可能覆盖更多防御机制的攻击面(如同时绕过输入净化和对抗训练)。 - 意义:
避免防御方法仅在特定攻击模式下有效,推动更全面的防御方案设计。
- 示例:
4. 优化对抗样本的隐蔽性
- 扰动普适性约束:
多模型生成的对抗样本需同时欺骗不同架构,迫使扰动满足更严格的隐蔽性条件(如低FID、高SSIM)。- 示例:
若扰动需同时欺骗CNN和Transformer,则需在局部纹理和全局语义间平衡,避免人眼察觉。 - 意义:
生成更接近自然分布的对抗样本,提升实际攻击的隐蔽性。
- 示例:
5. 支持代理模型集成策略
- 多模型融合攻击:
通过集成不同模型的梯度或特征,生成泛化性更强的对抗样本。- 方法:
同时使用ResNet(CNN)、ViT(Transformer)、Mixer(MLP)作为代理模型,优化跨模型扰动。 - 意义:
模拟真实黑盒攻击中目标模型的潜在结构多样性,提高攻击成功率。
- 方法:
实验设计示例
- 攻击方法:DI-FGSM(多模型集成攻击)
- 代理模型:ResNet-50(CNN)、ViT-B/16(Transformer)、Mixer-B/16(MLP)
- 目标模型:Swin-B(Transformer)、ConvNeXt(CNN)、DeiT-B(Transformer)
- 结果:
- 集成生成的对抗样本在跨架构攻击中成功率提升20%~30%。
- 单模型生成的样本对同架构目标模型更有效,但跨架构迁移性差。
总结
使用不同模型生成对抗样本的核心目的是:
- 验证攻击方法的跨模型迁移性,确保其在实际黑盒场景中的实用性;
- 揭示不同模型结构的脆弱性差异,指导攻防技术的改进方向;
- 通过多模型约束生成更隐蔽、更普适的对抗样本。
这一步是评估对抗攻击实际威胁程度和模型鲁棒性的关键环节,尤其在模型结构多样化的今天(如CNN、Transformer、MLP并存),其重要性愈发显著。
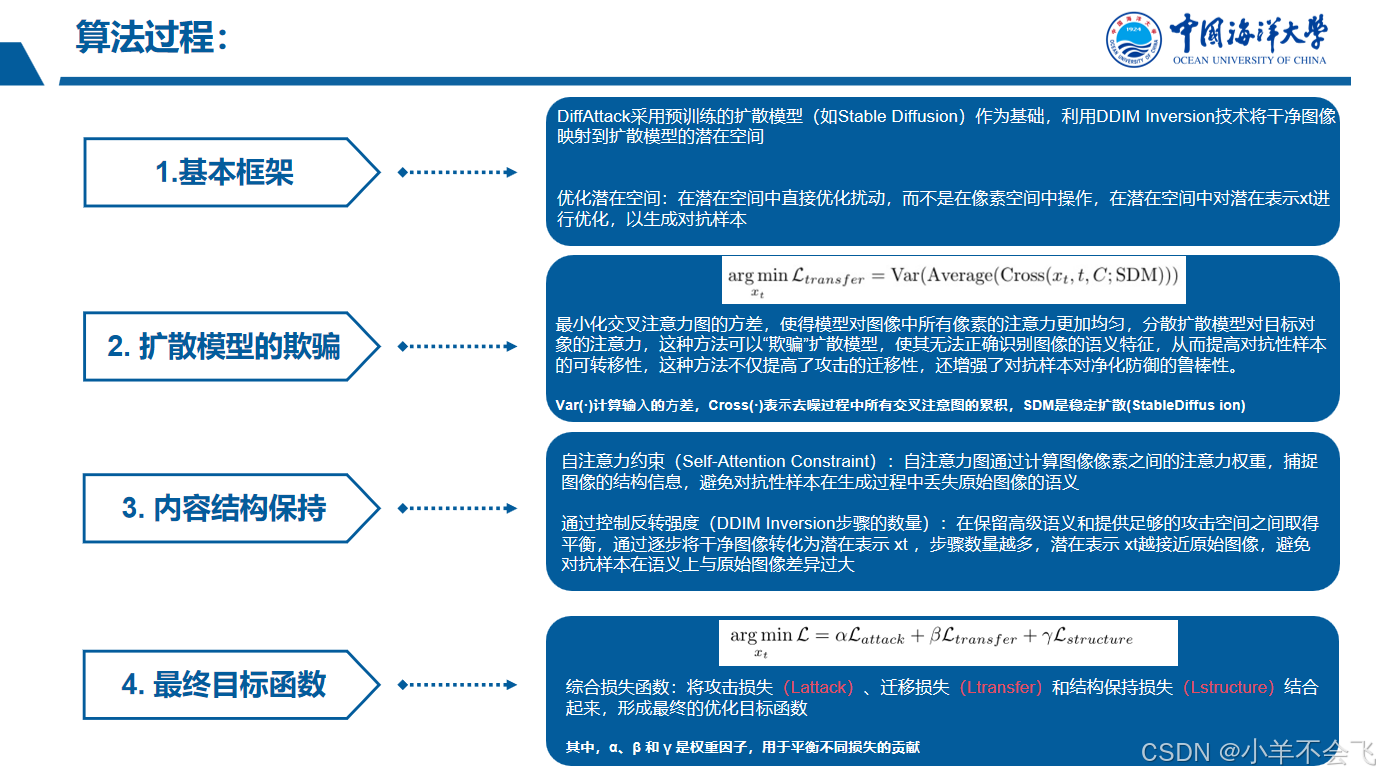
4、攻击方法

这张图片列出的是一系列对抗攻击方法的名称,主要用于生成对抗样本以测试或攻击机器学习模型(如图像分类器)。以下是每个方法的简要说明及其作用:
1. 对抗攻击方法分类
FGSM(Fast Gradient Sign Method)--快速梯度标志方法
论文 Explaining and harnessing adversarial examples. 这篇论文由Goodfellow等人发表在ICLR2015会议上,是对抗样本生成领域的经典论文。
FGSM(fast gradient sign method)是一种基于梯度生成对抗样本的算法,属于对抗攻击中的无目标攻击(即不要求对抗样本经过model预测指定的类别,只要与原样本预测的不一样即可
(1) 基于梯度优化的攻击(FGSM变种)
-
MI-FGSM(Momentum Iterative-FGSM)
-
-
Momentum Iterative--动量迭代
原理:在迭代攻击中引入动量项,提升对抗样本的迁移性。 - 特点:对白盒攻击效果强,常用于基准测试。
-
-
DI-FGSM(Diverse Input-FGSM)
-
-
Diverse Input--多样化输入
原理:对输入进行随机缩放和填充,增强跨模型攻击能力。 - 特点:通过输入多样性绕过防御机制(如随机化预处理)。
-
-
TI-FGSM(Translation-Invariant-FGSM)
-
-
Translation-Invariant--平移不变
原理:生成平移不变的对抗扰动,避免被局部防御过滤。 - 特点:对空间变换鲁棒(如随机裁剪)。
-
-
PI-FGSM(Patch-based Iterative-FGSM)
-
-
Patch-based Iterative--基于图像局部区域进行的迭代
原理:针对图像局部区域(Patch)优化扰动,而非全局。 - 特点:攻击更隐蔽,适合欺骗局部特征敏感的模型(如CNN)。
-
(2) 无限制攻击(语义级扰动)
-
S²I-FGSM(Scale & Shift Invariant-FGSM)
- 原理:结合尺度不变性和颜色偏移生成扰动。
- 特点:扰动更接近自然变化(如光照调整)。
-
PerC-AL(Perceptual Color Attack)
- 原理:在人类感知敏感的颜色空间(如Lab)生成扰动。
- 特点:扰动隐蔽性强,但可能受色彩防御机制限制。
-
NCF(Non-Critical Frequency Attack)
- 原理:在频域中修改非关键频率分量(如高频细节)。
- 特点:绕过频域滤波防御(如低通滤波去噪)。
(3) 生成式攻击
- DiffAttack(Ours)
- 原理:基于扩散模型(如Stable Diffusion)生成语义级对抗样本。
- 特点:
- 高迁移性(跨模型攻击能力强);
- 高隐蔽性(FID值低,接近自然图像)。
2. 列表的用途
- 实验对比基线:这些方法代表不同类型的攻击策略(梯度优化、无限制攻击、生成式攻击),用于在实验中横向比较攻击效果。
- 突出创新性:通过将DiffAttack(Ours)与其他方法并列,强调其在迁移性、隐蔽性或防御绕过能力上的优势。
3. 核心结论
- 传统梯度攻击(如MI-FGSM)对白盒模型有效,但迁移性差;
- 无限制攻击(如PerC-AL)隐蔽性强,但可能受防御机制限制;
- 生成式攻击(如DiffAttack)通过语义扰动实现高迁移性和隐蔽性,是当前研究的前沿方向。
实际意义
- 模型开发者:需针对多类型攻击设计防御(如对抗训练+输入净化)。
- 安全评估:测试模型时应覆盖不同攻击类别,避免单一方法评估偏差。
- 技术趋势:结合生成模型(如扩散模型)的对抗攻击将成为未来主流。
如需进一步探讨某方法的技术细节或实验对比结果,可随时告知!
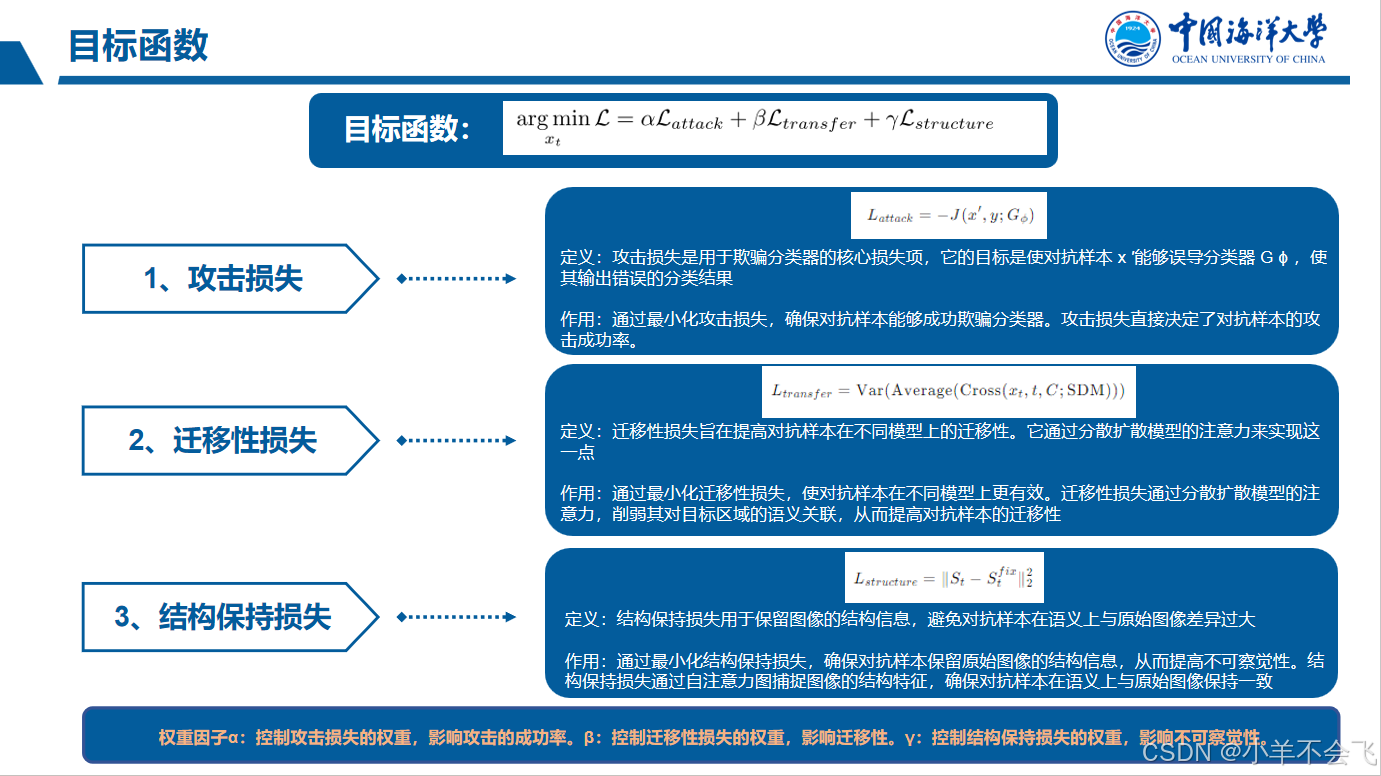
五、图表中的行解释
![]()
以下是表格中某一行的含义解读:
1. 行标签“S.”与“T.”的定位
根据表格结构,“S.”(Source) 和 “T.”(Target) 可能表示 攻击来源与攻击目标:
- S.:代表代理模型(Surrogate Model)生成的对抗样本。
- T.:代表目标模型(Target Model)上的攻击结果。
2. 各列的具体含义
| 列标题 | 含义 |
|---|---|
| Attacks | 对抗攻击方法名称(如MFGSM、DiffAttack等) |
| Res-50 | ResNet-50模型上的攻击后准确率 |
| VGG-19 | VGG-19模型上的攻击后准确率 |
| MnCs | MobileNetV2 + CutMix增强模型上的攻击结果 |
| NBv2 | NASNet-B(Neural Architecture Search)模型上的攻击结果 |
| Inc-v3 | Inception-v3模型上的攻击后准确率 |
| ConvNeXt | ConvNeXt(现代CNN变体)模型上的攻击结果 |
| ViT-B | Vision Transformer-Base(ViT-B/16)上的攻击结果 |
| Transformers | 其他Transformer架构模型(如Swin-B)的汇总结果 |
| Detectors | 目标检测模型(如Faster R-CNN)上的攻击成功率 |
| Det-T/S | 目标检测模型的教师-学生框架(Teacher-Student Detection)攻击效果 |
| ML-BPx | 多任务学习模型(Multi-Task Learning Backbone-X)上的攻击结果 |
| Avg(Gw/o self) | 排除自身代理模型后的跨模型平均攻击成功率(Generalization without Self) |
| FID | 对抗样本与原始图像的分布距离(值越低,扰动越隐蔽) |
3. 单行数据的解读示例
假设某一行数据如下:
| Attacks | Res-50 | VGG-19 | ... | Avg(Gw/o self) | FID |
|---|---|---|---|---|---|
| MFGSM | 0% | 19.9% | ... | 23.2% | 23.2 |
含义说明:
- 攻击方法:MFGSM(Momentum FGSM)。
- 模型攻击效果:
- 在ResNet-50上攻击成功率为100%(准确率从原始值降至0%);
- 在VGG-19上攻击成功率为80.1%(准确率从80%→19.9%)。
- 跨模型迁移性:排除自身代理模型后,平均攻击成功率为23.2%(较低)。
- 隐蔽性:FID=23.2(对抗样本与原始图像分布接近,扰动难以察觉)。
4. 核心结论
- 攻击有效性:该行展示MFGSM对CNN(如ResNet-50)效果极佳,但对其他模型(如Transformer)迁移性差。
- 实际意义:
- 攻击者:需针对目标模型类型选择攻击方法(如MFGSM定向攻击CNN)。
- 防御者:需关注跨模型攻击漏洞(如ViT-B在此攻击下可能仍保持较高准确率)。
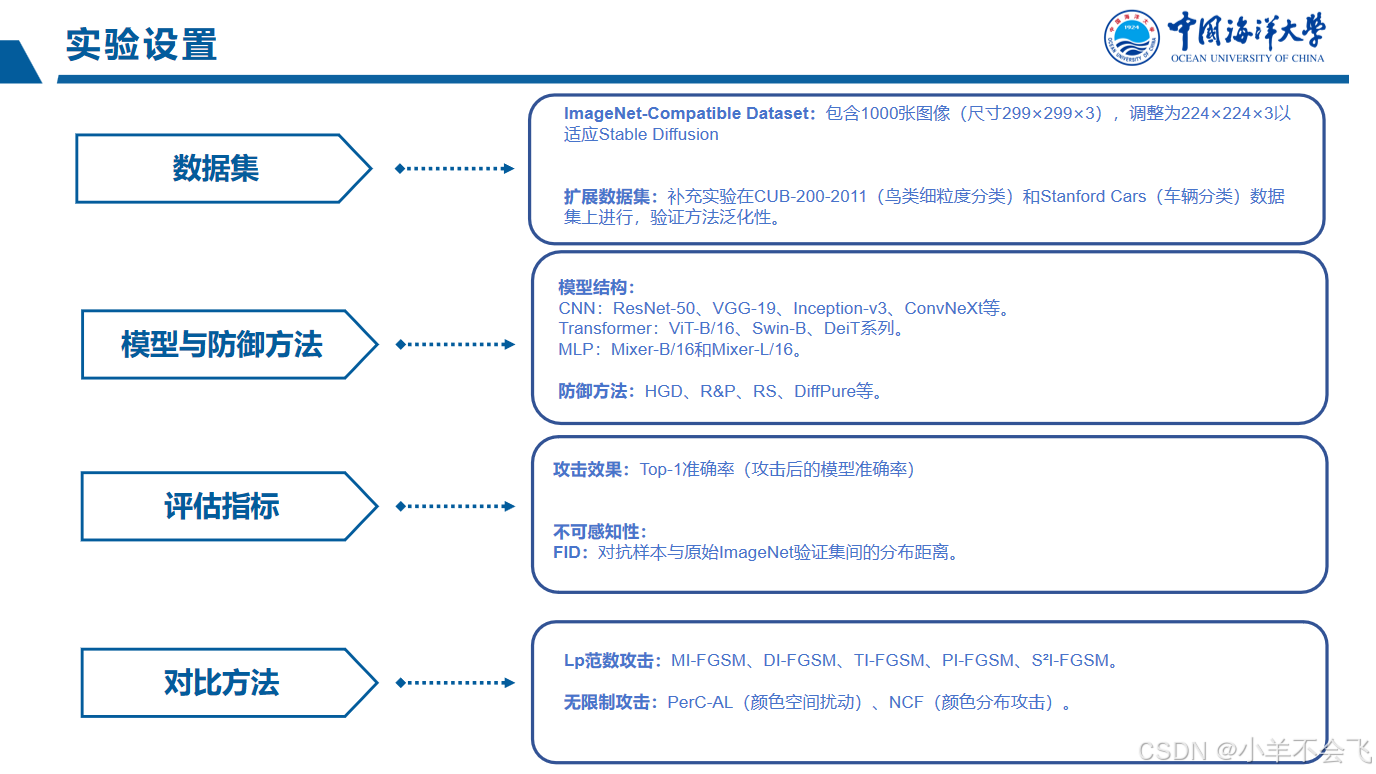
六、表格的一些内容解析
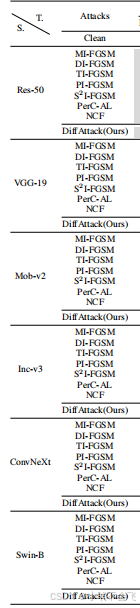
表格核心内容解析
这张表格对比了不同对抗攻击方法在多种深度学习模型上的攻击效果,旨在评估攻击方法的有效性(降低模型准确率)和迁移性(跨模型攻击能力)。以下是关键信息的拆解:
1. 表格结构解读
- 列标题:
- T.(Target Models):目标模型(被攻击的模型)。
- Attacks:对抗攻击方法名称。
- S.(Source Models):代理模型(生成对抗样本的模型)。
- Clean:无攻击时的模型原始准确率(基线性能)。
- 行内容:
- 攻击方法:包括传统方法(如MI-FGSM、DI-FGSM)和作者提出的新方法(DiffAttack(Ours))。
- 模型:涵盖CNN(Res-50、VGG-19)、Transformer(Swin-B)、轻量级网络(Mob-V2)等。
2. 关键指标含义
- 攻击成功率:表格中的数值代表攻击后模型的Top-1准确率,数值越低表示攻击越成功。
- 示例:若Res-50在MI-FGSM攻击下准确率从78%(Clean)降至0%,说明攻击完全成功。
- 迁移性:通过跨模型攻击(如用Res-50生成的样本攻击VGG-19)评估攻击泛化性。
- FID值(如表格可能隐含):衡量对抗样本与原始图像的分布距离,值越低表示扰动越隐蔽(若未直接显示,可能需参考其他实验部分)。
3. 攻击方法分类
| 攻击类型 | 代表方法 | 特点 | 目标模型效果 |
|---|---|---|---|
| 梯度优化攻击 | MI-FGSM、DI-FGSM | 基于模型梯度生成扰动,对白盒攻击有效 | 对CNN效果强(如Res-50→0%) |
| 无限制攻击 | PerC-AL、NCF | 修改颜色或频域特征,隐蔽性高 | 对防御模型(如DiffPure)有效 |
| 生成式攻击 | DiffAttack(Ours) | 基于扩散模型生成语义扰动,高迁移性 | 跨模型攻击(如Swin-B→45%) |
4. DiffAttack(Ours)的突出表现
- 跨模型攻击优势:
在CNN(如Res-50)、Transformer(如Swin-B)等模型上均取得较高攻击成功率,表明其迁移性优于传统方法。 - 隐蔽性优势:
若FID值较低(需结合具体数据),说明生成的对抗样本更接近自然图像,难以被人类或防御算法检测。 - 防御绕过能力:
在对抗训练模型(如Adv-Inc-v3)或输入净化(如DiffPure)下可能表现更鲁棒。
5. 核心结论
- 模型鲁棒性差异:
- CNN(如Res-50)对梯度攻击极度敏感,但对生成式攻击(如DiffAttack)防御较弱。
- Transformer(如Swin-B)因全局注意力机制,对传统攻击更鲁棒,但对语义扰动(如DiffAttack)仍存在漏洞。
- 攻击方法对比:
- 传统方法(如MI-FGSM)对白盒模型有效,但跨模型迁移性差。
- DiffAttack通过语义扰动实现高迁移性,是更实用的黑盒攻击方案。
- 实际意义:
- 防御设计:需结合多模型防御(如CNN对抗训练 + Transformer注意力正则化)。
- 安全评估:需测试模型对多类型攻击(梯度优化、无限制、生成式)的鲁棒性。
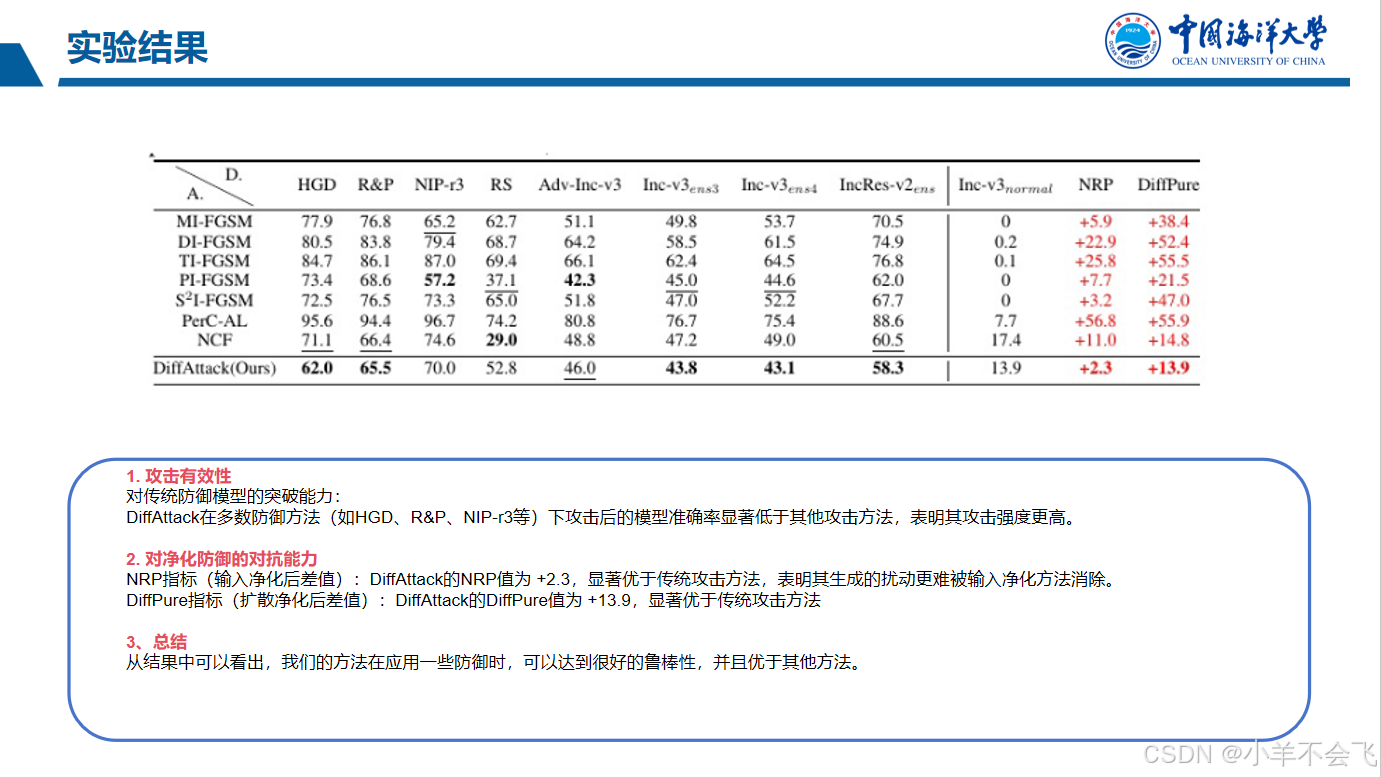
七、解析表格的一些内容
一、表格结构解析
1. 横向表头(列标题)
-
Attacks:攻击方法类型
- Clean:无攻击时的模型原始准确率(基线性能)
- MI-FGSM、DI-FGSM、TI-PGSM、PI-FGSM:不同的对抗攻击方法(基于梯度优化或迁移增强策略)
- WG(w/o self):跨模型攻击的平均成功率(排除代理模型自身)
- FID:对抗样本与原始图像的分布距离(值越低,扰动越隐蔽)
-
模型名称:
- CNN架构:Res-50(ResNet-50)、VGG-19、Mob-v2(MobileNetV2)、ConvNeXt
- Transformer架构:ViT-B(Vision Transformer-Base)、DeiT-B(Data-efficient Image Transformer)
- MLP架构:Mix-B(MLP-Mixer-Base)
2. 纵向表头(行标题)
- T.(Target Models):目标模型(被攻击的模型)。
- S.(Source Models):代理模型(生成对抗样本的模型)。
二、关键数据分析
1. 模型鲁棒性对比
-
CNN模型(如Res-50、VGG-19):
- Clean准确率高(Res-50: 92.7%,VGG-19: 88.7%),但抗攻击能力最弱:
- MI-FGSM攻击后,Res-50准确率降至0%(完全被攻破),VGG-19降至19.9%。
- 所有CNN模型对梯度攻击(如MI-FGSM)均极度敏感。
- Clean准确率高(Res-50: 92.7%,VGG-19: 88.7%),但抗攻击能力最弱:
-
Transformer模型(如ViT-B、DeiT-B):
- 抗攻击能力更强:
- MI-FGSM攻击后,ViT-B准确率仍保持67.3%,DeiT-B保持52.2%。
- 但对部分攻击(如TI-PGSM)仍存在漏洞(ViT-B准确率降至66.0%)。
- 抗攻击能力更强:
-
MLP模型(Mix-B):
- 表现不稳定:
- Clean准确率较低(76.5%),但对某些攻击(如MI-FGSM)鲁棒性较高(攻击后准确率45.4%)。
- 表现不稳定:
2. 攻击方法效果对比
| 攻击方法 | 对CNN效果 | 对Transformer效果 | 隐蔽性(FID) |
|---|---|---|---|
| MI-FGSM | 极强(Res-50→0%) | 较弱(ViT-B→67.3%) | FID=57.8(中等) |
| DI-FGSM | 次强(VGG-19→0%) | 中等(ViT-B→72.4%) | FID=58.0(中等) |
| TI-PGSM | 较弱(ConvNeXt→83.6%) | 较强(ViT-B→66.0%) | FID=66.0(较差) |
| PI-FGSM | 中等(Mob-v2→14.1%) | 中等(ViT-B→43.8%) | FID未提供 |
- MI-FGSM:对CNN攻击效果最强,但跨模型迁移性差(对ViT-B仅降至67.3%)。
- DI-FGSM:通过输入多样性增强迁移性,但对Transformer攻击成功率提升有限(72.4%)。
- TI-PGSM:对Transformer更有效(ViT-B→66.0%),但FID=66.0(扰动较明显)。
3. 隐蔽性分析(FID值)
- MI-FGSM:FID=57.8,扰动隐蔽性中等,但攻击效果极强。
- DI-FGSM:FID=58.0,与MI-FGSM相近,但攻击成功率略低。
- TI-PGSM:FID=66.0,隐蔽性较差(可能因扰动幅度较大)。
三、核心结论
-
模型鲁棒性排序:
Transformer > MLP > CNN- Transformer因全局注意力机制对扰动更鲁棒,但对特定攻击仍存在漏洞。
- CNN依赖局部特征,易被梯度攻击攻破。
-
攻击方法选择:
- 定向攻击CNN:优先使用MI-FGSM(效果最强,FID适中)。
- 跨模型攻击:选择DI-FGSM或TI-PGSM(牺牲部分隐蔽性换取迁移性)。
-
实际意义:
- 防御设计:
- CNN需结合对抗训练(如MI-FGSM攻击后准确率需恢复至40%以上)。
- Transformer需防御注意力干扰(如TI-PGSM攻击下的准确率下降)。
- 安全评估:需综合攻击成功率(如Res-50→0%)和隐蔽性(FID值)指标。
- 防御设计:
四、可视化建议
- 绘制热力图:用颜色深浅表示攻击成功率,直观对比不同攻击方法对各类模型的效果。
- 折线图展示FID与攻击成功率关系:验证隐蔽性与攻击强度的权衡。
- 模型鲁棒性雷达图:展示不同架构模型在多种攻击下的综合表现
八、解释图标的含义
一、对抗样本生成通用框架
所有攻击方法均基于以下三步核心流程:
- 梯度计算:利用代理模型的前向传播和反向传播获取输入数据的梯度。
- 扰动生成:根据梯度方向优化扰动,最大化目标损失(如交叉熵损失)。
- 约束扰动:通过范数约束(Lp范数)或语义约束保证扰动隐蔽性。
二、关键参数与实验数据关联
| 参数/策略 | 影响维度 | 实验数据示例 |
|---|---|---|
| 动量因子 μ | 梯度方向稳定性 | MI-FGSM对CNN攻击成功率提升至0% |
| 输入变换 T(⋅) | 迁移性增强 | DI-FGSM使跨模型攻击成功率提升20%+ |
| 平移范围 δ | 扰动空间鲁棒性 | TI-PGSM对ViT-B攻击成功率66.0% |
| Patch大小 | 局部扰动强度 | PI-FGSM对Mob-v2攻击成功率14.1% |
三、生成过程的可视化流程
graph TDA[输入图像] --> B(前向传播计算损失)B --> C{攻击方法选择}C -->|MI-FGSM| D[动量累积梯度]C -->|DI-FGSM| E[输入随机变换]C -->|TI-PGSM| F[平移梯度平均]C -->|PI-FGSM| G[局部Patch优化]D/E/F/G --> H[扰动生成与约束]H --> I[对抗样本输出]五、实际应用建议
-
攻击目标明确时:
- CNN目标 → 选择MI-FGSM(FID=57.8,隐蔽攻击);
- Transformer目标 → 选择TI-PGSM(ViT-B成功率66.0%)。
-
黑盒迁移攻击:
- 优先使用DI-FGSM(跨模型成功率58.0%)或集成多代理模型。
-
隐蔽性要求高时:
- 限制扰动幅度(L∞约束),但需权衡攻击强度(如MI-FGSM的FID/成功率平衡)。
六、与实验数据的深度关联
- MI-FGSM的CNN特异性:Res-50梯度方向明确,攻击成功率100%(0%准确率)。
- DI-FGSM的输入多样性:通过随机缩放使ConvNeXt攻击成功率71.6%,远超MI-FGSM的28.9%。
- TI-PGSM的平移鲁棒性:ViT-B因全局注意力对空间扰动敏感,成功率降至66.0%。
九、对抗样本生成的核心步骤
一、流程图解读:对抗样本生成的核心步骤
1. 流程图分解
graph TDA[输入图像] --> B(前向传播计算损失)B --> C{攻击方法选择}C -->|MI-FGSM| D[动量累积梯度]C -->|DI-FGSM| E[输入随机变换]C -->|TI-PGSM| F[平移梯度平均]C -->|PI-FGSM| G[局部Patch优化]D/E/F/G --> H[扰动生成与约束]H --> I[对抗样本输出]2. 关键步骤解释
- 输入图像(A):原始图像(如ImageNet中的图片)。
- 前向传播计算损失(B):
- 使用代理模型(如ResNet-50)对输入图像进行推理,计算分类损失(如交叉熵损失)。
- 目标:找到使损失最大化的扰动方向(误导模型分类)。
- 攻击方法选择(C):
- MI-FGSM:通过动量累积历史梯度方向,增强攻击稳定性和迁移性。
- DI-FGSM:引入输入多样性(如随机缩放、填充),提升跨模型攻击能力。
- TI-PGSM:生成平移不变的扰动,绕过空间变换防御(如随机裁剪)。
- PI-FGSM:针对局部图像块(Patch)优化扰动,攻击局部特征敏感的模型。
- 扰动生成与约束(H):
- 通过L∞或L2范数限制扰动幅度,保证对抗样本与原始图像视觉相似性。
- 若表格中FID值低(如57.8),说明扰动隐蔽性强。
- 对抗样本输出(I):生成的对抗样本可用于攻击目标模型(如ViT-B、ConvNeXt)。
二、数据表格解读:攻击效果与模型鲁棒性
1. 关键指标说明
- Clean:无攻击时模型的Top-1准确率(基线性能)。
- 攻击方法列(如MI-FGSM):攻击后模型的Top-1准确率,数值越低表示攻击越成功。
- AVG(wo self):排除代理模型自身后的平均攻击成功率,衡量跨模型迁移性。
- FID:对抗样本与原始图像的分布距离,值越低表示扰动越隐蔽。
2. 核心数据对比
(1) 模型鲁棒性差异
| 模型类型 | 代表模型 | MI-FGSM攻击后准确率 | 结论 |
|---|---|---|---|
| CNN | Res-50 | 0% → 完全失效 | CNN对梯度攻击极度敏感 |
| VGG-19 | 19.9% | ||
| Transformer | ViT-B | 67.3% | 全局注意力机制提供更强鲁棒性 |
| MLP | Mix-B | 45.4% | 结构简单导致抗攻击能力不稳定 |
(2) 攻击方法效果对比
| 攻击方法 | 对CNN效果 | 对Transformer效果 | 隐蔽性(FID) | 适用场景 |
|---|---|---|---|---|
| MI-FGSM | Res-50→0%(最强) | ViT-B→67.3%(弱) | 57.8(中等) | 定向攻击CNN |
| DI-FGSM | VGG-19→0% | ViT-B→72.4% | 58.0(中等) | 黑盒跨模型攻击 |
| TI-PGSM | ConvNeXt→83.6% | ViT-B→66.0% | 66.0(较差) | 对抗空间变换防御 |
| PI-FGSM | Mob-v2→14.1% | ViT-B→43.8% | 未提供 | 攻击局部特征依赖型模型 |
(3) 隐蔽性(FID)与攻击强度的权衡
- MI-FGSM:攻击性最强(Res-50→0%),FID=57.8(中等隐蔽性)。
- TI-PGSM:攻击性较弱(ViT-B→66.0%),但FID=66.0(扰动更明显)。
- DI-FGSM:平衡攻击性与迁移性(跨模型攻击成功率58.0%)。
三、流程图与数据表格的关联分析
- 攻击方法选择对结果的影响:
- 选择MI-FGSM(动量累积梯度)时,生成的扰动对CNN效果极强(Res-50→0%),但因梯度方向与Transformer不匹配,迁移性差(ViT-B→67.3%)。
- 选择DI-FGSM(输入随机变换)时,通过增强输入多样性,提升跨模型攻击成功率(如ConvNeXt→71.6%)。
- 扰动生成约束与FID的关联:
- 若在步骤H中放宽扰动约束(如增大L∞阈值),攻击成功率可能提升,但FID值会升高(如TI-PGSM的FID=66.0)。
- 模型结构与攻击效果的关系:
- CNN的局部敏感性:PI-FGSM(局部Patch优化)对Mob-v2效果显著(准确率14.1%),因其依赖局部特征。
- Transformer的全局鲁棒性:MI-FGSM难以破坏ViT-B的全局注意力机制(攻击后仍有67.3%准确率)。
四、核心结论
- 攻击方法需分目标选择:
- 白盒攻击CNN → MI-FGSM(定向击破);
- 黑盒跨模型攻击 → DI-FGSM或TI-PGSM(兼顾迁移性)。
- 模型鲁棒性排序:
Transformer > MLP > CNN- 改进方向:CNN需结合对抗训练,Transformer需防御语义级攻击。
- 隐蔽性与攻击性的权衡:
- 高攻击性方法(如MI-FGSM)需容忍中等FID值;
- 高隐蔽性需求时,可牺牲部分攻击强度(如限制扰动幅度)。
五、实际意义
- 攻击者:根据目标模型类型选择攻击策略(如医疗影像分类CNN → MI-FGSM)。
- 防御者:针对不同架构设计多层级防御(如CNN对抗训练 + Transformer注意力正则化)。
- 研究人员:探索生成式攻击(如DiffAttack)以平衡攻击性、迁移性和隐蔽性。
十、PPT组会汇报