【面试向】梯度消失和梯度爆炸,激活函数?权重初始化?归一化?
- 梯度爆炸 & 梯度消失
- 梯度爆炸
- 梯度消失
- 激活函数
- Sigmoid
- Sigmoid 函数的性质
- Sigmoid 函数在反向传播中的应用
- Sigmoid 函数的导数
- Sigmoid 函数在反向传播中的问题
- Tanh 函数
- ReLU 函数
- Leaky ReLU & Parametric ReLU (PReLU)
- Exponential Linear (ELU, SELU)
- 权重初始化方法
- Xavier 初始化(Glorot 初始化)—— Sigmoid 或 Tanh
- He 初始化(Kaiming 初始化)
- 归一化(Normalization)
- 常见的归一化方法
- BatchNorm(Batch Normalization)和 LayerNorm(Layer Normalization)
参考 Understanding Vanishing and Exploding Gradients in Deep Learning
参考 Vanishing Gradient Problem in Deep Learning: Understanding, Intuition, and Solutions
参考 A Practical Guide to ReLU
深度学习的成功归功于其能够从大量数据中自动学习复杂模式,而无需显式编程。基于梯度的优化,依赖于反向传播,是训练深度神经网络(DNN)的主要技术。
梯度爆炸 & 梯度消失
梯度下降 是一种优化方法,通过迭代修改其参数(如权重和偏置)来减少神经网络的误差或损失函数。在训练过程中,反向传播计算损失函数相对于这些权重的梯度,指示每个权重应如何修改以减少误差。
总结: 物无美恶,过则成灾
- 梯度消失 通过使 梯度变得极小 来阻碍训练过程,导致收敛速度变慢甚至停滞。
- 梯度爆炸 则通过使 梯度无限制增长 来破坏训练的稳定性,导致数值不稳定性并导致发散。

梯度爆炸
梯度爆炸 发生在反向传播过程中 梯度变得过大,导致训练不稳定和优化过程的可能发散。
假设我们有一个 CNN 架构,包含许多卷积层,后面跟着全连接层。在训练过程中,梯度根据损失函数生成,并通过网络反向传播以更新权重,使用梯度下降法进行更新。
- 网络权重初始化不良:如果网络的权重随机设置且过大,激活和梯度在通过层传播时可能会爆发。
- 高学习率:过高的学习率可能导致权重更新过大,从而引发梯度爆炸。
反向传播时,梯度的计算可能会因为 多次链式乘积,导致梯度值逐层增大。梯度过大时,会导致 权重更新过快,网络的训练变得非常不稳定,甚至可能导致 NaN 值的出现。
为了解决梯度爆炸的问题,可以实施 梯度裁剪(Gradient Clipping)、权重正则化和采用降低的学习率 等策略。这些策略 有助于稳定训练过程,防止梯度变得过大,从而实现更有效的优化和改进模型性能。
- 梯度裁剪(Gradient Clipping) :通过对梯度的大小进行限制,防止梯度值超过设定的阈值。这能有效防止梯度爆炸,使得训练过程更加稳定。
- 权重初始化方法:使用合适的权重初始化方法,如 Xavier 初始化或 He 初始化,可以减少梯度爆炸的发生。
梯度消失
假设你有一个包含十个层的深度神经网络,每个层都使用 sigmoid 激活函数。在训练过程中,梯度从输出层反向传播到输入层,经过每一层的 sigmoid 激活函数。sigmoid 函数的导数范围在 0 到 0.25 之间,其最高值位于输入范围的中间。当梯度通过每一层 sigmoid 时,它们可以减少高达 0.25,尤其是当权重接近 1 时。
因此,到达较早期层的梯度可能变得极其小,接近零。结果,这些层的权重变化微乎其微,导致学习过程缓慢或无法进行。这种现象被称为梯度消失。
梯度消失问题 是指在深度神经网络训练过程中 梯度逐渐减小 的问题。当反向传播过程中通过层的梯度变得非常小,使得网络 难以有效地更新权重。
梯度消失问题主要发生在深度神经网络中,特别是在使用 Sigmoid 或 Tanh 激活函数时。梯度消失问题是由于 反向传播中的链式法则 和 激活函数的选择 引起的:
- 在 反向传播 过程中,梯度是通过链式法则传递的。
- 每一层的梯度与该层的激活函数的导数有关。如果 激活函数的导数小于1(如 Sigmoid 或 Tanh 函数的导数最大值分别为 0.25 和 1),那么随着网络层数的加深,梯度在反向传播过程中会逐层变小。
- 由于梯度逐渐变小,网络的前面几层 (尤其是靠近输入层的层)几乎收不到有效的梯度更新,导致这些层的权重无法有效更新,训练进展缓慢,甚至可能完全停滞。
激活函数,如 Sigmoid 和双曲正切函数 tanh,负责将非线性引入 DNN 模型。然而,这些函数存在 饱和问题,即对于大或小的输入,梯度接近于零,这加剧了梯度消失问题。反向传播(Backpropagation)通过链式法则计算损失函数相对于权重的梯度,通过乘以这些小的梯度而加剧了这个问题。
可以通过选取更好的激活函数、批量归一化、权重初始化和 ResNet 来缓解梯度消失问题,
- ReLU(Rectified Linear Unit)激活函数在正值区域的梯度为常数1,避免了梯度消失 的问题。ReLU 已被广泛应用于最先进的 DNN 模型中,如 ResNet、Inception 和 VGG。
- 初始化方法:采用适当的权重初始化方法,例如 Xavier 初始化(适用于 Sigmoid 或 Tanh) 和 He 初始化(适用于 ReLU)。可以确保梯度在传播过程中既不会消失也不会爆炸,有助于更好的梯度流动和更稳定的训练。
- 批归一化(Batch Normalization):批归一化涉及 将每个层内的迷你批次的输入归一化,使其具有零均值和单位方差。通过归一化输入,减少了内部协变量偏移,并有助于保持稳定的梯度流动。
- 残差网络(ResNets) 通过利用 跳跃连接 来解决梯度消失问题。这些连接 允许梯度绕过一些层,直接流向深层,从而实现更平滑的梯度传播。ResNets 使得训练非常深的网络成为可能,同时缓解了梯度消失问题。
- 深度学习中梯度消失问题可以通过降低 DNN 模型的复杂度来缓解。降低复杂度可以通过减少层数或每层的神经元数量来实现。虽然这可以在一定程度上缓解梯度消失问题,但也会导致模型容量和性能的降低。
- 为了在缓解梯度消失问题的同时保持模型容量,研究人员已经探索了各种网络架构,例如 跳跃连接、卷积神经网络(CNN)和循环神经网络(RNN)。这些架构旨在 促进更好的梯度流动和信息在层之间的传播,从而减少梯度消失问题。

如何识别梯度消失问题?
- 计算损失,如果在多个 epoch 中保持一致,则意味着存在梯度消失问题。
- 绘制权重与训练轮数之间的图表,如果它是恒定的,则意味着权重没有变化,因此出现了梯度消失问题。
激活函数
神经网络的基本构建块之一是激活函数,它决定了神经元是否会被激活。具体来说,前馈神经网络中神经元的值计算如下:
Y = ∑ i = 1 m ( x i ∗ w i ) + b Y = \sum_{i=1}^m (x_i * w_i) + b Y=i=1∑m(xi∗wi)+b
其中 x i x_i xi 是输入特征, w i w_i wi 是权重, b b b 是神经元的偏置。然后,在每个神经元的值上应用激活函数 f \mathbf{f} f,以决定神经元是否活跃: o u t p u t = f ( Y ) output = f(Y) output=f(Y)
下图以图示方式展示了激活函数的工作原理:

因此,激活函数是一元非线性函数,如 Sigmoid 和双曲正切函数,负责将非线性引入 DNN 模型。
因为具有线性激活函数的网络等同于仅仅是一个线性回归模型。由于激活函数的非线性,神经网络可以捕捉复杂的语义结构并实现高性能。
Sigmoid
Sigmoid 函数是深度学习领域的一个基本 激活函数,用于 在神经网络中引入非线性。
- 它从前一层的输入中获取输入值并将其 映射到 [0, 1] 之间。
- Sigmoid 函数的图像看起来 像“S”形曲线,它在 定义域内的任何一点都是连续且可微的。

在机器学习中, x x x 可能是 神经网络神经元中的加权输入总和 或 逻辑回归中的原始分数。
- 如果输出值接近 1,则表示对某一类的置信度很高;
- 如果值接近 0,则表示对另一类的置信度很高。
Sigmoid 函数的性质
Sigmoid 函数具有几个关键性质,使其在机器学习和神经网络中成为流行的选择:
- 定义域:Sigmoid 函数的定义域是 所有实数。这意味着它可以 将任何实数映射到 0 到 1 的范围内。
- 渐近线:当 x x x 趋向于正无穷大时, σ ( x ) σ(x) σ(x) 趋向于 1。相反,当 x x x 趋向于负无穷大时, σ ( x ) σ(x) σ(x) 趋向于 0。这一性质 确保函数永远不会真正达到 0 或 1,但会无限接近。
- 单调性:Sigmoid 函数是单调递增的,这意味着随着输入的增加,输出也会增加。
- 可微性:Sigmoid 函数是可微的,这使得在机器学习模型的训练过程中 可以计算梯度。
Sigmoid 函数在反向传播中的应用
如果我们在神经网络中使用线性激活函数,模型只能线性地分离数据,这会导致 在非线性数据集上的性能较差。
然而,通过添加具有 sigmoid 激活函数的隐藏层,模型获得了处理非线性的能力,从而提高了性能。
在反向传播过程中,模型通过计算激活函数的导数来计算和更新权重和偏置。 sigmoid 函数很有用,因为:
- 它是自己出现在自己导数中的函数。
- 它在每一点上都是可微分的,这有助于在反向传播过程中有效地计算梯度。
Sigmoid 函数的导数
Sigmoid 函数的导数,记作 σ ′ ( x ) \sigma'(x) σ′(x),由以下公式给出:
σ ′ ( x ) = σ ( x ) ⋅ ( 1 − σ ( x ) ) \sigma'(x) = \sigma(x) \cdot (1 - \sigma(x)) σ′(x)=σ(x)⋅(1−σ(x))

那么 sigmoid 函数的导数是如何计算的?sigmoid 函数定义为:
y = σ ( x ) = 1 1 + e − x y = \sigma(x) = \frac{1}{1 + e^{-x}} y=σ(x)=1+e−x1
设 u = 1 + e − x u = 1 + e^{-x} u=1+e−x,我们可以重写 sigmoid 函数为:
y = 1 u y = \frac{1}{u} y=u1
对 u u u 关于 x x x 求导:
d u d x = − e − x \frac{du}{dx} = -e^{-x} dxdu=−e−x
对 y y y 关于 u u u 求导:
d y d u = − 1 u 2 \frac{dy}{du} = -\frac{1}{u^2} dudy=−u21
根据链式法则,我们有:
d y d x = d y d u ⋅ d u d x \frac{dy}{dx} = \frac{dy}{du} \cdot \frac{du}{dx} dxdy=dudy⋅dxdu
将上述结果代入,得到:
d y d x = ( − 1 u 2 ) ⋅ ( e − x ) = e − x u 2 \frac{dy}{dx} = \left( -\frac{1}{u^2} \right) \cdot \left( e^{-x} \right)= \frac{e^{-x}}{u^2} dxdy=(−u21)⋅(e−x)=u2e−x
代入 u = 1 + e − x u = 1 + e^{-x} u=1+e−x:
d y d x = e − x ( 1 + e − x ) 2 \frac{dy}{dx} = \frac{e^{-x}}{(1 + e^{-x})^2} dxdy=(1+e−x)2e−x
由于:
σ ( x ) = 1 1 + e − x \sigma(x) = \frac{1}{1 + e^{-x}} σ(x)=1+e−x1
我们可以重写为:
1 − σ ( x ) = e − x 1 + e − x 1 - \sigma(x) = \frac{e^{-x}}{1 + e^{-x}} 1−σ(x)=1+e−xe−x
替换后:
d y d x = σ ( x ) ⋅ ( 1 − σ ( x ) ) \frac{dy}{dx} = \sigma(x) \cdot (1 - \sigma(x)) dxdy=σ(x)⋅(1−σ(x))
最终结果:
σ ′ ( x ) = σ ( x ) ⋅ ( 1 − σ ( x ) ) \sigma'(x) = \sigma(x) \cdot (1 - \sigma(x)) σ′(x)=σ(x)⋅(1−σ(x))
上述方程被称为 sigmoid 函数导数的广义形式。
Sigmoid 函数在反向传播中的问题
使用 sigmoid 函数的一个关键问题是梯度消失问题。 当使用梯度下降法更新权重和偏置时,如果梯度太小,权重和偏置的更新变得微不足道,从而减慢甚至停止学习。

红色区域突出显示导数 σ ′ ( x ) \sigma'(x) σ′(x) 非常小(接近 0)的区域。 在这些区域,用于在反向传播期间更新权重和偏置的梯度变得极小。
因此,模型学习速度非常慢或完全停止学习,这是深度神经网络中的一个主要问题。
Tanh 函数
Tanh 函数是另一种可以作为神经网络层之间非线性激活函数的可能函数。
- 与 Sigmoid 函数不同,Tanh 函数将输入映射到范围 [ − 1 , 1 ] [-1, 1] [−1,1],并且 tanh 函数的斜率要陡峭得多。
- 与 Sigmoid 类似,它形成了一个‘S’曲线,并且在整个区域内都是可微和连续的。

当在神经网络中使用这些激活函数时,我们的数据 通常围绕零中心。因此,我们应该 关注每个梯度在零附近的特性。

- tanh 的梯度是 sigmoid 函数梯度的四倍。这意味着使用 tanh 激活函数会导致 训练期间梯度值更高,网络权重更新更大。因此,如果我们想要 强梯度和大学习步长,我们应该使用 tanh 激活函数。
- 另一个区别是,tanh 的输出在 零点对称,导致 收敛速度更快。
示例,使用 sigmoid(左)和 tanh(右)激活函数时的输出值和梯度:

就像 sigmoid 函数一样,tanh 函数的一个有趣性质是 它的导数可以用函数本身来表示。下面是 tanh 函数的实际公式以及计算其导数的公式。

双曲正切函数 tanh ( x ) \tanh(x) tanh(x) 的导数,记作 tanh ′ ( x ) \tanh'(x) tanh′(x),由以下公式给出:
tanh ′ ( x ) = 1 − tanh 2 ( x ) \tanh'(x) = 1 - \tanh^2(x) tanh′(x)=1−tanh2(x)
推导 tanh 函数的导数。首先,我们知道,tanh 函数定义为:
tanh ( x ) = sinh ( x ) cosh ( x ) \tanh(x) = \frac{\sinh(x)}{\cosh(x)} tanh(x)=cosh(x)sinh(x)
双曲正弦和双曲余弦函数的定义为:
sinh ( x ) = e x − e − x 2 , cosh ( x ) = e x + e − x 2 \sinh(x) = \frac{e^x - e^{-x}}{2}, \quad \cosh(x) = \frac{e^x + e^{-x}}{2} sinh(x)=2ex−e−x,cosh(x)=2ex+e−x
我们对 tanh ( x ) = sinh ( x ) cosh ( x ) \tanh(x) = \frac{\sinh(x)}{\cosh(x)} tanh(x)=cosh(x)sinh(x) 使用商法则进行求导,商法则公式为:
d d x ( f ( x ) g ( x ) ) = f ′ ( x ) g ( x ) − f ( x ) g ′ ( x ) [ g ( x ) ] 2 \frac{d}{dx} \left( \frac{f(x)}{g(x)} \right) = \frac{f'(x)g(x) - f(x)g'(x)}{[g(x)]^2} dxd(g(x)f(x))=[g(x)]2f′(x)g(x)−f(x)g′(x)
其中, f ( x ) = sinh ( x ) f(x) = \sinh(x) f(x)=sinh(x) 和 g ( x ) = cosh ( x ) g(x) = \cosh(x) g(x)=cosh(x)。对 sinh ( x ) \sinh(x) sinh(x) 和 cosh ( x ) \cosh(x) cosh(x) 求导:
d d x sinh ( x ) = cosh ( x ) , d d x cosh ( x ) = sinh ( x ) \frac{d}{dx} \sinh(x) = \cosh(x), \quad \frac{d}{dx} \cosh(x) = \sinh(x) dxdsinh(x)=cosh(x),dxdcosh(x)=sinh(x)
使用商法则对 tanh ( x ) \tanh(x) tanh(x) 求导:
tanh ′ ( x ) = cosh ( x ) ⋅ cosh ( x ) − sinh ( x ) ⋅ sinh ( x ) [ cosh ( x ) ] 2 = cosh 2 ( x ) − sinh 2 ( x ) cosh 2 ( x ) \tanh'(x) = \frac{\cosh(x) \cdot \cosh(x) - \sinh(x) \cdot \sinh(x)}{[\cosh(x)]^2} = \frac{\cosh^2(x) - \sinh^2(x)}{\cosh^2(x)} tanh′(x)=[cosh(x)]2cosh(x)⋅cosh(x)−sinh(x)⋅sinh(x)=cosh2(x)cosh2(x)−sinh2(x)
由于双曲恒等式 cosh 2 ( x ) − sinh 2 ( x ) = 1 \cosh^2(x) - \sinh^2(x) = 1 cosh2(x)−sinh2(x)=1:
tanh ′ ( x ) = 1 cosh 2 ( x ) \tanh'(x) = \frac{1}{\cosh^2(x)} tanh′(x)=cosh2(x)1
我们知道 tanh ( x ) = sinh ( x ) cosh ( x ) \tanh(x) = \frac{\sinh(x)}{\cosh(x)} tanh(x)=cosh(x)sinh(x),因此有:
cosh 2 ( x ) = 1 + tanh 2 ( x ) \cosh^2(x) = 1 + \tanh^2(x) cosh2(x)=1+tanh2(x)
因此,导数可以重写为:
tanh ′ ( x ) = 1 − tanh 2 ( x ) \tanh'(x) = 1 - \tanh^2(x) tanh′(x)=1−tanh2(x)
最终结果:
tanh ′ ( x ) = 1 − tanh 2 ( x ) \tanh'(x) = 1 - \tanh^2(x) tanh′(x)=1−tanh2(x)
这就是双曲正切函数 tanh ( x ) \tanh(x) tanh(x) 的导数。
ReLU 函数
ReLU(修正线性单元) 是神经网络中最常用的激活函数,尤其是在 CNN 中。如果你不确定在您的网络中使用哪种激活函数,ReLU 通常是首选。
ReLU 具有非饱和激活函数,这确保了梯度可以自由地在网络中流动。
从数学上讲,它定义为 y = m a x ( 0 , x ) y = max(0, x) y=max(0,x)。从视觉上看,它看起来如下:

根据分段定义,我们分别对两部分进行求导:
ReLU ′ ( x ) = { 1 if x > 0 , 0 if x < 0. \text{ReLU}'(x) = \begin{cases} 1 & \text{if } x > 0, \\ 0 & \text{if } x < 0.\\ \end{cases} ReLU′(x)={10if x>0,if x<0.
在 x = 0 x = 0 x=0 处,ReLU 函数不可导。通常在深度学习中,我们取: ReLU ′ ( 0 ) = 0 或 1 \text{ReLU}'(0) = 0 \quad \text{或} \quad 1 ReLU′(0)=0或1
在实际应用中,
ReLU ′ ( x ) = { 1 if x > 0 , 0 if x ≤ 0. \text{ReLU}'(x) = \begin{cases} 1 & \text{if } x > 0, \\ 0 & \text{if } x \leq 0.\\ \end{cases} ReLU′(x)={10if x>0,if x≤0.
ReLU 对所有正数是线性的(恒等),对所有负数是零。这意味着:
- 计算成本低,因为没有复杂的数学。因此,模型可以更快地进行训练或运行。
- 它收敛得更快。线性意味着当 x x x 值很大时,斜率不会“饱和”。它没有像 sigmoid 或 tanh 这样的激活函数所遭受的梯度消失问题。
- 它是稀疏激活的。由于 ReLU 对所有负输入都是零,因此任何给定单元可能根本不会激活。这通常是希望看到的。
为什么稀疏性是好的?
- 如果我们从生物神经网络的角度来考虑,这就会变得直观。虽然我们体内有数十亿个神经元,但并不是所有的神经元在所有时候都会因为所有行为而激活。相反,它们有不同的角色,并由不同的信号激活。
- 稀疏性导致模型简洁,通常具有更好的预测能力和更少的过拟合/噪声。在稀疏网络中,神经元实际上处理问题的有意义方面的可能性更大。例如,在一个检测图像中猫的模型中,可能有一个可以识别耳朵的神经元,显然,如果图像是关于建筑的,这个神经元就不应该被激活。
- 最后,稀疏网络比密集网络更快,因为要计算的东西更少。
“死亡 ReLU” 问题:如果 ReLU 神经元卡在负侧并且始终输出 0,则该神经元是“死亡”的。因为 ReLU 在负值范围的斜率也是 0,一旦神经元变负,它恢复的可能性就很小。这些神经元在区分输入方面不起任何作用,实际上是无用的。随着时间的推移,你可能会发现网络的大部分区域都在做无用功。
单步(例如在 SGD 中)涉及多个数据点,只要不是所有数据点都是负的,我们仍然可以从 ReLU 中得到斜率。当 学习率过高或存在较大的负偏差 时,死亡问题很可能会发生。
Leaky ReLU & Parametric ReLU (PReLU)

Leaky ReLU 对于负值有一个小的斜率,而不是完全为零。例如,Leaky ReLU 可能具有 y = 0.01 x y = 0.01x y=0.01x 当 x < 0 x < 0 x<0。
Parametric ReLU (PReLU) 是一种 Leaky ReLU,它不像 0.01 这样的预定斜率,而是 将其作为神经网络自行确定的参数: y = a x y = ax y=ax 当 x < 0 x < 0 x<0。
Leaky ReLU 有两个优点:
- 它解决了“死亡 ReLU”问题,因为它没有零斜率的部分。
- 与 ReLU 不同,Leaky ReLU 更“平衡”,因此可能学习得更快。
Exponential Linear (ELU, SELU)
与 Leaky ReLU 类似,ELU 在负值处具有较小的斜率。它不像直线,而使用类似于以下的对数曲线:

它旨在结合 ReLU 和 Leaky ReLU 的优点——它没有 ReLU 的死亡问题,对于大负值会饱和,使它们基本上处于不活跃状态。
权重初始化方法
| 特性 | Xavier 初始化 | He 初始化 |
|---|---|---|
| 作者及提出年份 | Xavier Glorot 和 Yoshua Bengio,2010 | Kaiming He,2015 |
| 适用激活函数 | Sigmoid, Tanh | ReLU, Leaky ReLU |
| 初始化方差 | 2 n i n + n o u t \frac{2}{n_{in} + n_{out}} nin+nout2 | 2 n i n \frac{2}{n_{in}} nin2 |
| 优点 | 改善了梯度消失或爆炸,适合对称激活函数 | 避免梯度消失,适合非对称激活函数 |
| 局限性 | 对非对称激活函数表现差 | 对对称激活函数表现差 |
Xavier 初始化(Glorot 初始化)—— Sigmoid 或 Tanh
当网络层太深时,前向传播和反向传播中的信号会随着层数增加而逐渐衰减或放大。Xavier 初始化通过 控制输入和输出的方差,使得信号能够在层与层之间稳定地传播。
对于每一层的权重矩阵 W:
W ∼ N ( 0 , 2 n i n + n o u t ) W \sim \mathcal{N} \left( 0, \frac{2}{n_{in} + n_{out}} \right) W∼N(0,nin+nout2)
或
W ∼ U ( − 6 n i n + n o u t , 6 n i n + n o u t ) W \sim \mathcal{U} \left( -\sqrt{\frac{6}{n_{in} + n_{out}}}, \sqrt{\frac{6}{n_{in} + n_{out}}} \right) W∼U(−nin+nout6,nin+nout6)
其中, n i n n_{in} nin 是输入单元数量, n o u t n_{out} nout 是输出单元数量。
He 初始化(Kaiming 初始化)
与 Xavier 初始化类似,但考虑到了 ReLU 的特性(只有正输出部分起作用),所以在计算方差时需要 增大初始化权重的方差。
对于每一层的权重矩阵 W:
W ∼ N ( 0 , 2 n i n ) W \sim \mathcal{N} \left( 0, \frac{2}{n_{in}} \right) W∼N(0,nin2)
或
W ∼ U ( − 6 n i n , 6 n i n ) W \sim \mathcal{U} \left( -\sqrt{\frac{6}{n_{in}}}, \sqrt{\frac{6}{n_{in}}} \right) W∼U(−nin6,nin6)
其中, n i n n_{in} nin 是输入单元数量。
归一化(Normalization)
归一化 是机器学习中常用的 数据预处理技术,主要目的是 将特征值转换到一个共同的尺度上,以便使模型训练时更加稳定和高效。
归一化是 将数据按比例缩放,使其符合特定的范围,常见的范围是 [ 0 , 1 ] [0, 1] [0,1] 或 [ − 1 , 1 ] [-1, 1] [−1,1]。它可以 消除特征之间由于量纲不同而导致的影响。
-
不同尺度特征的影响: 特征可能有不同的量纲,例如一个特征表示身高(单位为厘米),另一个特征表示体重(单位为公斤)。如果这些特征没有进行归一化,体重可能在模型训练中占据主导地位,影响模型的性能。
-
优化算法的影响: 许多优化算法(如梯度下降)对数据的尺度非常敏感。如果特征的范围差异过大,算法可能会在某些方向上收敛得非常慢,导致训练效率低下。
常见的归一化方法
-
最小-最大归一化(Min-Max Normalization)
这种方法将数据按比例缩放到指定的范围,通常是 [ 0 , 1 ] [0, 1] [0,1]。
X norm = X − X min X max − X min X_{\text{norm}} = \frac{X - X_{\text{min}}}{X_{\text{max}} - X_{\text{min}}} Xnorm=Xmax−XminX−Xmin- X X X 是原始特征值, X min X_{\text{min}} Xmin 和 X max X_{\text{max}} Xmax 分别是该特征的最小值和最大值。
- 归一化后的数据 X norm X_{\text{norm}} Xnorm 位于 [ 0 , 1 ] [0, 1] [0,1] 之间。
优点:
- 保持了原数据的分布形态。
- 适用于特征值本身具有明确最小值和最大值的情况。
缺点:
- 对离群点非常敏感,可能会导致大部分数据压缩在很小的范围内。
-
Z-score 标准化(Standardization)
标准化将数据转换为均值为 0、标准差为 1 的分布,常用于当数据没有固定的最小和最大值时。
X stand = X − μ σ X_{\text{stand}} = \frac{X - \mu}{\sigma} Xstand=σX−μ- μ \mu μ 是特征的均值, σ \sigma σ 是特征的标准差。
- 归一化后的数据具有 零均值 和 单位方差。
优点:
- 不受离群点的影响。
- 适用于大多数机器学习算法,尤其是线性回归、逻辑回归和支持向量机等。
缺点:
- 归一化后的数据没有明确的范围,有时可能导致一些模型不易解释。
-
最大绝对值归一化(Max Abs Scaling)
这种方法将数据按最大绝对值进行归一化,确保所有的特征值都位于 [ − 1 , 1 ] [-1, 1] [−1,1] 之间。X norm = X ∣ X max ∣ X_{\text{norm}} = \frac{X}{|X_{\text{max}}|} Xnorm=∣Xmax∣X
- 这里 X max X_{\text{max}} Xmax 是特征的最大绝对值。
优点:
- 不会改变数据的分布,保持了数据的稀疏性。
- 对离群点不敏感。
缺点:
- 如果数据包含较大的离群点,可能会影响到归一化的效果。
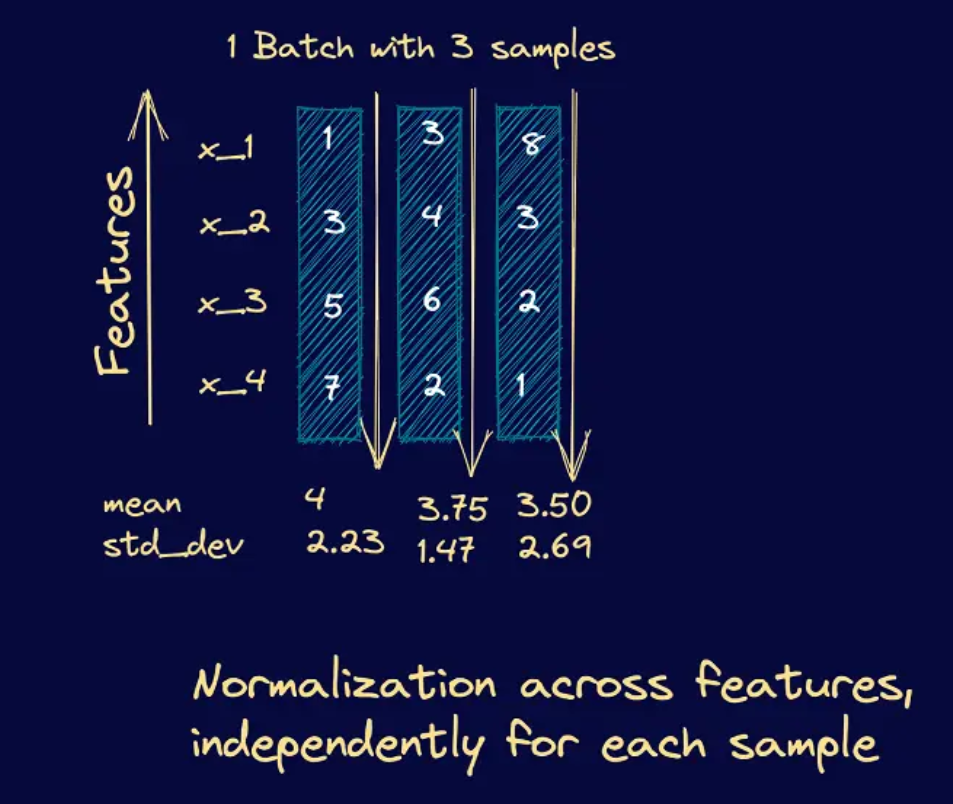
BatchNorm(Batch Normalization)和 LayerNorm(Layer Normalization)
BatchNorm(Batch Normalization)和 LayerNorm(Layer Normalization)都是深度学习中常用的 归一化方法,目的是 加快模型收敛、提高稳定性,减少梯度消失或爆炸问题。
但它们的归一化方式、适用场景和效果有所不同。
| 对比项 | BatchNorm | LayerNorm |
|---|---|---|
| 归一化维度 | 对 batch 维度(多个样本)进行归一化 | 对 feature 维度(单个样本内部)进行归一化 |
| 计算均值方差 | 针对每个 feature,在 batch 维度 计算均值/方差 | 针对每个样本,在 feature 维度 计算均值/方差 |
| 公式 | BN: x ^ i = x i − μ B σ B 2 + ϵ \text{BN: } \hat{x}_{i} = \frac{x_{i} - \mu_B}{\sqrt{\sigma^2_B + \epsilon}} BN: x^i=σB2+ϵxi−μB | LN: x ^ i = x i − μ L σ L 2 + ϵ \text{LN: } \hat{x}_{i} = \frac{x_{i} - \mu_L}{\sqrt{\sigma^2_L + \epsilon}} LN: x^i=σL2+ϵxi−μL |
| 参数 | 对每个 feature 学习 γ γ γ(scale) 和 β β β(shift) | 同样学习 γ γ γ 和 β β β,但作用在每个 feature |
| 对 batch size 敏感性 | 敏感,batch 越大效果越好 | 不敏感,适用于任意 batch size |

| 应用场景 | 推荐使用 |
|---|---|
| CNN(图像分类/识别) | BatchNorm 更适合(因为特征在 spatial 和 channel 上比较稳定,且 batch size 通常足够大) |
| RNN / Transformer / NLP任务 | LayerNorm 更适合(序列长度不一,batch size 小,不适合用 BN) |
| 小批量训练(small batch training) | LayerNorm 更稳定 |
| 强化学习 | LayerNorm 通常更稳定 |
| 自监督、生成模型(如GAN) | 取决于模型结构,一般 LayerNorm 更通用 |
小结一句话
- BatchNorm 是跨样本归一化,对 CNN 友好;
- LayerNorm 是跨特征归一化,对 NLP 和 Transformer 更好;
- 小 batch 情况用 LayerNorm 更稳。
其他归一化方式补充(了解)
| 方法 | 简介 |
|---|---|
| InstanceNorm | 在 每个样本、每个通道 上归一化(常用于 风格迁移) |
| GroupNorm | 在 feature 分组上归一化,兼顾 BN 和 LN 优点 |
| RMSNorm | 简化版 LayerNorm,只除以均方根 |