Actor-Critic(演员评论家算法)基础解析与代码实例:稳定倒立摆
目录
1. 前言
2. 算法原理
2.1 Actor(策略网络)
2.2 Critic(价值网络)
2.3 核心流程
3. Actor-Critic算法实例:稳定倒立摆
3.1 导入必要的库
3.2 定义Actor和Critic网络
3.3 定义Actor-Critic算法
3.4 训练过程
3.5 完整代码
4. 总结
1. 前言
在强化学习领域,Actor-Critic算法是一种结合了策略梯度方法和值函数方法的强化学习算法。它通过同时学习策略(Actor)和价值(Critic),既能够直接优化策略,又能利用价值函数降低梯度估计的方差。这种算法在处理复杂环境和高维状态空间时具有较高的效率和可扩展性。
这是一个值方法与策略方法相互取长补短的方法:
- 值函数方法(如Q学习):估算每个状态或状态-动作对的价值,并依据最大价值选择动作;
- 策略方法:直接优化动作选择的概率分布(策略),通过采样环境反馈进行改进;
- 策略-值函数结合的方法:例如Actor-Critic,综合两者的优点。
本文将详细介绍Actor-Critic算法的原理,并通过一个完整的稳定倒立摆代码示例展示如何实现和应用该算法。
2. 算法原理
2.1 Actor(策略网络)
Actor负责生成策略,给定状态 s,输出动作的概率分布 πθ(a∣s)。通过策略梯度进行更新,使得期望回报最大化。
2.2 Critic(价值网络)
Critic负责评估当前策略的价值,给定状态* s,输出状态价值 V(s)。它通过估计时间差分(TD)误差来指导策略的更新。
2.3 核心流程
结合上述部分,Actor-Critic的算法流程如下:
初始化Actor和Critic网络的参数;
重复以下步骤直到收敛:
在状态 s 下,Actor根据![]() 采样动作 a ;
采样动作 a ;
执行动作 a ,获得奖励 r 和下一状态 s' ;
Critic计算TD误差:
![]()
Critic更新:
![]()
Actor更新:
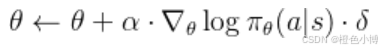
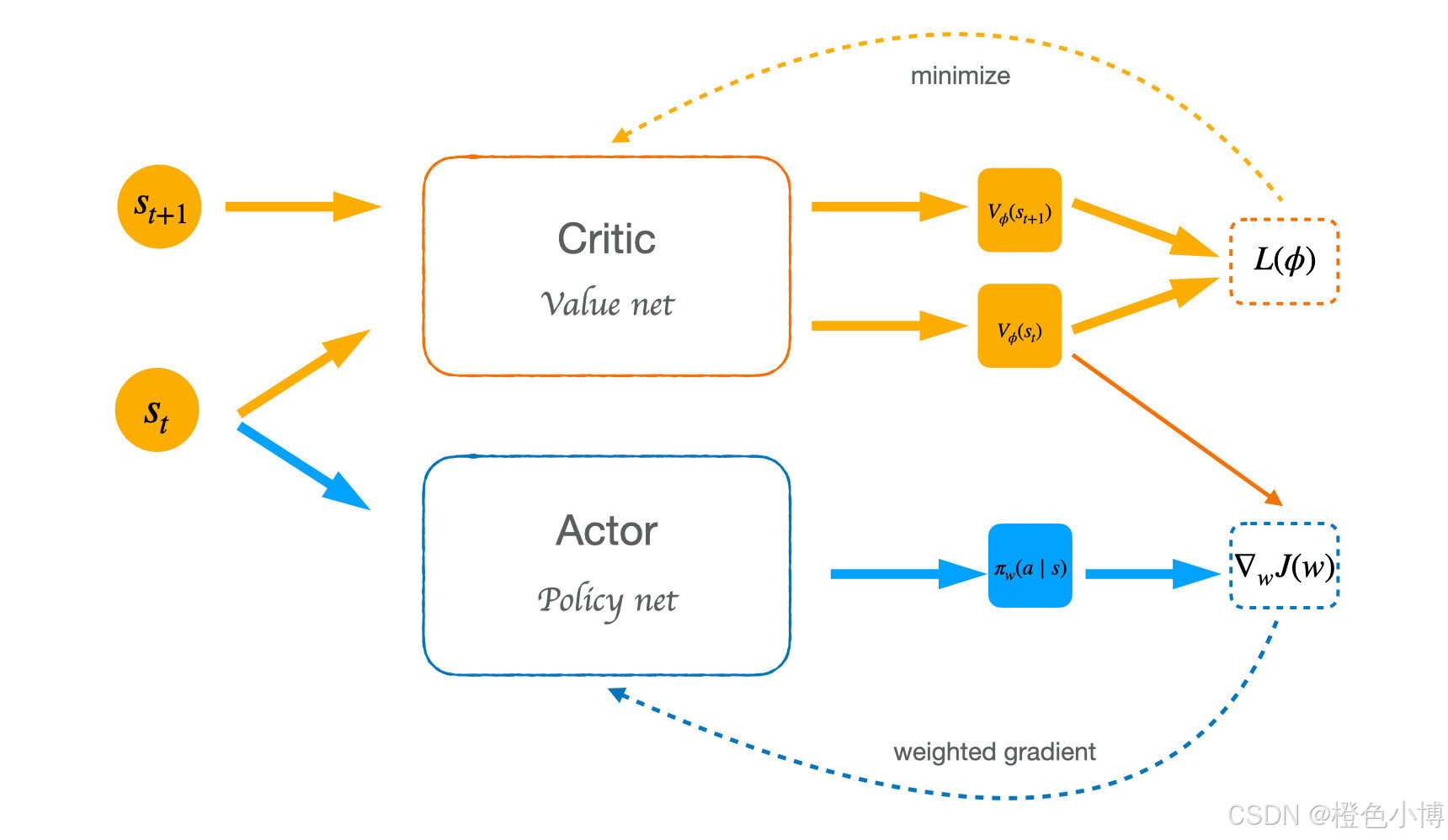
流程图如下:
3. Actor-Critic算法实例:稳定倒立摆
3.1 导入必要的库
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import gym
from collections import deque
import matplotlib.pyplot as plt3.2 定义Actor和Critic网络
class PolicyNet(nn.Module):def __init__(self, state_dim, hidden_dim, action_dim):super(PolicyNet, self).__init__()self.fc1 = nn.Linear(state_dim, hidden_dim)self.fc2 = nn.Linear(hidden_dim, action_dim)def forward(self, x):x = torch.relu(self.fc1(x))return torch.softmax(self.fc2(x), dim=1)class ValueNet(nn.Module):def __init__(self, state_dim, hidden_dim):super(ValueNet, self).__init__()self.fc1 = nn.Linear(state_dim, hidden_dim)self.fc2 = nn.Linear(hidden_dim, 1)def forward(self, x):x = torch.relu(self.fc1(x))return self.fc2(x)3.3 定义Actor-Critic算法
class ActorCritic:def __init__(self, state_dim, hidden_dim, action_dim, actor_lr, critic_lr, gamma, device):self.actor = PolicyNet(state_dim, hidden_dim, action_dim).to(device)self.critic = ValueNet(state_dim, hidden_dim).to(device)self.actor_optimizer = optim.Adam(self.actor.parameters(), lr=actor_lr)self.critic_optimizer = optim.Adam(self.critic.parameters(), lr=critic_lr)self.gamma = gammaself.device = devicedef take_action(self, state):state = torch.tensor([state], dtype=torch.float).to(self.device)probs = self.actor(state)action_dist = torch.distributions.Categorical(probs)action = action_dist.sample()return action.item()def update(self, transition_dict):states = torch.tensor(transition_dict['states'], dtype=torch.float).to(self.device)actions = torch.tensor(transition_dict['actions']).view(-1, 1).to(self.device)rewards = torch.tensor(transition_dict['rewards'], dtype=torch.float).view(-1, 1).to(self.device)next_states = torch.tensor(transition_dict['next_states'], dtype=torch.float).to(self.device)dones = torch.tensor(transition_dict['dones'], dtype=torch.float).view(-1, 1).to(self.device)td_target = rewards + self.gamma * self.critic(next_states) * (1 - dones)td_delta = td_target - self.critic(states)log_probs = torch.log(self.actor(states).gather(1, actions))actor_loss = torch.mean(-log_probs * td_delta.detach())critic_loss = torch.mean(F.mse_loss(self.critic(states), td_target.detach()))self.actor_optimizer.zero_grad()self.critic_optimizer.zero_grad()actor_loss.backward()critic_loss.backward()self.actor_optimizer.step()self.critic_optimizer.step()-
正的 TD Delta:表示当前动作带来了比预期更高的回报,策略网络应该增加采取该动作的概率。因此,正的 TD Delta 会通过梯度上升的方式增加策略网络的参数。
-
负的 TD Delta:表示当前动作带来了比预期更低的回报,策略网络应该减少采取该动作的概率。因此,负的 TD Delta 会通过梯度下降的方式减少策略网络的参数。
3.4 训练过程
def train():env = gym.make('CartPole-v1')state_dim = env.observation_space.shape[0]action_dim = env.action_space.nhidden_dim = 128actor_lr = 1e-3critic_lr = 1e-2gamma = 0.98device = torch.device("cuda" if torch.cuda.is_available() else "cpu")agent = ActorCritic(state_dim, hidden_dim, action_dim, actor_lr, critic_lr, gamma, device)num_episodes = 1000return_list = []for i in range(num_episodes):state = env.reset()[0]done = Falseepisode_return = 0transition_dict = {'states': [],'actions': [],'next_states': [],'rewards': [],'dones': [],}while not done:action = agent.take_action(state)next_state, reward, done, _, _ = env.step(action)transition_dict['states'].append(state)transition_dict['actions'].append(action)transition_dict['next_states'].append(next_state)transition_dict['rewards'].append(reward)transition_dict['dones'].append(done)state = next_stateepisode_return += rewardreturn_list.append(episode_return)agent.update(transition_dict)print(f"Episode: {i}, Return: {np.mean(return_list[-10:])}")return return_listif __name__ == "__main__":return_list = train()plt.plot(return_list)plt.title('Return per Episode')plt.xlabel('Episode')plt.ylabel('Return')plt.show()3.5 完整代码
完整代码如下方便调试:
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import gym
from collections import deque
import matplotlib.pyplot as plt
import torch.nn.functional as Fclass PolicyNet(nn.Module):def __init__(self, state_dim, hidden_dim, action_dim):super(PolicyNet, self).__init__()self.fc1 = nn.Linear(state_dim, hidden_dim)self.fc2 = nn.Linear(hidden_dim, action_dim)def forward(self, x):x = torch.relu(self.fc1(x))return torch.softmax(self.fc2(x), dim=1)class ValueNet(nn.Module):def __init__(self, state_dim, hidden_dim):super(ValueNet, self).__init__()self.fc1 = nn.Linear(state_dim, hidden_dim)self.fc2 = nn.Linear(hidden_dim, 1)def forward(self, x):x = torch.relu(self.fc1(x))return self.fc2(x)class ActorCritic:def __init__(self, state_dim, hidden_dim, action_dim, actor_lr, critic_lr, gamma, device):self.actor = PolicyNet(state_dim, hidden_dim, action_dim).to(device)self.critic = ValueNet(state_dim, hidden_dim).to(device)self.actor_optimizer = optim.Adam(self.actor.parameters(), lr=actor_lr)self.critic_optimizer = optim.Adam(self.critic.parameters(), lr=critic_lr)self.gamma = gammaself.device = devicedef take_action(self, state):state = torch.tensor([state], dtype=torch.float).to(self.device)probs = self.actor(state)action_dist = torch.distributions.Categorical(probs)action = action_dist.sample()return action.item()def update(self, transition_dict):states = torch.tensor(transition_dict['states'], dtype=torch.float).to(self.device)actions = torch.tensor(transition_dict['actions']).view(-1, 1).to(self.device)rewards = torch.tensor(transition_dict['rewards'], dtype=torch.float).view(-1, 1).to(self.device)next_states = torch.tensor(transition_dict['next_states'], dtype=torch.float).to(self.device)dones = torch.tensor(transition_dict['dones'], dtype=torch.float).view(-1, 1).to(self.device)td_target = rewards + self.gamma * self.critic(next_states) * (1 - dones)td_delta = td_target - self.critic(states)log_probs = torch.log(self.actor(states).gather(1, actions))actor_loss = torch.mean(-log_probs * td_delta.detach())critic_loss = torch.mean(F.mse_loss(self.critic(states), td_target.detach()))self.actor_optimizer.zero_grad()self.critic_optimizer.zero_grad()actor_loss.backward()critic_loss.backward()self.actor_optimizer.step()self.critic_optimizer.step()def train():env = gym.make('CartPole-v1')state_dim = env.observation_space.shape[0]action_dim = env.action_space.nhidden_dim = 128actor_lr = 1e-3critic_lr = 1e-2gamma = 0.98device = torch.device("cuda" if torch.cuda.is_available() else "cpu")agent = ActorCritic(state_dim, hidden_dim, action_dim, actor_lr, critic_lr, gamma, device)num_episodes = 1000return_list = []for i in range(num_episodes):state = env.reset()[0]done = Falseepisode_return = 0transition_dict = {'states': [],'actions': [],'next_states': [],'rewards': [],'dones': [],}while not done:action = agent.take_action(state)next_state, reward, done, _, _ = env.step(action)transition_dict['states'].append(state)transition_dict['actions'].append(action)transition_dict['next_states'].append(next_state)transition_dict['rewards'].append(reward)transition_dict['dones'].append(done)state = next_stateepisode_return += rewardreturn_list.append(episode_return)agent.update(transition_dict)print(f"Episode: {i}, Return: {np.mean(return_list[-10:])}")return return_listif __name__ == "__main__":return_list = train()plt.plot(return_list)plt.title('Return per Episode')plt.xlabel('Episode')plt.ylabel('Return')plt.show()结果如下:
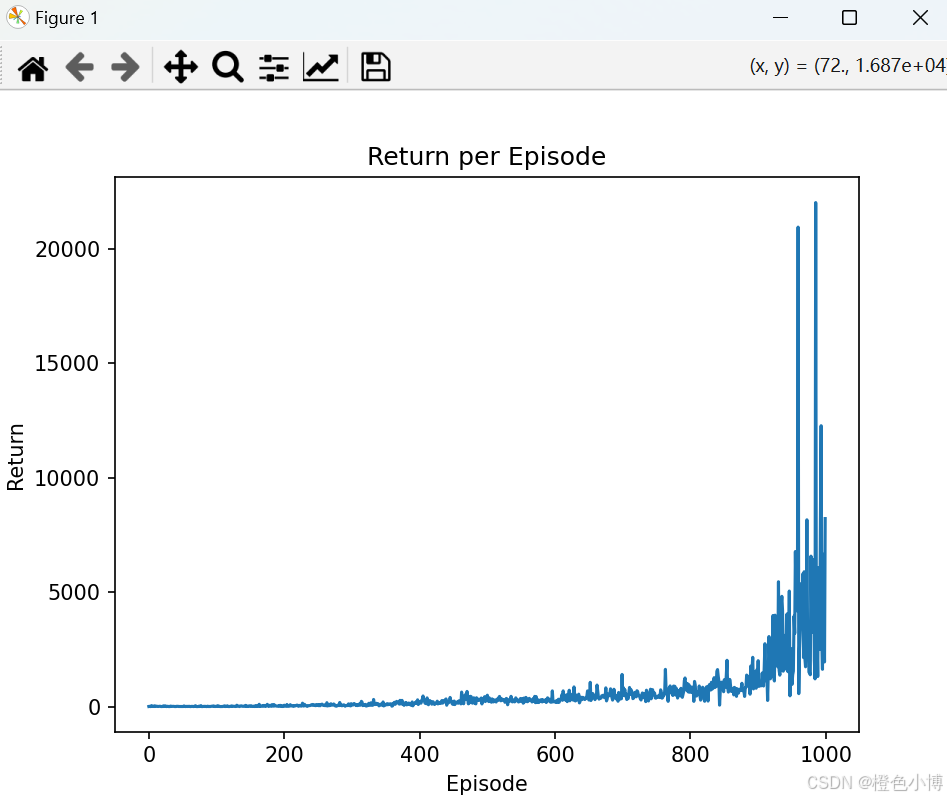
可以看得出来效果很好。
4. 总结
Actor-Critic算法通过结合策略梯度方法和值函数方法,能够有效地处理复杂环境中的强化学习问题。本文通过详细的代码示例展示了如何实现和应用该算法。通过调整超参数(如学习率、隐藏层大小等),可以进一步优化算法的性能。该算法在实际应用中具有广泛的应用前景,尤其是在机器人控制、自动驾驶等领域。关注我,一起在人工智能领域学习进步!