【CRF系列】第7篇:CRF实战——经典工具与Python库应用
【CRF系列】第7篇:CRF实战——经典工具与Python库应用
1. 引言
在前面六篇文章中,我们系统地学习了CRF的理论基础、数学模型、参数学习和解码算法。现在,是时候将理论付诸实践了!
本文将介绍两种在实际项目中广泛使用的CRF工具:
- CRF++:一个高效的C++实现,广泛用于各类序列标注任务
- sklearn-crfsuite:一个Python库,提供了类似scikit-learn的易用API
我们将详细介绍这两种工具的安装、使用方法、数据格式要求,并通过实际案例(中文分词和命名实体识别)展示完整的应用流程。无论你是更倾向于命令行工具还是Python编程,本文都将帮助你快速上手CRF模型,并将其应用到自己的项目中。
动手实践是掌握任何技术的最佳方式,让我们开始这个激动人心的实战之旅吧!
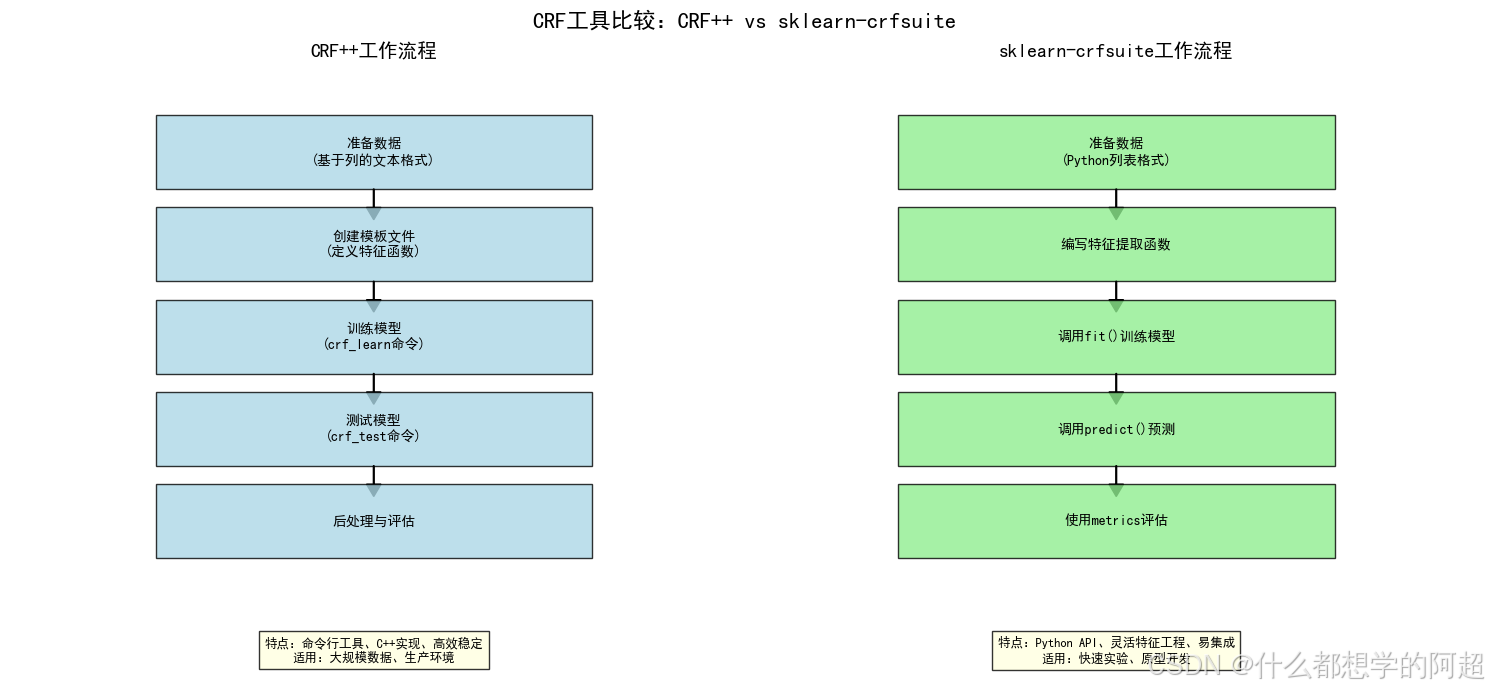
2. 实战工具一:CRF++
2.1 CRF++简介
CRF++是由日本学者Taku Kudo开发的开源CRF实现,具有以下特点:
- 高效:C++实现,运行速度快,支持多线程训练
- 灵活:通过模板文件灵活定义特征
- 稳定:广泛用于学术研究和工业应用
- 资源占用:对大规模数据集有良好支持
CRF++是一个命令行工具,主要包含两个核心命令:crf_learn(训练模型)和crf_test(测试模型)。
2.2 安装CRF++
Linux/Mac安装
# 下载源码
wget https://github.com/taku910/crfpp/archive/master.zip
unzip master.zip
cd crfpp-master# 编译安装
./configure
make
sudo make install
Windows安装
Windows用户可以下载预编译的二进制文件:
- 访问官方网站
- 下载适合Windows的二进制包
- 解压后将bin目录添加到PATH环境变量
安装完成后,可以在命令行中输入crf_learn -h和crf_test -h来确认是否安装成功。
2.3 CRF++核心命令详解
crf_learn:训练模型
基本语法:
crf_learn [options] template_file train_file model_file
主要参数:
template_file:模板文件,定义特征函数train_file:训练数据文件model_file:输出的模型文件
重要选项:
-a <algorithm>:指定训练算法,默认为CRF-L2,可选CRF-L1(L1正则化)-c <float>:正则化系数,默认为1.0-f <num>:特征频率阈值,低于此频率的特征将被忽略,默认为1-p <num>:线程数,默认为1-t:生成文本格式的模型(默认为二进制)-m <num>:内存上限(MB),默认为1000MB
例如:
crf_learn -f 3 -c 1.5 -p 4 template.txt train.data model
这个命令使用4个线程训练模型,特征频率阈值为3,L2正则化系数为1.5。
crf_test:测试模型
基本语法:
crf_test -m model_file test_files
主要参数:
-m model_file:训练好的模型文件test_files:测试数据文件
重要选项:
-o <filename>:输出结果到文件-v:输出概率值-n <num>:输出N-best结果-t:使用文本格式的模型(如果模型是文本格式的)
例如:
crf_test -m model -o output.txt test.data
2.4 CRF++文件格式
训练/测试数据格式
CRF++使用简单的基于列的文本格式。每行对应一个token(如单词或字符),不同的特征和标签以列的形式排列。空行表示序列的边界(如句子的结束)。最后一列必须是标签列。
例如,词性标注任务的数据:
I PRP
love VB
New NNP
York NNP
. .He PRP
hates VBZ
Washington NNP
. .
如果有更多特征,可以添加额外的列:
I I PRP B-NP
love love VB B-VP
New New NNP B-NP
York York NNP I-NP
. . . OHe He PRP B-NP
hates hate VBZ B-VP
Washington Washington NNP B-NP
. . . O
这里第一列是单词,第二列是词干,第三列是词性,第四列是短语标签。
模板文件语法
模板文件定义了如何从训练数据中生成特征函数。上一篇文章已经详细介绍过模板的语法,这里简要回顾:
# Unigram模板,只与当前标签相关
U00:%x[0,0] # 当前词
U01:%x[-1,0] # 前一个词
U02:%x[1,0] # 后一个词# Bigram模板,与当前标签和前一个标签相关
B
其中:
%x[row,col]表示相对于当前位置的特征,row是相对行偏移,col是列索引U开头的行定义Unigram特征B开头的行定义Bigram特征
输出格式
crf_test的标准输出格式是在原始测试数据的每行末尾添加一列预测标签:
I PRP PRP
love VB VB
New NNP NNP
York NNP NNP
. . .He PRP PRP
hates VBZ VBZ
Washington NNP NNP
. . .
使用-v选项时,还会输出标签的概率信息。
2.5 实战案例:中文分词
让我们通过一个中文分词案例来展示CRF++的完整使用流程。
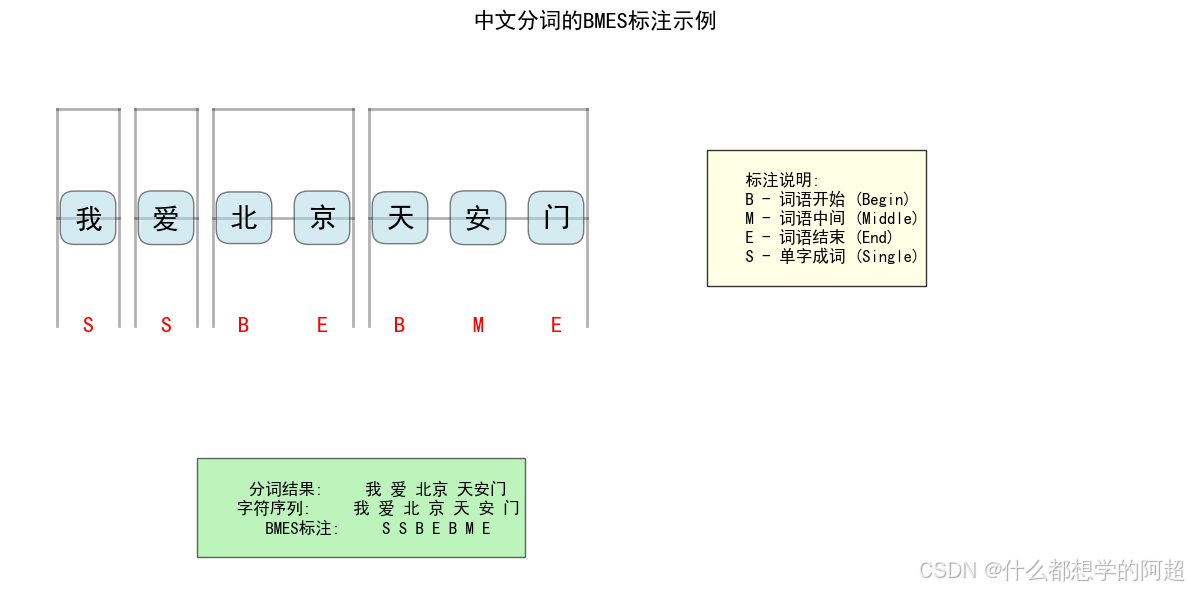
第一步:准备数据
中文分词通常使用BMES标注体系:
- B: 词的开始
- M: 词的中间
- E: 词的结束
- S: 单字成词
训练数据示例(已分词的句子转换为字级别的BMES标注):
# 转换脚本示例
def convert_to_bmes(sentence):"""将已分词的句子转换为BMES标注"""words = sentence.strip().split()chars = []tags = []for word in words:if len(word) == 1:chars.append(word)tags.append('S')else:for i, char in enumerate(word):chars.append(char)if i == 0:tags.append('B')elif i == len(word) - 1:tags.append('E')else:tags.append('M')return chars, tags# 示例
sentence = "我 爱 北京 天安门"
chars, tags = convert_to_bmes(sentence)
for char, tag in zip(chars, tags):print(f"{char}\t{tag}")
输出将是:
我 S
爱 S
北 B
京 E
天 B
安 M
门 E
将大量已分词文本转换为这种格式,得到训练和测试数据。
第二步:创建模板文件
我们为中文分词创建一个模板文件template.txt:
# 字符特征
U00:%x[0,0] # 当前字
U01:%x[-1,0] # 前一个字
U02:%x[1,0] # 后一个字
U03:%x[-2,0] # 前两个字
U04:%x[2,0] # 后两个字# 字符组合特征
U05:%x[-1,0]/%x[0,0] # 前一个字+当前字
U06:%x[0,0]/%x[1,0] # 当前字+后一个字
U07:%x[-1,0]/%x[0,0]/%x[1,0] # 前一个字+当前字+后一个字# 是否为标点、数字等(假设额外有一列表示字符类型)
U10:%x[0,1] # 当前字的类型# Bigram特征
B
第三步:训练模型
假设我们已经准备好了训练数据train.data,现在使用以下命令训练模型:
crf_learn -f 3 -c 1.5 -p 4 template.txt train.data model_seg
第四步:应用模型进行分词
准备一个测试文件test.data,其格式与训练数据相同,但不包含标签列,或包含标签列但仅用于评估。
crf_test -m model_seg test.data > output.txt
第五步:将BMES标注结果转回分词结果
def convert_bmes_to_words(chars, tags):"""将BMES标注转换回分词结果"""words = []current_word = ""for char, tag in zip(chars, tags):if tag == 'S':words.append(char)elif tag == 'B':current_word = charelif tag == 'M':current_word += charelif tag == 'E':current_word += charwords.append(current_word)current_word = ""return ' '.join(words)# 处理crf_test的输出
with open('output.txt', 'r', encoding='utf-8') as f:lines = f.readlines()chars = []
tags = []
for line in lines:if line.strip():parts = line.strip().split()chars.append(parts[0])# 最后一列是预测的标签tags.append(parts[-1])else:# 遇到空行,处理一个句子if chars:result = convert_bmes_to_words(chars, tags)print(result)chars = []tags = []
第六步:评估分词结果
可以使用标准的分词评估指标(准确率、召回率、F1值)评估分词结果:
from sklearn.metrics import precision_recall_fscore_supportdef evaluate_segmentation(gold_file, pred_file):"""评估分词结果"""gold_sents = [line.strip() for line in open(gold_file, 'r', encoding='utf-8')]pred_sents = [line.strip() for line in open(pred_file, 'r', encoding='utf-8')]gold_words = []pred_words = []for gold, pred in zip(gold_sents, pred_sents):gold_words.extend(gold.split())pred_words.extend(pred.split())precision, recall, f1, _ = precision_recall_fscore_support(gold_words, pred_words, average='binary')print(f"Precision: {precision:.4f}")print(f"Recall: {recall:.4f}")print(f"F1 Score: {f1:.4f}")
3. 实战工具二:Python库 sklearn-crfsuite
3.1 sklearn-crfsuite简介
sklearn-crfsuite是一个Python库,它封装了CRFsuite,并提供了类似scikit-learn的API,使得在Python中使用CRF变得简单而直观。
主要特点:
- Python友好:完全的Python接口,无需命令行操作
- scikit-learn兼容:符合scikit-learn的API设计,易于集成到现有流程
- 灵活的特征提取:可以直接在Python中定义特征提取函数
- 简化的参数调优:可与scikit-learn的网格搜索等工具集成
3.2 安装
pip install sklearn-crfsuite
sklearn-crfsuite依赖python-crfsuite,后者会自动安装。
3.3 核心用法
特征提取
与CRF++不同,sklearn-crfsuite允许直接在Python中定义特征提取函数,大大增加了灵活性。特征通常表示为字典列表:
def word2features(sent, i):"""为句子中的第i个词提取特征"""word = sent[i][0]features = {'bias': 1.0,'word': word,'word.lower()': word.lower(),'word[-3:]': word[-3:],'word[-2:]': word[-2:],'word.isupper()': word.isupper(),'word.istitle()': word.istitle(),'word.isdigit()': word.isdigit()}# 前一个词的特征if i > 0:word1 = sent[i-1][0]features.update({'-1:word': word1,'-1:word.lower()': word1.lower(),'-1:word.istitle()': word1.istitle(),'-1:word.isupper()': word1.isupper()})else:features['BOS'] = True # Beginning of sentence# 后一个词的特征if i < len(sent) - 1:word1 = sent[i+1][0]features.update({'+1:word': word1,'+1:word.lower()': word1.lower(),'+1:word.istitle()': word1.istitle(),'+1:word.isupper()': word1.isupper()})else:features['EOS'] = True # End of sentencereturn featuresdef sent2features(sent):return [word2features(sent, i) for i in range(len(sent))]def sent2labels(sent):return [label for token, label in sent]def sent2tokens(sent):return [token for token, label in sent]
模型训练
import sklearn_crfsuite# 假设训练数据已经准备好
train_sents = [[('I', 'PRP'), ('love', 'VB'), ('New', 'NNP'), ('York', 'NNP'), ('.', '.')],[('He', 'PRP'), ('hates', 'VBZ'), ('Washington', 'NNP'), ('.', '.')]
]# 提取特征
X_train = [sent2features(s) for s in train_sents]
y_train = [sent2labels(s) for s in train_sents]# 创建CRF模型
crf = sklearn_crfsuite.CRF(algorithm='lbfgs', # 优化算法c1=0.1, # L1正则化系数c2=0.1, # L2正则化系数max_iterations=100, # 最大迭代次数all_possible_transitions=True # 包含所有可能的转移
)# 训练模型
crf.fit(X_train, y_train)
模型预测
# 假设测试数据已经准备好
test_sents = [[('She', 'PRP'), ('loves', 'VBZ'), ('Chicago', 'NNP'), ('.', '.')]
]# 提取特征
X_test = [sent2features(s) for s in test_sents]# 预测
y_pred = crf.predict(X_test)
print(y_pred)
模型评估
sklearn-crfsuite提供了方便的评估工具:
from sklearn_crfsuite import metrics# 获取所有标签
labels = list(crf.classes_)
# 去掉 'O' 标签
labels.remove('O')# 计算F1分数
f1_score = metrics.flat_f1_score(y_test, y_pred, average='weighted', labels=labels)
print(f'F1 Score: {f1_score:.4f}')# 详细的分类报告
report = metrics.flat_classification_report(y_test, y_pred, labels=labels, digits=3
)
print(report)
3.4 实战案例:命名实体识别(NER)
让我们使用sklearn-crfsuite实现一个命名实体识别的例子。

第一步:准备数据
我们将使用CoNLL-2003格式的数据。这种格式中,每个词占一行,包含多个列(如单词、词性、标签等),句子之间用空行分隔。
# 读取CoNLL格式数据
def read_conll_data(file_path):sentences = []sentence = []with open(file_path, 'r', encoding='utf-8') as f:for line in f:line = line.strip()if line:# 假设格式为:词 词性 标签parts = line.split()if len(parts) >= 3:word, pos, tag = parts[0], parts[1], parts[2]sentence.append((word, pos, tag))else:if sentence:sentences.append(sentence)sentence = []if sentence: # 处理文件末尾没有空行的情况sentences.append(sentence)return sentences
第二步:特征提取
针对NER任务,我们设计更丰富的特征:
def word2features(sent, i):word = sent[i][0]postag = sent[i][1]features = {'bias': 1.0,'word.lower()': word.lower(),'word[-3:]': word[-3:],'word[-2:]': word[-2:],'word.isupper()': word.isupper(),'word.istitle()': word.istitle(),'word.isdigit()': word.isdigit(),'postag': postag,'postag[:2]': postag[:2],}# 前一个词的特征if i > 0:word1 = sent[i-1][0]postag1 = sent[i-1][1]features.update({'-1:word.lower()': word1.lower(),'-1:word.istitle()': word1.istitle(),'-1:word.isupper()': word1.isupper(),'-1:postag': postag1,'-1:postag[:2]': postag1[:2],})else:features['BOS'] = True# 前两个词的特征if i > 1:word2 = sent[i-2][0]postag2 = sent[i-2][1]features.update({'-2:word.lower()': word2.lower(),'-2:word.istitle()': word2.istitle(),'-2:postag': postag2,'-2:postag[:2]': postag2[:2],})# 后一个词的特征if i < len(sent)-1:word1 = sent[i+1][0]postag1 = sent[i+1][1]features.update({'+1:word.lower()': word1.lower(),'+1:word.istitle()': word1.istitle(),'+1:postag': postag1,'+1:postag[:2]': postag1[:2],})else:features['EOS'] = True# 后两个词的特征if i < len(sent)-2:word2 = sent[i+2][0]postag2 = sent[i+2][1]features.update({'+2:word.lower()': word2.lower(),'+2:word.istitle()': word2.istitle(),'+2:postag': postag2,'+2:postag[:2]': postag2[:2],})return featuresdef sent2features(sent):return [word2features(sent, i) for i in range(len(sent))]def sent2labels(sent):return [label for token, postag, label in sent]
第三步:训练和评估模型
import sklearn_crfsuite
from sklearn_crfsuite import metrics
from sklearn.model_selection import train_test_split# 读取数据
data = read_conll_data('ner_data.txt')# 划分训练集和测试集
train_data, test_data = train_test_split(data, test_size=0.2, random_state=42)# 提取特征
X_train = [sent2features(s) for s in train_data]
y_train = [sent2labels(s) for s in train_data]
X_test = [sent2features(s) for s in test_data]
y_test = [sent2labels(s) for s in test_data]# 训练模型
crf = sklearn_crfsuite.CRF(algorithm='lbfgs',c1=0.1,c2=0.1,max_iterations=100,all_possible_transitions=True
)
crf.fit(X_train, y_train)# 预测
y_pred = crf.predict(X_test)# 评估
labels = list(crf.classes_)
if 'O' in labels:labels.remove('O') # 通常我们更关心非O标签的性能# 计算F1分数
f1_score = metrics.flat_f1_score(y_test, y_pred, average='weighted', labels=labels)
print(f'F1 Score: {f1_score:.4f}')# 详细的分类报告
report = metrics.flat_classification_report(y_test, y_pred, labels=labels, digits=3
)
print(report)
第四步:参数调优
sklearn-crfsuite可以与scikit-learn的网格搜索结合,进行参数调优:
from sklearn.model_selection import RandomizedSearchCV
import scipy.stats as stats# 参数空间
params_space = {'c1': stats.expon(scale=0.5),'c2': stats.expon(scale=0.05),
}# 定义评分函数
def f1_score_weighted(y_true, y_pred):labels = list(set(y_true))if 'O' in labels:labels.remove('O')return metrics.flat_f1_score(y_true, y_pred, average='weighted', labels=labels)# 创建优化器
rs = RandomizedSearchCV(crf, params_space,cv=3,verbose=1,n_jobs=-1,n_iter=20,scoring=f1_score_weighted
)# 执行参数优化
rs.fit(X_train, y_train)# 打印最佳参数
print('最佳参数:', rs.best_params_)
print('最佳F1分数:', rs.best_score_)# 使用最佳参数的模型
crf = rs.best_estimator_
4. 工具对比与选择
CRF++和sklearn-crfsuite各有优缺点,选择哪个取决于你的具体需求:

CRF++的优势
- 性能:C++实现,运行速度快,适合大规模数据
- 多线程支持:训练速度可通过多线程大幅提升
- 内存效率:对大数据集的内存管理更高效
- 成熟稳定:广泛使用多年,bug较少
CRF++的局限
- 命令行界面:操作不如Python库直观
- 特征工程:需要通过模板文件定义,相对死板
- 集成难度:与其他系统集成需要额外工作
- 学习曲线:初学者可能需要更多时间上手
sklearn-crfsuite的优势
- Python集成:与Python生态系统无缝集成
- 灵活的特征工程:可以直接在Python中定义特征提取逻辑
- 用户友好:API设计简洁直观
- 与scikit-learn兼容:可以方便地使用网格搜索等工具优化参数
sklearn-crfsuite的局限
- 性能:比纯C++实现略慢
- 可扩展性:对于超大规模数据集,可能不如CRF++高效
- 依赖Python:需要Python环境
适用场景建议
-
选择CRF++:
- 处理大规模数据集(数百万条记录以上)
- 追求最高的运行速度
- 在生产环境中部署,要求稳定性
- 计算资源有限
-
选择sklearn-crfsuite:
- 快速原型设计和实验
- 已经在Python中处理数据
- 需要频繁调整特征工程
- 与scikit-learn等Python库集成
- 对速度要求不是特别高
在实际项目中,也可以先用sklearn-crfsuite进行快速实验和特征设计,然后在确定最终方案后,将模型迁移到CRF++以获得更好的性能。
5. 总结与展望
本文详细介绍了CRF的两种实用工具:命令行工具CRF++和Python库sklearn-crfsuite。我们通过具体的实战案例展示了从数据准备、特征工程、模型训练到评估的完整流程。
关键要点回顾:
- CRF++的核心命令、文件格式和模板语法
- sklearn-crfsuite的API使用、特征提取和模型评估
- 两种工具的优缺点和适用场景
通过本文的学习,你应该能够开始使用CRF解决实际的序列标注问题,如中文分词、命名实体识别、词性标注等。
在下一篇文章**【CRF系列】第8篇:CRF与深度学习的融合:BiLSTM-CRF模型**中,我们将探讨如何将CRF与深度学习模型结合,构建更强大的序列标注系统。
6. 练习
-
使用CRF++训练一个简单的命名实体识别模型:
- 下载CoNLL-2003数据集的示例部分
- 设计适合NER任务的模板文件
- 训练模型并评估在测试集上的性能
-
使用sklearn-crfsuite完成一个中文分词任务:
- 设计针对中文的特征提取函数
- 使用随机搜索找到最佳参数设置
- 比较不同特征组合对分词性能的影响