Deeplizard 深度学习课程(一)—— Pytorch 和 Tensor 简介
前言
该pytorch笔记参考deeplizard官方网站课程,有相应视频和博客,链接如下:
deeplizard![]() https://deeplizard.com/learn/video/v5cngxo4mIg
https://deeplizard.com/learn/video/v5cngxo4mIg
1.Pytorch 简介
PyTorch 是一个深度学习框架和一个科学计算包。PyTorch 的科学计算方面主要是 PyTorch 的张量库和关联张量操作的结果。PyTorch 是由 Facebook 创建和维护的,其前身为Torch(基于Lua编程语言)。
PyTorch 使用称为动态计算图的计算图(computational graphs),来绘制神经网络内部张量上发生的函数运算,动态意味着图形是在创建作时动态生成的。
1.1 PyTorch 包
| Package | Description | 说明 |
| torch | The top-level PyTorch package and tensor library | 最上层 |
| torch.nn | A subpackage that contains modules and extensible classes for building neural networks | 子包:包含构造神经网络的模块和可扩展类 |
| torch.autograd | A subpackage that supports all the differentiable Tensor operations in PyTorch. | 子包:支持Tensor的导数运算 |
| torch.nn.functional | A functional interface that contains typical operations used for building neural networks like loss functions, activation functions, and convolution operations. | 函数接口:包含构建神经网络的经典操作,如损失函数、卷积运算 |
| torch.optim | A subpackage that contains standard optimization operations like SGD and Adam. | 子包:包含经典的优化操作 |
| torch.utils | A subpackage that contains utility classes like data sets and data loaders that make data preprocessing easier. | 子包:包含实用程序(如数据集、数据加载器) |
| torchvision | A package that provides access to popular datasets, model architectures, and image transformations for computer vision. | 包:提供计算机视觉常用的数据集、架构等 |
1.2 why GPU
GPU(Graphics Processing Unit,图形处理单元)是一种处理特殊计算的处理器,专门为并行计算设计,最初用于图像处理(如3D渲染、图形加速),现也用于AI训练、大规模数据处理等。
这与CPU(Central Processing Unit,中央处理器)形成鲜明对比,CPU擅长处理逻辑复杂、顺序性强的任务,比如操作系统调度、网页浏览、文本编辑、程序运行等。
并行计算是一种计算类型,通过特定计算被分解为可以同时执行的独立较小的计算。较大任务可以分解的任务数取决于特定硬件上包含的内核数。内核是处理器中实际执行计算的单元,CPU 通常有 4 、8 或 16 个内核,每个核心都很强大,而 GPU 可能有数千个小而高效的内核,因此适合处理高度并行的任务。
之前听到过一个比较易懂的理解:CPU相当于一个博士生,可以完成非常复杂的工作;而GPU相当于很多个独立的高中生,可以同时完成很多简单的任务。
AI的核心是对神经网络的计算,而神经网络的底层是矩阵运算,矩阵运算又可以拆分成很多可以并行计算的乘法和加法运算,所以选择GPU较为合适。而随着矩阵维度的升高,GPU中的CUDA核心也难以满足计算要求,于是GPU就又发展出了一个模块,Tensor Core专门用于神经网络的参数计算,这种GPU被称作GPGPU。
1.3 CUDA / mps
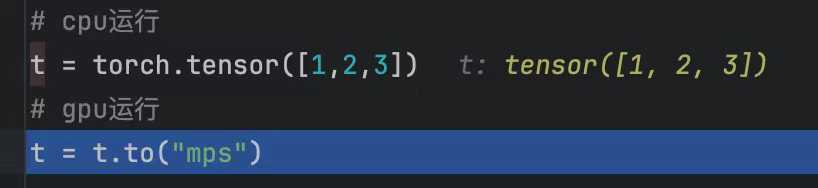
GPU是支持并行计算的硬件,而CUDA就可以理解为为开发者提供API的软件层,现在CUDA是pytorch的内置库,无需额外下载。mac需要将cuda改为mps。

2.Tensor 简介
2.1 深度学习的数据结构
tensor 是一个泛化的数据结构,因为标量是零维tensor,矢量是一维tensor,矩阵是二维tensor ...... n维数组是一个n维tensor;tensor的索引是从0开始编号

要注意区分 tensor 的维度 和 向量空间中向量的维度,tensor的维数并没有告诉我们tensor中有几个分量。例如二维向量空间中的向量有x、y两个分量,但二维tensor可以有9个分量。

2.2 Rank、Axes 和 Shape
| 三个最核心的属性 | 定义(理解) | 示例 |
| Rank(秩) | tensor的维度(访问tensor中元素所需的索引数;tensor的轴数) | dd 需要两个指标访问具体元素 dd [0] [2] ----> 3 |
| Axes(轴) | tensor的某一个特定维度 |   |
| Shape(形状) | 张量的形状由每个轴的长度决定 (shape只会改变元素的分组,但元素本身并未改变) | dd 的形状为【3,3】 说明秩为2,有两个轴,每个轴长度为3 |
例:下面 tensor 的 shape ? 【1,2,4】 / 1 ✖️ 2 ✖️ 4

2.3 CNN的tensor输入
卷积神经网络是图像识别任务的首选网络,因为它们非常适合检测空间模式。

CNN的tensor输入一般rank为4,即有四个轴,可以写作【B,C,H,W】对应【批量大小、颜色通道、高度、宽度】。高度和宽度比较好理解;所谓颜色通道常用的值如 3(RGB图像,红绿蓝)、1(灰度图像);批处理大小是指在CNN中,我们通常处理批量样本,因此这个维度是指相应批次中有多少样本。

取出其中的一个样本,我们用三个滤波器分别对颜色通道做卷积操作,可以得到右侧的三个特征图,这个过程称为特征映射。特征图是从卷积创建的输出通道。

由于我们有三个卷积滤波器,因此我们将有三个来自卷积层的通道输出。这些通道是卷积层的输出,因此名称为 output channels,而不是颜色通道。(相当于第二个轴的意义改变了)
2.4 PyTorch Tensors 详解
数据预处理的一个目标是将原始输入数据转换为神经网络能接受的tensor形式。
- torch.Tensor类的实例创建 及 属性
import numpy as np import torcht = torch.Tensor() print(type(t)) # <class 'torch.Tensor'>print(t.dtype) # torch.float32 print(t.device) # cpu print(t.layout) # torch.strided # layout为布局方式,布局指定了张量在内存中的存储方式 - Tensor 中的数据类型(dtype)
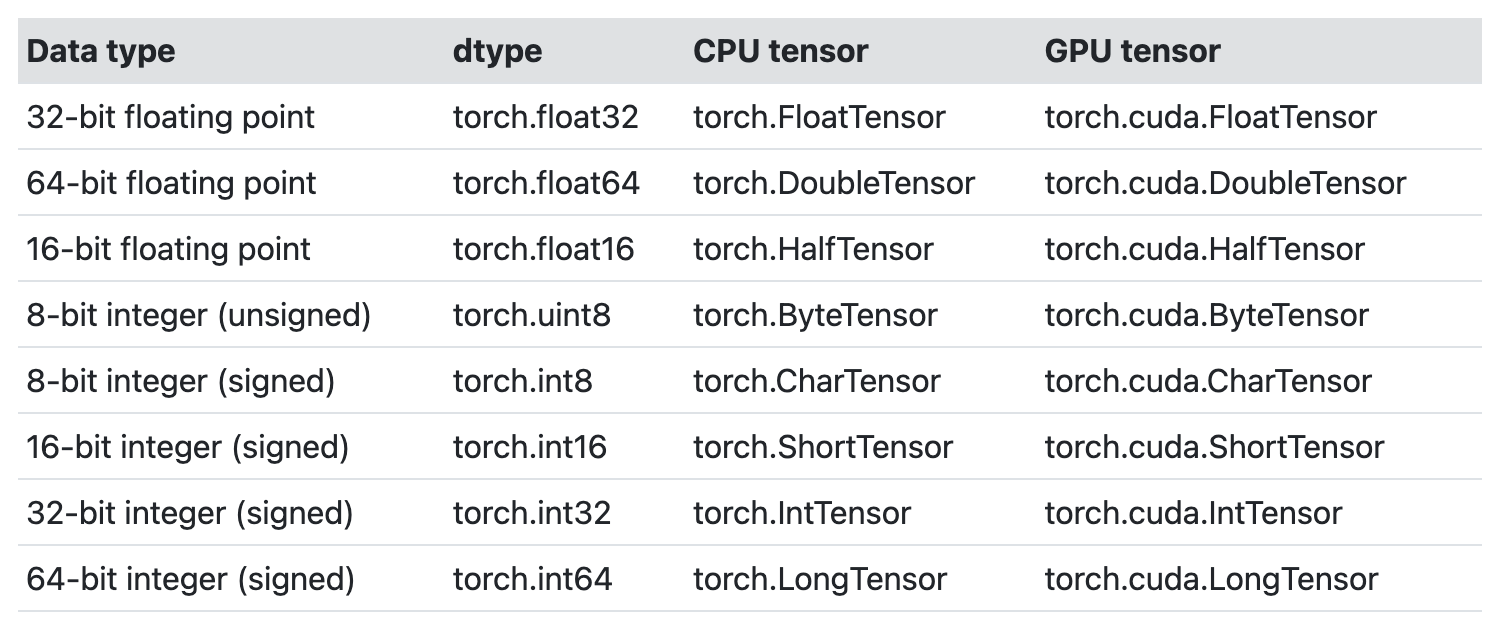
tensor包含相同类型的数值数据,每种类型都有CPU和GPU两个版本,决定了tensor运算的位置。这里要注意,tensor之间的数据运算 必须是相同类型相同device的tensor。