c++原子操作
原子操作,顾名思义,该操作不可分割。多线程环境也能保证读写数据不错乱。百度搜索了下,其核心概念如下:
1、不可分割性。原子操作是指一系列不可被CPU上下文交换的机器指令,操作要么完全执行,要么完全不执行,其他线程无法观察到中间状态。
2、可见性和顺序性。原子操作确保对变量的修改在所有线程中立即可见,并可通过内存顺序(如memory_order_relaxed、memory_order_seq_cst)控制操作的全局顺序一致性。
为了验证上面结论,测试下。 下面是开启10个线程执行同一个函数,将一个变量增加10000次,最终期望该变量值为100000,代码如下:
#include <iostream>
#include "listNode.h"
#include "solution.h"
#include <algorithm>
#include <unordered_set>
#include <unordered_map>
#include <map>
#include <string>
#include <stdio.h>
#include <stdlib.h>
#include "solution3.h"
#include "dataDefine.h"
#include "uthash.h"
#include "IntArrayList.h"
#include <string.h>
#include <thread>
#include <atomic>static std::atomic<int> count2{0}; // 原子整型
// 或这样写:
//static std::atomic<int> count2(0);void task2(int id) {for (auto i = 0; i < 10000; i++) {count2.fetch_add(1); // 值自增1}cout << "id:" << id << ", threadID:" << std::this_thread::get_id() << " finish" << endl;
}void testTread2() {vector<thread> threads;for (auto i = 0; i < 10; i++) {thread t(task2, i); // i是task2函数的参数threads.emplace_back(std::move(t)); // 线程不可拷贝,只能移动。不能直接传t, 或者直接这样:threads.emplace_back(task2, i);}for (auto& t : threads) {//cout << "thread id: " << t.get_id() << " invoke join in" << endl;t.join(); // 当前线程(即主线程)等待这个线程执行完毕。}cout << "count2 value: " << count2 << endl;
}int main() {testTread2();
}测试结果:
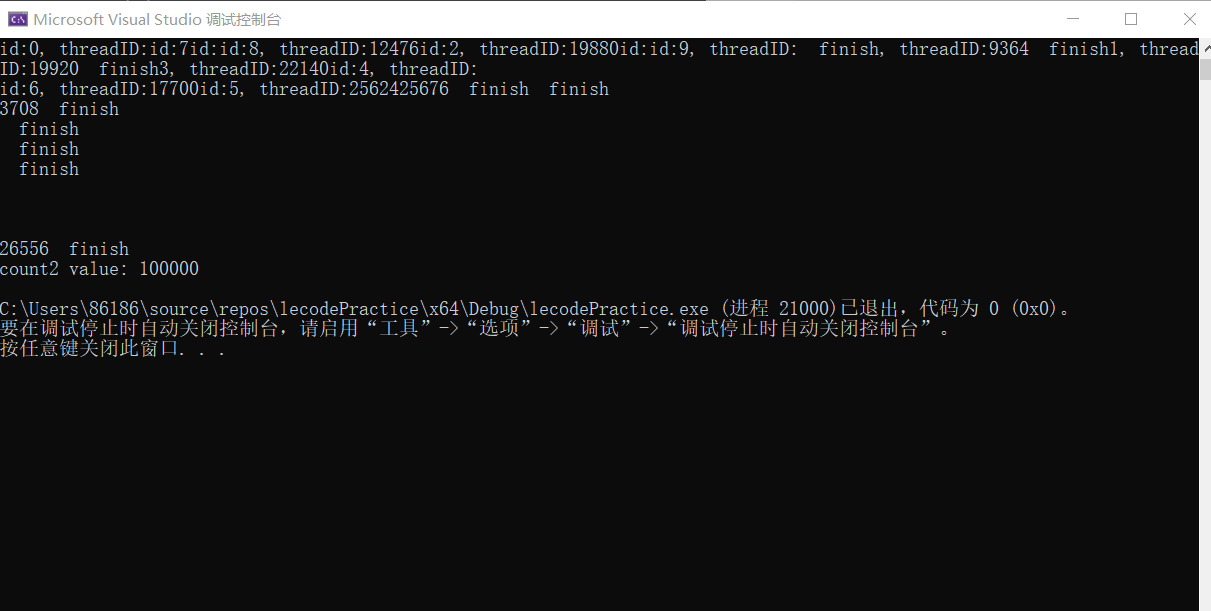
ok! 和预期结果一致。
再测试下非原子操作。下面操作是开启10个线程执行同一个函数,将一个变量增加10000次,最终期望该变量值为100000, 代码示例:
#include <iostream>
#include "listNode.h"
#include "solution.h"
#include <algorithm>
#include <unordered_set>
#include <unordered_map>
#include <map>
#include <string>
#include <stdio.h>
#include <stdlib.h>
#include "solution3.h"
#include "dataDefine.h"
#include "uthash.h"
#include "IntArrayList.h"
#include <string.h>
#include <thread>
#include <atomic>static auto count1 = 0;
void task1(int id) {for (auto i = 0; i < 10000; i++) {count1++;}cout << "id:" << id << ", threadID:" << std::this_thread::get_id() << " finish" << endl;
}void testTread1() {vector<thread> threads;for (auto i = 0; i < 20; i++) {threads.emplace_back(task1, i); // i是task1函数的参数// 或者这样构造一个线程//thread t(task1, i);}for (auto& t : threads) {//cout << "thread id: " << t.get_id() << " invoke join in" << endl;t.join(); // 当前线程(即主线程)等待这个线程执行完毕。}cout << "count1 value: " << count1 << endl;
}int main() {testTread1();
}测试打印结果:
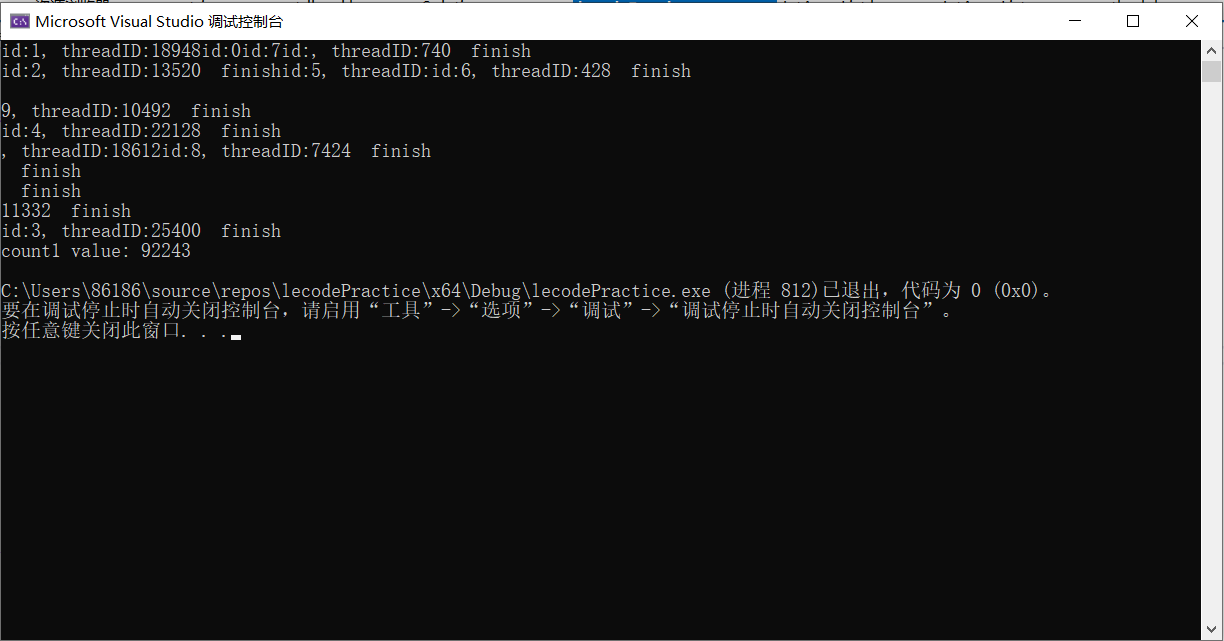
打印 count1 value:92243, 和期望值不一致,每次执行结果都是不确定的值。而且日志也打印的乱糟糟。
结论:非原子操作,以上示例,多线程调用同一个函数,没有对线程进行同步, 导致读写数据错乱,比如线程1读取该变量值为10, 可能同时线程2也读取到该变量值为10,然后都加1,结果变量值变为11被写回。所以最终结果会小于预期值。