《What Are Step-Level Reward Models Rewarding?》全文翻译
《What Are Step-Level Reward Models Rewarding?Counterintuitive Findings from MCTS-Boosted Mathematical Reasoning》
Step-Level奖励模型到底奖励了什么?来自基于MCTS提升的数学推理的反直觉发现
摘要
Step-level奖励模型(SRMs)通过过程监督或基于强化学习的步级偏好对齐,可以显著提升数学推理性能。SRMs的表现至关重要,因为它们作为关键指引,确保推理过程中的每一步都与期望的结果保持一致。近年来,类似AlphaZero的方法中,利用蒙特卡洛树搜索(MCTS)进行自动的步级偏好标注,证明了其特别有效。然而,SRMs成功背后的具体机制尚未得到充分探究。为弥补这一空白,本研究深入分析了SRMs的反直觉特征,尤其聚焦于基于MCTS的方法。我们的发现显示,移除对思维过程的自然语言描述对SRMs的效果影响甚微。此外,我们证明SRMs擅长评估数学语言中复杂的逻辑一致性,但在自然语言上的表现较差。这些见解为理解驱动有效步级奖励建模的核心要素提供了细致入微的认知。通过阐明这些机制,本研究为开发更高效且简化的SRMs提供了宝贵指导,表明聚焦数学推理关键部分即可实现目标。
引言
大规模语言模型(LLMs)已展示其在广泛任务上的卓越能力,如信息抽取、自然语言理解等(Zhao等,2023),彻底革新了深度学习领域。在这些能力中,推理尤为关键,尤其是数学推理,由于其复杂性,亟需进一步提升。众多研究表明,多步推理,通常借助Chain-of-Thought(CoT)提示,能够显著改善模型在推理任务上的表现(Zhou等,2023;Besta等,2024;Ding等,2023;Yao等,2024;Wang等,2022;Wei等,2022;Zheng等,2024;Li等,2024;Zhan等,2024)。
近来,受导向的树搜索方法进一步提升了推理能力,通过在线模拟探索多条推理路径,以找出最优解路径(Hao等,2023,2024;Feng等,2023)。尽管更优的推理路径带来更好表现,但推理链长导致搜索空间呈指数级增长,计算成本大幅提升。鉴于LLM推理本身代价高昂,对每道推理问题进行在线树搜索会带来重复且不必要的开销。
为解决该问题,提出了步级奖励模型(SRM)。Lightman等(2023)引入了过程奖励模型(PRM),采用人工注解的步级评分进行奖励建模;而Ma等(2023)进一步证实SRMs在数学推理和编程任务中的有效性。随后,Math-Shepherd(Wang等,2024)通过穷举推理过程遍历,系统地生成步级偏好数据以训练奖励模型,加强模型能力。更近期地,受AlphaZero启发,蒙特卡洛树搜索(MCTS)(Xie等,2024;Chen等,2024a,b)被用来更高效地收集偏好,利用其平衡探索与利用的能力。这些训练出来的SRMs能通过训练阶段的近端策略优化(PPO)协助步级偏好对齐,或者在推理阶段作为步骤验证器,有效提升推理表现。
尽管基于MCTS的方法构建的SRMs在数学推理上取得显著成就,它们的具体工作原理及究竟奖励了什么,仍未清晰。认知科学家和脑科学家指出,丰富的思考与推理过程不必然依赖自然语言(Fedorenko, Piantadosi, 和 Gibson,2024)。例如,一名熟练的数学家能判断数学表达式的逻辑一致及数值正确性,而不依赖自然语言。借此思想,我们提出针对LLM的类似假设:自然语言对数学推理而言非必需。我们推测,LLMs可直接对数学语言中的推理步骤学习偏好,而非依赖自然语言描述。这意味着LLMs或能通过数学语言的内在结构理解与处理数学推理,有望带来更高效、更加聚焦的训练方法,跳过自然语言解释的需求。此外,错误解答往往源于错误的数学计算或逻辑失误(Zhang等,2024),后者更具挑战性(Chen等,2024a)。因此,我们进一步探索SRMs在评估纯数学语言逻辑一致性方面的效力,表明改进并非仅是鼓励单步中计算正确。更令人意外的是,SRMs在学习评估自然语言中逻辑一致性时遇到困难,这进一步支持自然语言对步级奖励建模的非必要性。
为探究自然语言与数学语言在步级奖励建模中的不同作用,我们将推理路径的每一步拆分为两部分:思考过程的自然语言描述和数学表达式(见图1)。通过选择性地从SRM输入中剔除不同部分进行消融分析。此拆分模拟了人类数学问题解决中的典型流程,通常包含先思考策略,继而执行相关计算。思考过程包括该步应采用的策略,而计算则执行该思路。换言之,我们的拆分旨在将构成“思考”的自然语言与包含“思考”执行的数学表达式区分开,以期深入理解自然语言在步级奖励建模中的作用。
总而言之,实验结果支持SRMs对数学表达式有内在亲和力,而非自然语言。具体而言,我们总结如下关键见解:
-
思考过程的自然语言描述对成功进行步级奖励建模并非必须。
-
SRMs不仅推动单步计算准确,还能有效评估数学语言中具挑战性的逻辑一致性。
-
评估自然语言中的逻辑一致性较困难,SRMs往往难以胜任。
预备知识
马尔科夫决策过程
定义:马尔科夫决策过程(MDP)是一种用来建模决策问题的数学框架,广泛应用于强化学习(RL)领域,处理部分随机且部分可控的环境。MDP由五元组 ( S , A , P , R , γ ) (S, A, P, R, \gamma) (S,A,P,R,γ)定义,其中:
-
S S S为状态集合。
-
A A A为动作集合。
-
P P P为状态转移概率函数, P ( s t + 1 ∣ s t , a t ) P(s_{t+1} | s_t, a_t) P(st+1∣st,at),定义在状态 s t s_t st采取动作 a t a_t at后转移到状态 s t + 1 s_{t+1} st+1的概率。
-
R R R为奖励函数, R ( s t , a t , s t + 1 ) R(s_t, a_t, s_{t+1}) R(st,at,st+1),定义从状态 s t s_t st通过动作 a t a_t at转移到状态 s t + 1 s_{t+1} st+1后获得的即时奖励。
-
γ \gamma γ为折扣因子,决定未来奖励的重要性。
贝尔曼期望方程:
状态价值函数 V ( s ) V(s) V(s)的贝尔曼期望方程为: V π ( s ) = E a ∼ π ( ⋅ ∣ s ) [ E s ′ ∼ P ( ⋅ ∣ s , a ) [ R ( s , a , s ′ ) + V π ( s ′ ) ] ] V^{\pi}(s) = \mathbb{E}_{a \sim \pi(\cdot|s)} \left[ \mathbb{E}_{s' \sim P(\cdot|s,a)} \left[ R(s,a,s') + V^{\pi}(s') \right] \right] Vπ(s)=Ea∼π(⋅∣s)[Es′∼P(⋅∣s,a)[R(s,a,s′)+Vπ(s′)]]状态-动作价值函数 Q ( s , a ) Q(s,a) Q(s,a)的贝尔曼期望方程为: Q π ( s , a ) = E s ′ ∼ P ( ⋅ ∣ s , a ) [ R ( s , a , s ′ ) + E a ′ ∼ π ( ⋅ ∣ s ′ ) [ Q π ( s ′ , a ′ ) ] ] Q^{\pi}(s,a) = \mathbb{E}_{s' \sim P(\cdot|s,a)} \left[ R(s,a,s') + \mathbb{E}_{a' \sim \pi(\cdot|s')} \left[ Q^{\pi}(s',a') \right] \right] Qπ(s,a)=Es′∼P(⋅∣s,a)[R(s,a,s′)+Ea′∼π(⋅∣s′)[Qπ(s′,a′)]]最优价值函数定义为:
KaTeX parse error: Undefined control sequence: \* at position 13: \begin{align\̲*̲} V^{\*}(s) & =…
最优价值函数与最优贝尔曼方程的关系为:
V ∗ ( s ) = max a Q ∗ ( s , a ) (2) V^{*}(s) = \max_{a} Q^{*}(s,a) \tag{2} V∗(s)=amaxQ∗(s,a)(2)
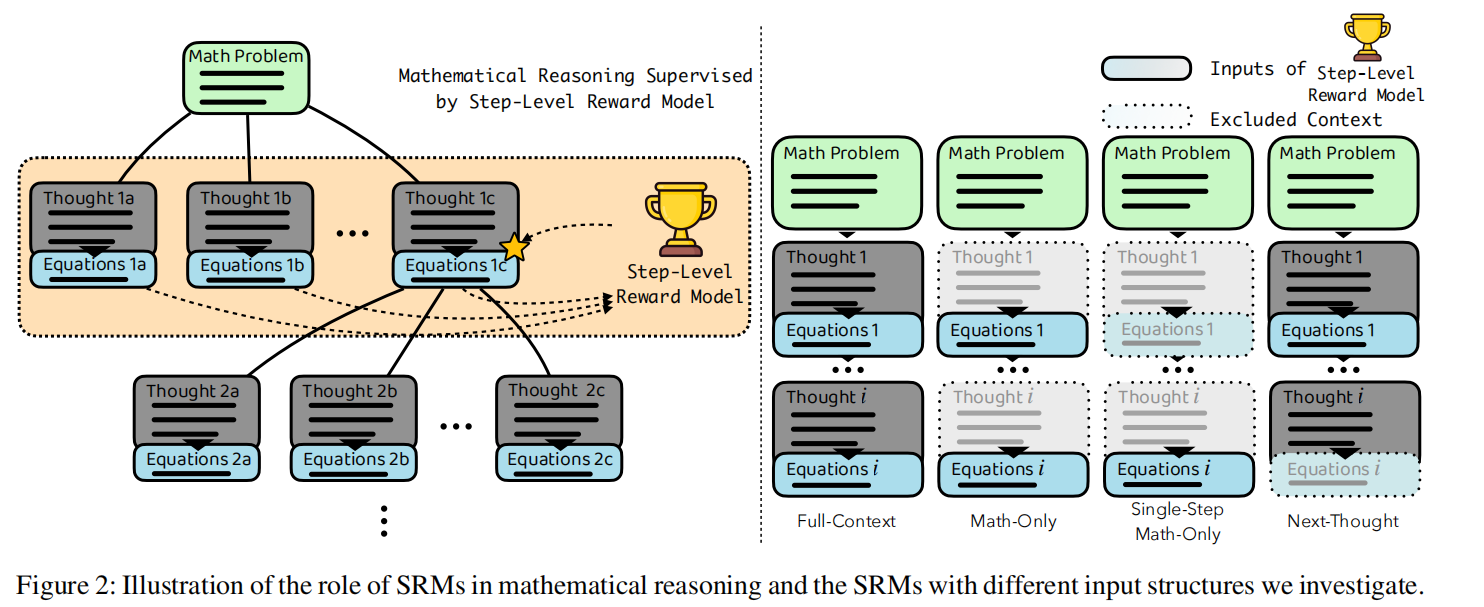
图2:数学推理中SRMs的作用示意及我们调查的不同输入结构的SRMs示意。
方法论
将LLM的数学推理视为MDP:我们的定义}
图2展示了数学推理过程,每步拆分为思考和数学表达式两部分。具体的MDP定义如下: M D P = ( S , A , P , R ) \mathrm{MDP} = (S, A, P, R) MDP=(S,A,P,R)其中:
-
状态空间 S S S由状态 s i = ( T k , E k ) k = 0 i s_i = \left(T_k, E_k\right)_{k=0}^i si=(Tk,Ek)k=0i组成,代表截至步骤 i i i的思考序列 T k T_k Tk与数学表达式序列 E k E_k Ek。
-
动作空间 A A A由动作 a i = T i + 1 a_i = T_{i+1} ai=Ti+1组成,表示LLM生成的下一步思考的自然语言描述。
-
状态转移函数 P ( s i + 1 ∣ s i , a i ) P(s_{i+1} | s_i, a_i) P(si+1∣si,ai)定义了在状态 s i s_i si采取动作 a i a_i ai后转移至 s i + 1 s_{i+1} si+1的概率。该函数由LLM实现,即基于下一思考 a i = T i + 1 a_i = T_{i+1} ai=Ti+1和现有状态 s i = ( T k , E k ) k = 0 i s_i = (T_k, E_k)_{k=0}^i si=(Tk,Ek)k=0i,生成对应数学表达式 E i + 1 E_{i+1} Ei+1。
-
奖励函数 R ( s i , a i , s i + 1 ) R(s_i, a_i, s_{i+1}) R(si,ai,si+1)定义了从状态 s i s_i si经过动作 a i a_i ai转移至 s i + 1 s_{i+1} si+1获得的即时奖励。我们根据最终答案是否正确,定义奖励为:
R ( s i , a i , s i + 1 ) = { 1 , 最终答案正确 0 , 最终答案错误 (3) R(s_i, a_i, s_{i+1}) = \begin{cases} 1, & \text{最终答案正确} \\ 0, & \text{最终答案错误} \end{cases} \tag{3} R(si,ai,si+1)={1,0,最终答案正确最终答案错误(3)
此外,策略 π ( a i ∣ s i ) \pi(a_i| s_i) π(ai∣si)由LLM实现,即根据当前状态 s i = ( T k , E k ) k = 0 i s_i = (T_k, E_k)_{k=0}^i si=(Tk,Ek)k=0i生成下一步思考 a i = T i + 1 a_i = T_{i+1} ai=Ti+1。基于式(1),智能体的目标是在每一步生成正确思考 T T T以最大化 V π ( s i ) V_\pi (s_i) Vπ(si)或 Q π ( s i , a ) Q_\pi (s_i, a) Qπ(si,a)。
总结:
语言模型在MDP框架中承担双重角色:
-
作为智能体(Agent):LLM依据策略 π ( a i ∣ s i ) \pi(a_i|s_i) π(ai∣si)在每个状态选择合适动作(下一步思考 T i + 1 T_{i+1} Ti+1)。
-
作为世界模型(World Model):LLM也充当状态转移函数 P ( s i + 1 ∣ s i , a i ) P(s_{i+1} | s_i, a_i) P(si+1∣si,ai),根据内在知识和训练数据预测动作结果,模拟数学推理环境,通过执行思考 T i + 1 T_{i+1} Ti+1及对应计算,输出新状态 s i + 1 s_{i+1} si+1。
基于MCTS的步级偏好采集}
数学推理与MDP的天然对应关系使我们可利用蒙特卡洛树搜索(MCTS)高效采集步级偏好。MCTS从根节点 s 0 s_0 s0(数学问题)开始,每个新节点代表状态更新。MCTS的每次迭代包含四个阶段:选择、扩展、模拟和回传。
- 选择。自根节点 s 0 s_0 s0起,沿树遍历至叶节点,利用上置信界(UCT)策略平衡探索与利用。在节点 s i s_i si,按式:
s i + 1 ∗ = arg max s i + 1 [ c ( s i + 1 ) N ( s i + 1 ) + w exp ⋅ log N ( s i ) N ( s i + 1 ) ] (4) s_{i+1}^* = \arg\max_{s_{i+1}} \left[ \frac{c(s_{i+1})}{N(s_{i+1})} + w_{\exp} \cdot \sqrt{\frac{\log N(s_i)}{N(s_{i+1})}} \right] \tag{4} si+1∗=argsi+1max[N(si+1)c(si+1)+wexp⋅N(si+1)logN(si)](4)
其中 c ( s i + 1 ) c(s_{i+1}) c(si+1)为正确计数, N ( s i ) N(s_i) N(si)与 N ( s i + 1 ) N(s_{i+1}) N(si+1)是访问计数, w exp w_{\exp} wexp平衡探索与利用。重复此过程至发现未扩展节点。
2. 扩展。到达叶节点后,代理生成 n n n个候选动作(思考) { a i j ∣ j = 1 , . . . , n } \{a_i^j| j=1,...,n\} {aij∣j=1,...,n},世界模型基于这些动作执行对应数学计算,构建新候选状态 { s i j ∣ j = 1 , . . . , n } \{s_i^j | j=1,...,n\} {sij∣j=1,...,n}。这些节点作为子节点加入树,拓宽搜索空间。
3. 模拟。模拟阶段从新扩展节点模拟推理至终止状态或设定深度,依据式(3)计算节点得分。此步骤用于估计新节点性能,为回传阶段提供依据。
4. 回传。从最终状态开始,将模拟结果沿路径向上回传,更新节点价值和访问次数,通过提升选择策略质量促进后续迭代。
MCTS完成后,可在树内通过节点值比较采集步级偏好对。
步级奖励建模
在完成偏好对的采集后,即可通过对比学习构造步级奖励模型。依据我们的MDP定义,SRM被视作动作价值函数 Q ( s , a ) Q(s,a) Q(s,a)或状态价值函数 V ( s ) V(s) V(s)。本研究调查四种不同输入格式的SRM进行消融,具体定义见图2右:
- \textbf{全上下文步级奖励模型(FC-SRM)}:输入当前状态的思考和数学表达式组合。
V 1 ( s i ) = V 1 ( ( T k , E k ) k = 0 i ) (5) V_1(s_i) = V_1 \left( (T_k, E_k)_{k=0}^i \right) \tag{5} V1(si)=V1((Tk,Ek)k=0i)(5)
- \textbf{纯数学步级奖励模型(MO-SRM)}:仅输入当前状态的数学表达式序列,不包含自然语言思考描述。
V 2 ( s i ) = V 2 ( ( E k ) k = 0 i ) (6) V_2(s_i) = V_2 \left( (E_k)_{k=0}^i \right) \tag{6} V2(si)=V2((Ek)k=0i)(6)
- \textbf{单步纯数学步级奖励模型(SSMO-SRM)}:仅输入当前步骤最新的数学表达式,不含自然语言也不含先前步骤表达式。
V 3 ( s i ) = V 3 ( E i ) (7) V_3(s_i) = V_3(E_i) \tag{7} V3(si)=V3(Ei)(7)
- \textbf{下一步思考步级奖励模型(NT-SRM)}:输入当前状态的思考和数学表达式,评估下一步思考。根据我们的定义,下一思考即为智能体的动作,故该模型即为动作价值函数。
Q ( s i , a i ) = Q ( ( T k , E k ) k = 0 i , T i + 1 ) (8) Q(s_i, a_i) = Q \left( (T_k, E_k)_{k=0}^i, T_{i+1} \right) \tag{8} Q(si,ai)=Q((Tk,Ek)k=0i,Ti+1)(8)
基于步级奖励模型的束搜索}
训练好SRMs后,常用它们进行步级偏好对齐以更新策略,旨在生成最优动作,减少在线MCTS引入的开销。亦可利用这些偏好数据提升世界模型 P P P的准确度,进而提高数学表现。
\begin{verbatim}
算法1:束搜索算法
输入:初始状态 s 0 s_0 s0,束宽 B B B,候选动作数 c c c
初始化束 B ← { s 0 } \mathcal{B} \leftarrow \{ s_0 \} B←{s0}
当 B \mathcal{B} B非空时循环:
初始化空列表$\mathcal{B}_{next} \leftarrow \emptyset$对每个状态$s_i \in \mathcal{B}$:生成动作候选集$\{ a_i^1, a_i^2, ..., a_i^c \}$对每个动作$a_i^j$:计算后续状态$s_{i+1}^j \leftarrow P(s_{i+1}| s_i, a_i^j)$评估$s_{i+1}^j$得分将$s_{i+1}^j$加入$\mathcal{B}_{next}$按分数对$\mathcal{B}_{next}$排序,保留前$B$个状态更新束$\mathcal{B} \leftarrow$ 前$B$状态
返回最终束中最佳状态
\end{verbatim}
鉴于本研究聚焦于SRMs,实验未包含偏好对齐过程,直接视SRMs为束搜索的打分函数,简化流程。该简化避免偏好对齐潜在不确定性,更清晰地展现SRMs的效力。特别是,当 B = 1 B=1 B=1时,束搜索退化为贪婪搜索(GS)。
贪婪搜索可理解为在SRM监督下的推理过程(图2左)。理论上,若样本无限,策略 π \pi π和世界模型 P P P在动作或状态选取上,将渐近于最优策略KaTeX parse error: Undefined control sequence: \* at position 5: \pi^\̲*̲,满足:
lim n → ∞ P ( arg max { a t } t = 0 n Q ( s , a t ) = arg max a ∈ A π ( s ) Q ( s , a ) ) = 1 (9) \lim_{n \to \infty} P \left( \arg\max_{\{a_t\}_{t=0}^n} Q(s,a_t) = \arg\max_{a \in A_\pi(s)} Q(s,a) \right) = 1 \tag{9} n→∞limP(arg{at}t=0nmaxQ(s,at)=arga∈Aπ(s)maxQ(s,a))=1(9)
其中 a t ∼ π ( a ∣ s ) a_t \sim \pi(a|s) at∼π(a∣s), A π ( s ) A_\pi(s) Aπ(s)为策略 π \pi π在状态 s s s下可选动作集合。状态空间同理:
lim n → ∞ P ( arg max { s t ′ } t = 0 n V ( s t ′ ) = arg max s ′ ∈ S ( s , a ) V ( s ′ ) ) = 1 (10) \lim_{n \to \infty} P \left( \arg\max_{\{s_t'\}_{t=0}^n} V(s_t') = \arg\max_{s' \in S(s,a)} V(s') \right) = 1 \tag{10} n→∞limP(arg{st′}t=0nmaxV(st′)=args′∈S(s,a)maxV(s′))=1(10)
其中 s t ∼ E a t − 1 ∈ π ( a ∣ s t − 1 ) P ( s ∣ s t − 1 , a t − 1 ) s_t \sim \mathbb{E}_{a_{t-1} \in \pi(a|s_{t-1})} P(s | s_{t-1}, a_{t-1}) st∼Eat−1∈π(a∣st−1)P(s∣st−1,at−1)。
实验}
实现细节}
数据集 为通过MCTS构造步级偏好对,使用GSM8K(Cobbe等,2021)和MATH(Hendrycks等,2021)训练数据中的数学题及对应答案。准确率在测试集上评估。
模型 推理过程由两个LLM协作实现,采用Llama-3-8B-Instruct(Dubey等,2024)作为MCTS中的代理与世界模型,因其指令遵循优良。
提示 一台LLM(代理)负责生成自然语言思考描述,另一台(世界模型)依据思考执行计算。具体提示见附录。
基线 使用Llama-3-8B-Instruct构建Pass@1基线,采用3-shot示例。
MCTS步级偏好采集 代理在扩展阶段采样 n = 6 n=6 n=6候选动作,针对每道题进行500次迭代评估节点质量。为避免答案格式差异影响,采用基于DeepSeek-Math-7B-Base的有监督微调模型判定模拟后的答案正确性,该模型也用于评测。为强化偏好,仅保留值差大于0.7的偏好对。详细超参见附录。
奖励训练 DeepSeek-Math-7B-Base(Shao等,2024)与Qwen2-7B(Yang等,2024)作为SRM训练基础模型。每个SRM训练两个实例,每实例配备8张A800 GPU。超参数详见附录。
主要结果}
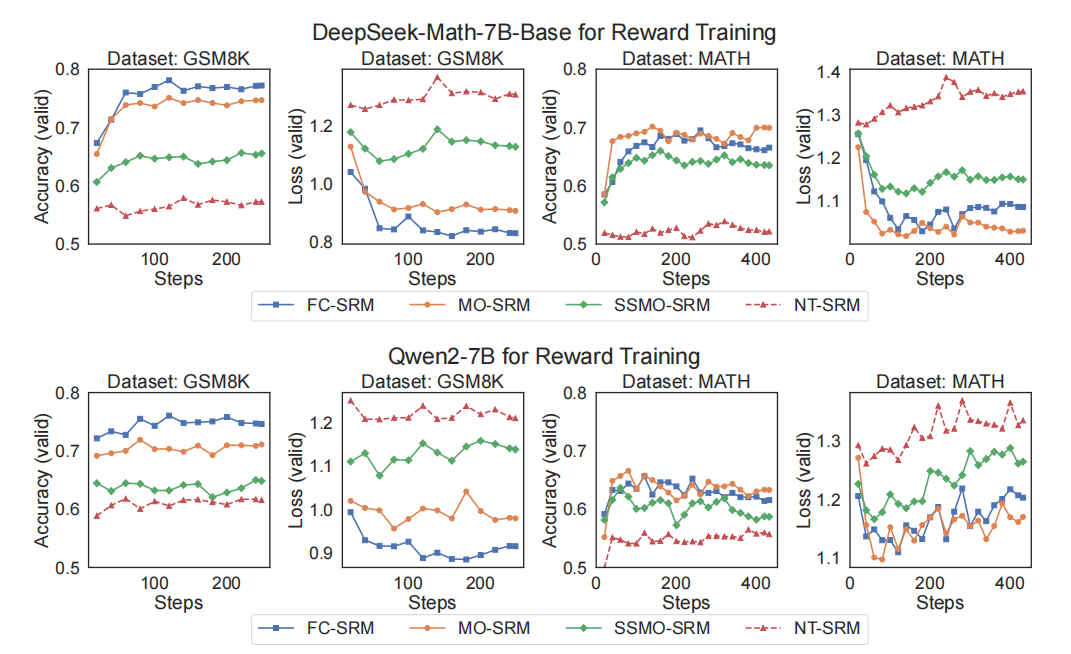
通过MCTS采集所有步级偏好对后,针对FC-SRM、MO-SRM、SSMO-SRM和NT-SRM提取相应数据训练奖励模型,训练曲线见图3。训练完成的SRMs作为贪婪搜索打分函数使用,结果及相对于基线的绝对提升见表1。后续章节进行深入分析。
我们真的需要自然语言吗?}
直觉上,自然语言描述应提供关键上下文,有助于SRMs“理解”。为验证,训练全上下文(FC)及纯数学(MO)输入格式的SRMs。
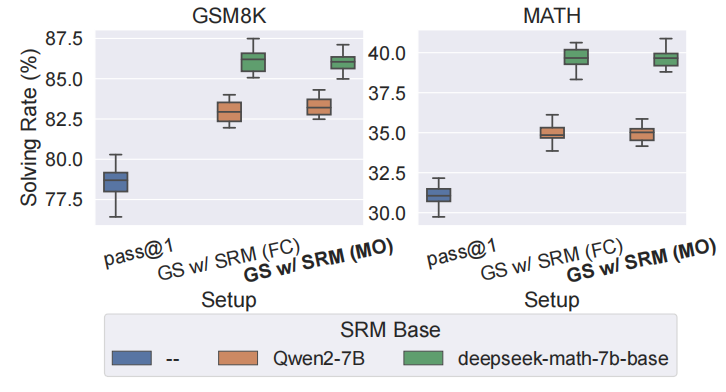
图4:仅输入数学表达式的SRMs在贪婪搜索时表现与全上下文输入的SRMs近似。图中箱线图基于20次运行统计。
结果显示,移除自然语言对步级奖励建模影响甚微。FC-SRMs与MO-SRMs在偏好预测准确率和贪婪搜索性能上表现极为接近,表明成功的步级奖励建模并不依赖自然语言描述,反常理。即使缺失每步的自然语言思考描述,MO-SRMs依然能成功训练(见图3)。表1和图4展示其作为贪婪搜索评分函数时表现;例如在MATH数据集上,基于DeepSeek-Math-7B-Base的MO-SRM( 39.64 % 39.64\% 39.64%)甚至优于FC-SRM( 38.58 % 38.58\% 38.58%)。我们进一步用t检验比较多个数据集及基础模型下FC-SRM与MO-SRM表现:GSM8K的 t = − 0.18 , p = 0.86 t=-0.18, p=0.86 t=−0.18,p=0.86(Qwen2-7B)、 t = − 0.14 , p = 0.89 t=-0.14, p=0.89 t=−0.14,p=0.89(DeepSeek-Math-7B-Base);MATH的 t = 0.79 , p = 0.44 t=0.79, p=0.44 t=0.79,p=0.44(Qwen2-7B)、 t = 0.77 , p = 0.45 t=0.77, p=0.45 t=0.77,p=0.45(DeepSeek-Math-7B-Base)。四组检验均 p > 0.05 p>0.05 p>0.05,差异无统计学意义。结果支持去除自然语言对SRMs效用无显著影响的结论。
SRMs能评估数学语言中的逻辑一致性吗?
MCTS方法的成功归因于避免逻辑和数值错误。常认为逻辑错误更难评估,MCTS被视为有效解决方案,通过收集偏好解决这难题。本节比较SSMO-SRM、MO-SRM和NT-SRM,探讨自然语言与数学语言在评估纯数学逻辑一致性中的作用。
若输入中上下文信息有用,含多步信息的SRM表现应优于仅依赖当前步的SSMO-SRM。此能力即模型对逻辑一致性的评估能力,意味着识别后续步骤是否逻辑上衔接前文及结论。结果见表1。
LLMs可被训练以评估纯数学语言的逻辑一致性。以DeepSeek-Math-7BBase为例,MO-SRM在GSM8K和MATH上分别获得 + 7.35 % +7.35\% +7.35%和 + 8.48 % +8.48\% +8.48%的提升,高于SSMO-SRM的 + 3.64 % +3.64\% +3.64%和 + 6.30 % +6.30\% +6.30%。Qwen2-7B基础模型下,MO-SRM在GSM8K和MATH分别提升 + 5.31 % +5.31\% +5.31%和 + 3.94 % +3.94\% +3.94%,亦超过SSMO-SRM的 + 3.18 % +3.18\% +3.18%和 + 1.92 % +1.92\% +1.92%。显著差距表明考虑全部数学表达式序列的MO-SRM更能捕获逻辑一致性,而非单步计算,从而SRMs可评估数学语言中的逻辑一致性。
相反,SRMs训练以评估自然语言中逻辑一致性则困难重重。依据我们的MDP定义,即使剥离当前步骤中的数学表达式,思考的自然语言描述仍包含了要执行动作的细节。理论上SRMs应能从构造的偏好对中学习判定有助解题的动作。然而,图3中虚线曲线显示在多数据集和基础模型下,NT-SRMs训练均表现出识别困难。表1也显示NT-SRMs作为评分函数表现欠佳。这暗示LLMs难以有效捕获并评估自然语言隐含的逻辑结构。
附加分析
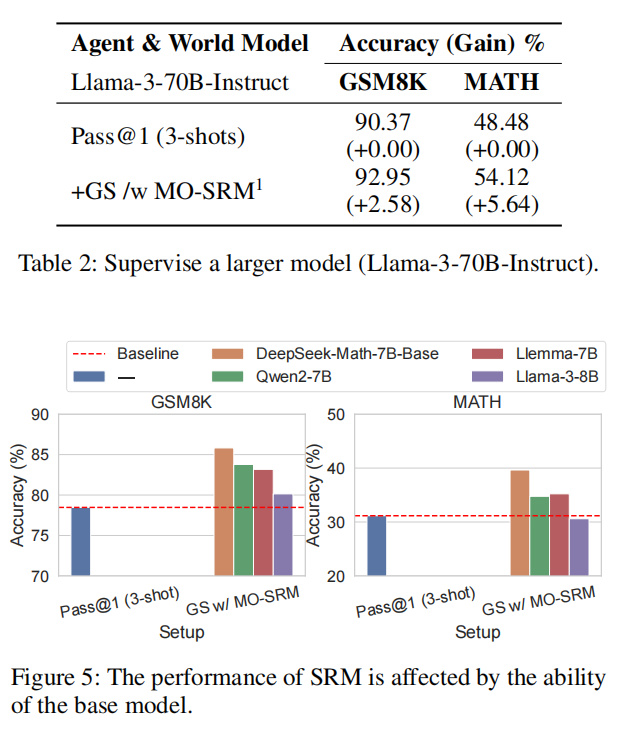
表2:利用大模型(Llama-3-70B-Instruct)进行监督。
图5:SRM性能受基础模型能力影响。
监督更大模型:尽管MO-SRM的偏好数据由较小模型产生,依然能有效指导更大模型推理,带来显著提升(GSM8K+ 2.58 % 2.58\% 2.58%,MATH+ 5.64 % 5.64\% 5.64%)(表2)。这进一步表明SRM可专注数学语言。
基础模型对MO-SRM的影响:MO-SRM基础模型不同影响表现(图5)。该影响不完全与基础模型的数学能力成正比。Llama-3-8B虽数学能力优异,却表现不及Llama-7B(Azerbayev等,2023)、Qwen2-7B及DeepSeek-Math-7B-Base,可能因自我评估难度或其他尚未探明因素所致。
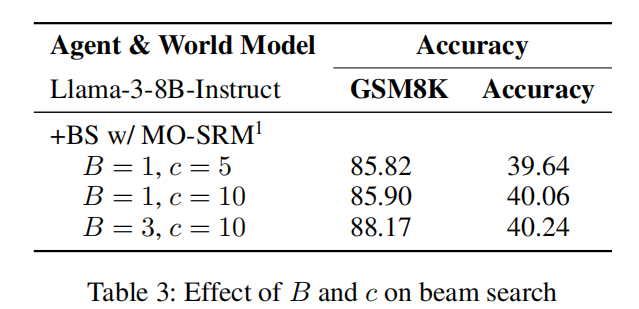
表3:束宽 B B B与候选动作数 c c c对束搜索的影响。
束宽和候选动作数的影响:增加 B B B和 c c c会带来小幅准确率提升,但提升将在一定程度后趋于饱和(详见表3)。
结论
本文探究自然语言与数学表达式在步级奖励建模中的作用,发现自然语言描述非成功的必要条件。大量实验表明,仅基于数学表达式的奖励模型能实现与包含自然语言同等的性能。同时,训练模型评估自然语言逻辑一致性较为困难,突显LLMs捕获隐性逻辑结构的挑战。相较之下,数学表达式内在逻辑结构的逻辑一致性可被训练基于LLM的SRMs有效评定。鉴于获取步级奖励的高昂成本,这些发现为构建更为高效、聚焦的奖励模型指明了方向,即通过聚焦数学推理步骤的关键要素,减少不必要的自然语言信息干扰。
\end{document}