在边缘端进行tensorflow模型的部署(小白初探)
1.配置tensorflow的环境
(我是安装GPU版本的)
建议参考这个博主的文章,确实非常快速!
十分钟安装Tensorflow-gpu2.6.0+本机CUDA12 以及numpy+matplotlib各包版本协调问题_tensorflow cuda12-CSDN博客
2.学习自制数据集
(我这里的模型是用来做目标检测的,所以就先使用labelimg制作了YOLO型的数据集,再使用Python进行格式转换的)
首先,使用检测的摄像头拍摄视频。然后用Python代码处理视频,生成图像数据:
import cv2
import os# 配置参数
video_path = r"D:\\TC264_Library-master(ADS1.9.4)\\SHangWeiJi\\tf_datas_01.avi"
output_dir = r"E:\\YOLO01\\img_Origin"
desired_fps = 10 # 目标提取帧率# 创建输出目录(如果不存在)
os.makedirs(output_dir, exist_ok=True)# 打开视频文件
cap = cv2.VideoCapture(video_path)
if not cap.isOpened():raise Exception(f"无法打开视频文件:{video_path}")# 获取视频原始属性
original_fps = cap.get(cv2.CAP_PROP_FPS)
total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
video_duration = total_frames / original_fpsprint(f"视频信息:")
print(f"原始帧率:{original_fps:.2f} FPS")
print(f"总帧数:{total_frames}")
print(f"持续时间:{video_duration:.2f} 秒")# 计算帧间隔(根据原始帧率和目标帧率)
frame_interval = int(round(original_fps / desired_fps))
print(f"采样间隔:每 {frame_interval} 帧保存一次")# 初始化计数器
count = 0
saved_count = 0while True:ret, frame = cap.read()if not ret:break# 按间隔保存帧if count % frame_interval == 0:# 生成带序号的文件名(4位数字补零)filename = f"frame_{saved_count:04d}.jpg"output_path = os.path.join(output_dir, filename)# 保存图像(质量参数75,可根据需要调整)cv2.imwrite(output_path, frame, [cv2.IMWRITE_JPEG_QUALITY, 75])saved_count += 1count += 1# 释放资源
cap.release()
print(f"\n处理完成!共保存 {saved_count} 张图像到:{output_dir}")接着,进入labelimg进行标注。YOLO型数据变为TFRecord型数据的转换代码如下所示:
import tensorflow as tfdef parse_tfrecord(example_proto):"""解析TFRecord特征描述"""feature_description = {'image': tf.io.FixedLenFeature([], tf.string),'bboxes': tf.io.VarLenFeature(tf.float32),'points': tf.io.VarLenFeature(tf.float32),'num_bboxes': tf.io.FixedLenFeature([], tf.int64),'num_points': tf.io.FixedLenFeature([], tf.int64)}parsed = tf.io.parse_single_example(example_proto, feature_description)# 解码图像image = tf.io.decode_raw(parsed['image'], tf.uint8)image = tf.reshape(image, [224, 224, 1])image = tf.cast(image, tf.float32) / 255.0# 解码边界框bboxes = tf.sparse.to_dense(parsed['bboxes'])bboxes = tf.reshape(bboxes, [parsed['num_bboxes'], 4])# 解码关键点points = tf.sparse.to_dense(parsed['points'])points = tf.reshape(points, [parsed['num_points'], 4])return image, {'bbox': bboxes, 'points': points}def load_dataset(subset, batch_size=32):"""加载TFRecord数据集"""pattern = f"E:/TFRecordData/{subset}/{subset}_*.tfrecord"files = tf.data.Dataset.list_files(pattern)dataset = files.interleave(lambda x: tf.data.TFRecordDataset(x),cycle_length=tf.data.AUTOTUNE,num_parallel_calls=tf.data.AUTOTUNE)dataset = dataset.map(parse_tfrecord,num_parallel_calls=tf.data.AUTOTUNE)dataset = dataset.padded_batch(batch_size,padded_shapes=([224, 224, 1],{'bbox': [None, 4],'points': [None, 4]})).prefetch(tf.data.AUTOTUNE)return dataset# 使用示例
train_dataset = load_dataset("train")
val_dataset = load_dataset("val")
test_dataset = load_dataset("test")3.模型训练
然后,我们就可以美美地把自己的数据集导入到模型里面进行训练了
我的模型训练结果如下:
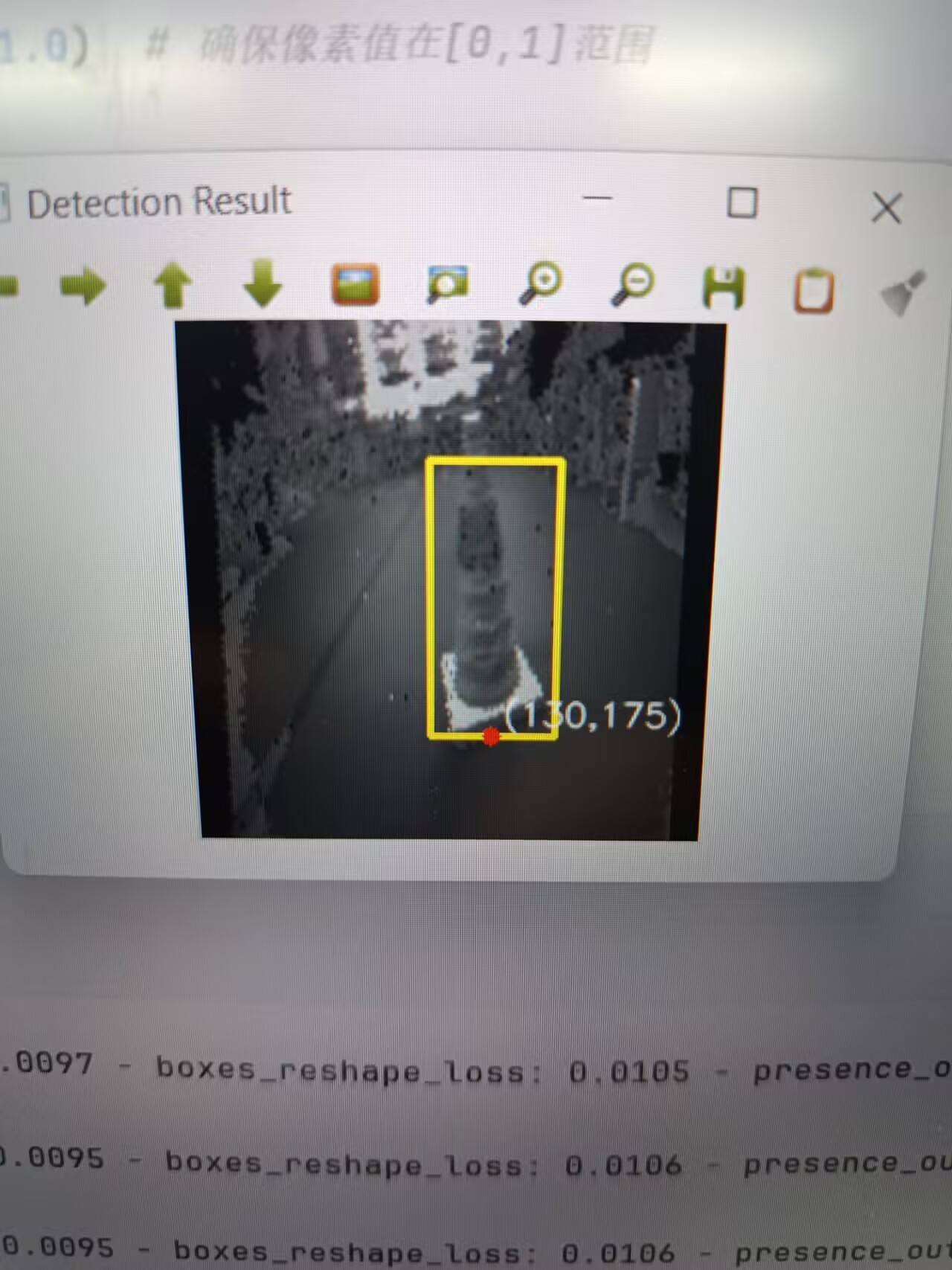
4.模型的部署
最后,按照单片机平台的tflite_Micro的资源包配置嵌入式平台的编译环境,再把模型的tflite文件转为C语言格式,一起导入工程代码。
OK!博主的部署操作到这里就结束了,更多细节,还要到后面有时间了再补充。