MegaTTS3: 下一代高效语音合成技术,重塑AI语音的自然与个性化
在近期的发布中,浙江大学赵洲教授团队与字节跳动联合推出了革命性的第三代语音合成模型——MegaTTS3,该模型不仅在多个专业评测中展现了卓越的性能,还为AI语音的自然性和个性化开辟了新的篇章。

MegaTTS3技术亮点
-
零样本语音合成
MegaTTS3采用先进的零样本技术,通过仅提供几秒钟的音频样本,便能够高效生成目标说话人的声音,完美模拟其语音特征,语音合成的自然度和流畅性令人惊叹。 -
轻量化架构,高效快速
该模型的核心架构仅包含0.45B参数,相比于其他同类大规模模型,具有更轻量、更高效、更易部署的优势。利用Piecewise Rectified Flow(PeRFlow)技术,MegaTTS3能够在生成语音时将采样步骤从25步压缩至8步,生成速度提高3倍,同时保证音质几乎无损。 -
创新的稀疏对齐策略
MegaTTS3引入了创新的稀疏对齐机制,通过提供粗略的语音-文本对齐信息,简化了传统的语音对齐问题,同时保留了生成空间的灵活性。此策略显著提升了语音的自然度和说话人相似度,解决了传统语音合成方法中自然度不足的问题。 -
多条件分类器无监督引导(CFG)
MegaTTS3在音色和语音内容的生成上提供了前所未有的灵活控制。其多条件CFG策略可以在不需要额外标注数据的情况下,调整音色强度和口音类型,极大提升了生成语音的个性化表达能力。 -
中英双语支持与跨语言克隆
MegaTTS3不仅支持中文和英文的无缝切换,还能够在同一段语音中实现自然的代码切换,为全球化应用提供了强大的语言适应能力。
技术架构与核心创新
MegaTTS3的成功离不开其创新的技术架构和多项突破性核心技术,下面我们将详细探讨其关键架构设计和创新技术。
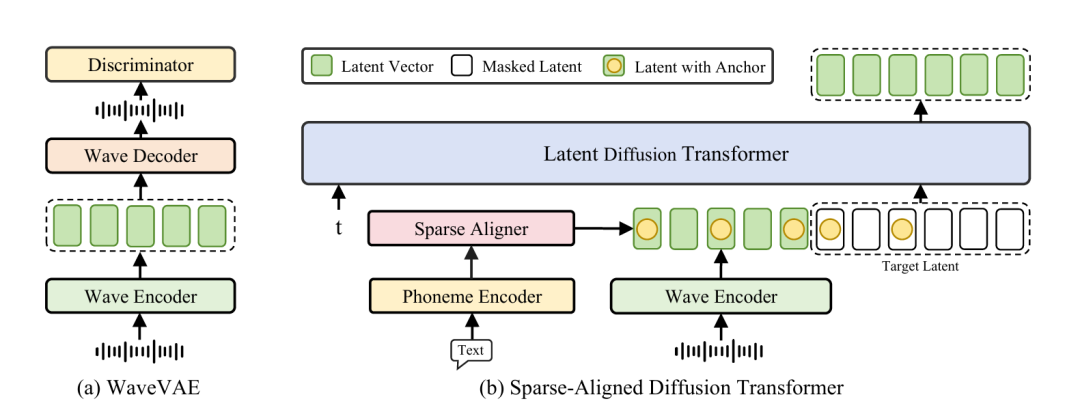
1. WaveVAE模块:高效的语音信号压缩与还原
WaveVAE模块是MegaTTS3的核心之一,负责将原始语音信号压缩成潜在向量,并通过解码器进行还原,确保语音合成的高保真度。它采用了变分自编码器(VAE)架构,分为编码器和解码器两个部分。
-
编码器:将输入的原始语音信号通过下采样处理,并提取关键的高频细节信息。通过将信号压缩成低维度的潜在向量,减少了后续处理的计算量,提高了整体生成效率。
-
解码器:将压缩后的潜在向量恢复为音频波形。为了保证生成的语音质量,解码器使用了多尺度判别器(MPD)、多分辨率判别器(MSD)和多尺度分辨率判别器(MRD)等判别机制,这些机制能够精细地恢复语音中的高频细节,确保语音的自然度和清晰度。
这一模块有效地解决了传统TTS系统中语音生成的高计算成本问题,同时还提升了生成语音的真实感。
2. Latent Diffusion Transformer(DiT):潜空间中的条件生成
MegaTTS3在Latent Diffusion Transformer(DiT)的基础上进行语音合成。该模型通过在潜空间内进行条件生成,将文本信息与语音信号的风格、语气、节奏等特征进行结合。具体而言,MegaTTS3的DiT模块采用了扩散模型来进行生成。
-
潜空间对齐:DiT通过自注意力机制对潜在向量序列进行建模,将文本和语音信号之间进行细致的对齐。通过稀疏对齐策略,MegaTTS3将生成过程中的对齐信息稀疏化,以简化学习过程。
-
稀疏对齐策略:这一创新策略能够大幅降低对齐任务的复杂性,同时不会限制模型的生成空间。与传统的强制对齐模型不同,稀疏对齐提供了更多的自由度,使得MegaTTS3能够生成更加自然的语音。
通过这种方式,MegaTTS3在保持语音自然度的同时,确保了生成语音与文本之间的精确映射,从而有效提高了语音合成的质量和可靠性。
3. 多条件分类器无监督引导(CFG):精准调控音色与情感
多条件分类器无监督引导(CFG)是MegaTTS3的一项重大创新,使得语音合成过程中的音色、口音、情感等特征能够得到精确控制。
-
CFG引导机制:传统的语音合成系统通过一套固定的训练数据来控制音色和情感表达,而MegaTTS3的CFG机制则使得用户可以自由调整音色和情感的强度。通过调整文本引导参数(αtxt)和说话人引导参数(αspk),用户能够控制语音的发音特征、口音强度等,进而定制更加个性化的语音输出。
-
口音强度调节:该技术不仅支持标准语音的生成,还能够根据需求调整口音的强度,使得生成的语音能够更加贴近不同地区和文化的发音特色。例如,用户可以生成带有本地口音的语音,或模拟标准英语的发音,极大提升了语音生成的灵活性。
这一创新使得MegaTTS3在处理情感表达和个性化定制方面比传统TTS模型具有显著优势,尤其在需要传达特定情感或风格的场景中表现尤为突出。
4. PeRFlow技术:加速生成过程,提高效率
PeRFlow(Piecewise Rectified Flow)是MegaTTS3中的另一项创新技术,它通过分段整流流加速生成过程,大幅提升了生成效率。
-
减少采样步骤:传统的扩散模型通常需要较多的采样步骤才能生成高质量的语音,而PeRFlow通过将生成过程分割成多个时间段,在每个时间段内进行快速计算,从而显著降低了采样步骤的数量。MegaTTS3的PeRFlow技术将生成过程中的采样步骤从常规的25步压缩至8步,大幅提高了生成速度。
-
实时生成:通过PeRFlow技术,MegaTTS3可以在0.124秒内生成1分钟的语音,且生成质量几乎没有下降。这使得MegaTTS3特别适用于实时语音交互应用,如直播字幕生成、智能语音助手等。
5. WaveVAE和Latent Diffusion结合:强大的语音合成效果
MegaTTS3的架构将WaveVAE和Latent Diffusion Transformer进行了结合,这种多模块协同合作的设计为MegaTTS3带来了卓越的语音合成效果。
-
WaveVAE模块负责提取语音的高频信息,并将其压缩为潜在向量,确保合成语音的高保真度。
-
Latent Diffusion Transformer则基于这些潜在向量进行条件生成,通过精细的对齐和情感控制,生成符合文本内容和语音风格的高质量语音。
这种模块化设计不仅提升了生成语音的自然度和清晰度,还保证了语音生成的高效性和灵活性,使得MegaTTS3在多种应用场景下表现出色。
实验结果与表现
在多个标准数据集上,MegaTTS3的表现超越了现有的大部分主流语音合成模型。根据LibriSpeech和LibriLight数据集的测试,MegaTTS3在语音清晰度、自然度、以及说话人相似度(SIM-O)等指标上均创下了新纪录。
-
零样本语音合成结果:MegaTTS3在SIM-O和SMOS评分上均表现出色,能够生成高质量、富有情感的语音。
-
口音控制能力:通过CFG策略,MegaTTS3不仅能够精确调节口音强度,还能生成标准英语或带有地方口音的语音,提供了前所未有的灵活性。
下载链接
OpenCSG社区:https://opencsg.com/models/ByteDance/MegaTTS3
HF社区:https://huggingface.co/ByteDance/MegaTTS3