教你如何创建Maven项目
前面我们了解了Maven的基本知识,接下来,我们结合IDEA编辑器,一起去创建Maven项目。
接下来我们将会在IDEA中去创建项目,并编写java代码来操作集群中的文件。以下是核心的步骤,大家跟上哈。
1.IDEA 中创建 Maven 项目
步骤一:点击 File -> New -> Project,在弹出的窗口左侧选择 Maven,点击 Next:
步骤二:填写项目的 GroupId、ArtifactId、Version 等信息(这些对应 pom.xml 中的关键配置),点击 Next。
步骤三:确认项目配置信息无误后,点击 Finish,IDEA 会自动生成 Maven 项目结构。
2.IDEA 中配置 Maven(使用自定义 Maven 版本示例)
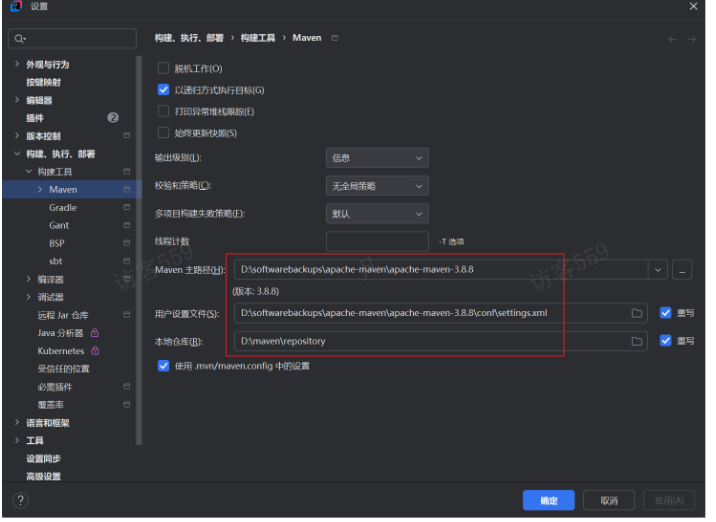
步骤一:打开 IDEA,点击 File -> Settings(Windows/Linux)或者 IntelliJ IDEA -> Preferences(Mac),进入设置界面,然后找到 Build, Execution, Deployment -> Build Tools -> Maven。
步骤二:在 Maven home directory 处,点击右侧的按钮,选择你本地安装的 Maven 目录,例如:
步骤三:可以在 User settings file 中指定 settings.xml 文件的路径(一般使用默认路径即可),Local repository 中指定本地仓库的路径,配置完成后点击 OK 保存设置。
(五)编写代码测试HDFS连接
我们先需要去下载响应的hadoop包,当然这个过程不需要我们去手动下载,只需要在maven中配置即可。
- 请在上一步创建的项目中修改pom.xml文件,添加如下的代码。
-
<dependencies><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.1.3</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.30</version></dependency> </dependencies>注意,这里的dependencies要这一步中的hadoop-client要和我们前面客户端准备中下载的hadoop保持一致。
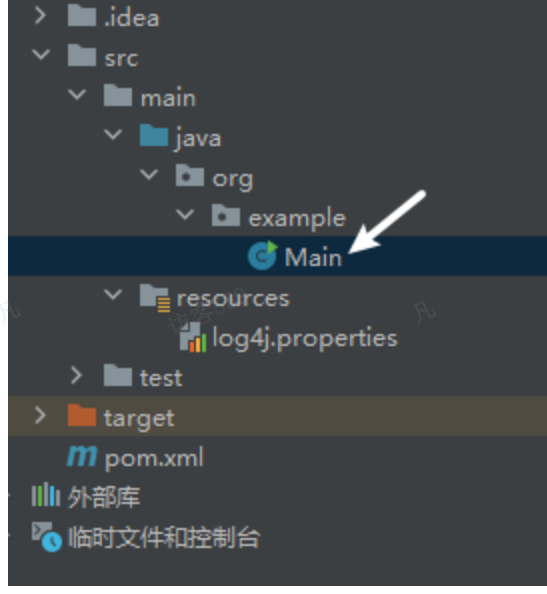
3. 配置日志信息。在项目的src/main/resources目录下,新建一个文件,命名为“log4j.properties”,在文件中填入如下配置信息:
log4j.rootLogger=INFO, stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n log4j.appender.logfile=org.apache.log4j.FileAppender log4j.appender.logfile.File=target/spring.log log4j.appender.logfile.layout=org.apache.log4j.PatternLayout log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n4.创建包及对应的类。我们创建一个包为org.example,并在下面创建Main类。
编写代码如下:
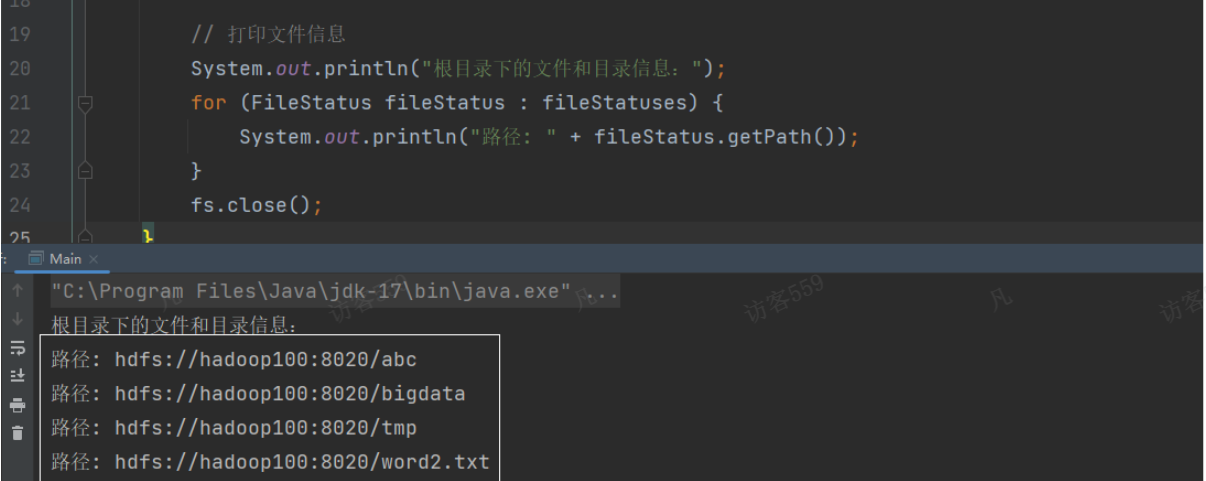
package org.example;import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileStatus; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path;import java.io.IOException; import java.net.URISyntaxException;public class Main {public static void main(String[] args) throws URISyntaxException, IOException, InterruptedException {Configuration conf = new Configuration();conf.set("fs.defaultFS", "hdfs://hadoop100:8020"); // hadoop100是namenode所在的节点conf.set("hadoop.job.ugi", "root");FileSystem fs = FileSystem.get(conf);FileStatus[] fileStatuses = fs.listStatus(new Path("/"));// 打印文件信息System.out.println("根目录下的文件和目录信息:");for (FileStatus fileStatus : fileStatuses) {System.out.println("路径: " + fileStatus.getPath());}fs.close();} }代码说明:
(1)Configuration 对象用于加载 Hadoop 配置文件(如 core-site.xml 和 hdfs-site.xml),这里没有明确指定配置文件路径,会默认加载类路径下的配置文件。
(2)FileSystem.get() 方法通过指定 HDFS 的 URI(hdfs://hadoop102:8020)和用户(root)来获取 HDFS 的文件系统对象 fs。其中:
hdfs://hadoop102:8020 表示 HDFS 的名称节点(NameNode)地址,hadoop102 是主机名,8020 是端口号。
root 是用户身份,用于认证和授权。
5. 执行程序
如果程序执行没有错误,就会打印出当前HDFS中的文件目录。