Day09【基于Tripletloss实现的简单意图识别对话系统】
基于Tripletloss实现的表示型文本匹配
- 目标
- 数据准备
- 参数配置
- 数据处理
- Triplet Loss目标
- Triplet Loss计算公式
- 公式说明
- 模型构建
- 网络结构设计
- 网络训练目标
- 损失函数设计
- 主程序
- 推理预测
- 类初始化
- 加载问答知识库
- 文本向量化
- 知识库查询
- 主程序`main`测试
- 测试效果
- 参考博客
目标
在此之前已经实现了基于余弦相似度实现的文本匹配1,本文将实现基于tripletloss实现文本匹配,并实现简单的意图识别问答系统。主要做法同样是基于给定的词表,将输入的文本基于jieba分词分割为若干个词,然后将词基于词表进行初步编码,之后经过网络表征层得到文本的表征向量,只不过最后在训练的时候使用TripletMarginLoss而不是之前的CosineEmbeddingLoss,推理预测时还是使用文本的表征向量。
数据准备
预训练模型bert-base-chinese预训练模型
词表文件chars.txt
类别标签文件schema.json
{"停机保号": 0,"密码重置": 1,"宽泛业务问题": 2,"亲情号码设置与修改": 3,"固话密码修改": 4,"来电显示开通": 5,"亲情号码查询": 6,"密码修改": 7,"无线套餐变更": 8,"月返费查询": 9,"移动密码修改": 10,"固定宽带服务密码修改": 11,"UIM反查手机号": 12,"有限宽带障碍报修": 13,"畅聊套餐变更": 14,"呼叫转移设置": 15,"短信套餐取消": 16,"套餐余量查询": 17,"紧急停机": 18,"VIP密码修改": 19,"移动密码重置": 20,"彩信套餐变更": 21,"积分查询": 22,"话费查询": 23,"短信套餐开通立即生效": 24,"固话密码重置": 25,"解挂失": 26,"挂失": 27,"无线宽带密码修改": 28
}
训练集数据train.json训练集数据
验证集数据valid.json验证集数据
参数配置
config.py
# -*- coding: utf-8 -*-"""
配置参数信息
"""
# -*- coding: utf-8 -*-"""
配置参数信息
"""Config = {"model_path": "model_output","schema_path": "../data/schema.json","train_data_path": "../data/train.json","valid_data_path": "../data/valid.json","pretrain_model_path":r"../../../bert-base-chinese","vocab_path":r"../../../bert-base-chinese/vocab.txt","max_length": 20,"hidden_size": 256,"epoch": 10,"batch_size": 128,"epoch_data_size": 10000, #每轮训练中采样数量"positive_sample_rate":0.5, #正样本比例"optimizer": "adam","learning_rate": 1e-3,"triplet_margin": 1.0,
}
数据处理
loader.py
# -*- coding: utf-8 -*-import json
import re
import os
import torch
import random
import jieba
import numpy as np
from torch.utils.data import Dataset, DataLoader
from collections import defaultdict
"""
数据加载
"""class DataGenerator:def __init__(self, data_path, config):self.config = configself.path = data_pathself.tokenizer = load_vocab(config["vocab_path"])self.vocab = load_vocab(config["vocab_path"])self.config["vocab_size"] = len(self.vocab)self.schema = load_schema(config["schema_path"])self.train_data_size = config["epoch_data_size"] #由于采取随机采样,所以需要设定一个采样数量,否则可以一直采self.data_type = None #用来标识加载的是训练集还是测试集 "train" or "test"self.load()def load(self):self.data = []self.knwb = defaultdict(list)with open(self.path, encoding="utf8") as f:for line in f:line = json.loads(line)#加载训练集if isinstance(line, dict):self.data_type = "train"questions = line["questions"]label = line["target"]for question in questions:input_id = self.encode_sentence(question)input_id = torch.LongTensor(input_id)self.knwb[self.schema[label]].append(input_id)#加载测试集else:self.data_type = "test"assert isinstance(line, list)question, label = lineinput_id = self.encode_sentence(question)input_id = torch.LongTensor(input_id)label_index = torch.LongTensor([self.schema[label]])self.data.append([input_id, label_index])returndef encode_sentence(self, text):input_id = []if self.config["vocab_path"] == "words.txt":for word in jieba.cut(text):input_id.append(self.vocab.get(word, self.vocab["[UNK]"]))else:for char in text:input_id.append(self.vocab.get(char, self.vocab["[UNK]"]))input_id = self.padding(input_id)return input_id#补齐或截断输入的序列,使其可以在一个batch内运算def padding(self, input_id):input_id = input_id[:self.config["max_length"]]input_id += [0] * (self.config["max_length"] - len(input_id))return input_iddef __len__(self):if self.data_type == "train":return self.config["epoch_data_size"]else:assert self.data_type == "test", self.data_typereturn len(self.data)def __getitem__(self, index):if self.data_type == "train":return self.random_train_sample() #随机生成一个训练样本else:return self.data[index]#随机生成3元组样本,2正1负def random_train_sample(self):standard_question_index = list(self.knwb.keys())# 先选定两个意图,之后从第一个意图中取2个问题,第二个意图中取一个问题p, n = random.sample(standard_question_index, 2)# 如果某个意图下刚好只有一条问题,那只能两个正样本用一样的;# 这种对训练没帮助,因为相同的样本距离肯定是0,但是数据充分的情况下这种情况很少if len(self.knwb[p]) == 1:s1 = s2 = self.knwb[p][0]#这应当是一般情况else:s1, s2 = random.sample(self.knwb[p], 2)# 随机一个负样本s3 = random.choice(self.knwb[n])# 前2个相似,后1个不相似,不需要额外在输入一个0或1的label,这与一般的loss计算不同return [s1, s2, s3]#加载字表或词表
def load_vocab(vocab_path):token_dict = {}with open(vocab_path, encoding="utf8") as f:for index, line in enumerate(f):token = line.strip()token_dict[token] = index + 1 #0留给padding位置,所以从1开始return token_dict#加载schema
def load_schema(schema_path):with open(schema_path, encoding="utf8") as f:return json.loads(f.read())#用torch自带的DataLoader类封装数据
def load_data(data_path, config, shuffle=True):dg = DataGenerator(data_path, config)dl = DataLoader(dg, batch_size=config["batch_size"], shuffle=shuffle)return dl还是一样自定义数据加载器 DataGenerator,用于加载和处理文本数据。主要区别在于训练时采样策略的处理,random_train_sample函数选取2个正样本1个负样本作为anchor、positive、negative。triplet loss训练要求positive样本和anchor相比较negative样本更接近,也即同类样本更加接近,不同类样本更加远离。它在面部识别、图像检索、个性化推荐等领域得到了广泛应用。
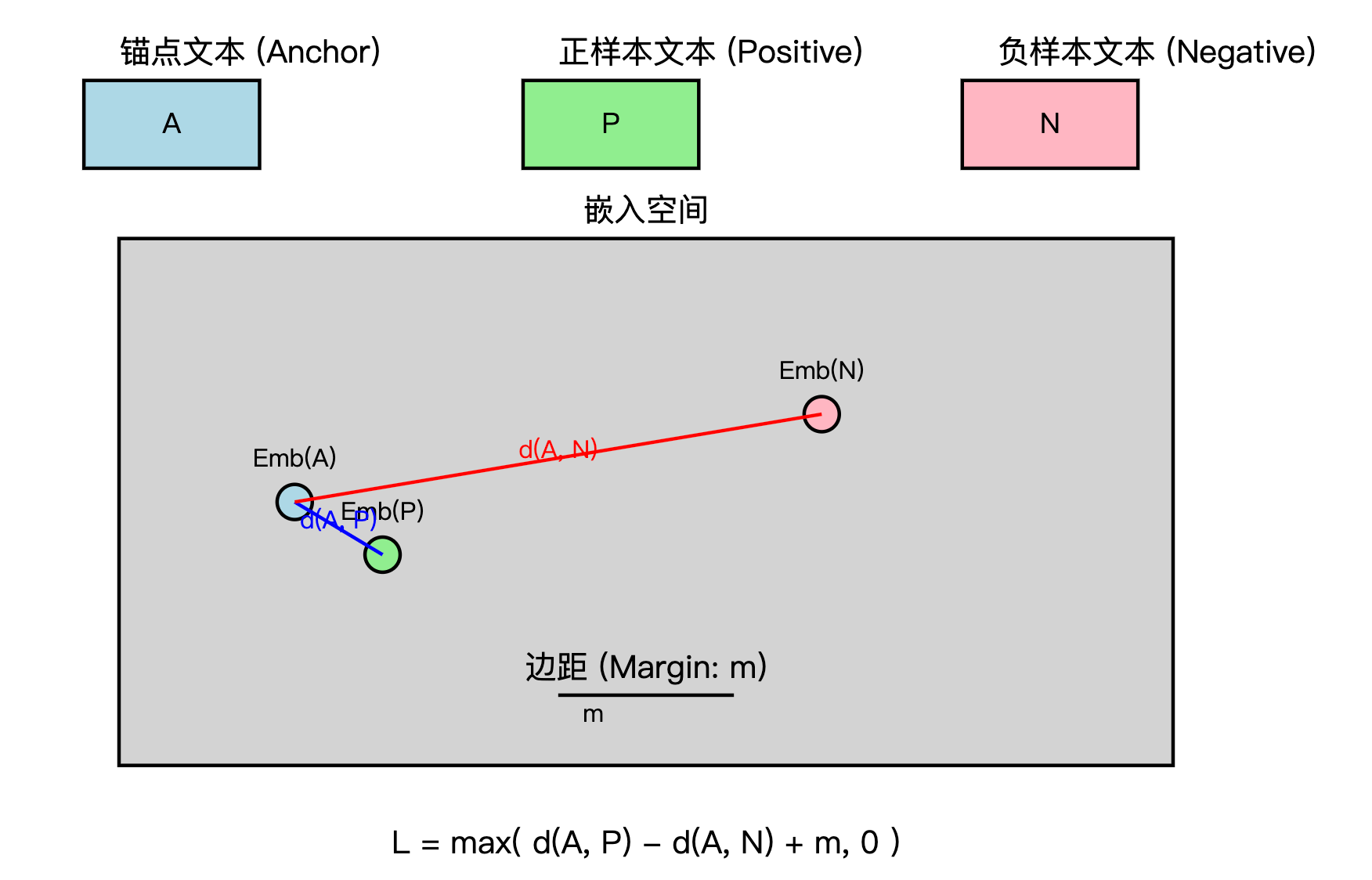
Triplet Loss目标
其目标是通过三元组(triplet)数据,即:一个锚点(anchor)、一个正样本(positive)和一个负样本(negative)来学习特征空间,使得:
- 锚点与正样本之间的距离应该尽可能小。
- 锚点与负样本之间的距离应该尽可能大。
Triplet Loss计算公式
假设:
- ( a ) 是锚点样本(anchor)。
- ( p ) 是与锚点相同类别的正样本(positive)。
- ( n ) 是与锚点不同类别的负样本(negative)。
那么,Triplet Loss 的计算公式为:
L ( a , p , n ) = max ( ∥ f ( a ) − f ( p ) ∥ 2 2 − ∥ f ( a ) − f ( n ) ∥ 2 2 + α , 0 ) L(a, p, n) = \max \left( \| f(a) - f(p) \|_2^2 - \| f(a) - f(n) \|_2^2 + \alpha, 0 \right) L(a,p,n)=max(∥f(a)−f(p)∥22−∥f(a)−f(n)∥22+α,0)
其中:
- f ( x ) f(x) f(x) 是输入样本 x x x 的特征向量(通常由神经网络模型生成)。
- ∥ f ( a ) − f ( p ) ∥ 2 2 \| f(a) - f(p) \|_2^2 ∥f(a)−f(p)∥22 是锚点 a a a 和正样本 p p p 之间的欧几里得距离的平方。
- ∥ f ( a ) − f ( n ) ∥ 2 2 \| f(a) - f(n) \|_2^2 ∥f(a)−f(n)∥22 是锚点 a a a 和负样本 n n n 之间的欧几里得距离的平方。
- ∥ ⋅ ∥ 2 \| \cdot \|_2 ∥⋅∥2 表示欧几里得距离(L2 距离)。
- α \alpha α 是一个超参数,称为“边际”或“阈值”,用于控制负样本与锚点之间的最小距离差,防止损失值过小。
公式说明
-
锚点与正样本的距离: ∥ f ( a ) − f ( p ) ∥ 2 2 \| f(a) - f(p) \|_2^2 ∥f(a)−f(p)∥22
这项度量锚点和正样本之间的相似性,目的是最小化这个距离。 -
锚点与负样本的距离: ∥ f ( a ) − f ( n ) ∥ 2 2 \| f(a) - f(n) \|_2^2 ∥f(a)−f(n)∥22
这项度量锚点和负样本之间的差异,目标是最大化这个距离。 -
边际 α \alpha α:
用于确保锚点与负样本之间的距离至少大于锚点与正样本之间的距离加上一个边际 α \alpha α,从而避免了负样本距离过近的情况。
模型构建
model.py
# -*- coding: utf-8 -*-import torch
import torch.nn as nn
from torch.optim import Adam, SGD
"""
建立网络模型结构
"""class SentenceEncoder(nn.Module):def __init__(self, config):super(SentenceEncoder, self).__init__()hidden_size = config["hidden_size"]vocab_size = config["vocab_size"] + 1max_length = config["max_length"]self.embedding = nn.Embedding(vocab_size, hidden_size, padding_idx=0)# self.layer = nn.LSTM(hidden_size, hidden_size, batch_first=True, bidirectional=True)self.layer = nn.Linear(hidden_size, hidden_size)self.dropout = nn.Dropout(0.5)#输入为问题字符编码def forward(self, x):sentence_length = torch.sum(x.gt(0), dim=-1)x = self.embedding(x)#使用lstm# x, _ = self.layer(x)#使用线性层x = self.layer(x)# x.shape[1]表示kernel_size,表示池化窗口的大小,# 输入是一个形状为 (batch_size, channels, length) 张量x = nn.functional.max_pool1d(x.transpose(1, 2), x.shape[1]).squeeze()return xclass SiameseNetwork(nn.Module):def __init__(self, config):super(SiameseNetwork, self).__init__()self.sentence_encoder = SentenceEncoder(config)self.margin = config["triplet_margin"]self.loss = nn.TripletMarginLoss(self.margin,2)# 计算余弦距离 1-cos(a,b)# cos=1时两个向量相同,余弦距离为0;cos=0时,两个向量正交,余弦距离为1def cosine_distance(self, tensor1, tensor2):tensor1 = torch.nn.functional.normalize(tensor1, dim=-1)tensor2 = torch.nn.functional.normalize(tensor2, dim=-1)cosine = torch.sum(torch.mul(tensor1, tensor2), axis=-1)return 1 - cosinedef cosine_triplet_loss(self, a, p, n, margin=None):ap = self.cosine_distance(a, p)an = self.cosine_distance(a, n)if margin is None:diff = ap - an + 0.1else:diff = ap - an + marginres = diff[diff.gt(0)]if len(res) == 0:return torch.tensor(1e-6)return torch.mean(res)#sentence : (batch_size, max_length)def forward(self, sentence1, sentence2=None, sentence3=None):#同时传入3个句子,则做tripletloss的loss计算if sentence2 is not None and sentence3 is not None:vector1 = self.sentence_encoder(sentence1)vector2 = self.sentence_encoder(sentence2)vector3 = self.sentence_encoder(sentence3)return self.loss(vector1, vector2, vector3)return self.cosine_triplet_loss(vector1, vector2, vector3, self.margin)#单独传入一个句子时,认为正在使用向量化能力else:return self.sentence_encoder(sentence1)def choose_optimizer(config, model):optimizer = config["optimizer"]learning_rate = config["learning_rate"]if optimizer == "adam":return Adam(model.parameters(), lr=learning_rate)elif optimizer == "sgd":return SGD(model.parameters(), lr=learning_rate)网络结构设计
该代码实现了一个Siamese Network,主要用于计算文本的相似度。模型由两部分组成:SentenceEncoder和SiameseNetwork。SentenceEncoder是一个句子编码器,用于将输入的文本转换为固定维度的向量表示。它通过一个嵌入层(embedding layer)将单词转换为稠密的向量表示,然后通过线性层进行特征提取。为了捕获句子的全局信息,使用最大池化(MaxPool)操作,从每个维度中选择最大的值,这有助于保留关键信息。SiameseNetwork包含两个这样的编码器,分别用于处理两个输入句子,并将其输出向量进行比较。
网络训练目标
Siamese网络的训练目标是让相似的句子对的向量表示更接近,不相似的句子对的向量表示更远离。为了实现这一目标,模型通过计算两个输入句子的相似度来进行优化。这个过程通常使用对比学习的方法,在每一轮训练时,网络通过最小化句子对之间的距离来优化其参数。在训练过程中,网络将接受来自数据集的句子对,每一对包含两个句子和它们的标签,标签表示句子对是否相似。通过这种方式,模型学习到如何将相似的句子映射到相近的向量空间,并将不相似的句子映射到较远的空间。
损失函数设计
模型的损失函数设计主要有两种选择,具体取决于使用的距离度量方法。首先,SiameseNetwork类支持使用余弦相似度来计算句子对之间的相似度。这种方式通过计算两个向量的余弦值来度量它们的相似性,值越大表示越相似。其次,模型还支持使用三元组损失(Triplet Loss)。三元组损失是一种常用的度量学习方法,它通过比较一个“锚”句子、正样本(相似句子)和负样本(不相似句子)的距离,确保正样本距离锚点更近,负样本距离锚点更远。三元组损失函数通过最小化这个距离差异来训练模型,从而优化句子编码器的表示能力,提升模型的相似度计算精度。
该模型通过最小化损失函数来优化句子编码器的参数,从而提升句子相似度的预测能力,广泛应用于文本相似度计算、语义匹配等任务。模型的训练和推理过程需要通过对比句子对(或三元组)来进行优化,最终使得模型能够准确判断两个句子之间的语义相似性。
主程序
main.py
# -*- coding: utf-8 -*-import torch
import os
import random
import os
import numpy as np
import logging
from config import Config
from model import SiameseNetwork, choose_optimizer
from loader import load_datalogging.basicConfig(level = logging.INFO,format = '%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)"""
模型训练主程序
"""def main(config):#创建保存模型的目录if not os.path.isdir(config["model_path"]):os.mkdir(config["model_path"])#加载训练数据train_data = load_data(config["train_data_path"], config)#加载模型model = SiameseNetwork(config)# 判断是否有 GPU 支持mps_flag = torch.backends.mps.is_available()device = torch.device("cpu")model = model.to(device)if not mps_flag:device = torch.device("mps") # 使用 Metal 后端print("Using GPU with Metal backend")model = model.to(device) # 将模型迁移到 Metal 后端(MPS)else:print("Using CPU") # 如果没有 GPU,则使用 CPU# # 标识是否使用gpu# cuda_flag = torch.cuda.is_available()# if cuda_flag:# logger.info("gpu可以使用,迁移模型至gpu")# model = model.cuda()#加载优化器optimizer = choose_optimizer(config, model)#训练for epoch in range(config["epoch"]):epoch += 1model.train()logger.info("epoch %d begin" % epoch)train_loss = []for index, batch_data in enumerate(train_data):optimizer.zero_grad()# if mps_flag: #如果gpu可用则使用gpu加速# batch_data = [d.to('mps') for d in batch_data]anchor_ids, positive_ids, negative_ids = batch_dataanchor_ids = anchor_ids.to(device)positive_ids = positive_ids.to(device)negative_ids = negative_ids.to(device)loss = model(anchor_ids, positive_ids, negative_ids) #计算losstrain_loss.append(loss.item())#每轮训练一半的时候输出一下loss,观察下降情况if index % int(len(train_data) / 2) == 0:logger.info("batch loss %f" % loss)loss.backward() #反向传播梯度计算optimizer.step() #更新模型参数logger.info("epoch average loss: %f" % np.mean(train_loss))model_path = os.path.join(config["model_path"], "epoch_%d.pth" % epoch)torch.save(model.state_dict(), model_path)returnif __name__ == "__main__":main(Config)
主程序核心流程包括数据加载、模型训练以及反向传播更新。
-
训练数据加载:通过
load_data函数从config["train_data_path"]路径加载训练数据,并返回train_data。每个训练数据包含一个三元组(anchor, positive, negative),这些数据在训练过程中用于计算Siamese Network的损失。 -
模型训练过程:
- 首先,创建
SiameseNetwork模型并将其迁移到适当的设备(CPU或GPU/Metal后端)。模型通过model.to(device)迁移到指定设备,确保可以利用GPU加速训练。 - 然后,定义优化器
optimizer,并开始训练过程。每个epoch内,程序遍历所有训练数据,获取当前batch的三元组(anchor_ids, positive_ids, negative_ids)。
- 首先,创建
-
损失计算与反向传播:
- 对于每个batch,模型计算当前三元组的损失:
loss = model(anchor_ids, positive_ids, negative_ids)。这里,模型通过计算anchor和positive、negative之间的相似度来得到损失。 - 损失计算后,通过
loss.backward()进行反向传播,计算梯度。梯度反向传播使得模型能够更新其参数以最小化损失。 optimizer.step()则根据计算得到的梯度更新模型的参数,从而逐步优化模型。
- 对于每个batch,模型计算当前三元组的损失:
-
训练日志:每个batch的损失会输出,用于跟踪训练进度,每个epoch结束时,计算并输出平均损失。
最终,训练完成后,模型参数会被保存至指定路径。
推理预测
predict.py
# -*- coding: utf-8 -*-
import jieba
import torch
import logging
from loader import load_data
from config import Config
from model import SiameseNetwork, choose_optimizer"""
模型效果测试
"""class Predictor:def __init__(self, config, model, knwb_data):self.config = configself.model = modelself.train_data = knwb_dataif torch.cuda.is_available():self.model = model.cuda()else:self.model = model.cpu()self.model.eval()self.knwb_to_vector()#将知识库中的问题向量化,为匹配做准备#每轮训练的模型参数不一样,生成的向量也不一样,所以需要每轮测试都重新进行向量化def knwb_to_vector(self):self.question_index_to_standard_question_index = {}self.question_ids = []self.vocab = self.train_data.dataset.vocabself.schema = self.train_data.dataset.schemaself.index_to_standard_question = dict((y, x) for x, y in self.schema.items())for standard_question_index, question_ids in self.train_data.dataset.knwb.items():for question_id in question_ids:#记录问题编号到标准问题标号的映射,用来确认答案是否正确self.question_index_to_standard_question_index[len(self.question_ids)] = standard_question_indexself.question_ids.append(question_id)with torch.no_grad():question_matrixs = torch.stack(self.question_ids, dim=0)if torch.cuda.is_available():question_matrixs = question_matrixs.cuda()self.knwb_vectors = self.model(question_matrixs)#将所有向量都作归一化 v / |v|self.knwb_vectors = torch.nn.functional.normalize(self.knwb_vectors, dim=-1)returndef encode_sentence(self, text):input_id = []if self.config["vocab_path"] == "words.txt":for word in jieba.cut(text):input_id.append(self.vocab.get(word, self.vocab["[UNK]"]))else:for char in text:input_id.append(self.vocab.get(char, self.vocab["[UNK]"]))return input_iddef predict(self, sentence):input_id = self.encode_sentence(sentence)input_id = torch.LongTensor([input_id])if torch.cuda.is_available():input_id = input_id.cuda()with torch.no_grad():test_question_vector = self.model(input_id) #不输入labels,使用模型当前参数进行预测res = torch.mm(test_question_vector.unsqueeze(0), self.knwb_vectors.T)hit_index = int(torch.argmax(res.squeeze())) #命中问题标号hit_index = self.question_index_to_standard_question_index[hit_index] #转化成标准问编号return self.index_to_standard_question[hit_index]if __name__ == "__main__":knwb_data = load_data(Config["train_data_path"], Config)model = SiameseNetwork(Config)model.load_state_dict(torch.load("model_output/epoch_10.pth"))pd = Predictor(Config, model, knwb_data)sentence = "发什么有短信告诉说手机话费"res = pd.predict(sentence)print(res)while True:sentence = input("请输入:")print(pd.predict(sentence))这段代码主要是基于Siamese网络的文本匹配,实现简单文本意图识别的问答系统。通过训练得到的模型,系统能够将输入的问题与知识库中的问题进行相似度比较,并返回最匹配的标准问题。主要功能是将输入问题与预训练模型进行匹配,并返回最相关的标准问题。代码流程包括问题向量化、输入句子编码、相似度计算和最终的预测结果输出。
类初始化
class Predictor:def __init__(self, config, model, knwb_data):self.config = configself.model = modelself.train_data = knwb_dataif torch.cuda.is_available():self.model = model.cuda()else:self.model = model.cpu()self.model.eval()self.knwb_to_vector()
__init__方法中,config是配置文件,model是训练好的Siamese网络模型,knwb_data是训练数据。model.eval():将模型设置为推理模式,禁用掉训练时的dropout等机制。knwb_to_vector()方法被调用,目的是将训练数据中的问题转化为向量,以便后续进行匹配。
加载问答知识库
def knwb_to_vector(self):self.question_index_to_standard_question_index = {}self.question_ids = []self.vocab = self.train_data.dataset.vocabself.schema = self.train_data.dataset.schemaself.index_to_standard_question = dict((y, x) for x, y in self.schema.items())for standard_question_index, question_ids in self.train_data.dataset.knwb.items():for question_id in question_ids:self.question_index_to_standard_question_index[len(self.question_ids)] = standard_question_indexself.question_ids.append(question_id)with torch.no_grad():question_matrixs = torch.stack(self.question_ids, dim=0)if torch.cuda.is_available():question_matrixs = question_matrixs.cuda()self.knwb_vectors = self.model(question_matrixs)self.knwb_vectors = torch.nn.functional.normalize(self.knwb_vectors, dim=-1)
- 该方法的主要作用是将知识库中的问题转化为向量,以便之后与输入的句子进行相似度匹配。
question_index_to_standard_question_index记录问题编号与标准问题编号的映射,用来标记最终答案的准确性。question_matrixs是所有问题的ID集合,经过模型转化后,得到问题的向量表示knwb_vectors。torch.nn.functional.normalize()对所有向量进行归一化,使得它们的长度为1,便于计算相似度。
文本向量化
def encode_sentence(self, text):input_id = []if self.config["vocab_path"] == "words.txt":for word in jieba.cut(text):input_id.append(self.vocab.get(word, self.vocab["[UNK]"]))else:for char in text:input_id.append(self.vocab.get(char, self.vocab["[UNK]"]))return input_id
- 该方法将输入的文本句子转换为词或字的ID序列。如果配置文件中指定的词汇表路径是
words.txt,则使用jieba进行分词,否则按字符逐一处理。 - 如果某个词或字符在词汇表中不存在,则使用
[UNK]代替。
知识库查询
def predict(self, sentence):input_id = self.encode_sentence(sentence)input_id = torch.LongTensor([input_id])if torch.cuda.is_available():input_id = input_id.cuda()with torch.no_grad():test_question_vector = self.model(input_id)res = torch.mm(test_question_vector.unsqueeze(0), self.knwb_vectors.T)hit_index = int(torch.argmax(res.squeeze()))hit_index = self.question_index_to_standard_question_index[hit_index]return self.index_to_standard_question[hit_index]
predict方法用于对用户输入的句子进行查询预测。- 首先,将句子转化为ID序列
input_id。 - 然后,输入到模型中得到句子的向量表示
test_question_vector。 torch.mm计算该句子向量与所有知识库问题向量的相似度。- 通过
torch.argmax(res.squeeze())得到最相似问题的索引,进而通过question_index_to_standard_question_index和index_to_standard_question映射回标准问题。
主程序main测试
if __name__ == "__main__":knwb_data = load_data(Config["train_data_path"], Config)model = SiameseNetwork(Config)model.load_state_dict(torch.load("model_output/epoch_10.pth"))pd = Predictor(Config, model, knwb_data)sentence = "发什么有短信告诉说手机话费"res = pd.predict(sentence)print(res)while True:sentence = input("请输入:")print(pd.predict(sentence))
- 首先,通过
load_data函数加载训练数据,并初始化模型SiameseNetwork。 - 加载训练好的模型参数(如从
epoch_10.pth文件中读取)。 - 创建
Predictor实例,并对某个示例句子进行预测(如“发什么有短信告诉说手机话费”)。 - 进入循环,不断接收用户输入的句子并返回预测结果。
测试效果
请输入:导航到流量余额查询菜单
套餐余量查询
请输入:协议预存款的金额有规定吗
月返费查询
请输入:我收到一个信息是怎么回事
宽泛业务问题
请输入:
参考博客
1.基于余弦相似度实现的文本匹配
1 ↩︎