JVM 垃圾回收
垃圾回收
在 C/C++ 没有自动垃圾回收机制的语言中,一个对象如果不再被使用,则需要手动释放,否则就会出现内存泄漏(不再使用的对象未被系统回收而导致内存溢出)。
Java 为了简化对象释放的操作,降低编程的复杂度,引入的自动的垃圾回收 ( GC - Garbage Collection ) 机制。通过垃圾回收器来将不再使用的对象完成自动的回收,其主要负责对堆上的内存进行回收。
方法区回收
在运行时数据区中,线程不共享的部分,都是伴随着线程的创建而创建,线程的销毁而销毁,并且方法的栈帧在方法执行完成后会自动弹出栈并释放掉其对应的内存。
方法区中能被回收的内容主要是不再使用的类,判断一个类是否可以被卸载回收,需要满足以下三个条件:
- 此类所有实例对象都已经被回收,在堆中已经不存在任何该类的实例对象及其子类对象。
- 加载该类的类加载器已经被回收。
- 该类对应的 java.lang.Class 对象没有在任何地方被引用。
在 Java 程序中,可以使用System.gc()方法手动调用触发垃圾回收,但调用该方法并不一定会立即执行垃圾回收,而是向 Java 虚拟机发送一个垃圾回收的请求,具体执行流程还是得由 Java 虚拟机自行判断。
堆回收
判断 Java 中的对象是否能被回收,可以根据对象是否被引用而决定。若对象被引用,说明该对象正在被使用,不允许被回收。
通常有引用计数法和可达性分析法这两种方式去判断对象是否有被引用。
引用计数法
该方法会为每个对象维护一个引用计数器,当对象被引用时加一,取消引用时减一。引用计数法实现简单,但也有缺点:
- 每次引用和取消引用时都需要维护计数器,频繁操作会对系统性能有一定的影响。
- 若存在循环引用问题,则会导致对象无法回收,造成内存泄漏问题。
所以如果要使用引用计数法来判断对象是否被引用,则需要解决循环引用的问题。
可达性分析
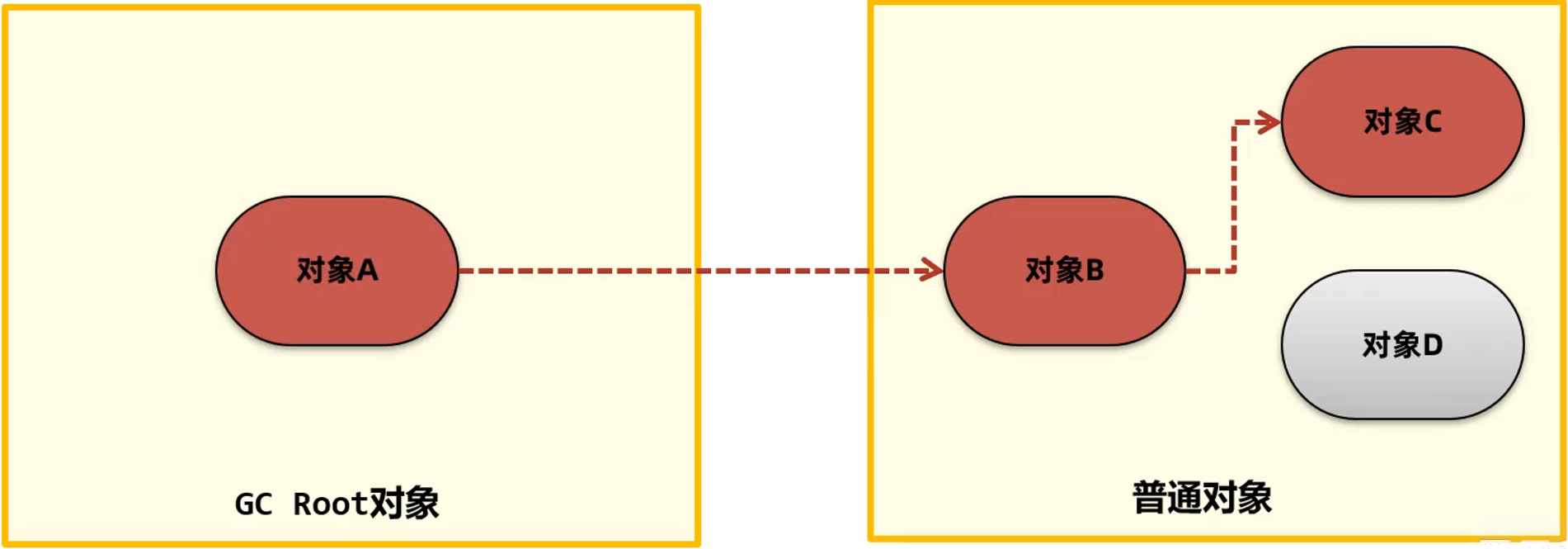
Java 使用的是可达性分析算法来进行判断对象是否可以被回收。其中可达性分析将对象分为了两类:垃圾回收的根对象(GC Root)和普通对象,同时对象与对象之间存在引用关系。一般 GC Root 对象是不可被回收的,而普通对象是可以被回收的,然而被 GC Root 对象引用的普通对象则不能被回收。
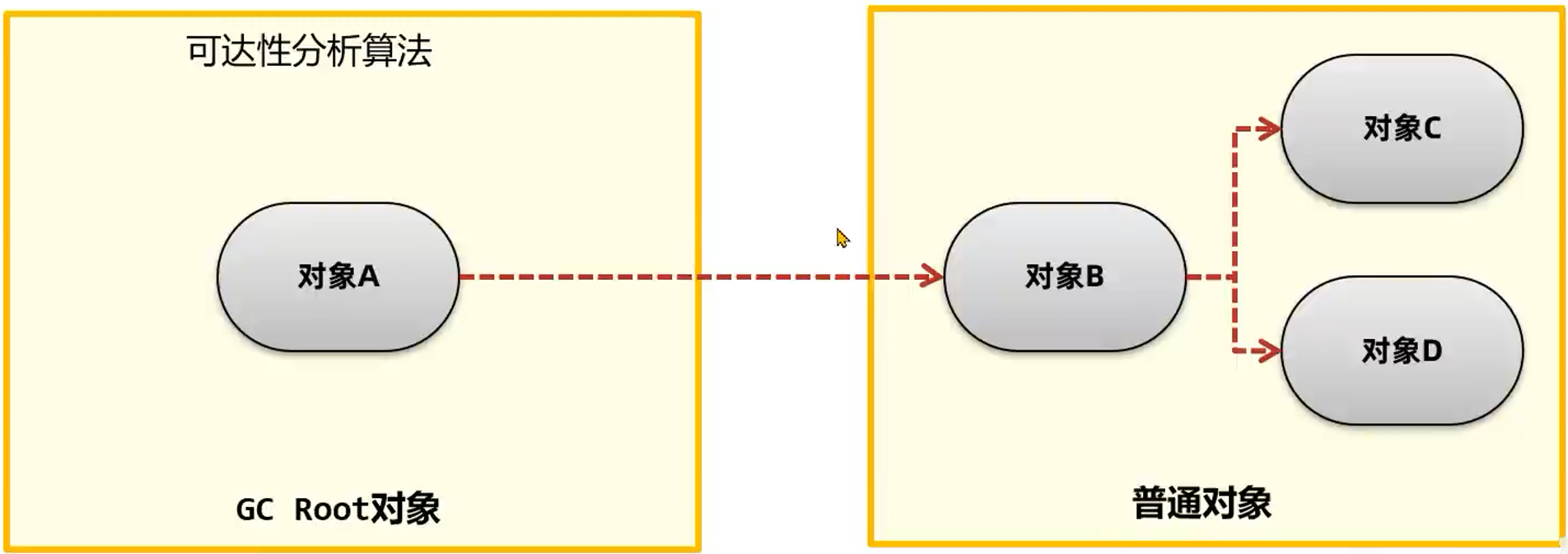
以下类别的对象都为 GC Root 对象:
- 线程 Thread 对象(其会引用线程栈帧中的方法参数、局部变量等)。
- 系统类加载器加载的 java.lang.Class 对象。
- 监视器对象,用来保存同步锁 synchronized 关键字持有的对象。
- 本地方法调用时使用的全局对象。
五种对象引用
Java 中设计了有五种对象引用的方式:
- 强引用
- 弱引用
- 软引用
- 虚引用
- 终结器引用
可达性算法中描述的对象引用,一般是指强引用,即 GCRoot 对象对普通对象存在引用关系,只要该引用关系一直存在,则普通对象则无法被回收。
软引用
用于描述一些还有用但并非必需的对象。只有在 JVM 内存不足时,垃圾回收器才会回收软引用指向的对象。如果一个对象只有软引用关联到它,当程序内存不足时,就会将软引用中的数据进行回收。软引用通常用于实现内存敏感的缓存。
在 JDK 1.2 之后提供了SoftReference类来实现软引用。
// 匿名类方式
SoftReference<Object> softReference = new SoftReference<>(new Object());// 先强引用,再包装软引用
Object object = new Object();
SoftReference<Object> softReference = new SoftReference<>(object);
软引用中的对象如果在内存不足时被回收,其 SoftReference 对象本身也是需要回收的,但是因为无法判断软引用中的对象是否被回收,所以无法确定 SoftReference 对象本身的回收时机, SoftReference 为此提供了一套队列机制:
- 软引用创建时,通过构造器传入引用队列
- 在软引用中包含的对象被回收时,该软引用对象会被放入引用队列。
- 通过遍历引用队列,将其中的 SoftReference 的强引用删除。
// 软引用 List 集合
List<SoftReference<byte[]>> softReferences = new ArrayList<>();// Reference 引用队列
ReferenceQueue<byte[]> referenceQueue = new ReferenceQueue<>();// 循环放入对象与 SoftReference
for(int i = 0;i < 5;i++) {// 创建 SoftReference 时,指定 Reference 队列SoftReference<byte[]> softReference = new SoftReference<>(new byte[1024*1024*100],referenceQueue);// 集合存入 SoftReferencesoftReferences.add(softReference);
}// 计数器:软引用中其中被回收对象的个数
int count = 0;
while(referenceQueue.poll() != null) {count++;
}// 输出结果
System.out.println(count);
下面将使用 SoftReference 实现一个能够自动回收内存的缓存。
创建一个 User 对象
class User {private Long id;private String username;public User(Long id, String username) {this.id = id;this.username = username;}public Long getId() {return id;}public void setId(Long id) {this.id = id;}public String getUsername() {return username;}public void setUsername(String username) {this.username = username;}
}
创建 UserCache
public class UserCache {/*** 创建单例实例*/private static final UserCache cache = new UserCache();/*** 用于存储用户引用的映射表*/private final Map<Long, UserReference> userReferenceMap;/*** 引用队列,用于跟踪被垃圾回收的引用*/private final ReferenceQueue<User> queue;/*** 私有构造函数,初始化映射表和引用队列*/private UserCache() {userReferenceMap = new HashMap<>();queue = new ReferenceQueue<>();}/*** 获取单例实例* @return {@link UserCache }*/public static UserCache getInstance() {return cache;}/*** 将用户缓存到映射表中** @param user 用户*/private void cacheUser(User user) {// 清理已被回收的用户引用cleanCache();// 创建用户的软引用UserReference reference = new UserReference(user, queue);// 将用户引用存储到映射表中userReferenceMap.put(user.getId(), reference);// 打印映射表的大小System.out.println(userReferenceMap.size());}/*** 根据用户ID获取用户** @param id 同上* @return {@link User }*/public User getUser(Long id) {// 从映射表中获取用户引用UserReference reference = userReferenceMap.getOrDefault(id, null);// 如果引用为空,抛出异常if (reference == null) {throw new RuntimeException("Not found this user, because its reference is null!");}// 获取软引用中的实际用户对象User user = reference.get();// 如果用户对象为空(已被垃圾回收),抛出异常if (user == null) {throw new RuntimeException("The user with the ID of " + id + " was not found");}// 返回用户对象return user;}// 内部类,用于表示用户的软引用private static class UserReference extends SoftReference<User> {// 用户IDprivate final Long key;// 构造函数,创建软引用并记录用户IDpublic UserReference(User user, ReferenceQueue<User> queue) {super(user, queue);key = user.getId();}}/*** 清理已被回收的用户引用*/private void cleanCache() {UserReference reference;// 从引用队列中轮询被回收的引用,并从映射表中移除对应的用户IDwhile ((reference = (UserReference) queue.poll()) != null) {userReferenceMap.remove(reference.key);}}// 主函数,用于测试public static void main(String[] args) {// 创建随机数生成器Random random = new Random();// 无限循环,随机生成用户并缓存while (true) {UserCache.getInstance().cacheUser(new User(random.nextLong(), String.valueOf(random.nextLong())));}}
}
弱引用
弱引用的整体机制与软引用基本一致,区别在于弱引用中包含的对象在垃圾回收时,无论内存是否充足都会被直接回收。弱引用主要使用在 ThreadLocal 中。
在 JDK 1.2 版本之后提供了WeakReference类来实现弱引用,弱引用对象本身也可以使用引用队列进行回收。
WeakReference<Object> weakRef = new WeakReference<>(new Object());
虚引用
虚引用也叫幽灵引用/幻影引用,不能通过虚引用对象获取到包含的对象。虚引用唯一的用途是当对象被垃圾回收器回收时可以接收到对应的通知。Java中使用PhantomReference实现了虚引用,直接内存中为了及时知道直接内存对象不再使用,从而回收内存,使用了虚引用来实现。虚引用在常规开发中不会被使用。
终结器引用
终结器引用指的是在对象需要被回收时,对象将会被放置在 Finalizer 类中的引用队列中,并在稍后由一条由 FinalizerThread 线程从队列中获取对象,然后执行对象的finalize方法。在这个过程中可以在 finalize 方法中再将自身对象使用强引用关联上,但是不建议这样做,如果耗时过长会影响其他对象的回收。
垃圾回收算法评价标准
垃圾回收主要做两件事情:
- 找到并保留内存中存活的对象。
- 释放不再存活对象的内存,使得程序能再次利用这部分空间。

Java 垃圾回收过程会通过单独的 GC 线程来完成,但是不管使用哪一种 GC 算法,都会有部分阶段需要停止所有的用户线程。这个过程被称之为Stop The World简称STW,如果STW时间过长则会影响用户的使用。

可以从以下三个方面来判断 GC 算法是否优秀:
- 吞吐量
吞吐量指的是 CPU 用于执行用户代码的时间与 CPU 总执行时间的比值,吞吐量数值越高,垃圾回收的效率就越高。 - 最大暂停时间
最大暂停时间指的是所有在垃圾回收过程中的STW时间最大值。最大暂停时间越短,用户使用系统受影响越短。 - 堆使用效率
不同垃圾回收算法对堆内存的使用方法是不同的。堆使用效率越高,则该 GC 算法越好。例如标记清除算法可以使用完整的堆内存,而复制算法将堆内存一分为二,每次只能使用一半的内存,则从堆使用效率上来看,标记清除算法要优于复制算法。
上述三种评价标准:堆使用效率、吞吐量,以及最大暂停时间不可兼得。一般来说,堆内存越大,最大暂停时间就越长。想要减少最大暂停时间,就会降低吞吐量。
垃圾回收算法
下面将逐个介绍这四种垃圾回收算法是如何回收垃圾的

标记清除算法
分为两个阶段:标记阶段和清除阶段。在标记阶段,遍历所有的对象,将可达的对象进行标记。在清除阶段,回收未被标记的对象。可以处理循环引用的问题。
- 标记阶段,将所有存活的对象进行标记。java中使用可达性分析算法,从GC Root开始通过引用链遍历出所有存活对象。
- 清除阶段,从内存中删除没有被标记也就是非存活对象。
该算法实现简单,只需要在第一阶段给每个对象维护标志位,第二个阶段删除对象即可。
由于内存是连续的,所以在对象被删除之后,内存中会出现很多细小的可用内存单元,产生内存碎片。如果需要的是一个比较大的空间,很有可能这些内存单元的大小过小无法进行分配。
由于内存碎片的存在,需要维护一个空闲链表,极有可能发生每次需要遍历到链表的最后才能获得合适的内存空间,所以其分配速度比较慢,效率较低。
复制算法
复制算法的核心思想是:
- 准备两块空间From空间和To空间,每次在对象分配阶段,只能使用其中一块空间(From空间)
- 在垃圾回收GC阶段,将From中存活对象复制到To空间。
- 将两块空间的From和To名字互换,随后清空To块空间上的内存
复制算法只需要遍历一次存活对象复制到To空间即可,比标记整理算法少了一次遍历的过程,因而性能较好,但是不如标记清除算法。因为标记清除算法不需要进行对象的移动。复制算法在复制之后就会将对象按照顺序放入To空间中,所以对象以外的区域都是可用区域,并不存在碎片化内存空间。
但是该算法的内存使用率低,每次只能让一半的内存空间来创建对象使用。
标记整理算法
也是分为标记和整理两个阶段。标记阶段与标记-清除算法相同。整理阶段将存活的对象向一端移动,整理后直接回收内存。

该算法内存使用率高,其整个堆内存都可以使用,不会像复制算法只能使用半个堆内存。
在整理阶段可以将对象往内存的一侧进行移动,剩下的空间都是可以分配对象的有效空间。
整理算法有很多种,比如 Lisp2 整理算法需要对整个堆中的对象搜索3次,整体性能不佳。可以通过Two-Finger、表格算法、ImmixGC 等高效的整理算法优化此阶段的性能。
分代垃圾回收算法
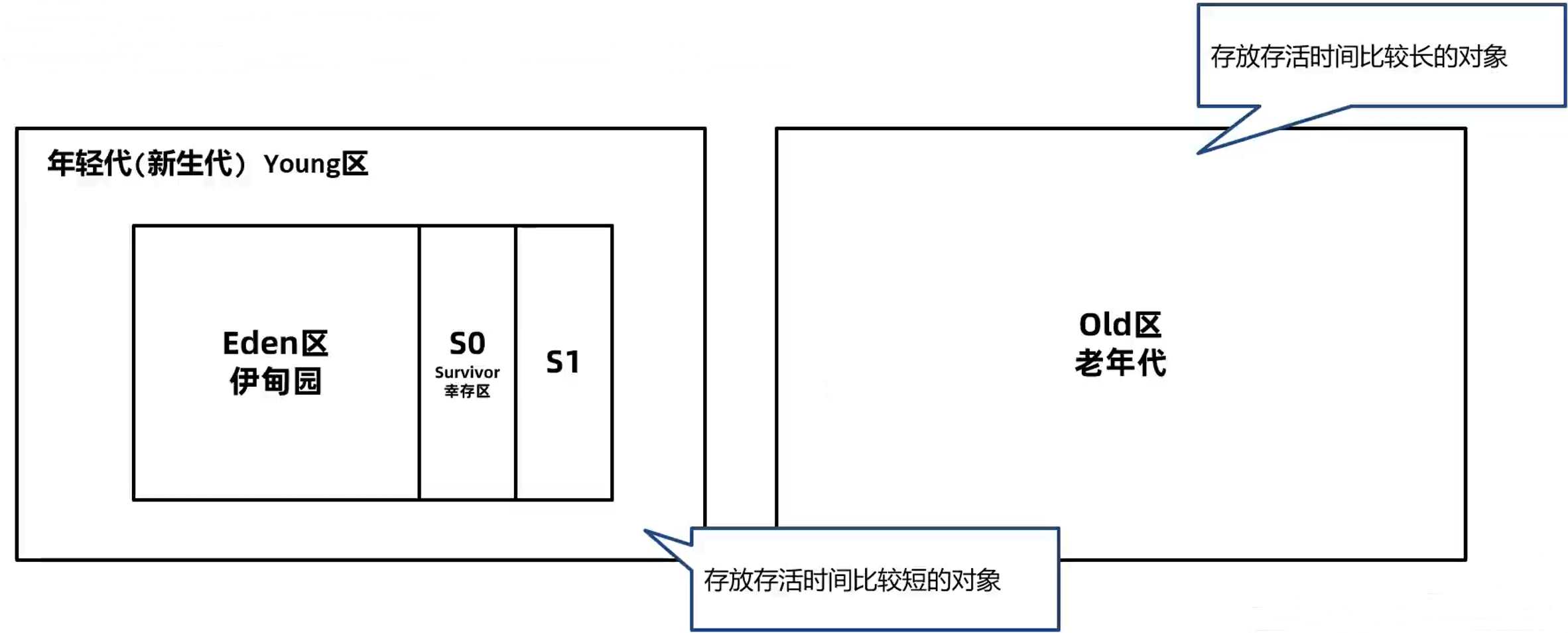
分代回收算法会将堆内存分为不同的代,例如新生代、老年代,根据对象的生命周期进行管理。新生代用于存储新创建的对象,老年代用于存储存活时间较长的对象。
分代回收时,创建出来的对象,首先会被放入Eden伊甸园区。
随着对象在Eden区越来越多,如果Eden区满,新创建的对象已经无法放入,就会触发年轻代的GC,称为 Minor GC 或者 Young GC。
Minor GC会把需要eden中和From需要回收的对象回收,把没有回收的对象放入To区。
接下来,S0会变成To区,S1变成From区。当eden区满时再往里放入对象,依然会发生 Minor GC。
此时会回收eden区和S1(from)中的对象,并把eden和from区中剩余的对象放入S0(每次 Minor GC 中都会为对象记录其年龄,初始值为0,每次GC完加1)。
如果 Minor GC 后对象的年龄达到阈值(最大15,默认值和垃圾回收器有关),对象就会被晋升至老年代。
当老年代中空间不足,无法放入新的对象时,先尝试 minor gc 如果还是不足,就会触发 Full GC,Full GC会对整个堆进行垃圾回收。
若 Full GC 后依然无法回收掉老年代中的对象,则当对象继续放入老年代时,就会抛出 Out Of Memory 异常。
可以根据以下虚拟机参数,调整堆的大小,JDK 8需要加上-XX:UseSerialGC 参数手动指定垃圾回收器
| 参数名 | 参数含义 | 示例 |
|---|---|---|
| -Xms | 设置堆的最小和初始大小,必须是1024的倍数且大于1MB | 初始化大小为512MB: -Xms512m |
| -Xmx | 设置最大堆的大小,必须是1024的倍数且大于2MB | 最大堆为1024MB: -Xmx1024m |
| -Xmn | 新生代的大小 | |
| -XX:SurvivorRatio | 伊甸园区和幸存区的比例,默认为8 新生代1g内存,伊甸园区800MB,S0和S1各100MB | 比例调整为4: -XX:SurvivorRatio=4 |
| -XX:+PrintGCDetails verbose:gc | 打印GC日志 | 无 |
为什么分代回收算法要将堆分为新生代与老年代呢?
总共有以下几点原因:
- 系统中的大多数对象创建后不久就不再使用,便可以进行回收。
- 如果堆内存没有分代,每次垃圾回收都需要扫描整个堆,而分代回收算法通常只对新生代进行频繁回收,从而减少了全堆扫描的开销,提高了回收效率。
- 分代回收算法可以根据应用程序的对象分布情况灵活调整新生代和老年代的大小,从而优化内存管理。例如,可以通过调整新生代的大小来减少频繁垃圾回收带来的停顿。
- 适应不同的应用场景,短命对象为主的应用适合将更多内存分配给新生代,快速回收短命对象。长命对象为主的应用适合将更多内存分配给老年代,减少新生代的回收频率。
垃圾回收器
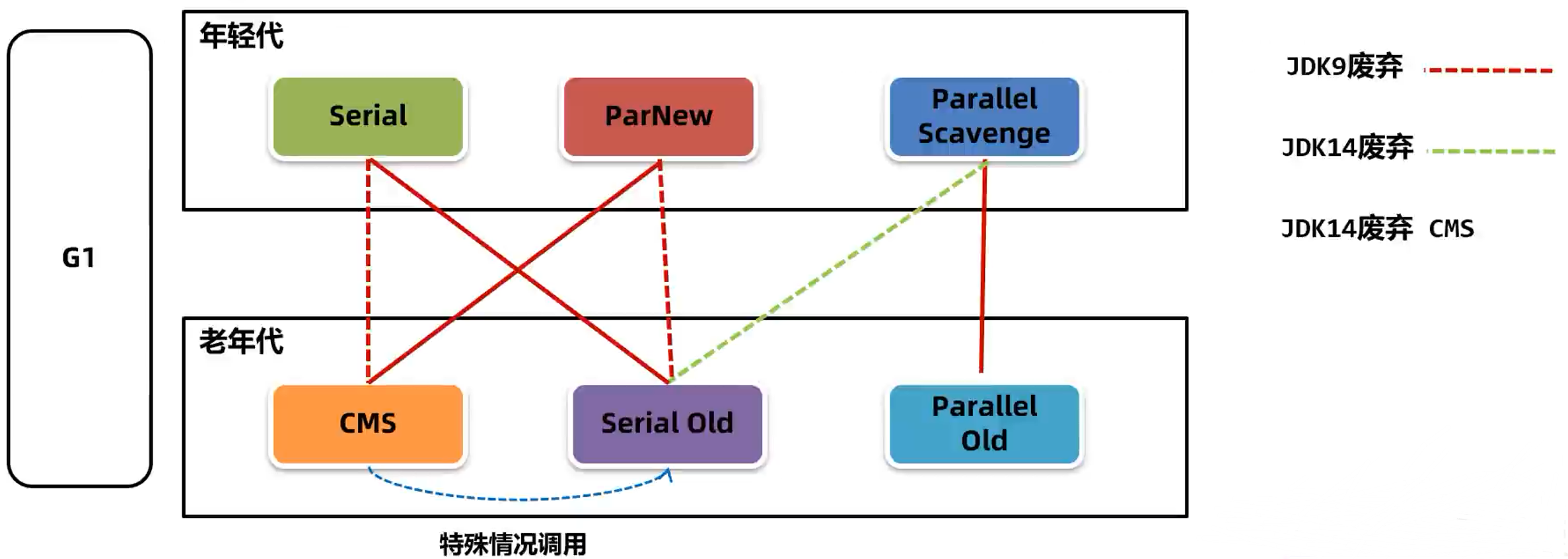
垃圾回收器是垃圾回收算法的具体实现。由于垃圾回收器分为年轻代和老年代,除了 G1 之外的其他垃圾回收器必须成对组合进行使用。
Serial GC
Serial是是一种单线程串行回收年轻代的垃圾回收器。其采用的是复制算法,回收年轻代。其在单CPU处理器下吞吐量出色,但在多CPU下吞吐量不如其他垃圾回收器,堆如果偏大会导致用户线程处于长时间的等待中。适用于 Java 编写的客户端程序或硬件配置有限的场景。
其对应的 SerialOld 是 Serial 垃圾回收器的老年代版本,依旧采用的是单线程串行回收,但 SerialOld 采用的是标记-整理算法。-XX:+UserSerialGC新生代、老年代都使用串行回收器。
ParNew GC
ParNew垃圾回收器本质上是对Serial在多 CPU 下的优化,所以仍然采用的复制算法,使用多线程在年轻进行垃圾回收
-XX:+UseParNewGC新生代使用ParNew回收器,老年代使用串行回收器。
其优点是在多CPU处理器下停顿时间较短,但吞吐量和停顿时间不如G1,所以在 JDK9 之后便不建议使用。该 GC 适用于 JDK8 及其之前版本中,与 CMS 老年代垃圾回收器搭配使用。
CMS GC
CMS,Concurrent Mark Sweep
CMS垃圾回收器关注的是系统的暂停时间允许用户线程和垃圾回收线程在某些步骤中同时执行,减少了用户线程的等待时间。
JVM参数为:-XX:+UseConcMarkSweepGC
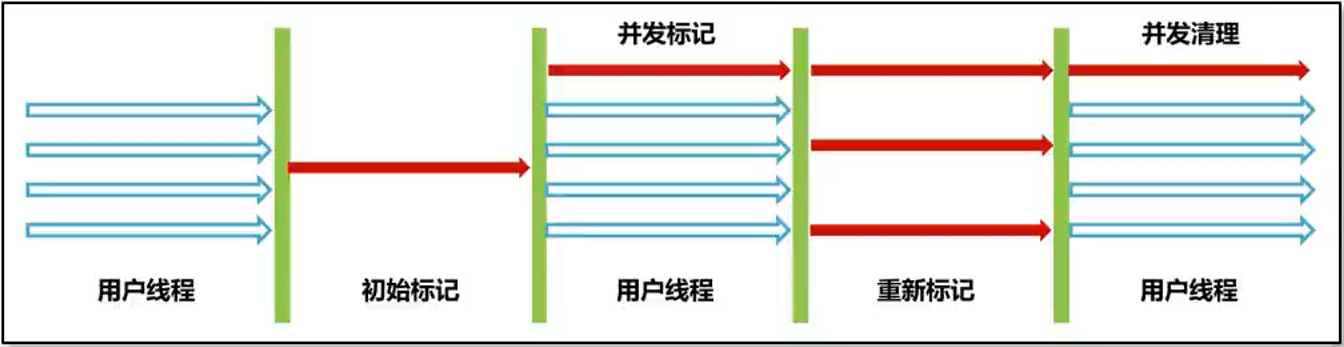
其采用的是标记-清除-整理算法回收老年代,使用该回收算法的系统由于垃圾回收出现的停顿时间(STW)较短,用户体验好。缺点是会有内存碎片、退化(如果老年代内存不足无法分配对象,则会退化成 SerialOld 单线程串行回收老年代)、浮动垃圾等问题。适用于大型互联网系统中用户请求数据量大、频率高的场景,例如订单接口与商品接口等。
Parallel Scavenge GC
ParallelScavenge是JDK8 默认的年轻代垃圾回收器多线程并行回收,关注的是系统的吞吐量。具备自动调整堆内存大小的特点。
Oracle官方建议在使用这个组合时,不要设置堆内存的最大值,垃圾回收器会根据最大暂停时间和吞吐量自动调整内存大小。
其主要采用复制算法回收年轻代,吞吐量高,并且可以手动控制,为了提高吞吐量,虚拟机会动态调整堆的参数,但不能保证单次的停顿(STW)时间,适用于后台任务,不需要与用户交互,且容易产生大量的对象的场景。
Parallel Old GC
Parallel Old是为Parallel Scavenge收集器设计的老年代版本,利用多线程并发收集。
参数:-XX:+UseParallelGC 或 -XX:+UseParallelOldGC可以使用 Parallel Scavenge + Parallel Old这种组合。
该回收器采用标记整理算法回收老年代,并行收集,在多核CPU下效率较高,但暂停时间会比较长,与 Parallel Scavenge 配套使用。
| 参数 | 说明 |
|---|---|
| -XX:MaxGCPauseMillis=n | 设置每次垃圾回收时的最大停顿毫秒数 |
| -XX:GCTimeRatio=n | 设置吞吐量为n(用户线程执行时间=n/(n + 1)) |
| -XX:+UseAdaptiveSizePolicy | 可以让垃圾回收器根据吞吐量和最大停顿的毫秒数自动调节内存大小 |
G1 GC
JDK9之后默认的垃圾回收器是G1(Garbage First)垃圾回收器。JDK 8之前可以使用 JVM 参数-XX:UseG1GC打开 G1 的开关,JDK 9之后为默认回收器则不需要手动打开,当然不建议 JDK 8 之前使用 G1 回收器,因为此时的 G1 并不够成熟,存在一些问题。
上述的PS GC关注吞吐量,允许用户设置最大暂停时间,但是会降低年轻代可用空间的大小。CMS关注暂停时间,但是吞吐量方面会下降。G1 GC 的设计目标则是将上述两种垃圾回收器的优点进行融合:
- 支持巨大的堆空间回收,并且具有较高的吞吐量。
- 支持多CPU并行垃圾回收。
- 允许用户设置最大暂停时间。
G1出现之前的垃圾回收器内存结构一般都是连续的:
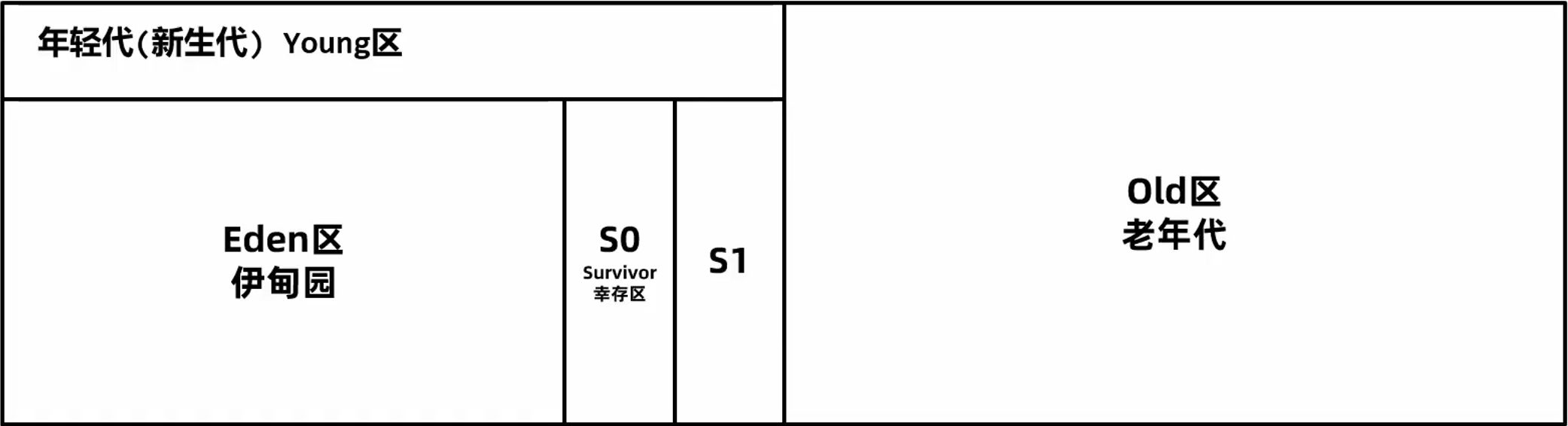
G1的整个堆会被划分成多个大小相等的区域,称之为区 Region,区域不要求是连续的。分为 Eden、Survivor、Old 区。Region的大小通过堆空间大小2048计算得到,也可以通过参数-XX:G1HeapRegionSize=32m指定(其中32m指定region大小为32M),Region size 必须是2的指数幂,取值范围从1M到32M。
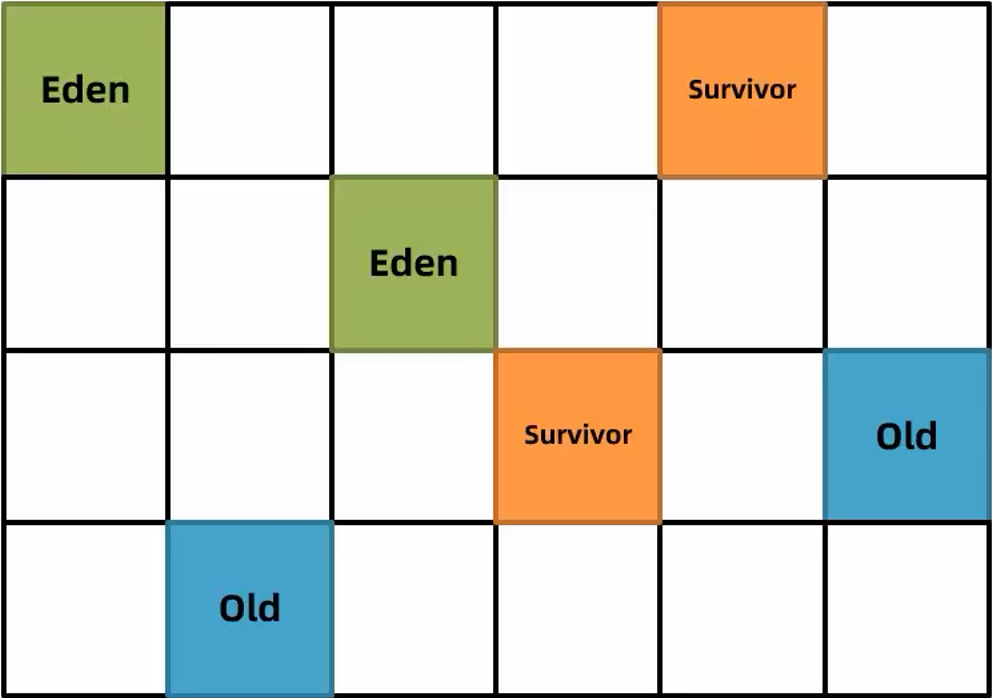
G1 垃圾回收有两种方式:新生代回收(Young GC)和混合回收(Mixed GC)
新生代回收(Young GC),回收Eden区和Survivor区中不用的对象。会导致STW,G1中可以通过参数-XX:MaxGCPauseMillis=n(默认200)设置每次垃圾回收时的最大暂停时间毫秒数,G1垃圾回收器会尽可能地保证暂停时间。
G1在进行 Young GC 的过程中会去记录每次垃圾回收时每个Eden区和Survivor区的平均耗时,以作为下次回收时的参考依据。即根据配置的最大暂停时间计算出本次回收时最多能回收多少个 Region 区域。
年轻代回收执行流程
- 新创建的对象会存放在Eden区。当G1判断新生代区不足(max默认60%,即新生代区栈总堆区的百分之六十),无法分配对象时需要回收时会执行Young GC。
- 标记出 Eden 和 Survivor 区域中的存活对象。
- 根据配置的最大暂停时间选择某些区域将存活对象复制到一个新的 Survivor 区中(年龄 + 1),并清空这些区域。
- 后续Young GC时与之前相同,只不过 Survivor 区中存活对象会被搬运到另一个Survivor区。
- 当某个存活对象的年龄到达阈值(默认15),将被晋升到老年代。
- 部分对象大小超过了 Region 的一半,则会被直接放入老年代,这类老年代被称作为 Humongous 区。例如堆内存是 4G,每个 Region 是2M,只要一个大对象超过了1M则会被放入 Humongous 区,若对象过大则会横跨多个 Region 。
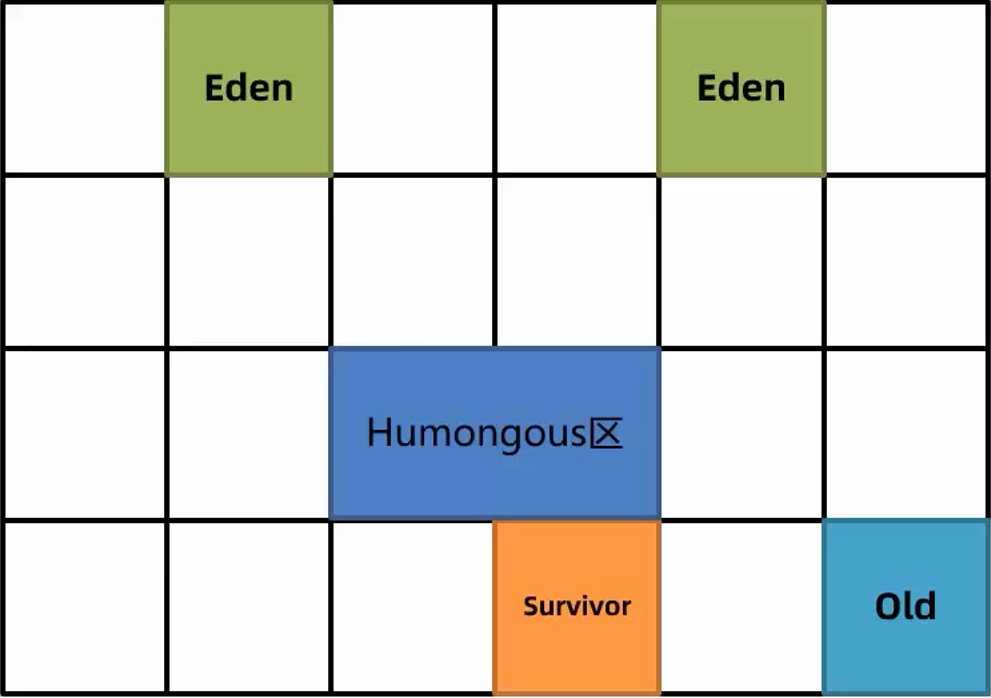
- 多次回收之后,则会出现很多老年代区,此时总堆占有率达到阈值时(JVM参数
-XX:InitiatingHeapOccupancyPercent默认为45%)则会触发混合回收 Mixed GC 。采用复制算法回收所有年轻代和部分老年代的对象以及大对象区。
混合回收分为了初始标记、并发标记、最终标记、并发清理
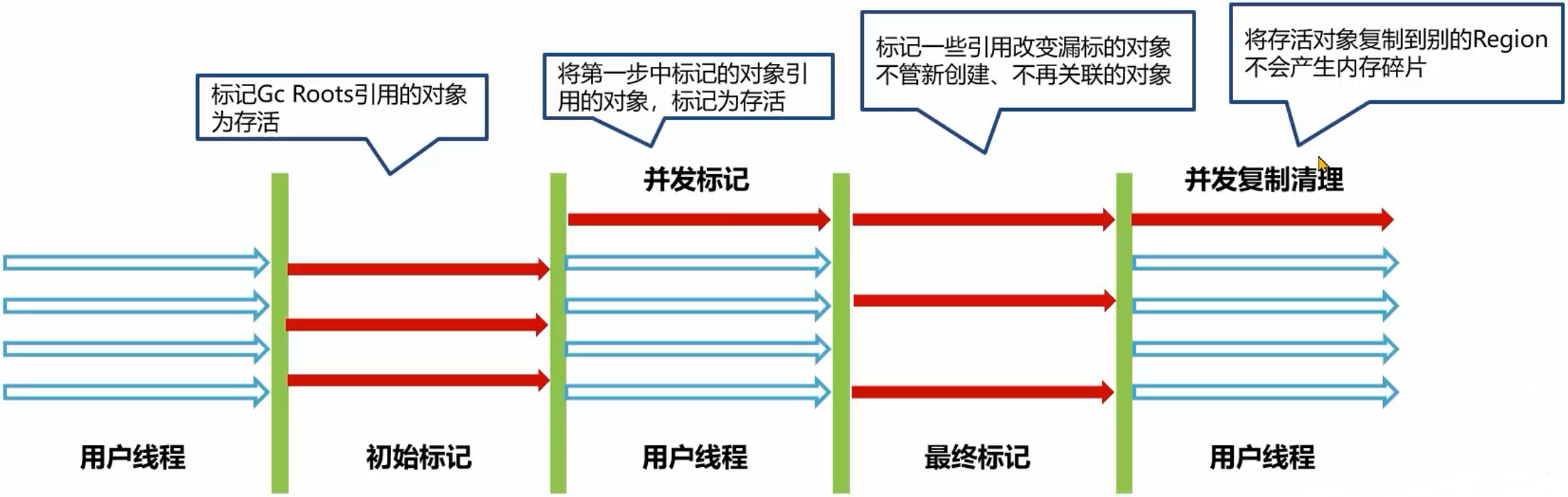
G1 对老年代的清理会选择存活度最低的区域来进行回收,可以保证回收率最高。
G1 在最后清理阶段使用复制算法,则不会产生内存碎片。
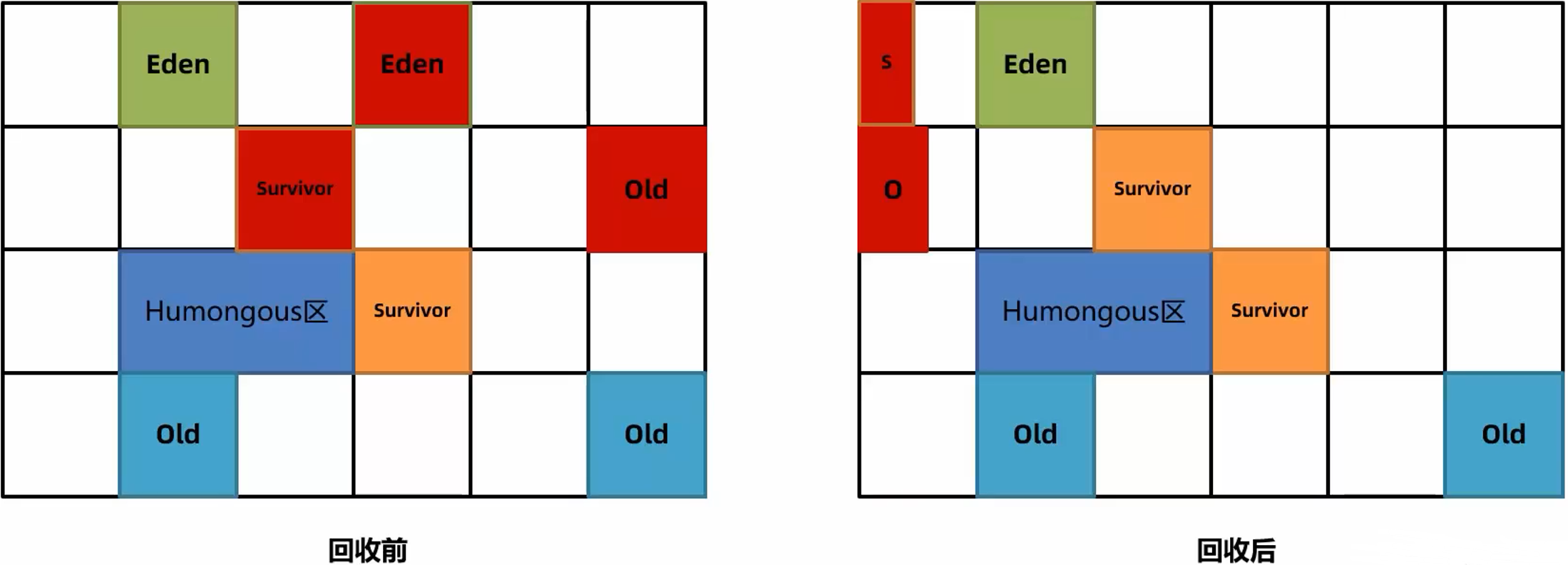
注意:如果清理过程中发现没有足够的空 Region 存放转移的对象,会出现 Full GC 。单线程执行标记-整理算法此时会导致用户线程的暂停。则需要时常保证使用中的堆内存有一定多余的空间。
Shenandoah GC
Shenandoah 是由Red Hat开发的一款低延迟的垃圾收集器,Shenandoah 并发执行大部分 GC 工作,包括并发的整理,堆大小对STW的时间基本没有影响。
Shenandoah 只包含于 OpenJDK 中,默认是不包含在内,需要自己单独构建或者下载已经构建好的。下载地址:https://builds.shipilev.net/openjdk-jdk-shenandoah/
将下载好的 Openjdk 配置到环境变量中后,使用-XX:+UseShenandoahGC开启 Shenandoah GC
调优手册:https://wiki.openjdk.org/display/shenandoah/Main
ZGC
ZGC 是一种可扩展的低延迟垃圾回收器。ZGC 在垃圾回收过程中,STW的时间不会超过一毫秒,适合需要低延迟的应用。支持几百兆到16TB 的堆大小,堆大小对STW的时间基本没有影响。
ZGC降低了停顿时间,能降低接口的最大耗时,提升用户体验。但是吞吐量不佳,所以如果Java服务比较关注 QPS (每秒的查询次数) ,那么G1仍然是比较不错的选择。
OracleJDK 和 OpenJDK 中都支持 ZGC,阿里的 DragonWell 龙井JDK 也支持 ZGC 但属于其自行对 OpenJDK11 的 ZGC 进行优化的版本
使用 ZGC 时建议使用 JDK 17 之后的版本,其延迟较低并且同时无需手动进行配置并行线程数。
使用分代 ZGC 则添加-XX:UseZGC -XX:+ZGenerational JVM参数进行启用,使用非分代 ZGC 则只添加-XX:+UseZGC参数即可。
ZGC在设计上做到了自适应,根据运行情况自动调整参数,让用户手动配置的参数最少化。其自动设置年轻代大小,无需设置-Xmn参数;自动晋升阈值(复制中存活多少次才搬运到老年代),无需设置-XX:TenuringThreshold。在JDK17之后支持自动的并行线程数,无需设置-XX:ConcGCThreads。
但是 ZGC 需要通过设置-Xmx最大的堆内存大小,这是 ZGC 最重要的一个参数,必须设置。ZGC在运行过程中会使用一部分内存用来处理垃圾回收,所以尽量保证堆中有足够的空间。设置多少值取决于对象分配的速度,根据测试情况来决定。
ZGC 还可以设置-XX:SoftMaxHeapSize值,设置后 ZGC 会尽量保证堆内存小于该值,这样在内存靠近这个值时会尽早地进行垃圾回收,但是依然有可能会超过该值。例如,-Xmx5g -XX:SoftMaxHeapSize=4g 这个参数设置,ZGC会尽量保证堆内存小于4GB,最多不会超过 5GB。
同时 ZGC 中可以使用Linux的Huge Page大页技术优化性能,提升吞吐量、降低延迟。
注意: 安装过程需要root 权限,所以ZGC默认有开启此功能。
操作步骤:
1、计算所需页数,Linux x86架构中大页大小为2MB,根据所需堆内存的大小估算大页数量。比如堆空间需要 16G,预留 2G ( JVM需要额外的一些非堆空间),那么页数就是 18G / 2MB= 9216。
2、配置系统的大页池以具有所需的页数(需要root权限)
echo 9216 > /sys/kernel/mm/hugepages/hugepages-2048kB/nr_hugepages
3、添加 JVM 参数-XX:+UseLargePages 启动程序进行测试
4、使用完毕后,若后续不再使用大页技术,需要将配置的页数归零释放掉其中的内存空间
echo 0 > /sys/kernel/mm/hugepages/hugepages-2048kB/nr_hugepages
GC 演进
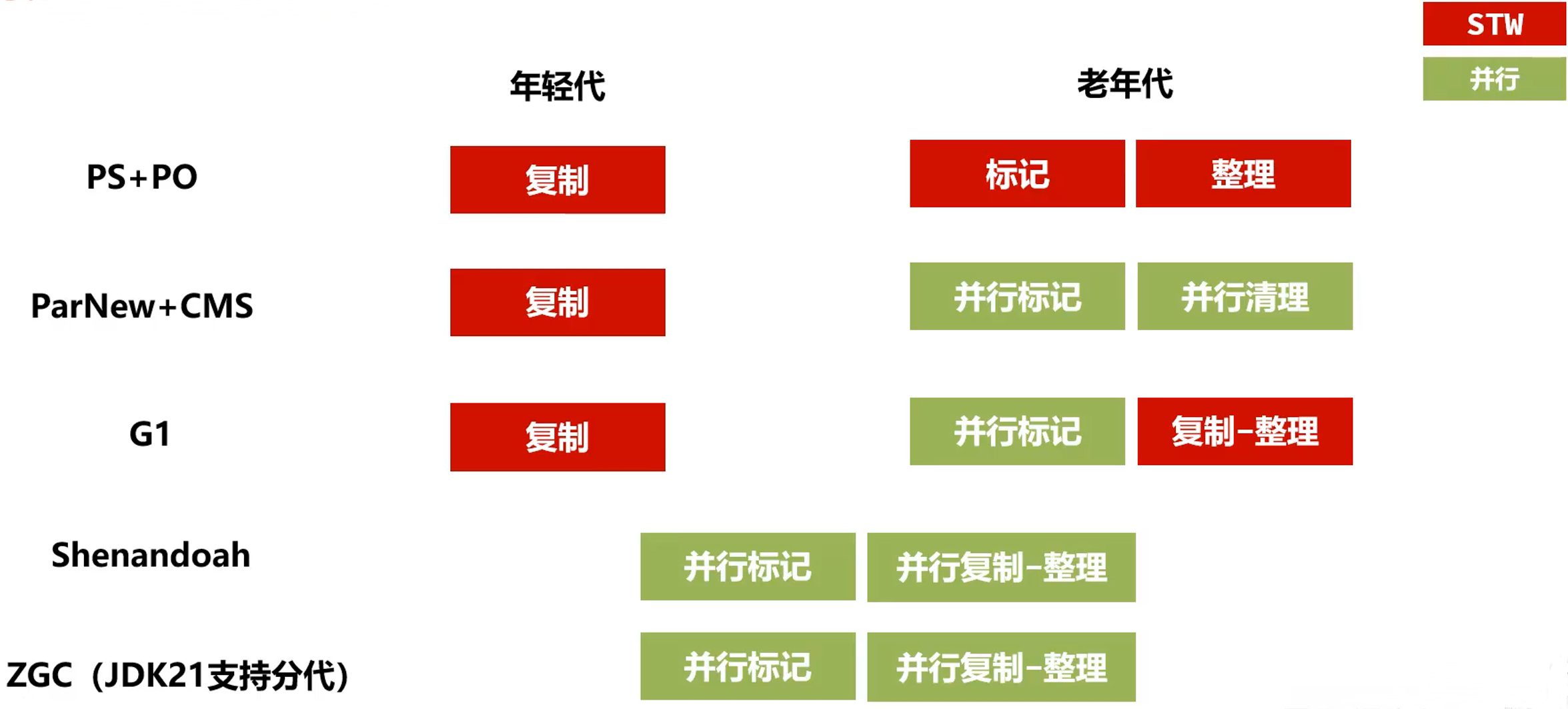
不同的垃圾回收器设计的目标是不同的
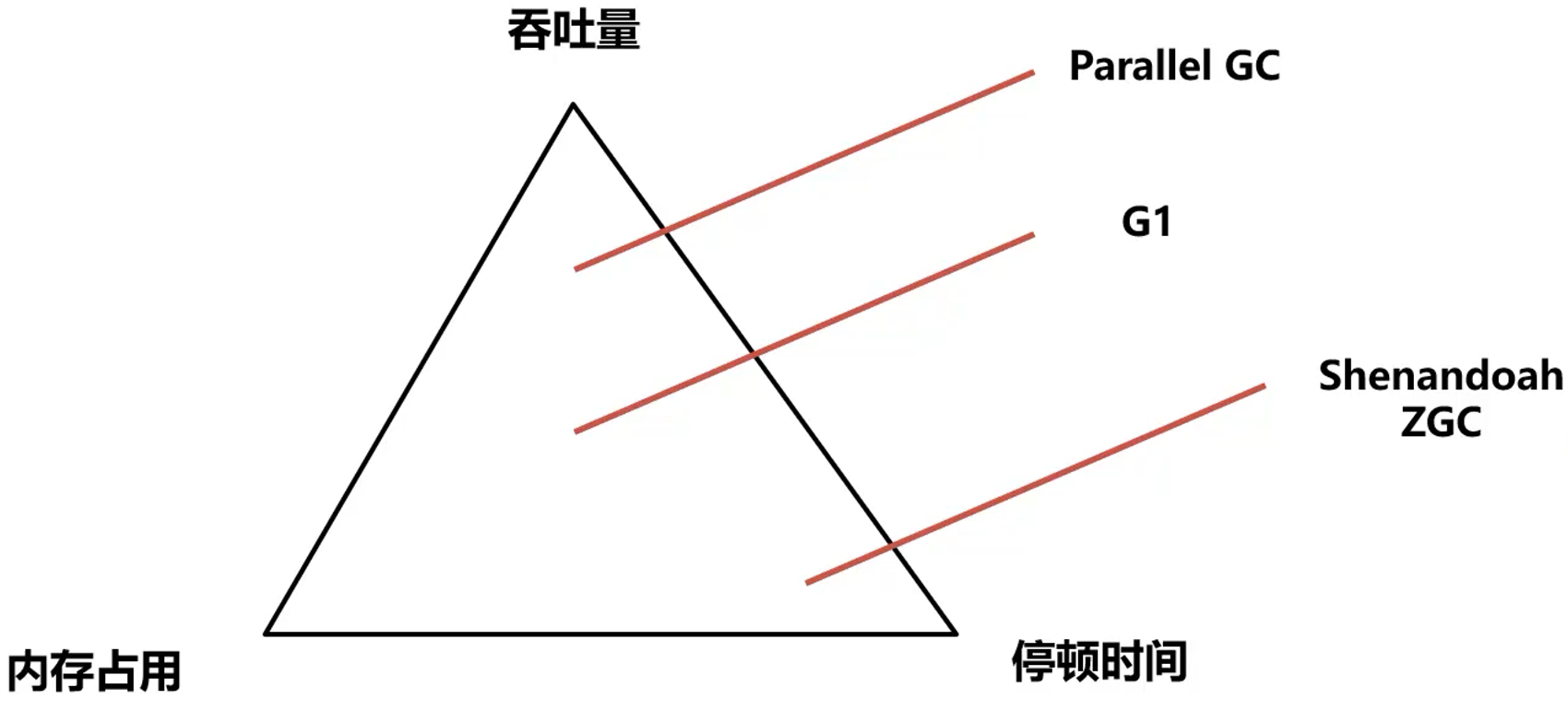
吞吐量、内存占用、停顿时间三者同时最多只能兼顾两个(突出优势)