Google-Tensorflow-NLP

1. 分词


对每个字母或者每个单词进行编码,这个过程就是分词。
在自然语言处理(NLP)中,分词(tokenization )是将文本分割成更小基本单元(token,也称词元、标记 )的过程,是很多NLP任务的关键起点。以下是关于分词的介绍:
分词粒度
即确定把文本分割成何种形式的单元,常见粒度有:
- 词粒度:将文本分割成一个个单词,符合语言直觉。如英文文本“ I love my dog” ,分词后为 [“I”, “love”, “my”, “dog”] 。但像一些固定搭配(如“look forward to” )需视为一个词处理。
- 字符粒度:把文本按单个字符分割 ,例如“apple”分词后是 [“a”, “p”, “p”, “l”, “e”] 。在处理形态丰富语言或关注字符级信息(如验证码识别、某些文字游戏 )时常用。
- 子词粒度:介于词和字符之间,将单词拆分成有意义子单元 。比如“unhappiness”可分成 [“un”, “happy”, “ness”] 。在处理词汇量大、词形变化多语言,或降低词表规模、处理未登录词时很有效,BPE(字节对编码 )算法是常用的子词划分方法。
分词方法
- 基于规则的分词:
- 原理:通过人工设定规则和词库来切分文本。如正向最大匹配法,从左向右取待切分语句m个字符作为匹配字段(m为词库中最长词条字符数 ),在词库中查找匹配,成功则切分,否则去掉最后一个字继续匹配,直至切分出所有词;逆向最大匹配法与之类似,只是从文本末端开始匹配 ;双向最大匹配法是比较正向和逆向最大匹配结果,选切分词数最少的。
- 优势:实现简单、速度快 。
- 局限:对新词、歧义词处理能力差,依赖人工编写规则和维护词库 。
- 基于统计的分词:
- 原理:基于大规模已分词语料库,利用统计机器学习模型学习词语切分规律。如N - 最短路径方法、基于词的n元语法模型分词方法等。以n元语法模型为例,通过计算词序列出现概率来确定最佳分词方式 。
- 优势:能处理新词发现等特殊场景,对不同领域文本适应性相对较好 。
- 局限:对语料库质量和规模要求高,计算复杂度较高 。
- 基于深度学习的分词:
- 原理:以基本向量化原子特征作为输入,经多层非线性变换预测当前字标记或下一步动作 。常见模型结构如LSTM + CRF、BiLSTM + CRF 等 。通过对大量文本数据学习,捕捉上下文语义信息进行分词 。
- 优势:自动学习文本特征,无需人工设计复杂规则,在复杂场景和大规模数据上表现优异 。
- 局限:训练成本高,需大量标注数据,模型解释性相对较差 。
不同语言的分词差异
- 英文分词:单词间天然由空格分隔,相对简单。但需处理固定搭配、缩写(如“it’s”需处理为“it is” )、特殊符号等情况 。可使用简单基于空格分割方法,也可用NLTK、spaCy等工具包实现更复杂处理 。
- 中文分词:词与词间无天然分隔符,分词难度大。要解决分词规范(词与词素、短语划界 )、歧义切分(如“结合成”可切分为“结合│成”或“结│合成” )、未登录词识别(新词或词表未收录词 )等问题 。常用工具包如jieba、pyltp等 。
- 其他语言:像日语有平假名、片假名、汉字混合书写情况,韩语需考虑词尾变化等,每种语言都有其独特的书写规则和语言结构,分词方法和重点也各有不同 。
分词在文本分类、情感分析、机器翻译、信息检索等诸多NLP任务中都是基础且关键的环节,合适的分词方式能提升后续任务处理效果和准确性 。
实现

基于TensorFlow框架进行文本分词处理的Python代码,具体解释如下:
import tensorflow as tf:导入TensorFlow库,并将其别名为tf,方便后续调用库中的函数和类。from tensorflow import keras:从TensorFlow库中导入Keras模块。Keras是一个用于构建和训练深度学习模型的高级API,可运行在TensorFlow等后端之上。from tensorflow.keras.preprocessing.text import Tokenizer:从TensorFlow的Keras模块的文本预处理工具中导入Tokenizer类。Tokenizer类用于将文本数据转换为数字序列,是自然语言处理任务中常见的预处理步骤。sentences = ['I love my dog', 'I love my cat']:定义了一个包含两个句子的列表sentences,作为待处理的文本数据。tokenizer = Tokenizer(num_words = 100):创建一个Tokenizer对象,其中参数num_words = 100表示仅保留训练数据中按词频排序的前100个单词 。tokenizer.fit_on_texts(sentences):让Tokenizer对象在定义的文本数据sentences上进行训练,分析文本中的单词,统计词频等信息,构建词汇表。word_index = tokenizer.word_index:获取训练后得到的单词索引字典word_index,其中键为单词,值为对应的索引编号。print(word_index):打印出单词索引字典,展示每个单词在词汇表中的索引位置。 这段代码整体实现了使用TensorFlow的Keras工具对简单文本数据进行分词及构建单词索引的功能 。

如果更新句子

from tensorflow.keras.preprocessing.text import Tokenizersentences = ['i love my dog','I, love my cat','You love my dog!'
]tokenizer = Tokenizer(num_words = 100)
tokenizer.fit_on_texts(sentences)
word_index = tokenizer.word_index
print(word_index)
结果为:

2. 文本转换成数据
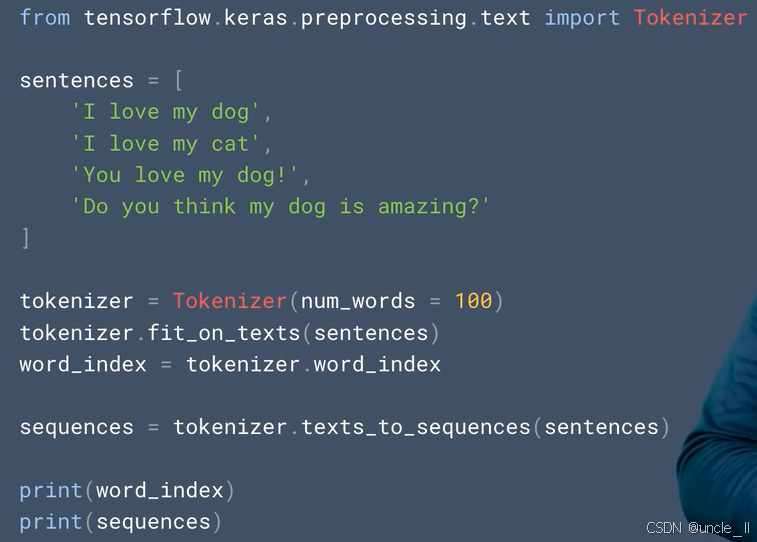
基于TensorFlow的Keras库进行文本预处理的Python代码,主要功能是对输入文本进行分词并将其转换为数字序列,具体解释如下:
from tensorflow.keras.preprocessing.text import Tokenizer:从TensorFlow的Keras模块的文本预处理工具中导入Tokenizer类,Tokenizer用于将文本数据转换为便于机器学习模型处理的格式。sentences = ['I love my dog', 'I love my cat', 'You love my dog!', 'Do you think my dog is amazing?']:创建一个包含多个句子的列表,作为待处理的文本数据集。tokenizer = Tokenizer(num_words = 100):初始化Tokenizer对象,参数num_words = 100表示仅保留训练数据中按词频排序的前100个单词 。tokenizer.fit_on_texts(sentences):让Tokenizer在sentences数据集上进行训练,分析文本中的单词,统计词频等信息,构建词汇表。word_index = tokenizer.word_index:获取训练后得到的单词索引字典,字典中的键是单词,值是该单词对应的索引编号,用于后续文本的数字化表示。sequences = tokenizer.texts_to_sequences(sentences):使用训练好的Tokenizer将sentences中的每个句子转换为数字序列,序列中的每个数字对应词汇表中单词的索引。print(word_index):打印出单词索引字典,展示每个单词在词汇表中的索引位置。print(sequences):打印出转换后的数字序列,展示每个句子对应的数字表示形式。 这段代码整体实现了对输入文本的分词、构建词汇表以及将文本转换为数字序列的功能,是自然语言处理任务中常见的预处理步骤 。

当神经网络需要对文本进行分类,而文本中有它未见过的单词时,会发生什么?
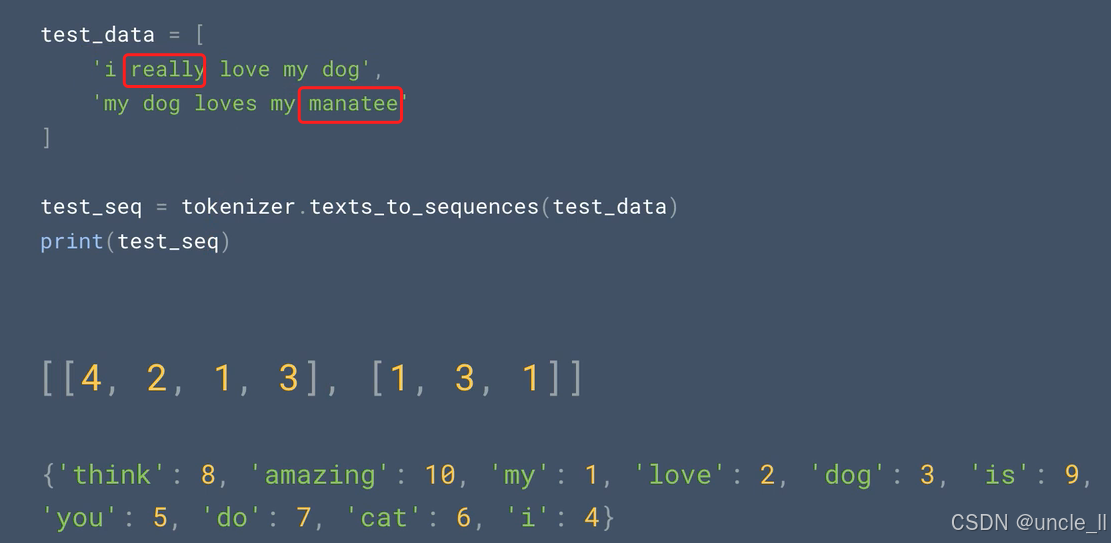
比如manatee,really这两个词. 不再词典中所以无法索引。可以添加OOV进行识别不认识的单词。
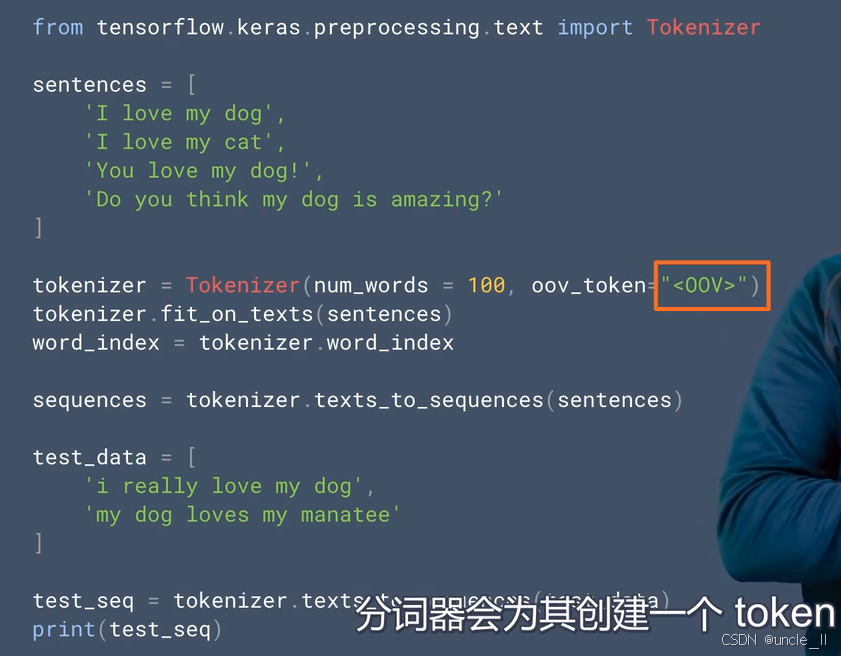
tokenizer = Tokenizer(num_words = 100, oov_token="<OOV>"):初始化Tokenizer对象,num_words = 100表示仅保留训练数据中按词频排序的前 100 个单词 ,oov_token=“”(该部分用橙色框标注 )设置了一个特殊标记 “” ,用于表示词汇表外的单词。然后通过tokenizer.fit_on_texts(sentences)在训练数据集sentences上进行训练,构建词汇表。test_seq = tokenizer.texts_to_sequences(test_data):将测试数据集test_data转换为数字序列,对于测试数据中在训练词汇表外的单词,分词器会用之前设置的 “” 标记对应的索引来表示 。最后通过print(test_seq)打印出测试数据转换后的数字序列。

如何处理不同长度的文本呢,可以使用pad操作
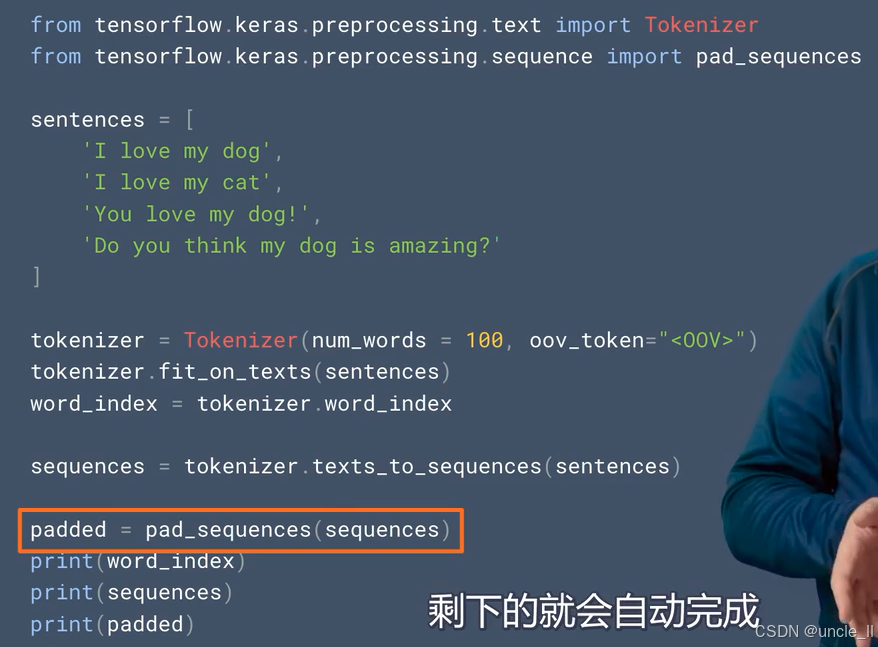
这是一段基于TensorFlow的Keras库进行文本预处理的Python代码,在之前分词基础上增加了序列填充操作,具体解释如下:from tensorflow.keras.preprocessing.text import Tokenizer:导入Tokenizer类,用于文本分词及数字化。from tensorflow.keras.preprocessing.sequence import pad_sequences:导入pad_sequences函数,用于对文本转换后的数字序列进行填充,使序列长度统一 。sentences = ['I love my dog', 'I love my cat', 'You love my dog!', 'Do you think my dog is amazing?']:创建包含多个句子的列表,作为待处理的文本数据集。tokenizer = Tokenizer(num_words = 100, oov_token="<OOV>"):初始化Tokenizer对象,设置保留前100个高频词,并指定词汇表外单词标记为“” 。然后通过tokenizer.fit_on_texts(sentences)在文本数据集上训练,构建词汇表。word_index = tokenizer.word_index:获取训练后得到的单词索引字典,记录单词与索引的对应关系。sequences = tokenizer.texts_to_sequences(sentences):将文本数据集sentences转换为数字序列。padded = pad_sequences(sequences):使用pad_sequences函数对sequences进行填充(该部分用橙色框标注 )。默认情况下,它会在较短序列前填充0 ,使所有序列长度一致,方便后续输入到深度学习模型中进行处理。 最后通过print(word_index)、print(sequences)、print(padded)分别打印单词索引字典、转换后的数字序列以及填充后的序列。
用0填充,保证长度相同。

这是Python中使用Keras的pad_sequences函数对文本转换后的数字序列进行填充和截断操作的代码,具体解释如下:pad_sequences:Keras提供的用于对序列数据(如文本转换后的数字序列 )进行填充和截断处理的函数,目的是使序列长度统一,以便输入到深度学习模型中。sequences:待处理的数字序列,通常是之前通过Tokenizer.texts_to_sequences方法得到的文本数字化后的序列。padding='post':指定填充位置为“后置” ,即如果序列长度小于指定的最大长度,在序列的末尾(后方 )填充0 (默认填充值为0 )。与之相对的是padding='pre',表示在序列开头(前方 )填充 。truncating='post':指定截断方式为“后置” ,即如果序列长度超过指定的最大长度,从序列的末尾(后方 )开始截断。若为truncating='pre',则从序列开头(前方 )截断 。maxlen=5:指定序列的最大长度为5 。如果序列长度小于5 ,根据padding参数进行填充;如果序列长度大于5 ,根据truncating参数进行截断 。 这段代码整体实现了对数字序列sequences按照指定规则进行填充和截断,使其长度统一为5 ,为后续输入深度学习模型做准备 。
实现
import tensorflow as tf
from tensorflow import kerasfrom tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequencessentences = ['I love my dog','I love my cat','You love my dog!','Do you think my dog is amazing?'
]tokenizer = Tokenizer(num_words = 100, oov_token="<OOV>")
tokenizer.fit_on_texts(sentences)
word_index = tokenizer.word_indexsequences = tokenizer.texts_to_sequences(sentences)padded = pad_sequences(sequences, maxlen=5)
print("\nWord Index = " , word_index)
print("\nSequences = " , sequences)
print("\nPadded Sequences:")
print(padded)# Try with words that the tokenizer wasn't fit to
test_data = ['i really love my dog','my dog loves my manatee'
]test_seq = tokenizer.texts_to_sequences(test_data)
print("\nTest Sequence = ", test_seq)padded = pad_sequences(test_seq, maxlen=10)
print("\nPadded Test Sequence: ")
print(padded)
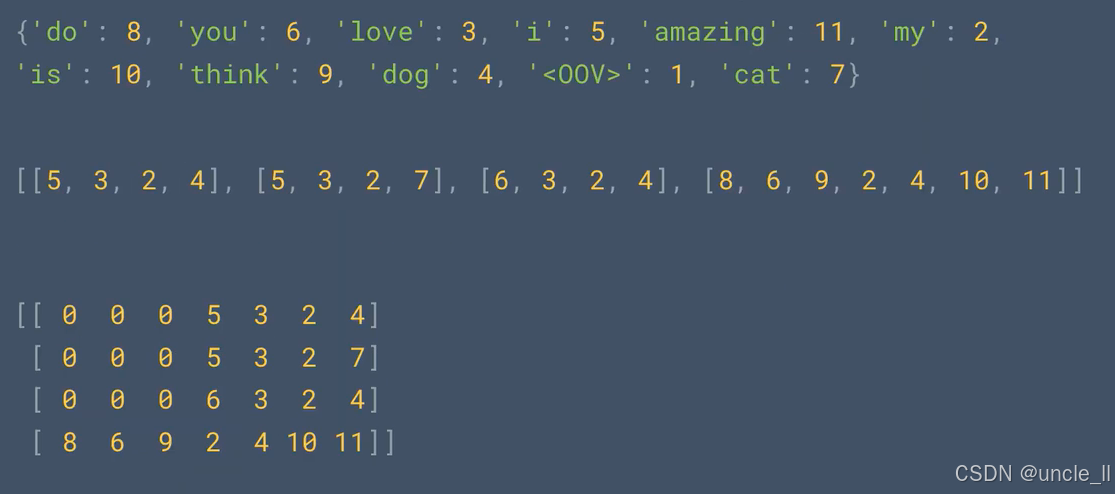
Word Index = {'<OOV>': 1, 'my': 2, 'love': 3, 'dog': 4, 'i': 5, 'you': 6, 'cat': 7, 'do': 8, 'think': 9, 'is': 10, 'amazing': 11}Sequences = [[5, 3, 2, 4], [5, 3, 2, 7], [6, 3, 2, 4], [8, 6, 9, 2, 4, 10, 11]]Padded Sequences:
[[ 0 5 3 2 4][ 0 5 3 2 7][ 0 6 3 2 4][ 9 2 4 10 11]]Test Sequence = [[5, 1, 3, 2, 4], [2, 4, 1, 2, 1]]Padded Test Sequence:
[[0 0 0 0 0 5 1 3 2 4][0 0 0 0 0 2 4 1 2 1]]
3. 训练一个模型去实现文本情感识别
数据集


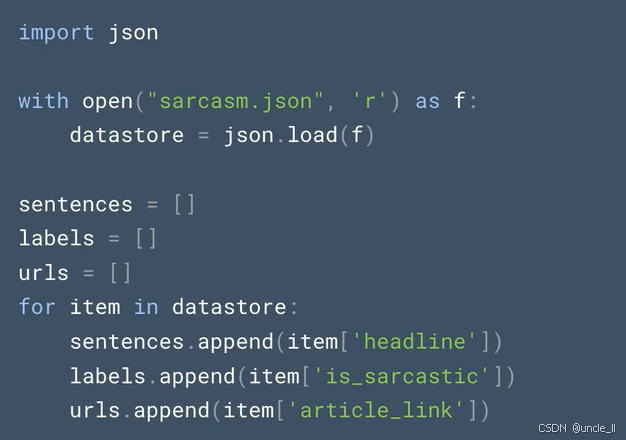
主要功能是从一个JSON文件中读取数据,并将数据解析为文本句子、标签和链接三个列表,具体解释如下:
import json:导入Python的json模块,用于处理JSON格式的数据,JSON是一种常用于存储和交换数据的轻量级数据格式 。with open("sarcasm.json", 'r') as f: datastore = json.load(f):使用with语句以只读模式('r')打开名为“sarcasm.json”的文件,并将文件对象赋值给f。然后通过json.load(f)将文件中的JSON数据解析为Python对象(通常是字典或列表 ),并赋值给datastore。with语句确保文件在使用完后会自动关闭。sentences = []:初始化一个空列表,用于存储从JSON数据中提取的文本句子。labels = []:初始化一个空列表,用于存储与文本句子对应的标签,这里标签可能用于标识句子是否为讽刺性语句(从键名'is_sarcastic'推测 )。urls = []:初始化一个空列表,用于存储与文本句子相关的链接(从键名'article_link'推测 )。for item in datastore::遍历datastore中的每个元素(假设datastore是一个列表,每个元素是一个字典 )。sentences.append(item['headline']):将每个元素中键为'headline'对应的值(即文本句子 )添加到sentences列表中。labels.append(item['is_sarcastic']):将每个元素中键为'is_sarcastic'对应的值(即标签 )添加到labels列表中。urls.append(item['article_link']):将每个元素中键为'article_link'对应的值(即链接 )添加到urls列表中。
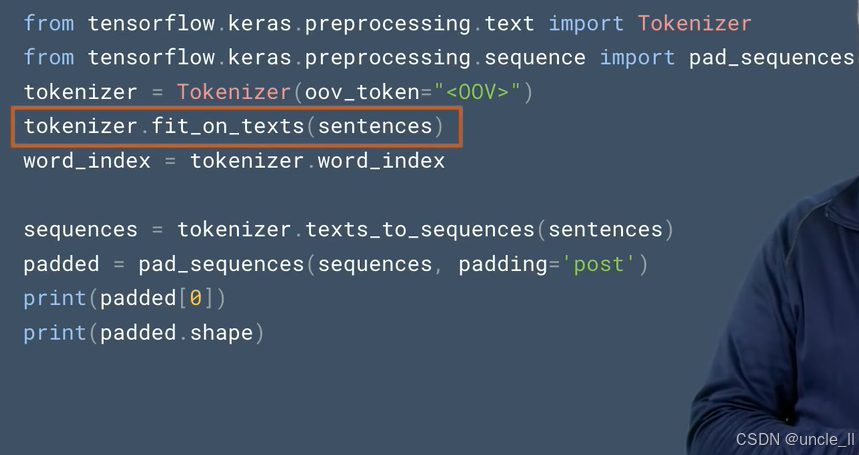
将句子分词并进行表示。

26709个词,每个句子用40个词进行表示。
划分训练集,测试集。

在机器学习和深度学习任务中,通常需要将数据集划分为训练集和测试集。训练集用于训练模型,让模型学习数据中的模式和规律;测试集用于评估模型在未见过的数据上的性能表现,检验模型的泛化能力。training_sentences = sentences[0:training_size]:从sentences列表中提取前training_size个句子,组成训练集句子列表training_sentences。这里training_size是一个预设的变量,代表训练集数据的数量,通过切片操作[0:training_size]实现从索引0开始到索引training_size - 1的元素提取 。testing_sentences = sentences[training_size:]:从sentences列表中提取索引training_size及之后的句子,组成测试集句子列表testing_sentences。该切片操作表示从索引training_size开始一直到列表末尾的所有元素 。training_labels = labels[0:training_size]:从labels列表中提取前training_size个标签,组成训练集标签列表training_labels,与训练集句子相对应。testing_labels = labels[training_size:]:从labels列表中提取索引training_size及之后的标签,组成测试集标签列表testing_labels,与测试集句子相对应。
但是训练的时候只能用见过的数据,所以分词只能对训练集进行处理,这里需要重新修改:

主要用于对文本数据进行预处理,以便输入到深度学习模型中,具体步骤如下:
tokenizer = Tokenizer(num_words=vocab_size, oov_token=oov_tok):从Keras导入的Tokenizer类创建一个分词器对象。num_words=vocab_size表示将保留训练数据中按词频排序的前vocab_size个单词 ,oov_token=oov_tok指定一个特殊标记(如<OOV>)用于表示词汇表外的单词 。tokenizer.fit_on_texts(training_sentences):使用训练集句子training_sentences对分词器进行训练,分词器会分析这些句子,统计词频,构建词汇表。word_index = tokenizer.word_index:获取训练后得到的单词索引字典,其中键是单词,值是对应的索引编号,用于后续将文本转换为数字序列。training_sequences = tokenizer.texts_to_sequences(training_sentences):将训练集句子training_sentences转换为数字序列,每个单词被替换为在单词索引字典中对应的索引编号。training_padded = pad_sequences(training_sequences, maxlen=max_length, padding=padding_type, truncating=trunc_type):对训练集数字序列进行填充和截断操作。maxlen=max_length指定序列的最大长度,padding=padding_type指定填充位置(如'pre'或'post'),truncating=trunc_type指定截断方式(如'pre'或'post'),使所有训练集序列长度统一。testing_sequences = tokenizer.texts_to_sequences(testing_sentences):将测试集句子testing_sentences转换为数字序列,依据训练阶段构建的单词索引字典进行转换。testing_padded = pad_sequences(testing_sequences, maxlen=max_length, padding=padding_type, truncating=trunc_type):对测试集数字序列进行填充和截断操作,使其长度与训练集序列统一,确保测试集数据格式与训练集一致,便于后续模型评估。
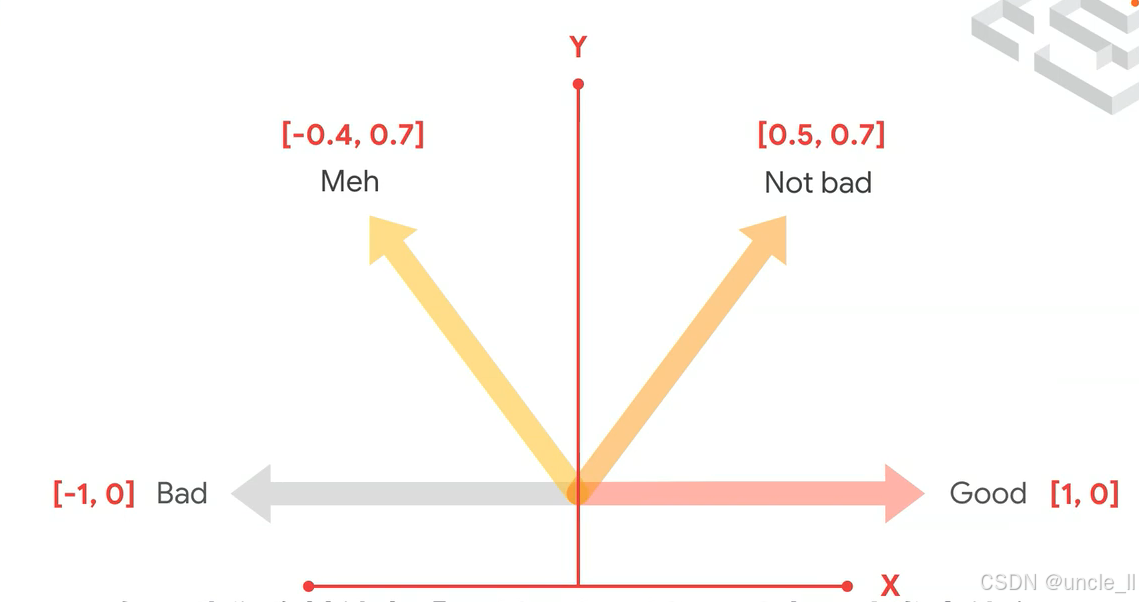
从嵌入(embedding)角度来看,这张图展示了不同情感类别在二维嵌入空间中的表示:
- 嵌入是将高维数据(如文本中的单词 )映射到低维连续向量空间的技术,在这个空间中,语义相近的元素距离较近。图中的二维坐标系(X轴和Y轴 )构成了一个简单的嵌入空间,每个点的坐标代表一个向量,用于表示特定的情感类别。
- Bad(差):坐标为
[-1, 0],位于X轴负半轴。说明在这个嵌入空间中,“Bad”情感被映射到了一个特定的向量位置,X轴值为-1 ,Y轴值为0 ,表示该情感在X轴负方向上有较强的特征表达。 - Good(好):坐标为
[1, 0],位于X轴正半轴。意味着“Good”情感在X轴正方向上有较强特征,与“Bad”情感在X轴上方向相反,体现了两者语义上的对立。 - Meh(一般):坐标为
[-0.4, 0.7],在第二象限。表明“Meh”情感在X轴负方向有一定特征(但程度弱于“Bad” ),同时在Y轴正方向也有特征,说明它在嵌入空间中的特征表达更为复杂,既不是纯粹的负面,也不是正面。 - Not bad(还不错):坐标为
[0.5, 0.7],在第一象限。表示“Not bad”情感在X轴正方向和Y轴正方向都有特征,且在X轴上的正向特征弱于“Good” ,反映出它介于“Good”和中性之间的情感程度。 - 嵌入意义: 通过将不同情感类别映射到二维嵌入空间,可直观地看出它们之间的相对位置和语义关联。相近的情感类别在空间中距离较近,如“Meh”和“Bad”在X轴负方向都有特征;相反的情感类别在空间中距离较远且方向相反,如“Bad”和“Good” 。这种嵌入表示有助于机器学习模型(如情感分类模型 )学习和区分不同情感,通过计算向量之间的距离或相似度来判断文本的情感倾向 。
实现



训练好了后进行预测:


import json
import tensorflow as tffrom tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequencesvocab_size = 10000
embedding_dim = 16
max_length = 100
trunc_type='post'
padding_type='post'
oov_tok = "<OOV>"
training_size = 20000'''
!wget --no-check-certificate \https://storage.googleapis.com/learning-datasets/sarcasm.json \-O /tmp/sarcasm.json
'''with open("/tmp/sarcasm.json", 'r') as f:datastore = json.load(f)sentences = []
labels = []for item in datastore:sentences.append(item['headline'])labels.append(item['is_sarcastic'])training_sentences = sentences[0:training_size]
testing_sentences = sentences[training_size:]
training_labels = labels[0:training_size]
testing_labels = labels[training_size:]tokenizer = Tokenizer(num_words=vocab_size, oov_token=oov_tok)
tokenizer.fit_on_texts(training_sentences)word_index = tokenizer.word_indextraining_sequences = tokenizer.texts_to_sequences(training_sentences)
training_padded = pad_sequences(training_sequences, maxlen=max_length, padding=padding_type, truncating=trunc_type)testing_sequences = tokenizer.texts_to_sequences(testing_sentences)
testing_padded = pad_sequences(testing_sequences, maxlen=max_length, padding=padding_type, truncating=trunc_type)# Need this block to get it to work with TensorFlow 2.x
import numpy as np
training_padded = np.array(training_padded)
training_labels = np.array(training_labels)
testing_padded = np.array(testing_padded)
testing_labels = np.array(testing_labels)model = tf.keras.Sequential([tf.keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length),tf.keras.layers.GlobalAveragePooling1D(),tf.keras.layers.Dense(24, activation='relu'),tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])model.summary()num_epochs = 30
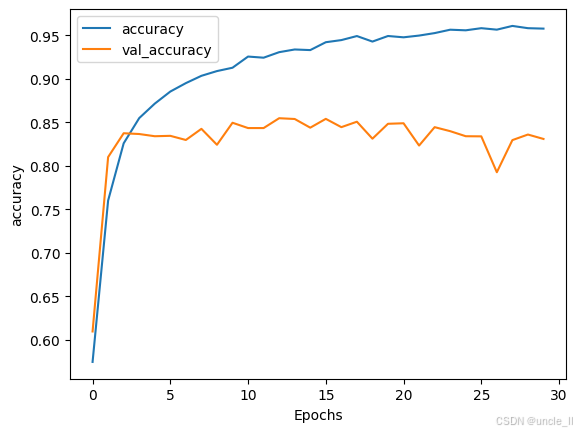
history = model.fit(training_padded, training_labels, epochs=num_epochs, validation_data=(testing_padded, testing_labels), verbose=2)import matplotlib.pyplot as pltdef plot_graphs(history, string):plt.plot(history.history[string])plt.plot(history.history['val_'+string])plt.xlabel("Epochs")plt.ylabel(string)plt.legend([string, 'val_'+string])plt.show()plot_graphs(history, "accuracy")
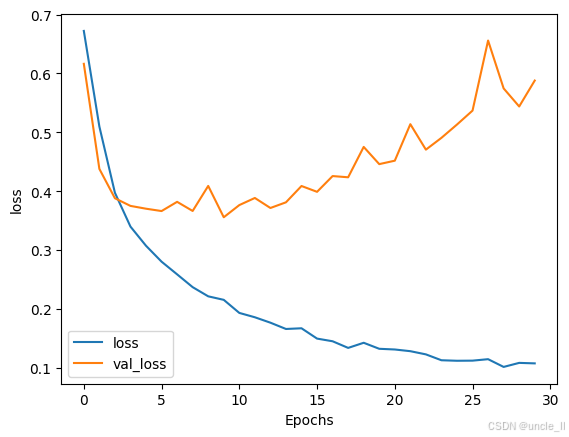
plot_graphs(history, "loss")reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])def decode_sentence(text):return ' '.join([reverse_word_index.get(i, '?') for i in text])print(decode_sentence(training_padded[0]))
print(training_sentences[2])
print(labels[2])e = model.layers[0]
weights = e.get_weights()[0]
print(weights.shape) # shape: (vocab_size, embedding_dim)import ioout_v = io.open('vecs.tsv', 'w', encoding='utf-8')
out_m = io.open('meta.tsv', 'w', encoding='utf-8')
for word_num in range(1, vocab_size):word = reverse_word_index[word_num]embeddings = weights[word_num]out_m.write(word + "\n")out_v.write('\t'.join([str(x) for x in embeddings]) + "\n")
out_v.close()
out_m.close()try:from google.colab import files
except ImportError:pass
else:files.download('vecs.tsv')files.download('meta.tsv')sentence = ["granny starting to fear spiders in the garden might be real", "game of thrones season finale showing this sunday night"]
sequences = tokenizer.texts_to_sequences(sentence)
padded = pad_sequences(sequences, maxlen=max_length, padding=padding_type, truncating=trunc_type)
print(model.predict(padded))

4. 用RNN进行机器学习
讽刺性标题分类器
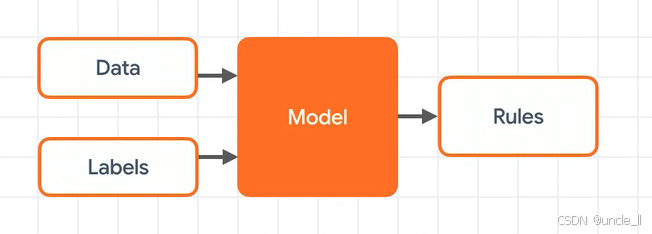
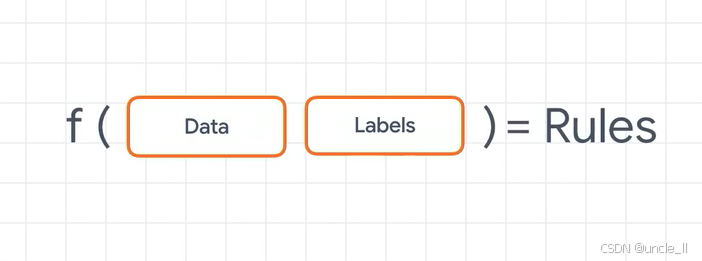
从数据输入到规则输出的建模过程:
- Data(数据):代表输入的原始数据,是模型训练的基础。
- Labels(标签):对应数据的标注信息,为模型提供监督信号(如分类任务中的类别标签)。
- Model(模型):对输入的“Data”和“Labels”进行学习与处理,通过算法挖掘数据与标签间的内在关联。
- Rules(规则):模型学习后输出的结果,即从数据中提炼出的规律或模式,可用于指导预测、决策等后续任务。
整体描述了一个典型的监督学习或数据建模流程:利用带标签的数据训练模型,模型从中归纳出规则,以应用于新数据的处理或分析。
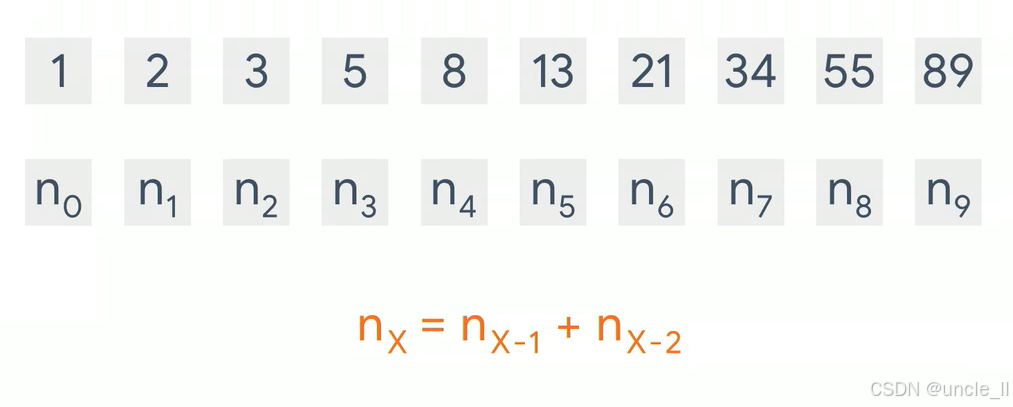
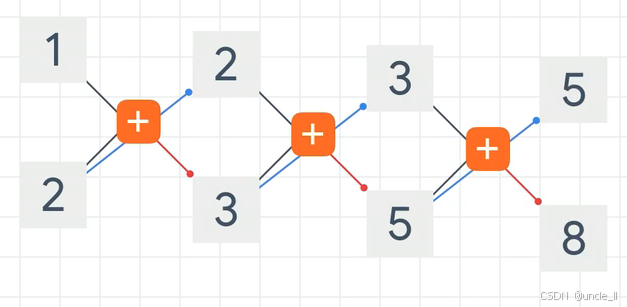
斐波拉契数列,循环神经网络RNN有点像这样
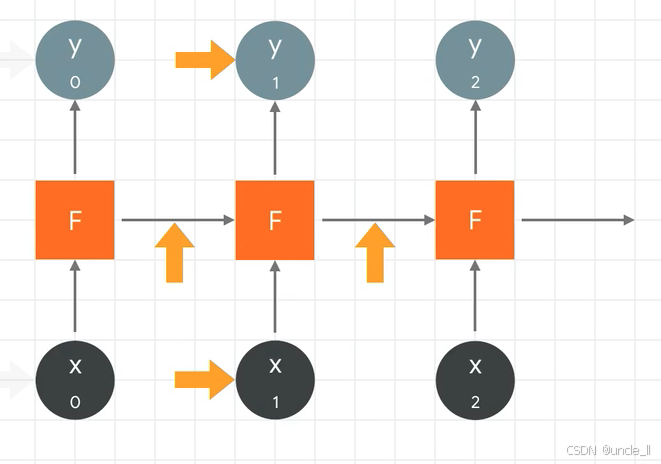
这张图展示了一个序列处理模型的结构,循环神经网络(RNN)的工作机制:
- 图中橙色方块“F”代表处理函数或模型单元,负责对输入进行转换。
- 黑色圆圈 ( x_0, x_1, x_2 ) 表示不同时刻或步骤的输入数据,灰色圆圈 ( y_0, y_1, y_2 ) 表示对应步骤的输出。
- 橙色箭头(如 ( x_0 \to x_1 )、( y_0 \to y_1 ))体现了输入或输出的更新与传递,表明模型在处理序列数据时,当前步骤的输入或输出会影响下一步的处理。
整体上,该图描绘了一个迭代处理过程:每个 ( F ) 单元利用当前输入 ( x ) 生成输出 ( y ),同时状态在步骤间传递,反映了对序列数据(如时间序列、文本序列等)的动态处理特性,体现了模型在序列上下文中的依赖关系与信息传递。

5. LSTM

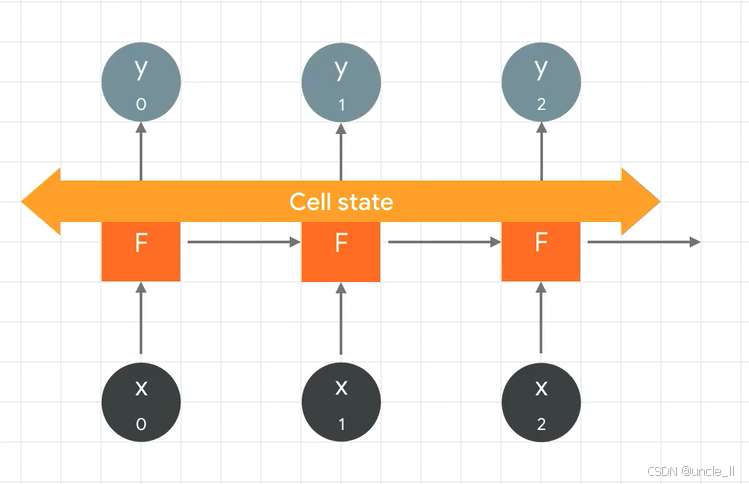
与循环神经网络(如LSTM)相关的结构,核心元素是 “Cell state(细胞状态)”,它是一条贯穿整个序列的“传送带”,用于传递长期记忆信息,解决传统循环神经网络中信息长期依赖的问题。以下是图中各部分的详细说明:
- Cell state(橙色长条):作为核心载体,在序列处理过程中传递信息,允许信息在较长的序列中保持,避免传统RNN的梯度消失问题,确保模型能捕捉远距离的依赖关系。
- F模块(橙色方块):代表处理单元(如LSTM中的门控单元),每个单元接收当前输入 X t X_t Xt( X 0 , X 1 , X 2 X_0, X_1, X_2 X0,X1,X2),结合细胞状态 Cell state \text{Cell state} Cell state 进行计算,生成当前输出 Y t Y_t Yt( Y 0 , Y 1 , Y 2 Y_0, Y_1, Y_2 Y0,Y1,Y2),并更新细胞状态,实现对信息的选择性遗忘、记忆和传递。
- 输入与输出: X 0 , X 1 , X 2 X_0, X_1, X_2 X0,X1,X2 是不同时刻的输入数据, Y 0 , Y 1 , Y 2 Y_0, Y_1, Y_2 Y0,Y1,Y2 是对应时刻的输出。细胞状态在序列处理中持续更新,确保信息的有效传递和利用。
整体而言,该图体现了通过细胞状态维持长期记忆,结合处理单元对序列数据进行动态处理的机制,是LSTM等改进型循环神经网络处理序列信息的关键架构。
实现
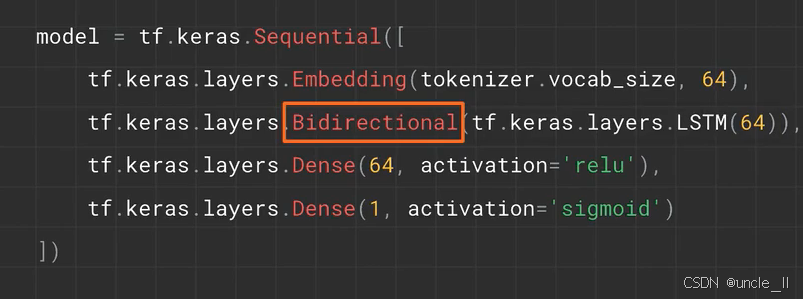
使用 TensorFlow 的 Keras API 构建神经网络模型的代码,各部分功能如下:
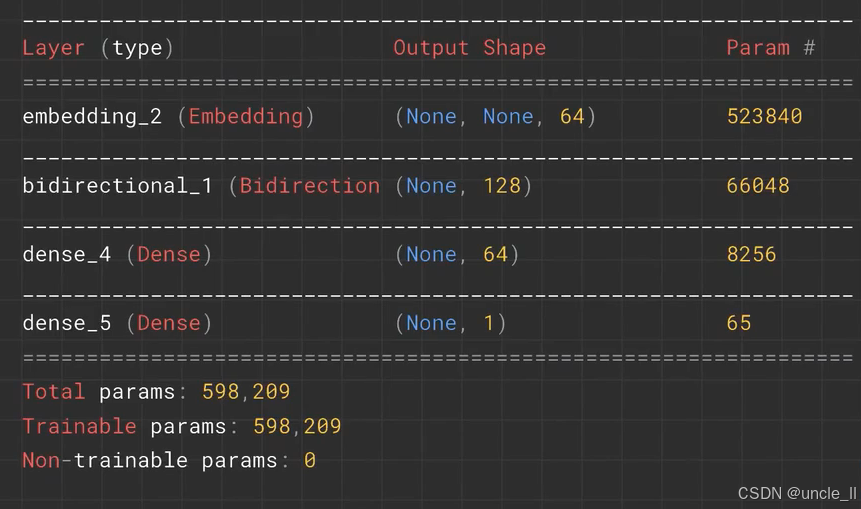
tf.keras.Sequential:创建一个顺序模型,按层的顺序依次堆叠。tf.keras.layers.Embedding(tokenizer.vocab_size, 64):- 嵌入层,将输入的整数序列(如文本分词后的索引)映射为低维稠密向量。
tokenizer.vocab_size表示词汇表大小(输入维度),64是嵌入维度。
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(64)):Bidirectional(橙色框标注):双向包装器,使内部的 LSTM 层同时从正向和反向处理输入序列,从而捕捉前后文信息,增强模型对序列上下文的理解能力。LSTM(64):长短期记忆网络层,含 64 个单元,处理序列数据并捕捉长期依赖关系。
tf.keras.layers.Dense(64, activation='relu'):- 全连接层,64 个单元,
relu激活函数,对数据进行非线性变换。
- 全连接层,64 个单元,
tf.keras.layers.Dense(1, activation='sigmoid'):- 输出层,1 个单元,
sigmoid激活函数,适用于二分类任务,输出概率值(0 到 1 之间)。
- 输出层,1 个单元,
该模型可用于处理序列数据(如文本分类),通过双向 LSTM 增强对上下文的理解,经全连接层处理后输出分类结果。

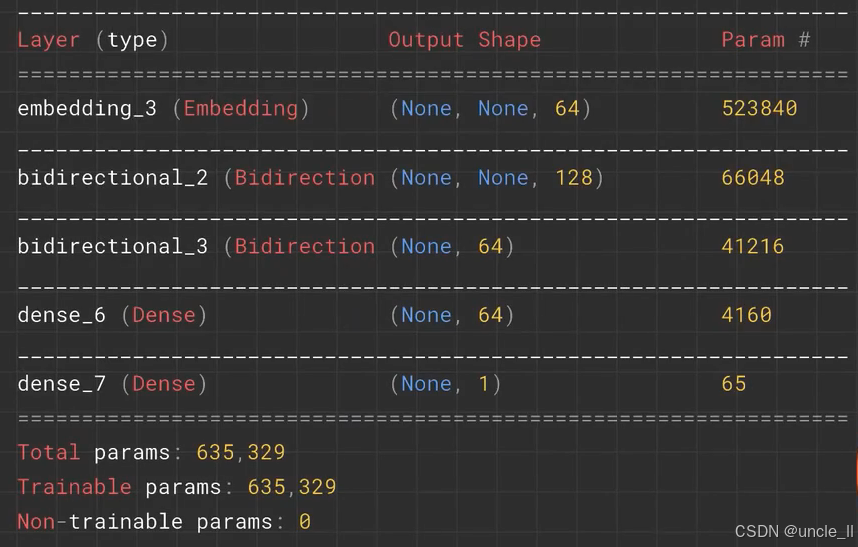
使用 TensorFlow 的 Keras API 构建神经网络模型的代码,核心在于理解 return_sequences=True 的作用:
tf.keras.layers.Embedding(tokenizer.vocab_size, 64):嵌入层,将输入的词汇索引映射为 64 维的稠密向量,tokenizer.vocab_size为词汇表大小。tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(64, return_sequences=True)):Bidirectional:双向包装器,使内部的 LSTM 同时从正向和反向处理序列,捕捉上下文信息。return_sequences=True(橙色框标注):让该 LSTM 层返回每个时间步的输出序列(而非仅最后一个时间步),以便后续的 LSTM 层能接收序列输入进行处理。
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(32)):第二个双向 LSTM 层,默认return_sequences=False,仅返回最后一个时间步的输出。- 后续的
Dense层:全连接层,分别进行非线性变换(relu激活)和二分类输出(sigmoid激活,输出 0 到 1 之间的概率)。
整体而言,return_sequences=True 确保第一层双向 LSTM 输出完整序列,为下一层 LSTM 提供序列输入,使模型能更好地处理序列数据的长期依赖关系。
6. 训练一个写诗AI
首先创建文本

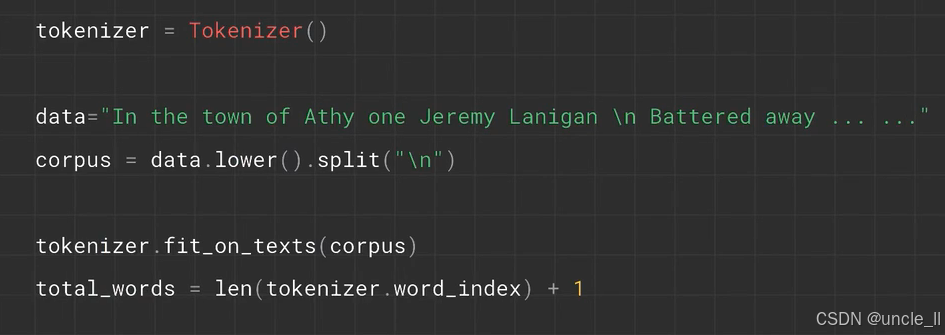
使用 Keras 中 Tokenizer 处理文本的 Python 代码,具体功能如下:
tokenizer = Tokenizer():创建一个Tokenizer实例,用于文本向量化(将文本转换为数字序列)。data="In the town of Athy one Jeremy Lanigan \n Battered away … …":定义包含文本内容的字符串data,其中\n表示换行。corpus = data.lower().split("\n"):data.lower():将文本转为小写,统一格式。.split("\n"):按换行符分割文本,将data拆分为字符串列表corpus,每一个元素为一行文本。
tokenizer.fit_on_texts(corpus):让Tokenizer在corpus上拟合,统计单词频率,构建词汇表(单词到整数索引的映射)。total_words = len(tokenizer.word_index) + 1:tokenizer.word_index是单词到索引的字典(索引从1开始)。len(tokenizer.word_index) + 1计算词汇表大小,+1是为了oov)。
这段代码为后续文本的数值化处理(如生成词向量、输入神经网络)做准备。
文本处理得到语料库,因为用了oov,总单词数量+1。
将文本数据转成训练数据
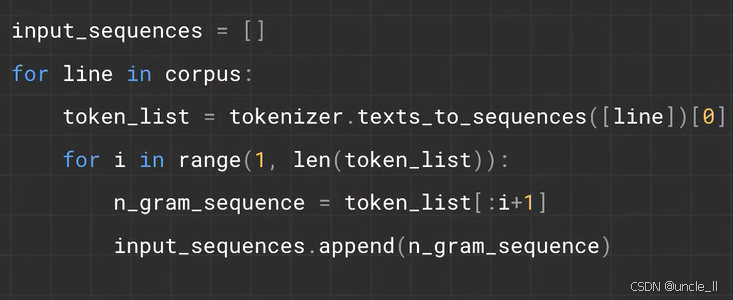
这段代码用于生成输入序列,具体步骤如下:
- 初始化列表:
input_sequences = []创建一个空列表,用于存储生成的输入序列。 - 遍历语料库:
for line in corpus:对语料库corpus中的每一行文本进行处理。 - 文本转序列:
token_list = tokenizer.texts_to_sequences([line])[0]将当前行文本转换为对应的数字序列(通过之前拟合的Tokenizer)。 - 生成 n - gram 序列:
- 内层循环
for i in range(1, len(token_list)):从索引1开始(即从 2 - gram 开始),到标记列表长度减一。 n_gram_sequence = token_list[:i+1]截取标记列表的前i+1个元素,形成一个 n - gram 序列(如i=1时为 2 - gram,i=2时为 3 - gram)。
- 内层循环
- 添加到列表:
input_sequences.append(n_gram_sequence)将每个生成的 n - gram 序列添加到input_sequences中。
最终,input_sequences 存储了语料库中每行文本生成的多种 n - gram 序列,为后续训练语言模型等任务提供数据,使模型能够学习单词间的顺序和关联关系。


模型是用来预测可能出现的下一个单词的,所以一条句子能构成很多条组合

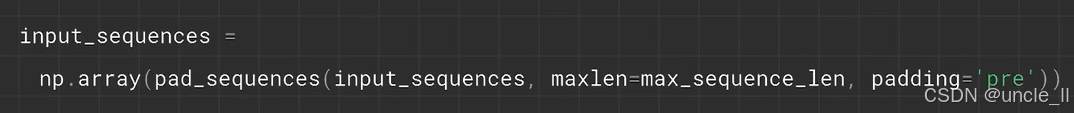
找到最大长度进行填充

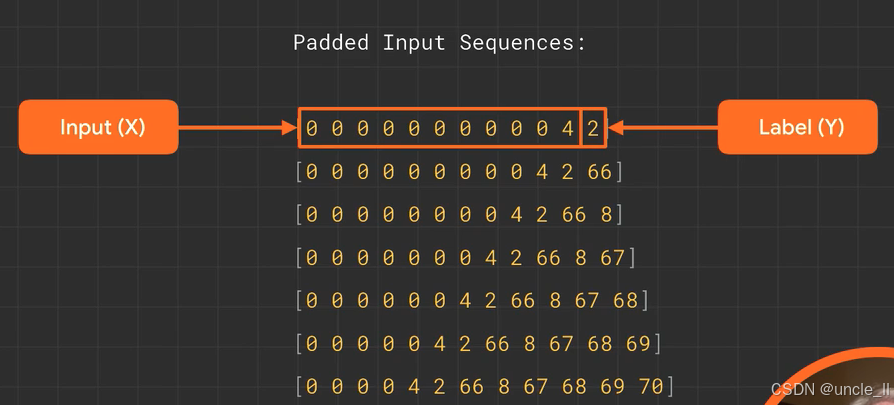
可以把前面的数据作为训练数据,最后一个数作为标签


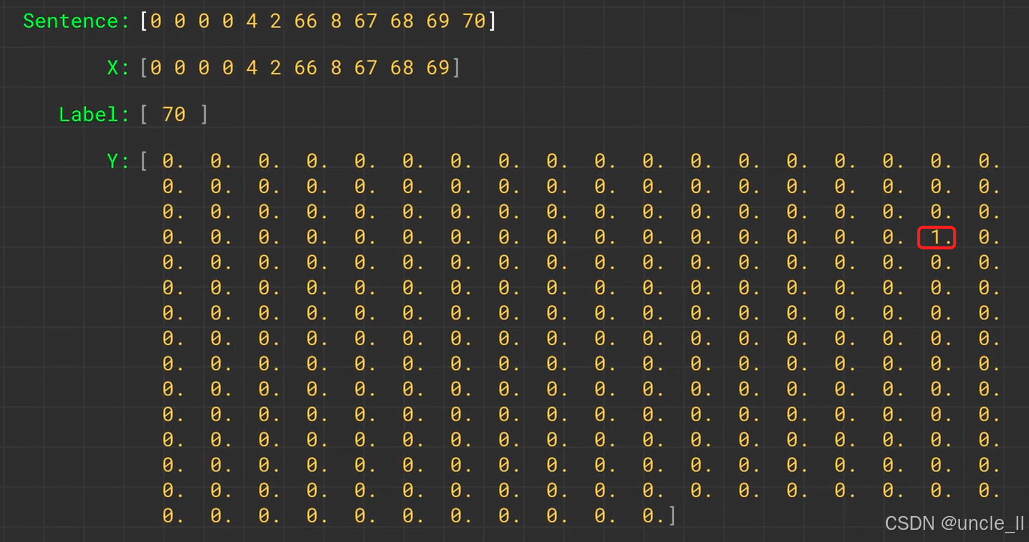
转成one-hot编码
开始构建模型进行训练
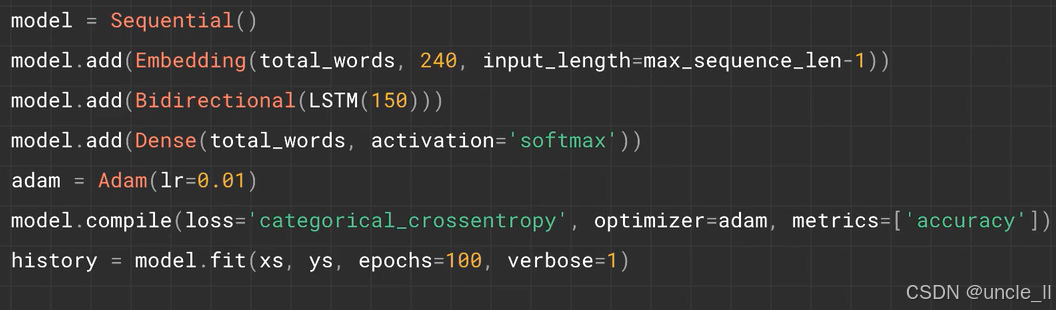
使用 Keras 构建并训练一个神经网络模型,具体步骤如下:
-
创建顺序模型:
model = Sequential()
初始化一个顺序模型,用于按层顺序堆叠构建网络。 -
添加嵌入层:
model.add(Embedding(total_words, 240, input_length=max_sequence_len-1))total_words:词汇表大小,将输入的整数索引映射到嵌入空间。240:嵌入维度,每个单词表示为 240 维向量。input_length=max_sequence_len-1:输入序列长度,减 1 可能用于预测下一个词(如输入n-1个词,预测第n个词)。
-
添加双向 LSTM 层:
model.add(Bidirectional(LSTM(150)))Bidirectional:双向处理序列,捕捉前后文信息。LSTM(150):150 个 LSTM 单元,处理序列数据的长期依赖。
-
添加全连接输出层:
model.add(Dense(total_words, activation='softmax'))total_words:输出维度与词汇表大小一致,每个神经元对应一个单词的预测概率。softmax激活函数:将输出转换为概率分布,用于多分类(预测下一个词)。
-
配置优化器:
adam = Adam(lr=0.01)
创建 Adam 优化器,学习率设置为0.01。 -
编译模型:
model.compile(loss='categorical_crossentropy', optimizer=adam, metrics=['accuracy'])loss='categorical_crossentropy':多分类交叉熵损失,适用于标签为独热编码的情况。optimizer=adam:使用 Adam 优化器。metrics=['accuracy']:训练过程中监控准确率。
-
训练模型:
history = model.fit(xs, ys, epochs=100, verbose=1)xs:输入数据(如词序列)。ys:标签数据(独热编码的下一个词)。epochs=100:训练 100 个轮次。verbose=1:显示训练进度条。
该模型常用于语言建模任务,通过学习词序列预测下一个词,双向 LSTM 和嵌入层帮助捕捉上下文语义信息。
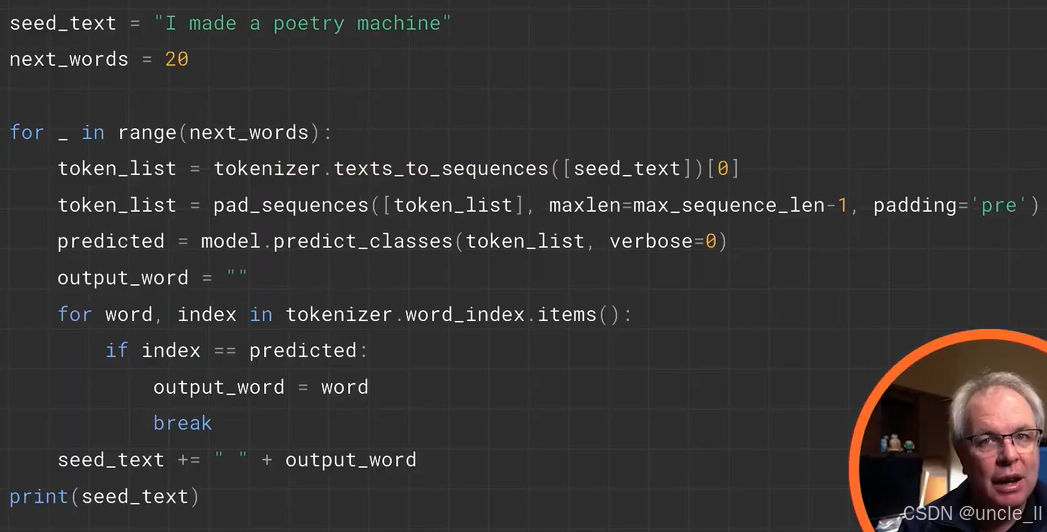
基于已训练模型的文本生成功能,具体步骤如下:
-
初始化种子文本与生成词数:
seed_text = "I made a poetry machine":设定初始文本,作为生成的起点。next_words = 20:指定后续生成的单词数量为 20 个。
-
循环生成单词:
for _ in range(next_words)::循环 20 次,每次生成一个单词。token_list = tokenizer.texts_to_sequences([seed_text])[0]:将种子文本转换为数字序列(利用已拟合的tokenizer)。token_list = pad_sequences([token_list], maxlen=max_sequence_len-1, padding='pre'):对序列进行填充,确保长度符合模型输入要求(max_sequence_len-1),采用前置填充(padding='pre')。predicted = model.predict_classes(token_list, verbose=0):使用模型预测下一个单词的索引(predict_classes返回类别索引)。- 遍历
tokenizer.word_index.items(),找到与predicted索引匹配的单词,赋值给output_word。 seed_text += " " + output_word:将生成的单词添加到种子文本后,更新seed_text。
-
输出结果:循环结束后,最终的
seed_text包含初始文本和生成的 20 个单词,并通过print(seed_text)输出。
该代码通过模型预测和循环迭代,逐步生成连贯的文本,适用于基于语言模型的文本续写任务。
