FinanceRAG获奖方案解读:ACM-ICAIF ’24的FinanceRAG挑战赛
ACM-ICAIF '24 FinanceRAG Challenge提供一套整合的文本和表格财务数据集。这些数据集旨在测试系统检索和推理财务数据的能力。参与者将受益于 Github 上的基线示例和官方提交代码,其位于FinanceRAG,以及在 huggingface 上的简化的数据集访问,其位于Linq-AI-Research/FinanceRAG。
核心问题
- 金融领域的复杂性:金融文档包含大量专业术语、缩写和数值表格,传统RAG系统难以高效处理。
- 长上下文问题:金融文档通常篇幅较长,直接输入大语言模型会导致性能下降。
- 检索精度:如何从大规模语料中准确提取与查询最相关的文档。
亚军方案
通过优化查询扩展、语料优化和长上下文管理等技术打造的针对金融领域的高性能检索增强生成(RAG)系统,在ACM-ICAIF ’24的FinanceRAG挑战赛中取得了第二名的成绩。
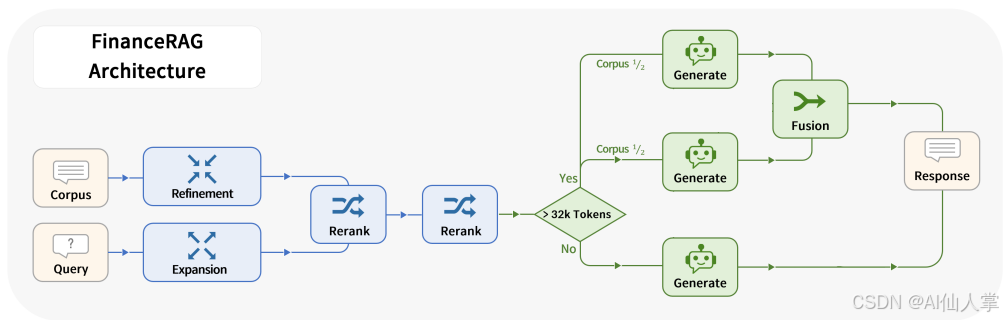
方法与技术亮点
围绕RAG系统的三个阶段展开:预检索(Pre-Retrieval)、检索(Retrieval)和生成(Generation)。以下是对每个阶段的详细分析。
1. 预检索(Pre-Retrieval)
预检索阶段的目标是对查询和语料进行优化,以提高后续检索的效率和准确性。
-
查询扩展(Query Expansion):
- 问题:金融领域的查询往往包含缩写、模糊含义或需要多步推理。
- 方法:通过OpenAI/GPT-4o-mini对查询进行改写、关键词提取和假设文档生成。
- 延展:查询扩展技术在自然语言处理中已有广泛应用,但论文通过结合金融领域的特定需求(如缩写解析和数值推理),进一步提升了查询的语义表达能力。
- 实验结果:通过对比不同查询扩展方法的NDCG@10指标,发现结合原始查询和关键词提取的方法效果最佳。
-
语料优化(Corpus Optimization):
- 问题:金融语料规模庞大,直接检索效率低下。
- 方法:对语料进行摘要提取和表格数据分离。摘要提取使用OpenAI/GPT-4o生成,表格数据分离针对MultiHiertt数据集(包含大量表格信息)。
- 延展:语料优化技术可以进一步结合领域知识,例如针对财务报表中的数值表格,可以提取关键指标(如收入、利润)并生成结构化的中间表示。
2. 检索(Retrieval)
检索阶段的核心是通过多级重排序器(Multi-Reranker)提高检索精度。
- 重排序器(Reranker):
- 问题:传统基于嵌入相似度的检索方法难以捕捉复杂的语义关系。
- 方法:使用多级重排序器模型,首先通过轻量级模型提取前200条相关语料,再通过更精确的模型进一步筛选出前10条。
- 延展:重排序器模型的选择可以结合任务需求,例如金融领域需要支持多语言和数值推理的模型。论文中使用的模型包括jina-reranker-v2-base-multilingual和gte-multilingual-reranker-base。
- 实验结果:通过对比不同重排序器模型的性能,最终在公共排行榜上达到了NDCG@10 0.63996的分数。
3. 生成(Generation)
生成阶段的目标是在长上下文输入下生成准确、简洁的回答。
-
长上下文管理(Long Context Management):
- 问题:大语言模型在处理超过32k tokens的上下文时性能显著下降。
- 方法:将输入语料分为两部分,分别处理后融合结果。例如,将前10条语料和后10条语料分别输入模型,最后融合生成最终答案。
- 延展:长上下文管理技术可以进一步结合注意力机制优化,例如通过稀疏注意力机制减少计算复杂度。
- 实验结果:通过限制上下文大小并优化答案格式,生成的回答在准确性和效率上均优于直接输入长上下文的方法。
-
答案格式优化(Answer Format Optimization):
- 问题:金融专家通常需要具体的数值答案,而非冗长的解释。
- 方法:通过提示工程(Prompt Engineering)引导模型输出关键信息。
- 延展:提示工程可以进一步结合领域知识,例如设计特定的提示模板,要求模型直接输出数值结果或简要分析。
优点与创新
- 预检索消融分析:通过全面的消融研究优化了预检索技术,增强了整体检索效果。
- 准确的检索算法:开发了基于多个重排模型的准确检索算法,提高了检索语料库的相关性。
- 高效的长上下文管理:设计了一种有效管理长上下文大小的方法,显著提升了响应的质量和准确性。
- 高性能的RAG系统:开发了一个高性能的、特定于金融领域的检索增强生成(RAG)系统,并在ACM-ICAIF’24 FinanceRAG竞赛中获得了第二名。
- 多种重排模型的组合:使用了多种重排模型,并通过实验确定了最适合每个数据集的重排模型。
- 上下文大小管理策略:针对LLM上下文大小增加带来的性能下降问题,提出了有效的上下文大小管理策略。
- 查询扩展技术的应用:采用了多种查询扩展技术,如释义、关键词提取和假设文档的创建,以提高检索过程的有效性。
- 表格提取和摘要的使用:在处理大规模语料库时,使用了摘要和表格提取技术,特别是针对包含大量表格数据的MultiHiertt数据集。
仓库结构
FinanceRAG/
├── financerag/ # 主模块目录
│ ├── common/ # 通用工具函数
│ ├── generate/ # 响应生成代码
│ ├── rerank/ # 检索文档重排序代码
│ └── retrieval/ # 文档检索代码
├── dataset/ # 数据集存储文件夹
├── paper/ # 论文文件夹
├── pre_retrieval.py # 预检索脚本
├── prepare_dataset.py # 数据集下载和准备脚本
├── prompt.json # 预检索提示配置
├── requirements.txt # Python 依赖项
├── rerank.py # 重排序脚本
└── run.sh # 运行完整流程的脚本
代码片段功能
rerank.py:定义了重排序脚本的命令行参数,包括任务选择、模型选择、前 K 个结果重排序、批量大小等。FinQATask.py:定义了FinQA任务的元数据,包括任务名称、描述、数据集路径、任务类型等。financerag/generate/openai.py:实现了一个与 OpenAI API 交互的类OpenAIGenerator,用于生成响应,支持并行处理。pre_retrieval.py:包含加载提示模板、扩展查询和压缩语料库等功能。financerag/retrieval/:包含多种检索方法的实现,如DenseRetrieval(基于编码器的密集检索)和BM25Retriever(基于词法模型的检索)。financerag/common/loader.py:实现了数据集加载的功能,包括加载语料库和查询数据集。
环境要求
- Python:3.10+
- CUDA:12.2+
- API 密钥:需要 OpenAI API 密钥和 Kaggle API 密钥及用户名。
- Python 包:具体依赖项见
requirements.txt。
快速开始
- 克隆仓库:
git clone https://github.com/cv-lee/FinanceRAG.git
cd FinanceRAG
- 创建
.env文件:
touch .env
- 写入
.env文件:
# .env
OPENAI_API_KEY=YOUR_OPENAI_API_KEY
KAGGLE_USERNAME=YOUR_KAGGLE_USERNAME
KAGGLE_KEY=YOUR_KAGGLE_KEY
- 执行完整流程:
bash run.sh
故障排除
- Flash Attention 安装问题:可以在
run.sh脚本中取消注释pip uninstall -y transformer - engine,若问题仍然存在,可参考官方 [Flash Attention GitHub 仓库](https://github.com/Dao - AILab/flash - attention)。 - 检索速度慢:可以在
run.sh中使用--batch_size参数调整批量大小。
论文
可以在 Arxiv 上查看完整论文。