CS5346 - Visualization Design Process
文章目录
- Stage 1: Preparatory Stage(准备阶段)
- Stage 2: Working with Data(数据处理阶段)
- 两种表格数据集(Two types of Tabulated Datasets)
- Normalized Tabulated Datasets
- Cross-tabulated Data(交叉跨表数据 / 聚合数据)
- 两种数据类型(定量数据 - Quantitative 和定性数据 - Qualitative)
- Qualitative (定性数据)
- Quantitative (定量数据)
- 其他数据类型 (Other types of Data)
- Textual (文本型)
- Temporal(时间型)
- Discrete (离散型)
- Continuous (连续型)
- Working with Data 的四个阶段
- Acquisition(获取)
- Examination(检查)
- Transformation(转换)
- Clean(清洗)
- Create or Convert(创造或转换)
- Consolidate(整合)
- Exploration(探索)
- Deductive(演绎式探索)
- Inductive(归纳式探索)
- Knowledge State in Four Quadrants
- Known knowns(我们知道我们知道的)
- Known unknowns(我们知道自己不知道的)
- Unknown knowns(我们不知道我们知道的)
- Unknown unknowns(我们不知道我们不知道的)
- Summary of Stage 2
- Stage 3: Preparatory stage (筹备阶段)
- Angle(角度)
- Framing(取舍)
- Focus(聚焦)
- Summarization of Stage 3
- Stage 4: Visual manifestation of preparatory work (准备工作的视觉体现)
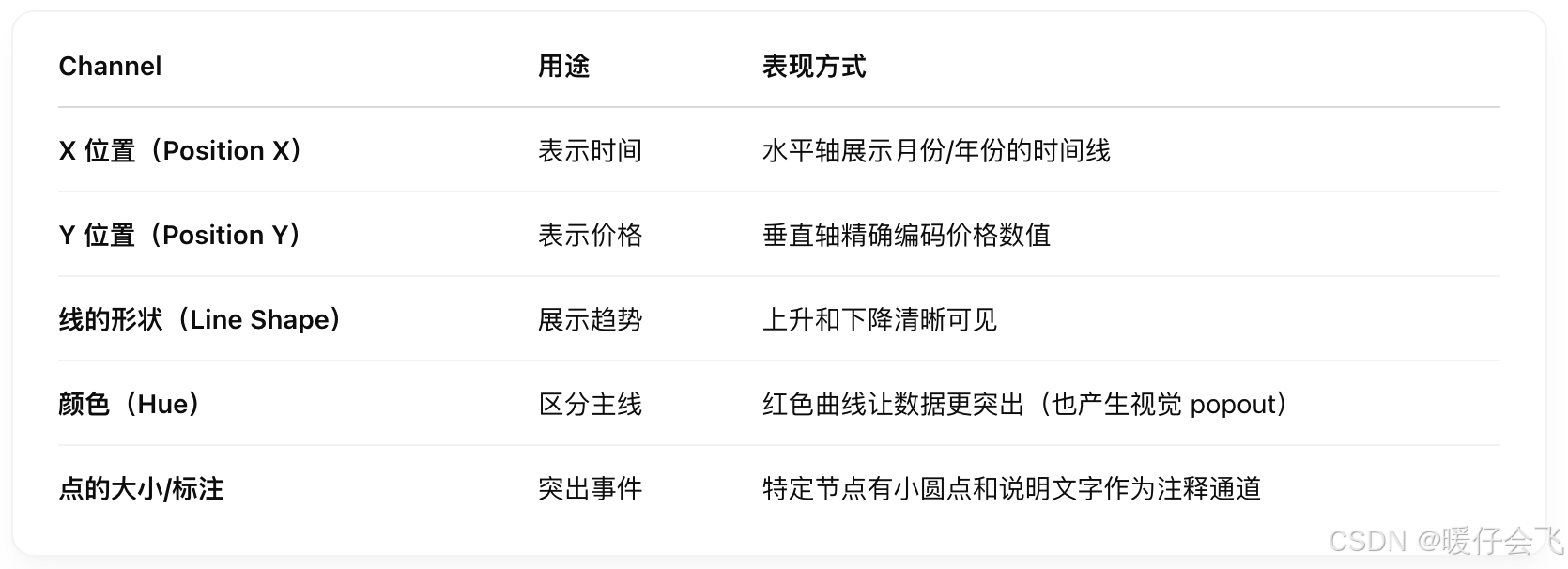
- Marks and Channels (标记和通道)
- Examples
- Channels Ranking (通道排序)
- Selective(选择性)
- Associative(关联性)
- Quantitative(定量性)
- Order(顺序性)
- Channles Ranking Summary
- Color Knowledge
- Visual Encoding(视觉编码)
- Visual Encoding Design Principles
- Principle of Expressiveness (表现力原则)
- Principle of Effectiveness(有效性原则)
- Channel Effectiveness (通道有效性)
- Accuracy(准确性)
- Discriminability(可区分性)
- Separability(可分离性)
- Visual Popout(视觉突出)
- Other factors affects accuracy(其他影响 accuracy 的因素)
Stage 1: Preparatory Stage(准备阶段)
关键词:动机、好奇心、目标受众
你需要问自己:
“我为什么做这个项目?”(动机)
“我想搞清楚什么?”(核心好奇心)
“谁会用我的可视化,目的是什么?”(用户需求)
✅ 举例:
你热爱电影,对某些演员的“昙花一现”很感兴趣。于是你想探索“演员的走红与沉寂之间有没有规律?”
又比如,如果你是一个电影公司选角导演,你的任务是找一位30-45岁、女演员、从未出演过科幻片、片酬低于$200万的 rising star,那你就会基于职业需求来筛选数据。
- 这个阶段像是在制定一个“研究问题”,并弄清楚“谁在乎这个问题”。




Stage 2: Working with Data(数据处理阶段)
关键词:获取、理解、清洗、转换、探索
两种表格数据集(Two types of Tabulated Datasets)
- 标准格式的表格数据(normalized)
- 聚合的表格数据集(cross-tabulated)
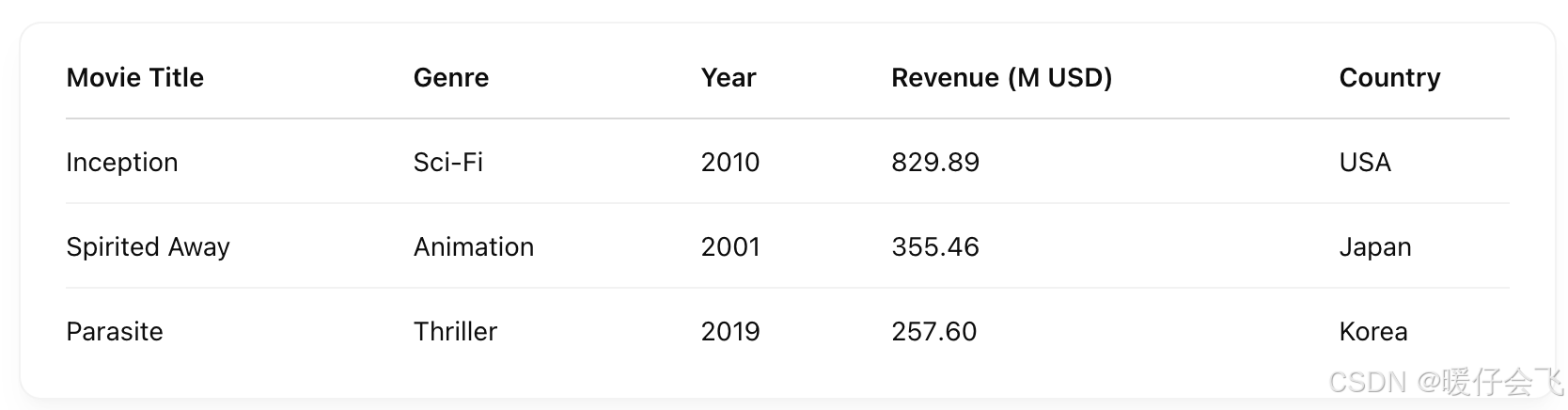
Normalized Tabulated Datasets
- 特点:一行(row) 是一个记录(实体),每一列(column) 是属性或变量。
-
每一行代表一个电影。
-
每一列是某种属性(变量)。
-
数据适合做过滤、分组、计算等操作。
-
Cross-tabulated Data(交叉跨表数据 / 聚合数据)
- 特点:表格已经 聚合 过,行和列通常是 类别组合,表中内容是统计值。
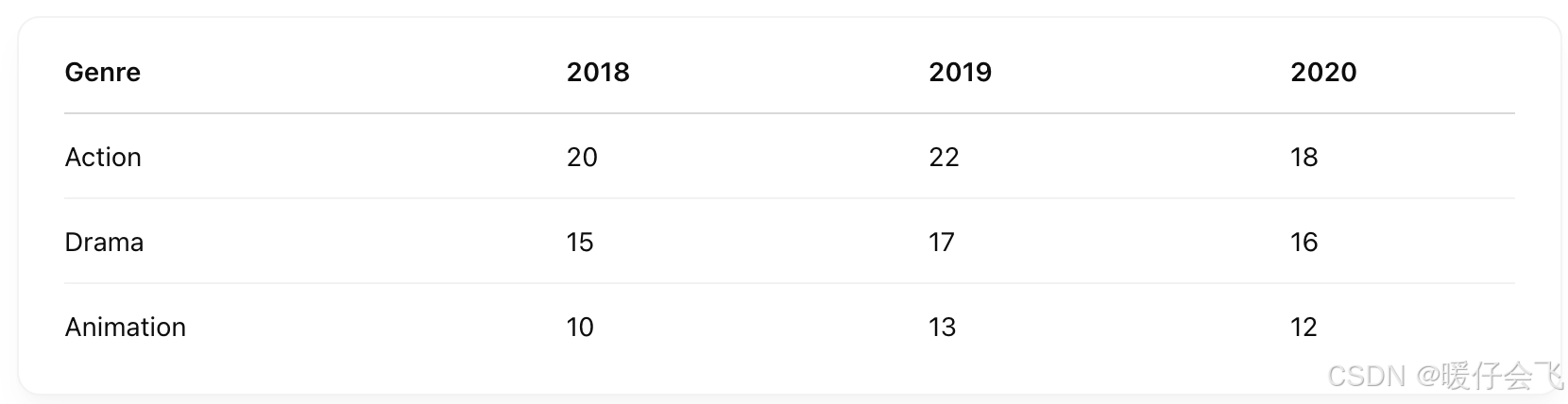
- 行:电影类型
- 列:年份
- 单元格:该类型在该年份上映的电影数量(不是原始数据,而是汇总后的统计结果)
如何快速区分:

两种数据类型(定量数据 - Quantitative 和定性数据 - Qualitative)
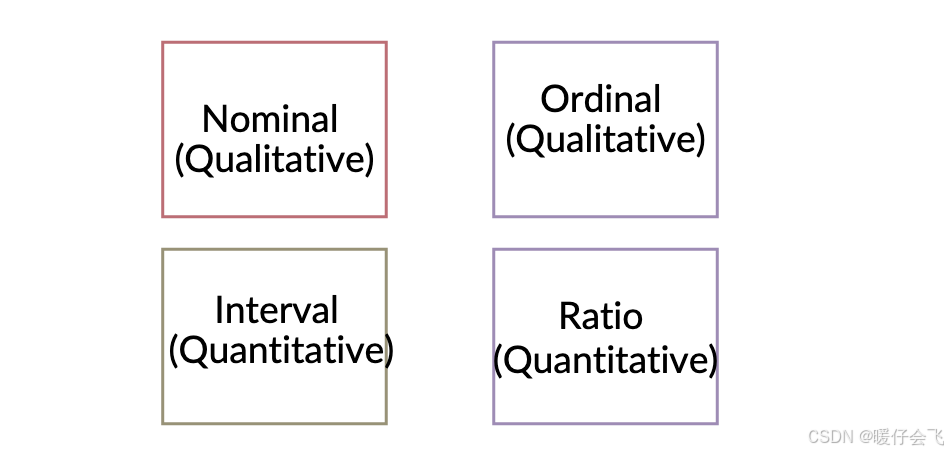
这两大类数据类型包含 4 种子类型:
Qualitative (定性数据)
-
Nominal:只表示不同 类别,比如「男/女」、「苹果/香蕉」,不能比较大小。
-
Ordinal:表示 等级,有顺序,但没法做加减法,比如「喜欢程度:喜欢/一般/不喜欢」。酒店类型 1 - 5 星,但是 1星 + 2星的酒店不等于 3 星的酒店
Quantitative (定量数据)
-
Interval:无绝对零点,并且不可比较倍数。 可以比较两个温度从 20℃ 到 30℃ 是 10℃差,但不能说“30℃ 是 20℃ 的 1.5 倍”,因为没有 “零度是起点” 的概念。

-
Ratio:年龄、收入就有“0”这个起点,可以说“60岁是30岁的2倍”。


其他数据类型 (Other types of Data)
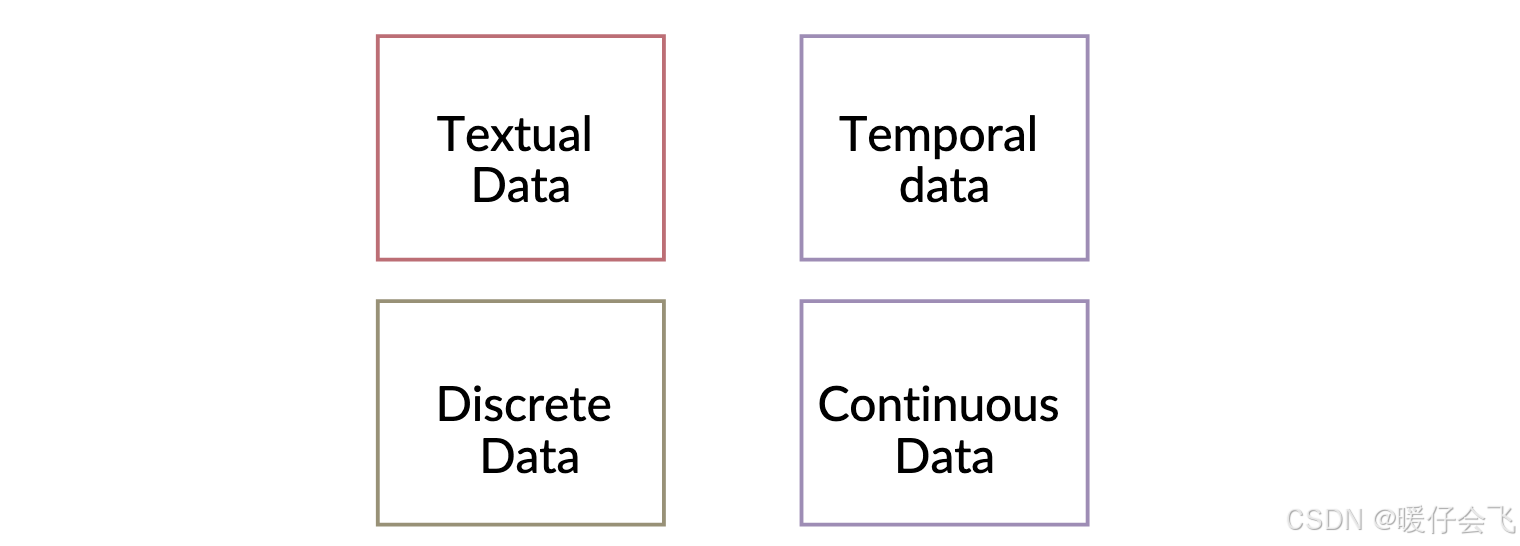
Textual (文本型)

-
✅ 可用于情感分析、关键词提取、词频统计
-
✅ 可从中派生出“Noninal”(e.g. 情感类型)或“Quantitative Variable”(e.g. 字数、字符数、情感分数等)
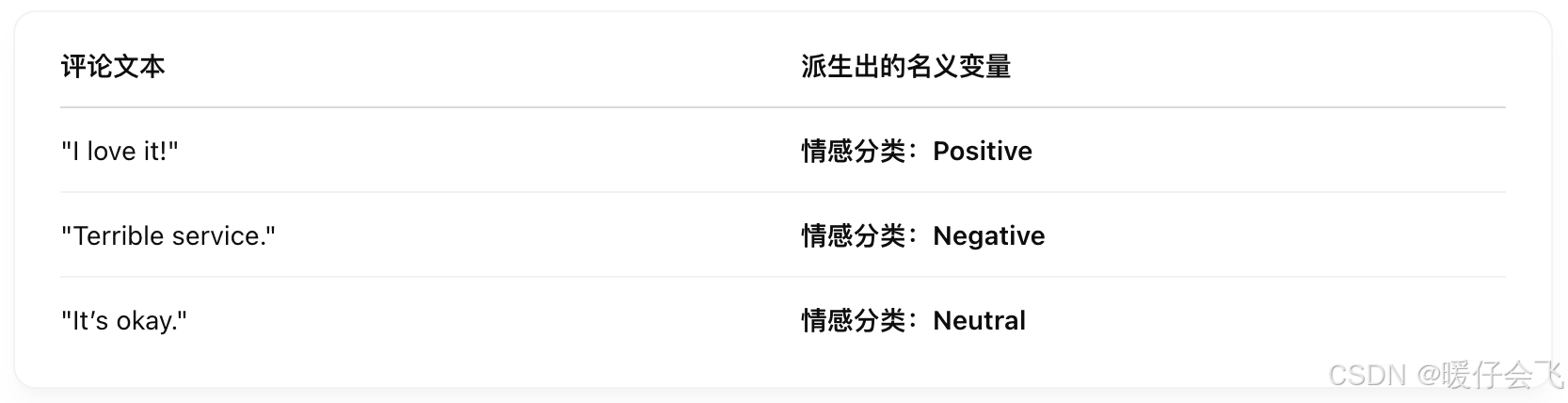

-
📊 可视化:词云、关键词柱状图、文本注解图
Temporal(时间型)
时间型数据指的是与时间点、时间段或时间顺序有关的变量。
它可以是单独一个时间戳,也可以是范围、周期,甚至文字表达的时间概念。
Temporal 类型可以被转换/派生为以下变量类型:
- norminal:
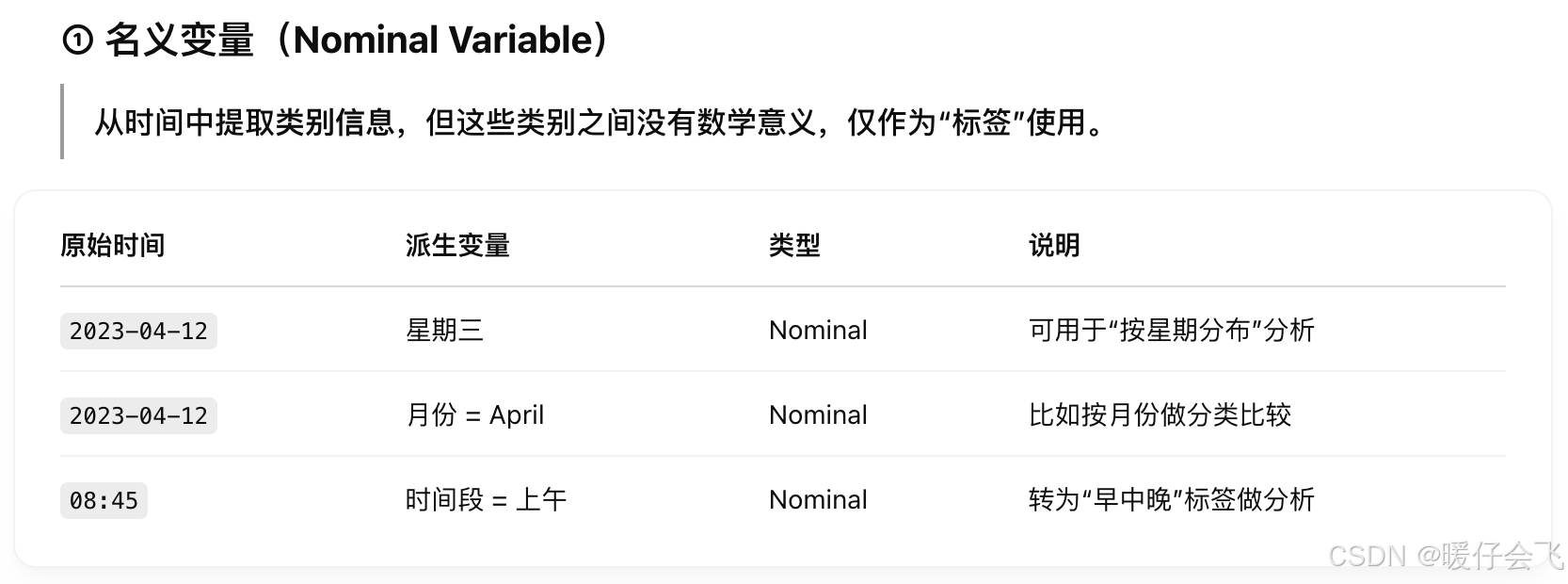
- ordinal:

- quantitative:

Discrete (离散型)
- 只能取有限或可数的数值,通常是整数,没有中间状态。


Continuous (连续型)
- 可以取无限多个值,理论上可以精确到任意小数点。


Working with Data 的四个阶段

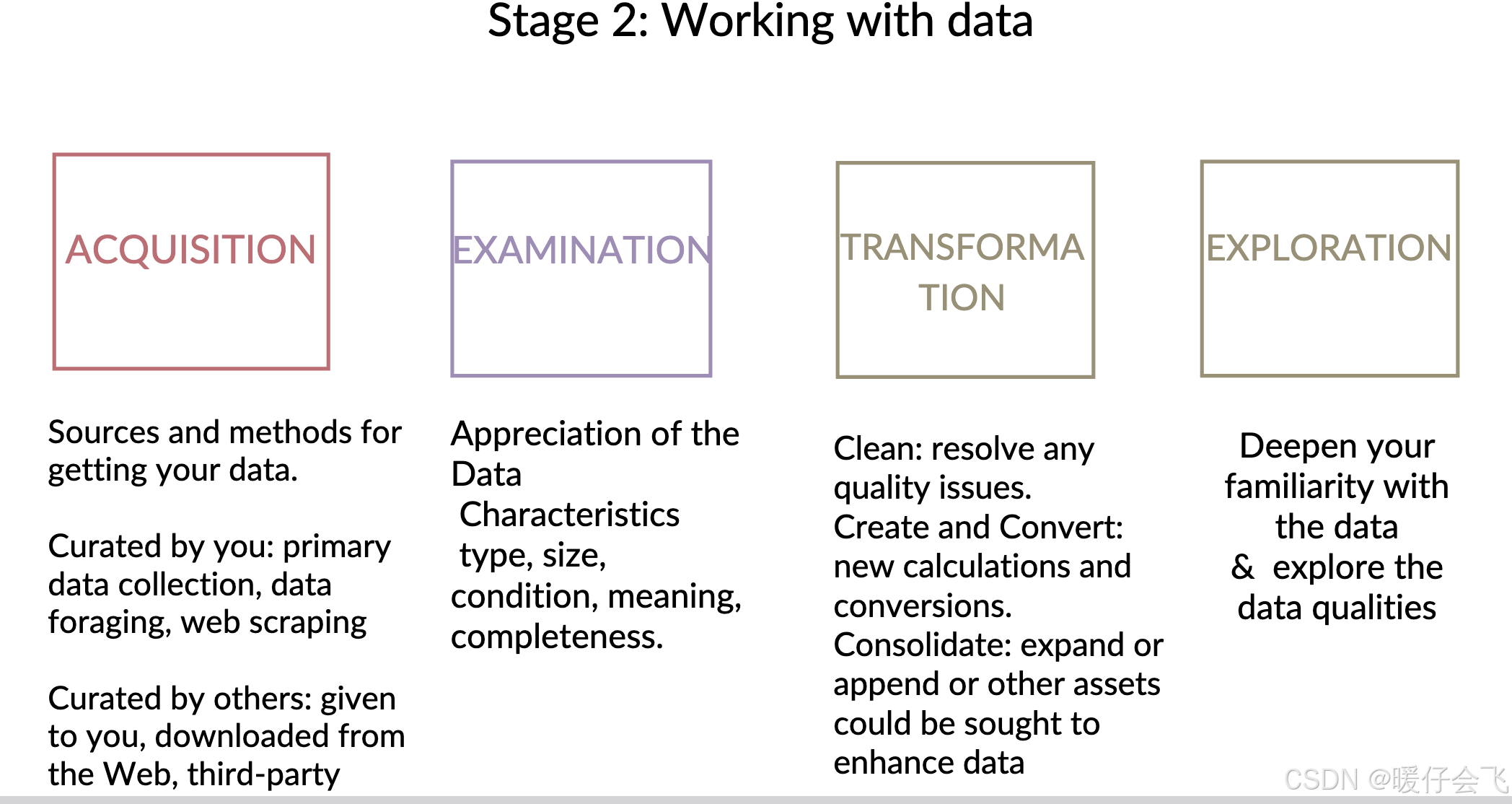
Acquisition(获取)
📌 核心问题:
我需要哪些数据?
数据从哪里来?如何获取?
是自己收集,还是别人提供?
📌 数据来源包括:
自己测量(primary collection)
手动整理(data foraging)——例如从 PDF 抽取历史资料
网络爬虫(web scraping)——自动提取网页内容
开放数据库/API(由他人整理好的)
直接由客户/公司/团队提供
Examination(检查)
👉 获取数据后,下一步是“了解这份数据到底长什么样、好不好用”。
📌 关键任务:
查看数据的 字段、类型、单位、格式
检查数据是否有:
缺失值(missing values)
异常值/错误值(如“性别”列中出现年龄)
格式不统一(比如日期格式混乱)
重复值或无效值
📌 可查看内容:
每列数据的类型(Nominal, Ordinal, Ratio...)
值的范围、分布、最大最小值、平均值
文本字段的长度、是否有乱码
是否有不一致的单位(e.g. cm vs inches)
🧠 举例:
检查“收入”列有没有负数
检查“出生日期”有没有空白或格式混乱(如 dd/mm/yy vs mm/dd/yy)

Transformation(转换)

👉 有了数据、也检查完了问题,现在就要“清洗和改造”数据,让它更适合分析与可视化。
📌 包含三类操作:
Clean(清洗)
修复格式、纠正拼写、统一值(e.g. 男/Male → Male)
删除重复值或无用字段
清除无效字符或空格
Create or Convert(创造或转换)
衍生新字段(如“出生年份” → “年龄段”)
分解字段(如“2023-04-12” → 年、月、日)
创建计算值(如 “收入/人口” → 人均收入)
Consolidate(整合)
合并来自多个数据源的数据
添加辅助字段(如添加“国家所属洲”列)
把文本变成分类变量或关键词
🧠 举例:
把“Male”/“Female” → 1/0
把“Release Date” 拆成 “Year” 和 “Month”
从“文本评论”中提取关键词、字数、情绪分数等
Exploration(探索)
👉 这一阶段的任务是“理解数据能告诉你什么”,是为可视化和分析做铺垫。
📌 两种方式:
Deductive(演绎式探索)
你已经有一个明确的好奇心/假设
→ 检查数据是否支持你的想法
Inductive(归纳式探索)
你没有明确方向,只是观察数据,看有没有模式
→ 比如:“点开看看这个变量和那个变量有没有关系?”
📊 常见探索方式:
可视化初步分布(直方图、散点图)
算基本统计量(均值、中位数、标准差)
查看缺口、分布偏态、聚类情况
🧠 举例:
看电影票房分布,发现大多数票房集中在“100-300万”之间
看马拉松成绩分布,发现很多人在3h、4h整点冲线(目标性行为)
Knowledge State in Four Quadrants
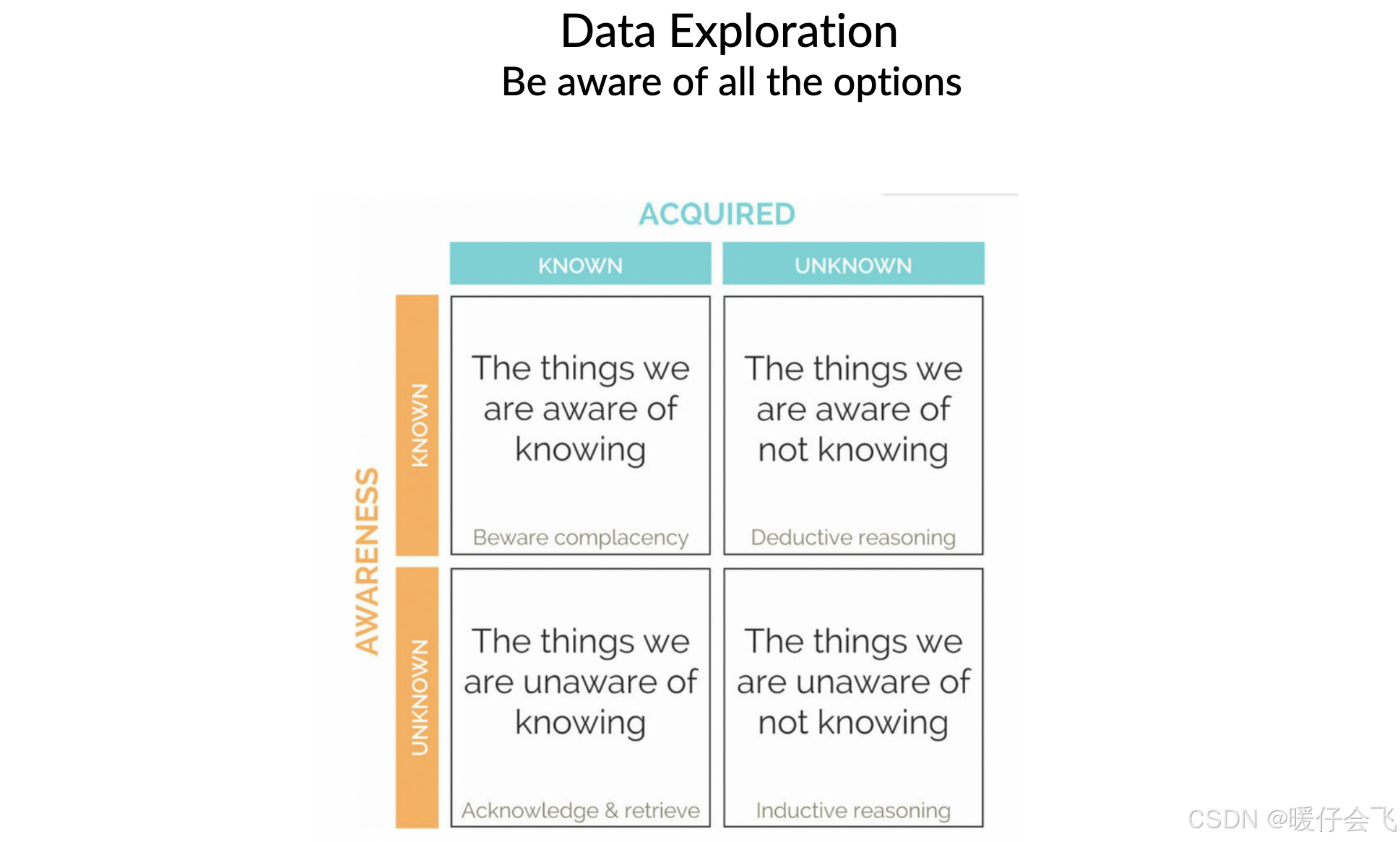
这个模型使用了 两个维度 来划分你的知识状态:
横轴:Acquired(是否已获取)
Known:我们已经拥有的信息
Unknown:我们还没有的信息
纵轴:Awareness(是否意识到)
Known:我们意识到了
Unknown:我们尚未意识到
于是形成了四种情形:
Known knowns(我们知道我们知道的)
📍 左上角
你清楚地知道自己掌握了什么
属于“已知的知识 + 有意识”
✅ 好处:基础牢固
⚠️ 风险:容易自满(Beware complacency)
📌 举例:
你知道某个字段是“收入”,你也知道它是 ratio 数据,这是你的专业知识。
Known unknowns(我们知道自己不知道的)
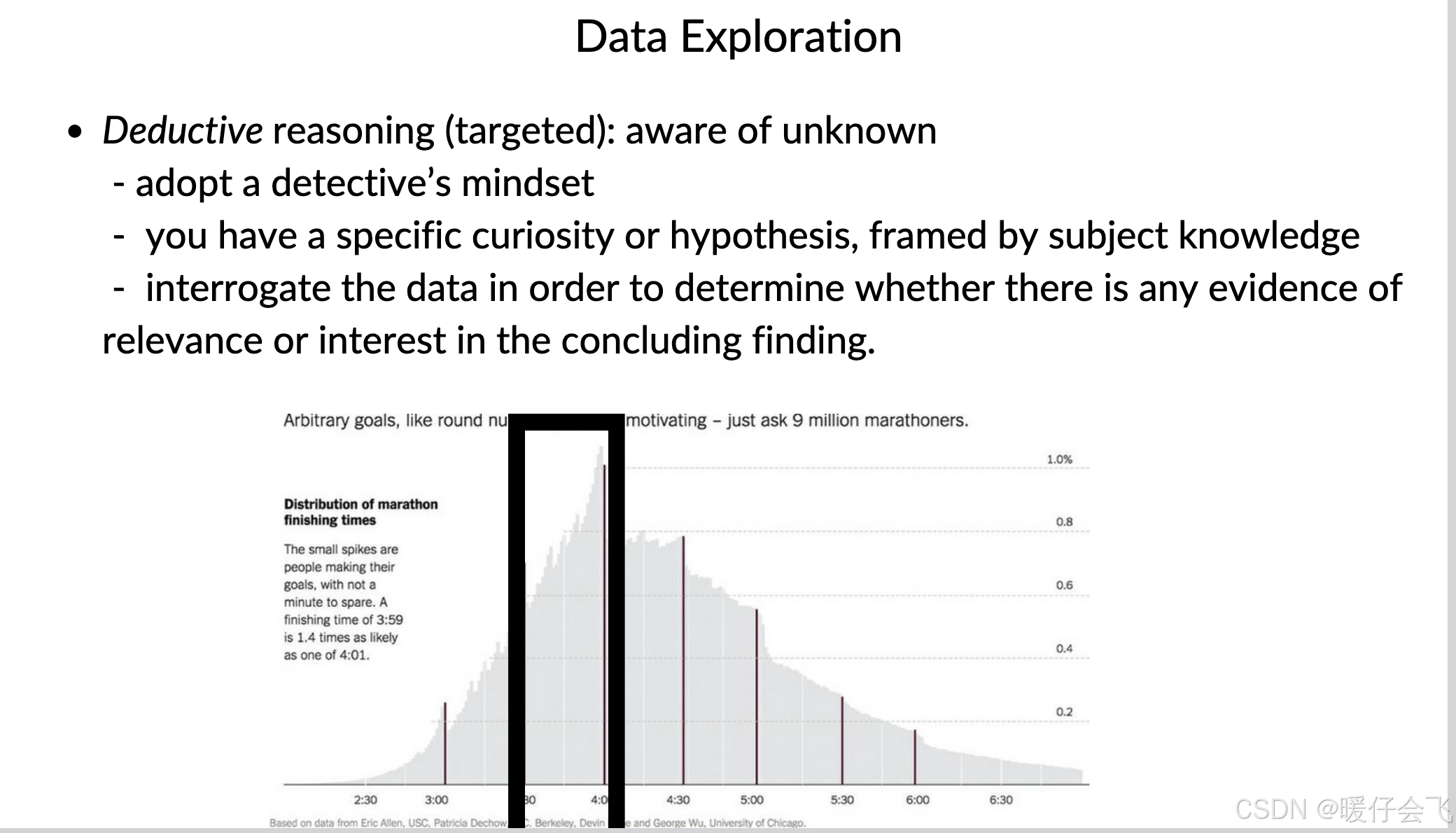
📍 右下角
你意识到自己缺少某些知识
例如:知道“这张图看起来有模式,但不知道为什么”
- 用 Deductive Reasoning(演绎推理) 去验证猜想
📌 举例:
你知道“性别变量可能影响购买偏好”,但你不确定数据里是否支持这种关系 → 可以通过可视化或分析来检验。
Unknown knowns(我们不知道我们知道的)
📍 左下角
被遗忘、忽视、习以为常的知识
需要 回忆/挖掘/正视自己已有的隐性知识
📌 举例:
你做项目时本来会写 SQL,但因为平时没用就忘了,这也是“你知道但没意识到你知道”。
Unknown unknowns(我们不知道我们不知道的)

📍 右下角
最难察觉的盲区:既没掌握、也没意识到
适合用 探索性可视化 来“打开思路”
- 需要通过 Inductive Reasoning(归纳探索) 来发现新的知识线索
📌 举例:
你在探索电影数据时,无意中发现“90后导演拍科幻片更容易大卖”,这是之前从未预料到的模式。
Summary of Stage 2
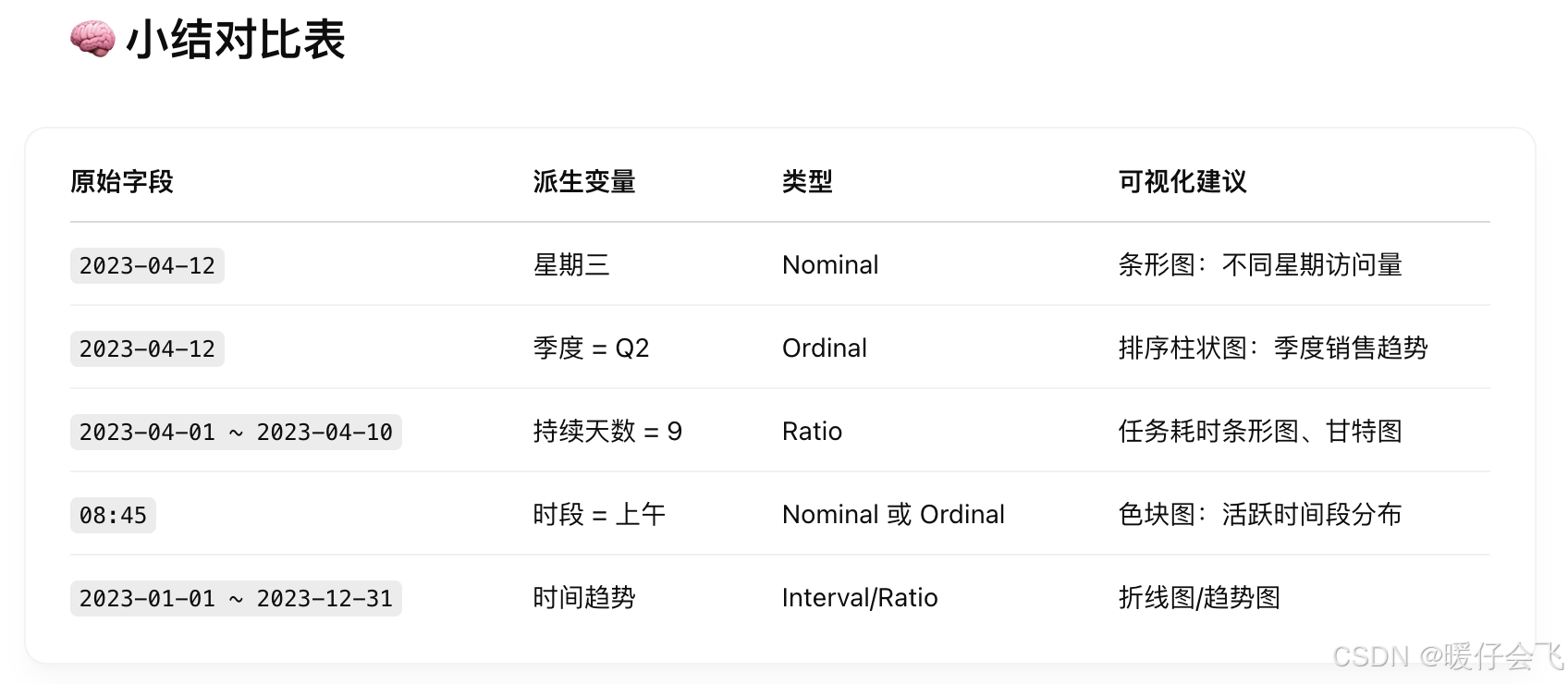
- 这部分我们理解了两种主要不同类型的表格数据

- 同时,掌握了 4 个不同的阶段分别要做什么
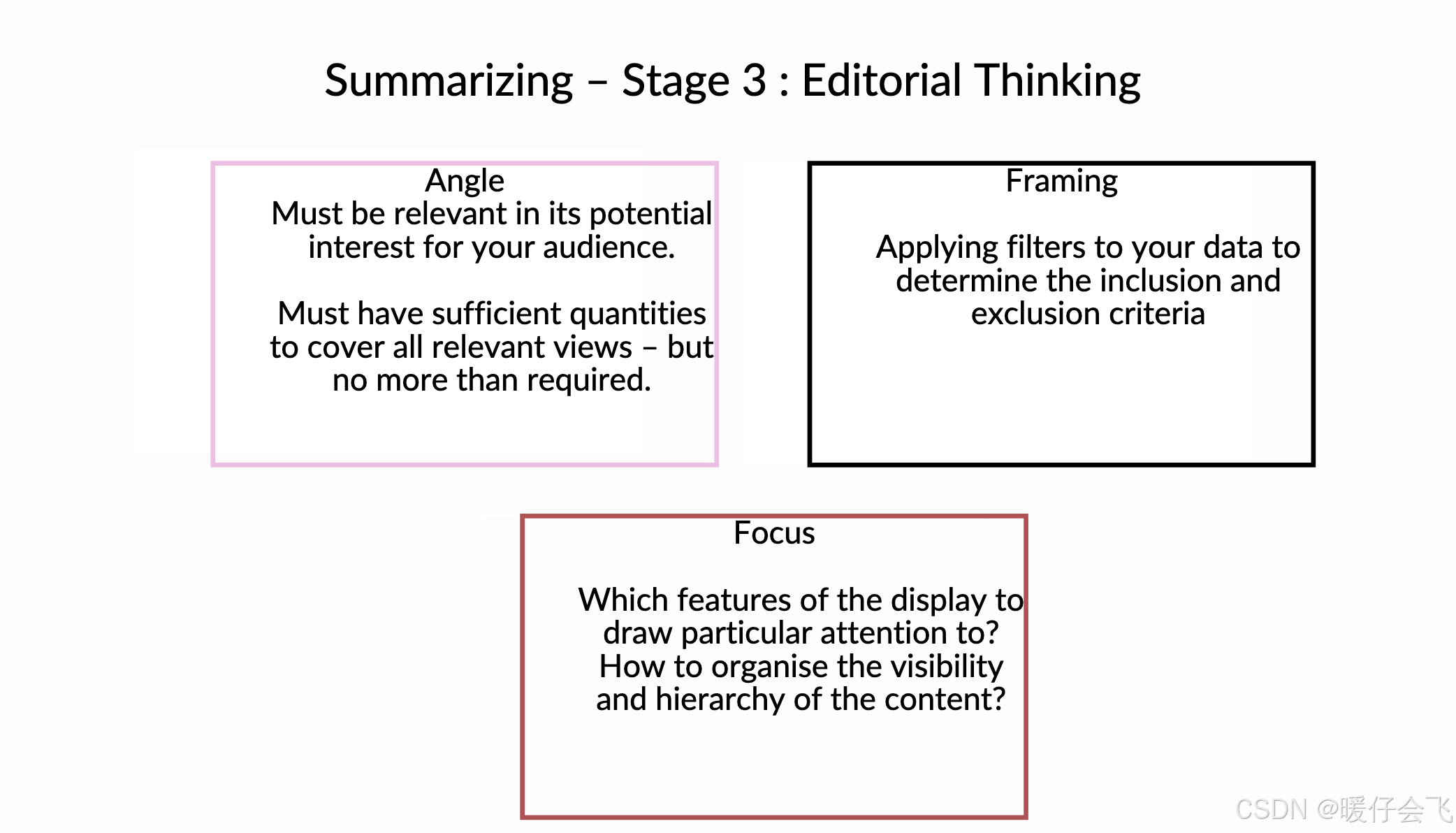
Stage 3: Preparatory stage (筹备阶段)
-
✅ Editorial Thinking(编辑思维阶段)也就是在准备好数据之后,决定如何呈现这些数据给你的目标观众。
-
🎯 这个阶段的 核心目标:
明确你想讲什么故事、突出什么重点、用什么方式组织与展现信息。
-
📦 三个关键词 构成这个阶段的核心框架:Angle, Framing, and Focus

Angle(角度)

-
你从什么视角来分析/展示数据
-
是想看时间变化?地域分布?类别之间的差异?
-
是按总量?还是增长率?
-
是从“用户”视角?还是“政策制定者”视角?
-

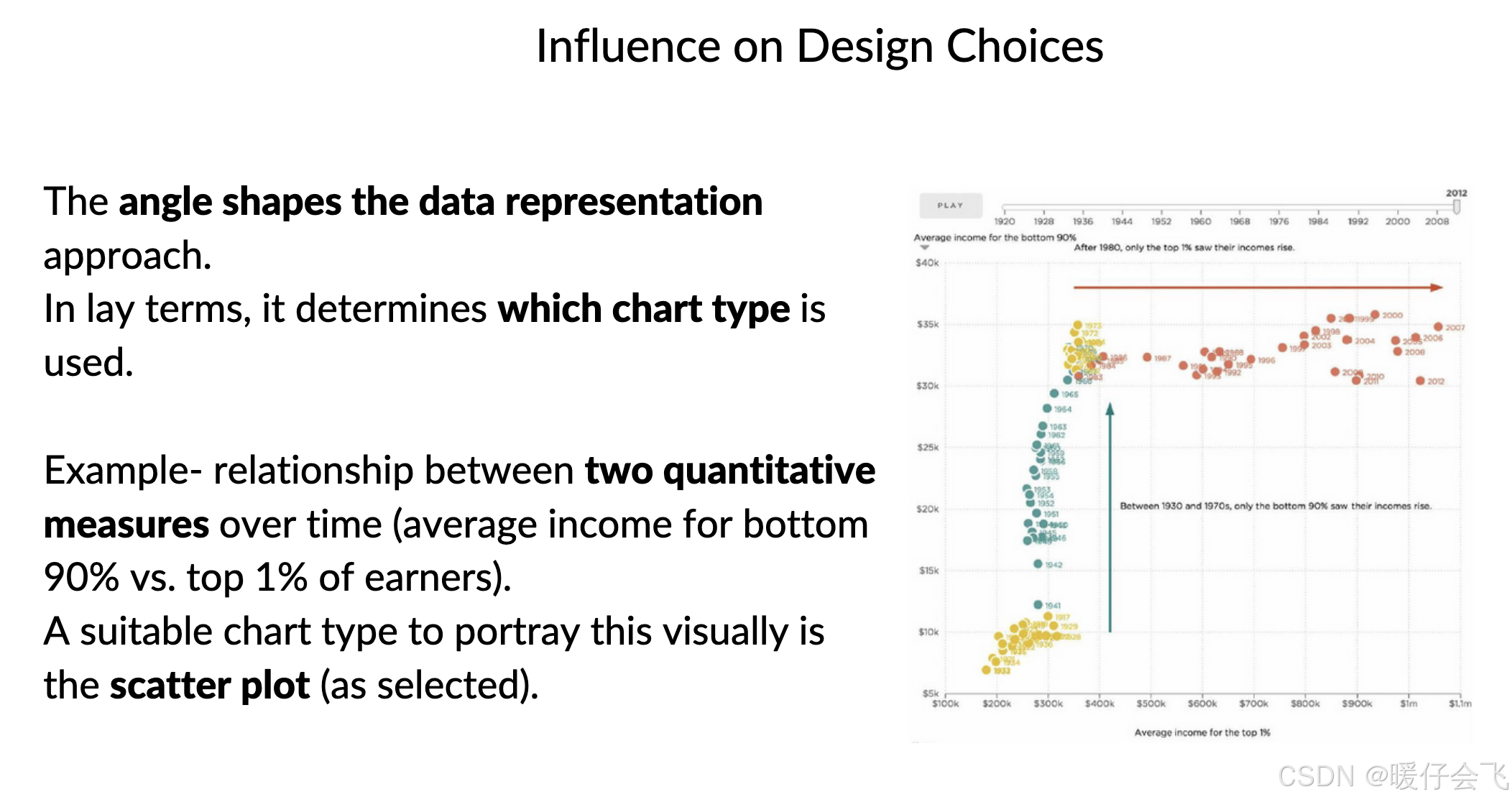
📌 举例,在展示收入不平等时,你可能选择的角度是:
比较 top 1% vs bottom 90% 的收入随时间的变化
或者按地区显示高收入者的分布
- 呈现数据的角度决定了最终使用的图表类型和呈现方法
Framing(取舍)

-
你决定展示哪些数据,排除哪些数据
-
限定时间范围?(例如只展示2000年以后的数据)
-
限定类别?(只关注5个国家)
-
排除异常值或稀有项?
-
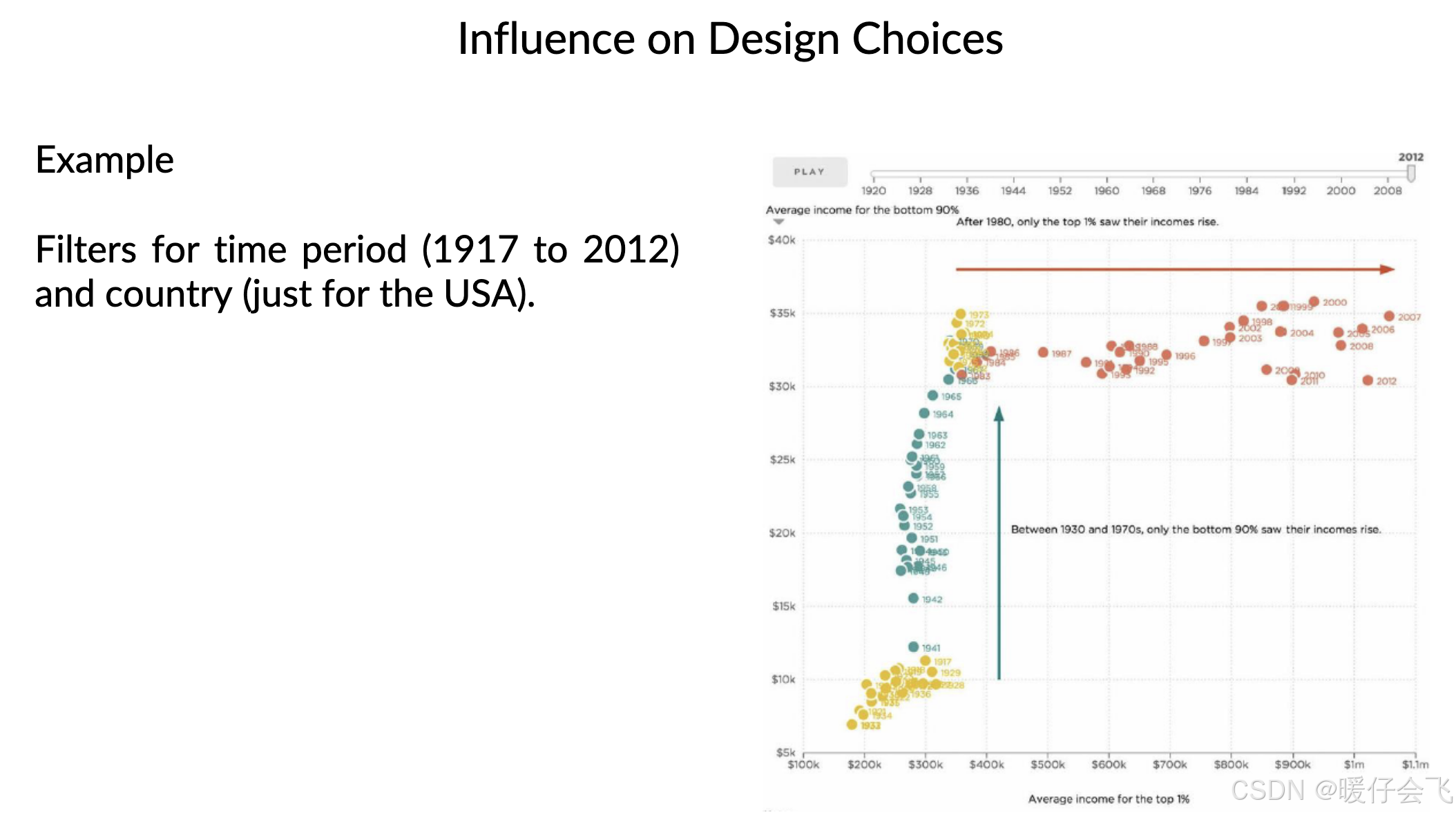
📌 举例:
只选取 2010–2020 年的数据 + 仅限美国数据,来讨论大学学费变化。
Focus(聚焦)

-
你希望观众重点注意什么?视觉重点在哪里?
-
用颜色、大小、注解、动画去突出重点
-
减少“图像噪音”,避免一切都抢眼、观众看不到重点
-
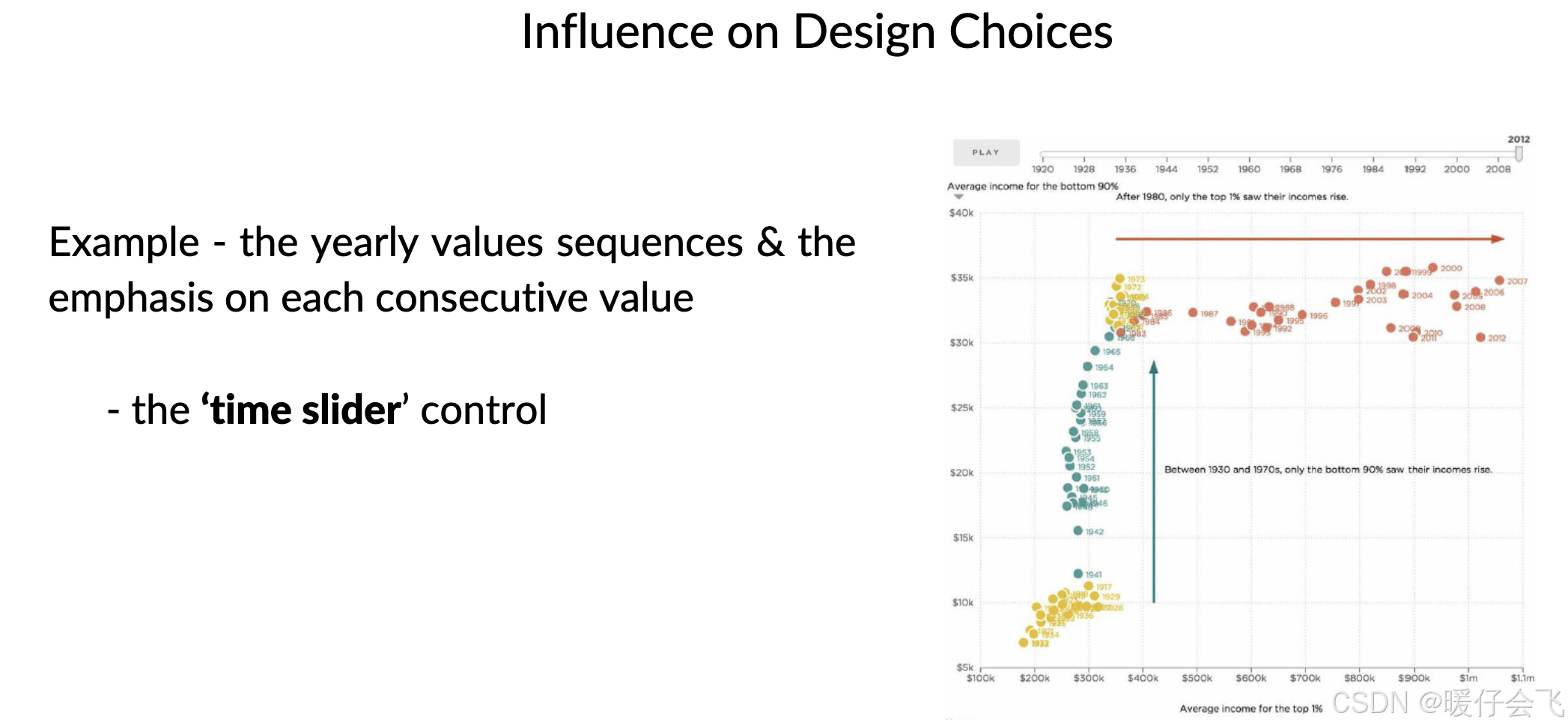
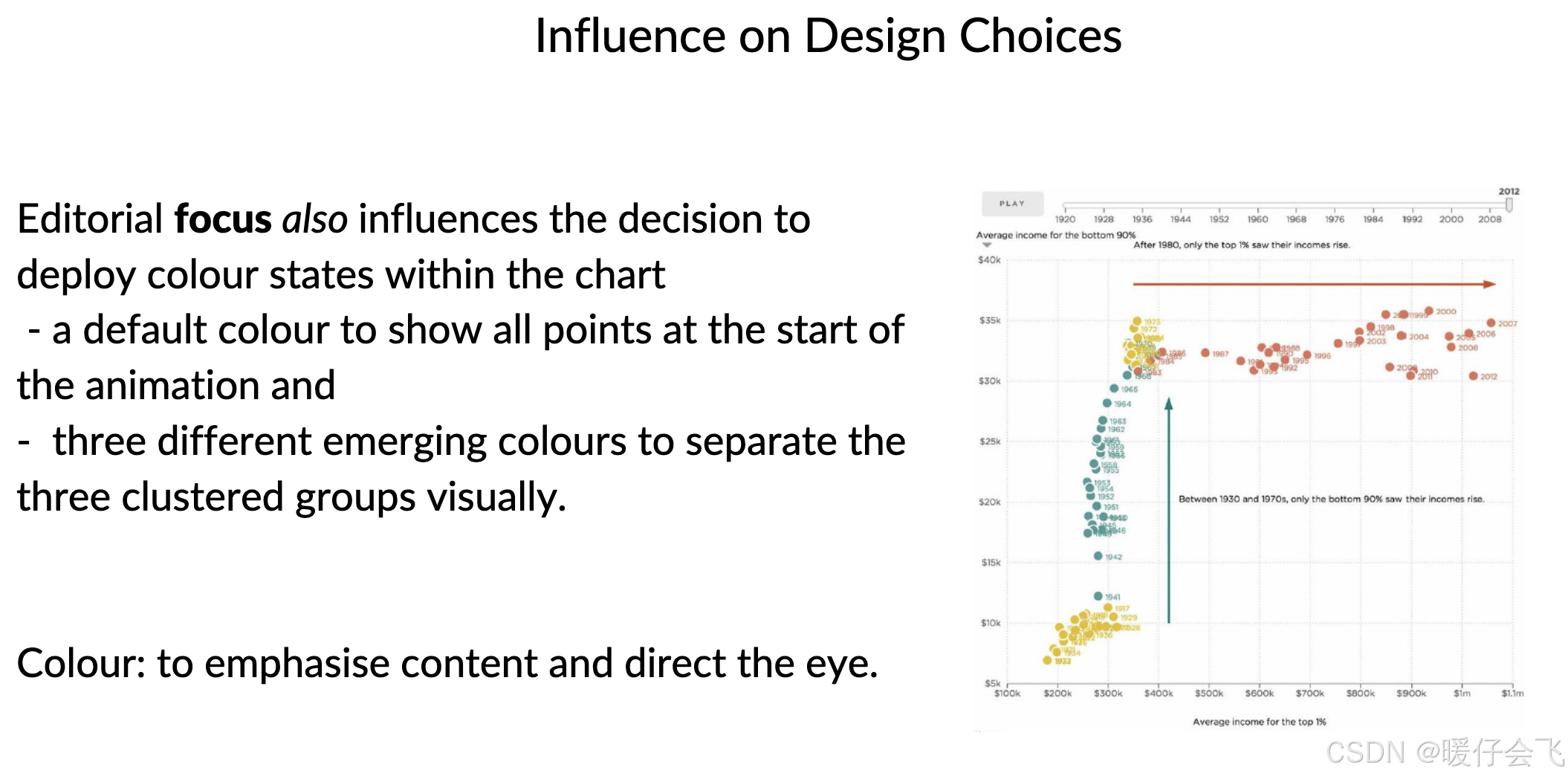
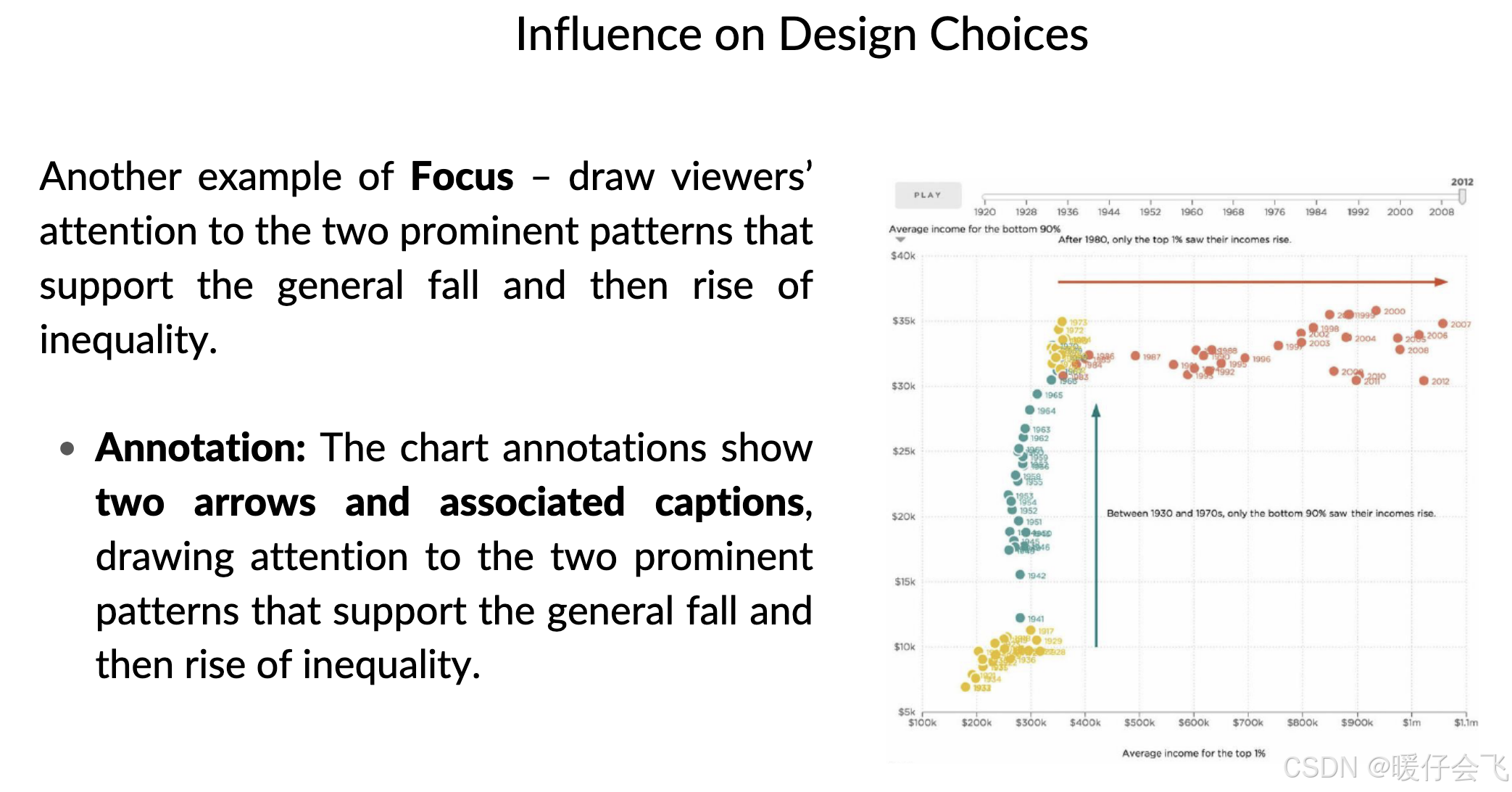
📌 举例:
用高亮色标出今年的数据 vs 历年平均
给某个极端值加上箭头与解释文字
使用渐进加载,让观众逐步理解数据含义
Summarization of Stage 3
- 在编辑思维阶段 editorial thinking,你不是处理数据,而是在思考如何构建数据故事、打动观众、让重点被看到。
Stage 4: Visual manifestation of preparatory work (准备工作的视觉体现)

- 数据的可视化呈现 —— 包括图形编码(visual encoding)、通道(channels)、标记(marks)、交互、注解、色彩和构图等内容。
Marks and Channels (标记和通道)

-
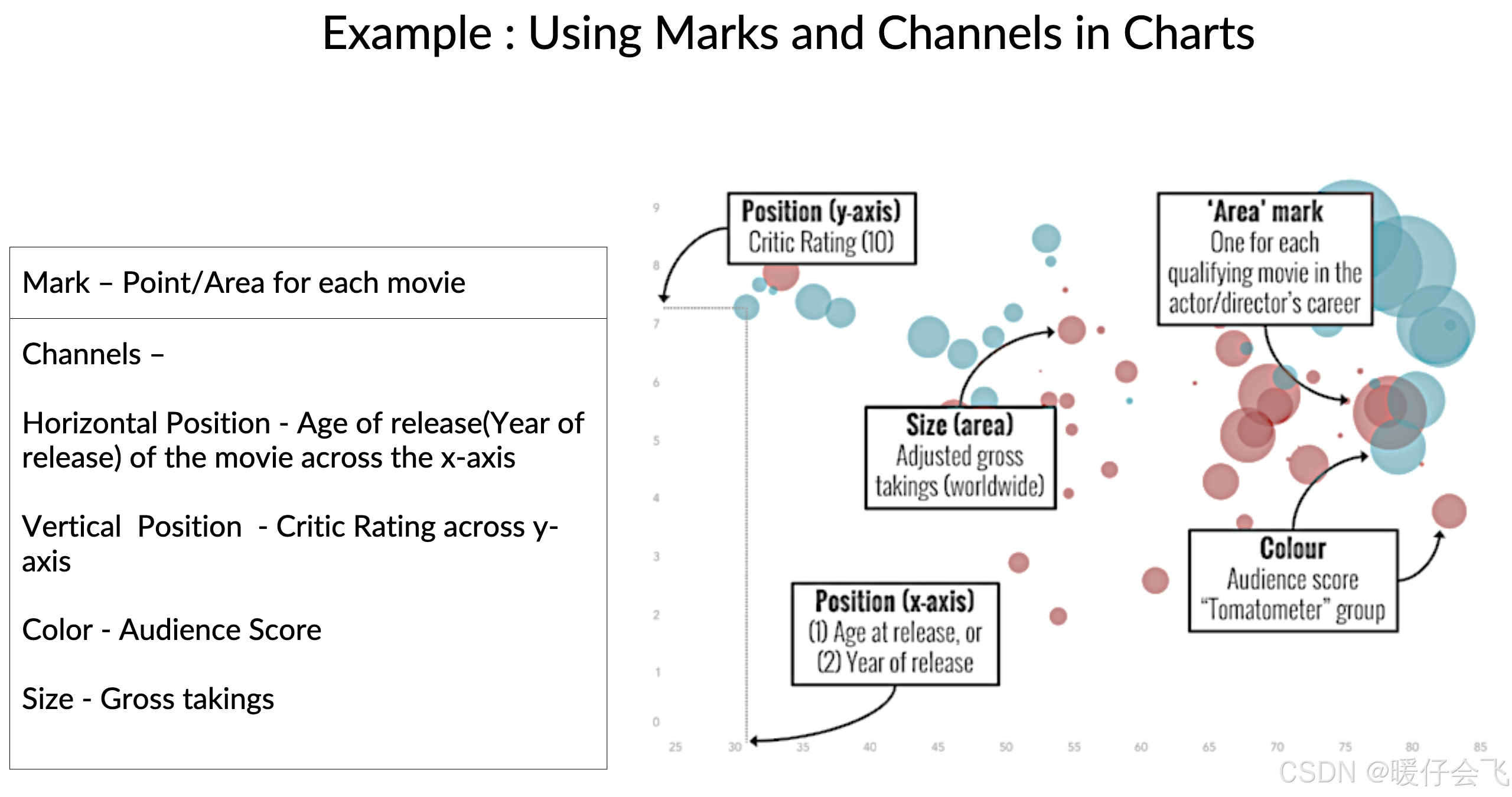
Marks(标记):
表示数据点的可视元素:如点(point)、线(line)、面(area)
每个 Mark 通常表示一个数据记录

📌 例子:
每个“电影”可以是一个点,每个月的“账单”可以是一条线
-
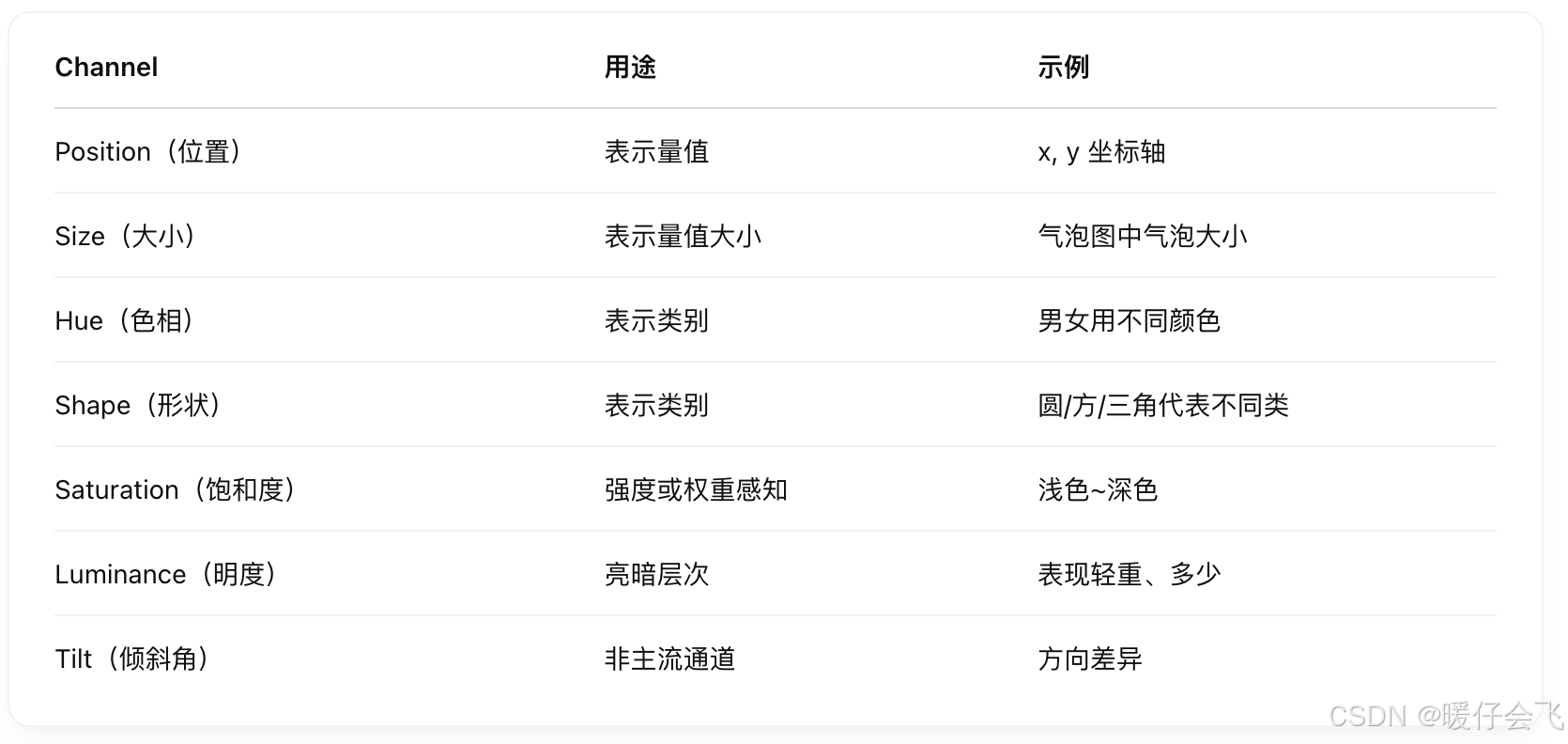
Channels(通道):
用来编码数据属性的视觉变化方式
表示数据属性值的变化,比如大小、颜色、位置

📦 常见通道类型:

Examples
-
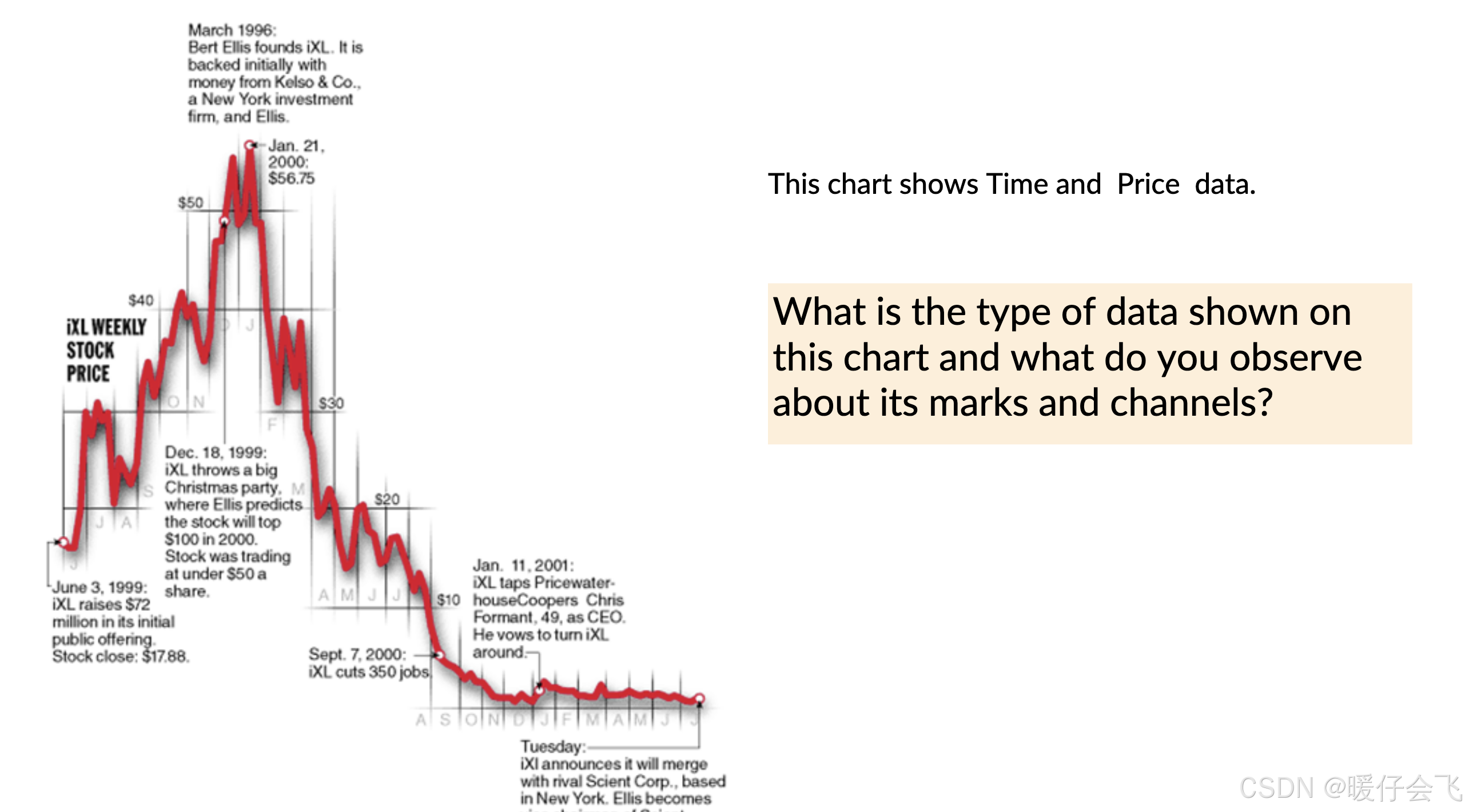
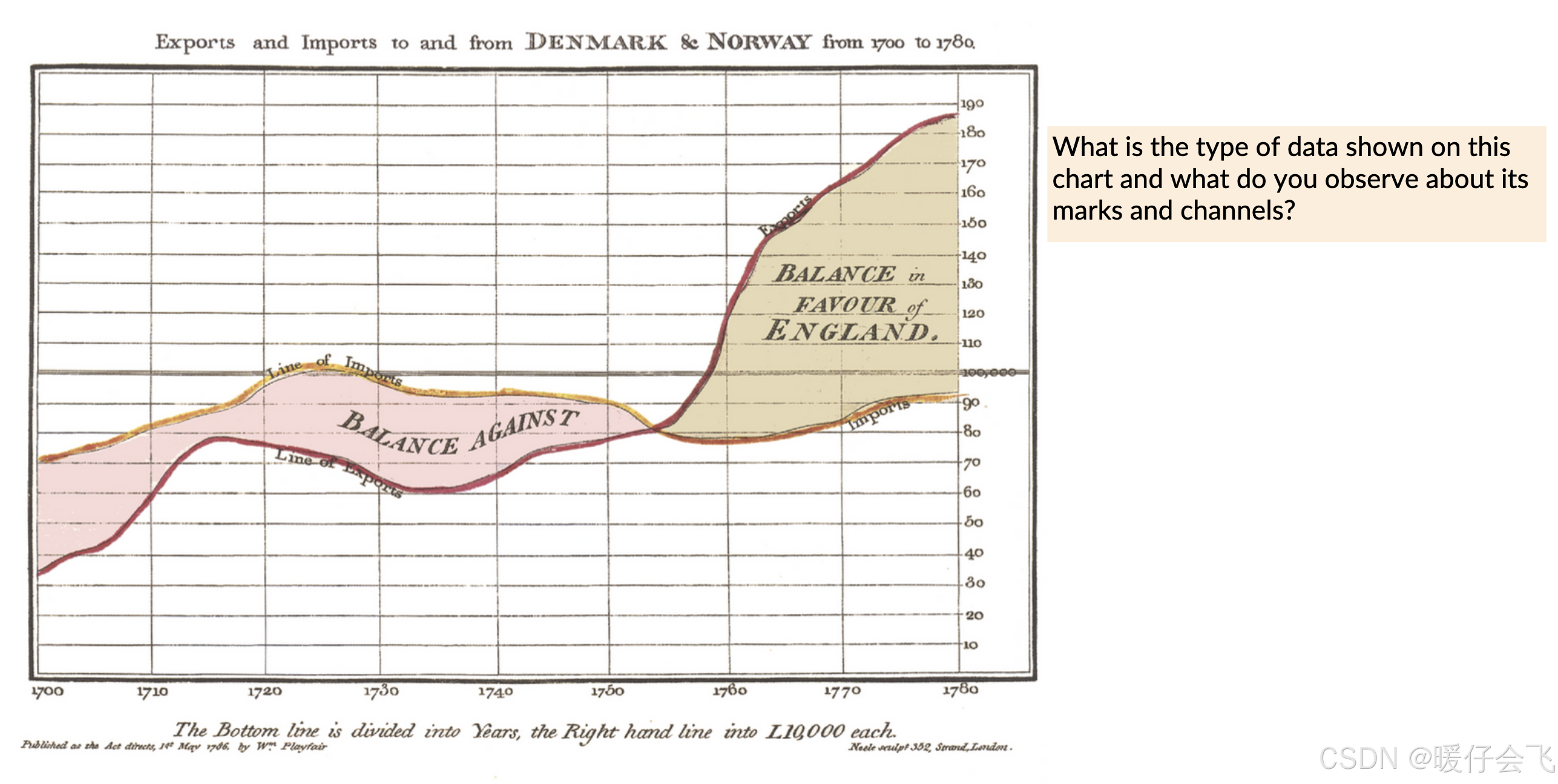
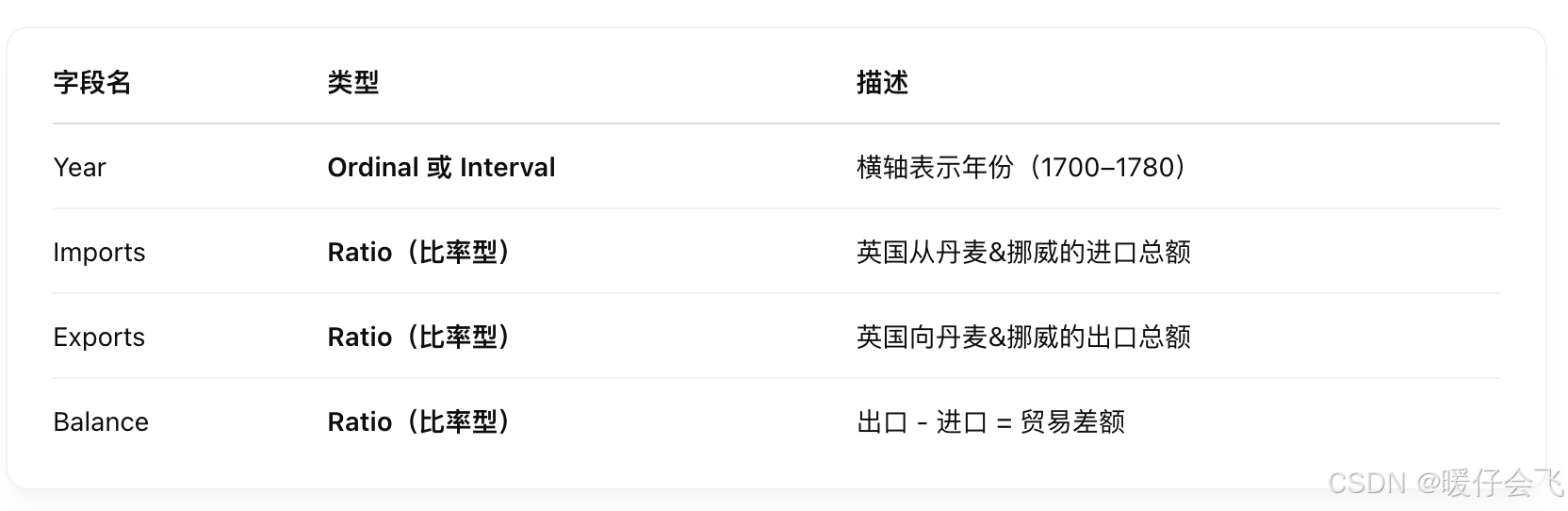
逆向想象表示上述数据的 table 应该长什么样子,应该包含下面两列:
- 时间(Time):沿 x 轴,是**有序型(Ordinal)或间隔型(Interval)**数据
- 股票价格(Price):沿 y 轴,是比率型(Ratio)数据,有绝对零点
-
这个 figure 的 mark 应该是 line 每个点以及下一个点之间的 line
-
而 channles 应该是:
-
数据类型:
-
可能的表结构:
-
Marks:
- Line marks(线):
一条线表示进口金额(Line of Imports)
一条线表示出口金额(Line of Exports)
- Line marks(线):
-
Area marks(面积):
- Exports 与 Imports 之间的区域用颜色填充,表示贸易盈余或赤字
粉红色区间(Exports < Imports)→ “Balance Against”
黄色区间(Exports > Imports)→ “Balance in Favour of England”
- Exports 与 Imports 之间的区域用颜色填充,表示贸易盈余或赤字
-
Channels:
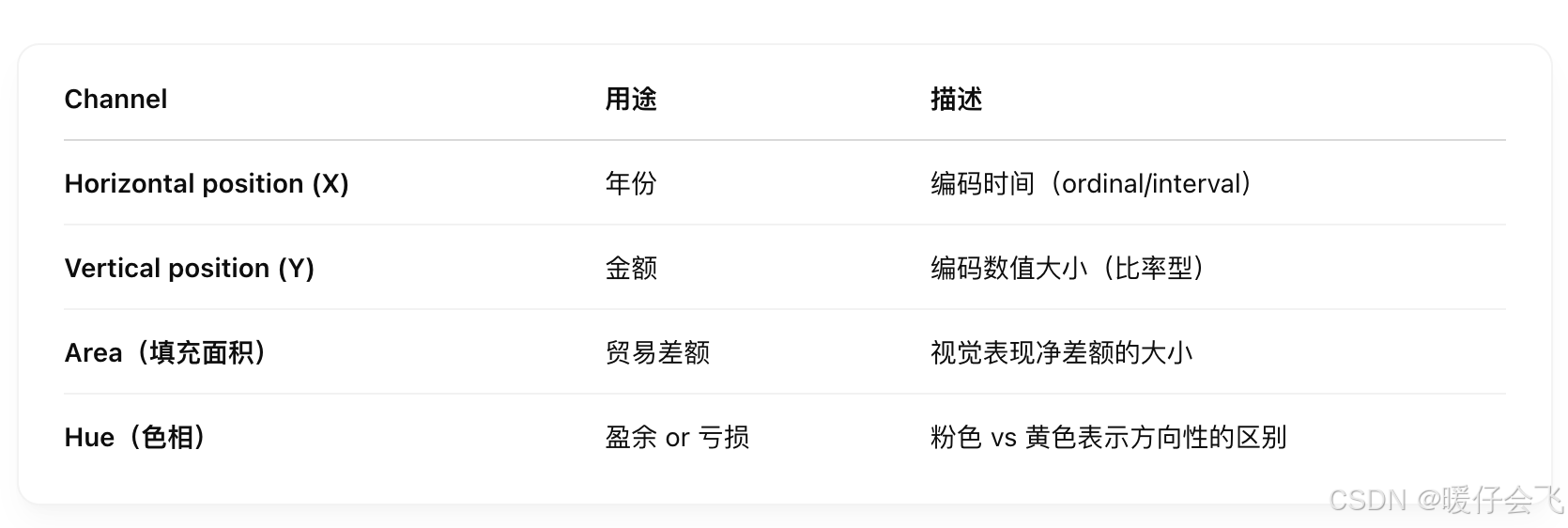
Channels Ranking (通道排序)
-
在图表中,你看到的颜色、位置、大小、形状、角度等都是 channels(通道),它们是我们用来表达数据数值或类别的“视觉语言”。
-
通道决定了 marks(标记) 的外观,比如一个点的颜色或一个条形图的高度。
🧠 为什么要排 Channel 的优劣?
因为我们人类的视觉系统对某些通道更敏感、更容易分辨,使用效果也更好。所以在可视化设计中,要优先使用“效果好的通道”去表达重要数据。
🔢 Channel Ranking 是如何评判的?
 为什么这四个指标最关键?
为什么这四个指标最关键?
- 因为这四个指标分别对应人类在看图表时的四种核心感知任务;能做到这四点,就能被人类的感知系统很快接受,反之则会给人类造成混乱。可以看后面的 Channel Effectiveness 章节
Selective(选择性)


Associative(关联性)


Quantitative(定量性)

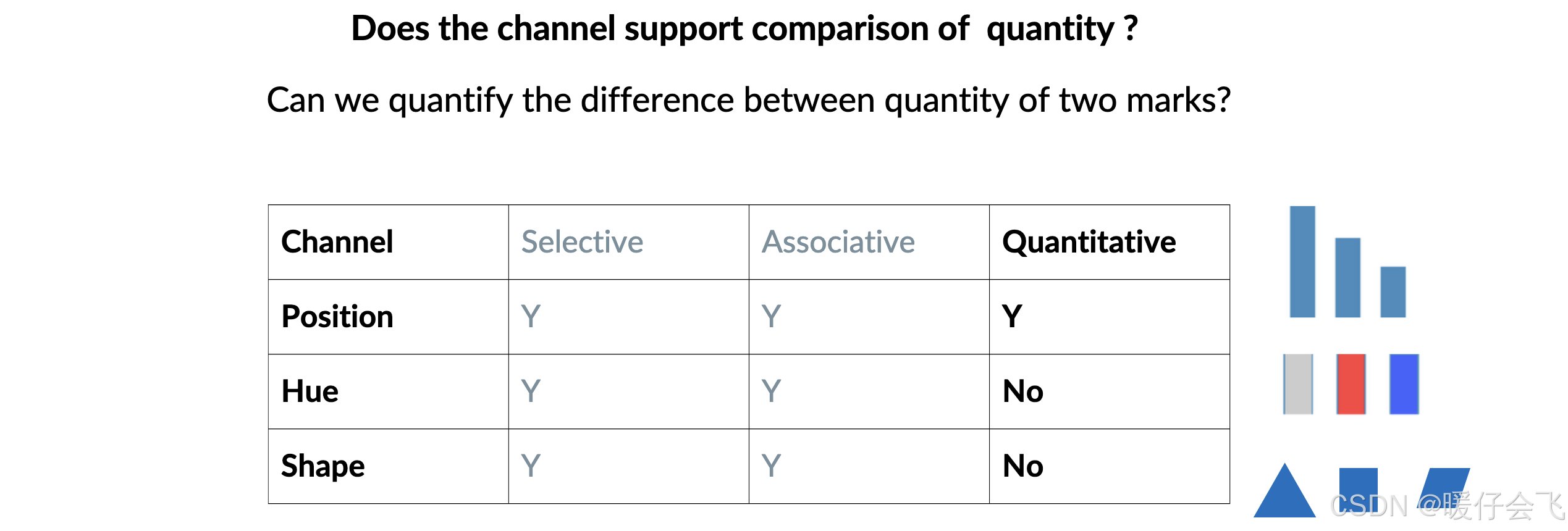
Order(顺序性)


Channles Ranking Summary
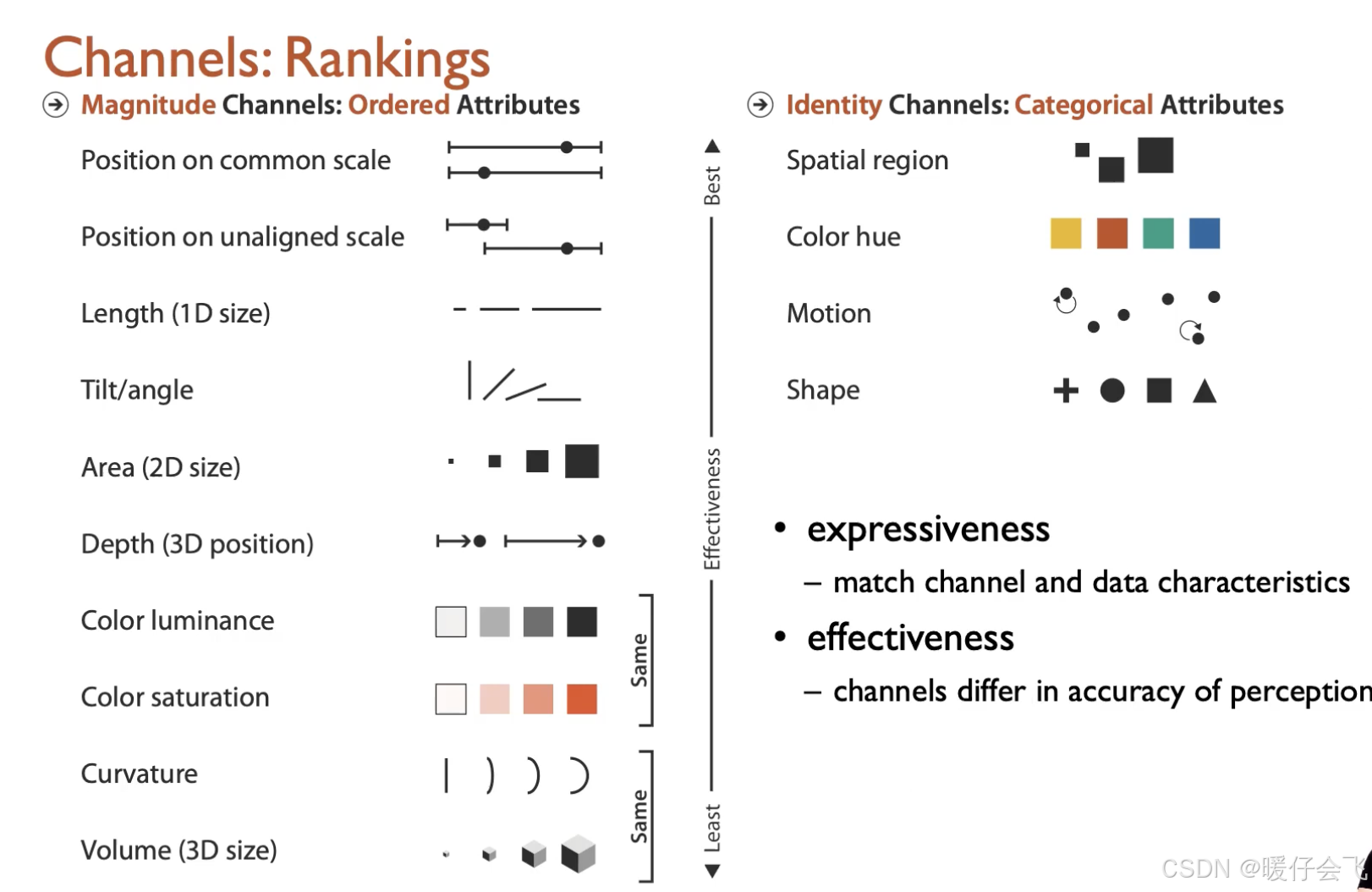
- Magnitude channels(适合表示“多少”)
- Identity channels(适合表示“是什么” / 区分不同的类别)

Color Knowledge

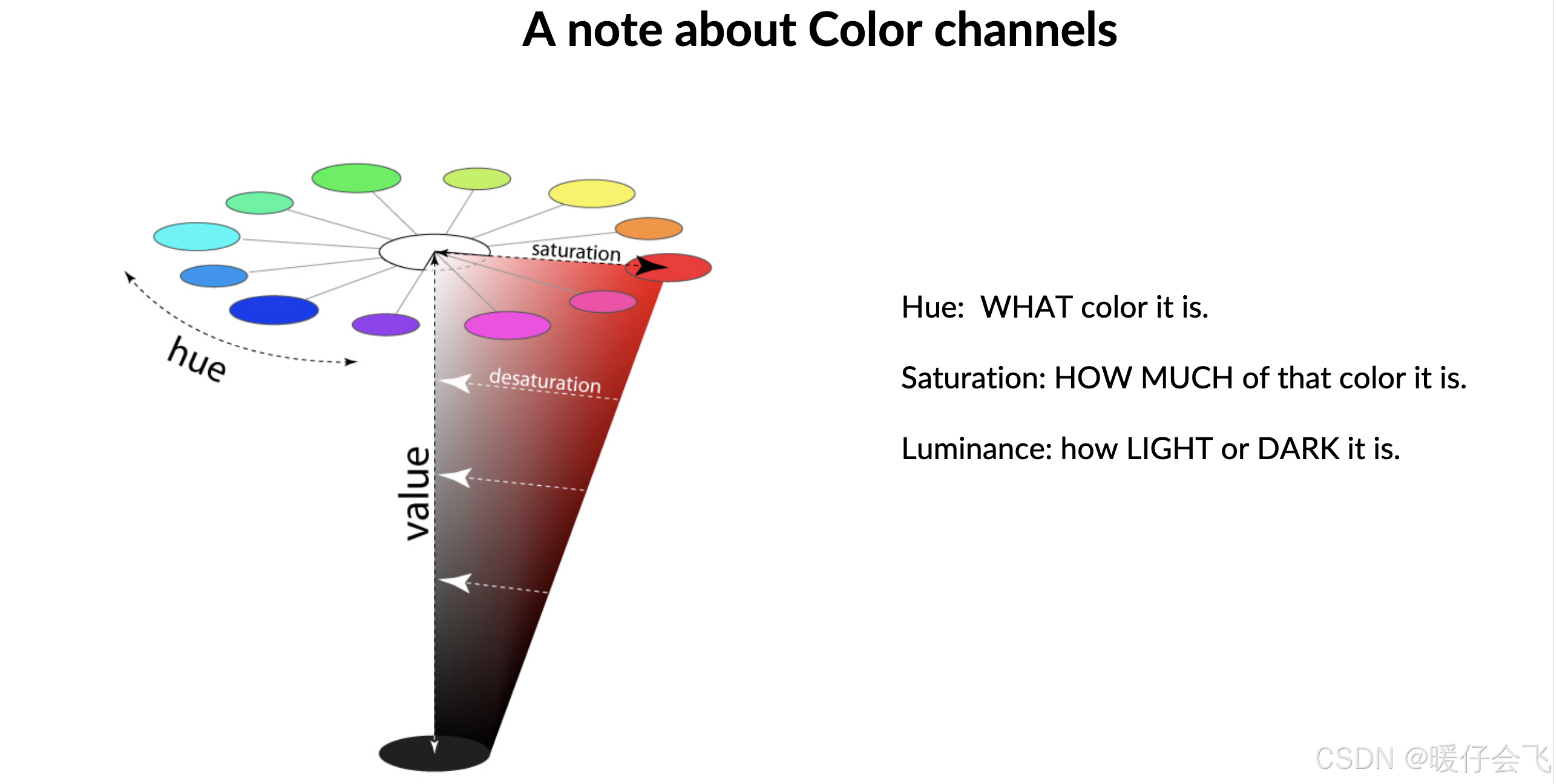
Visual Encoding(视觉编码)


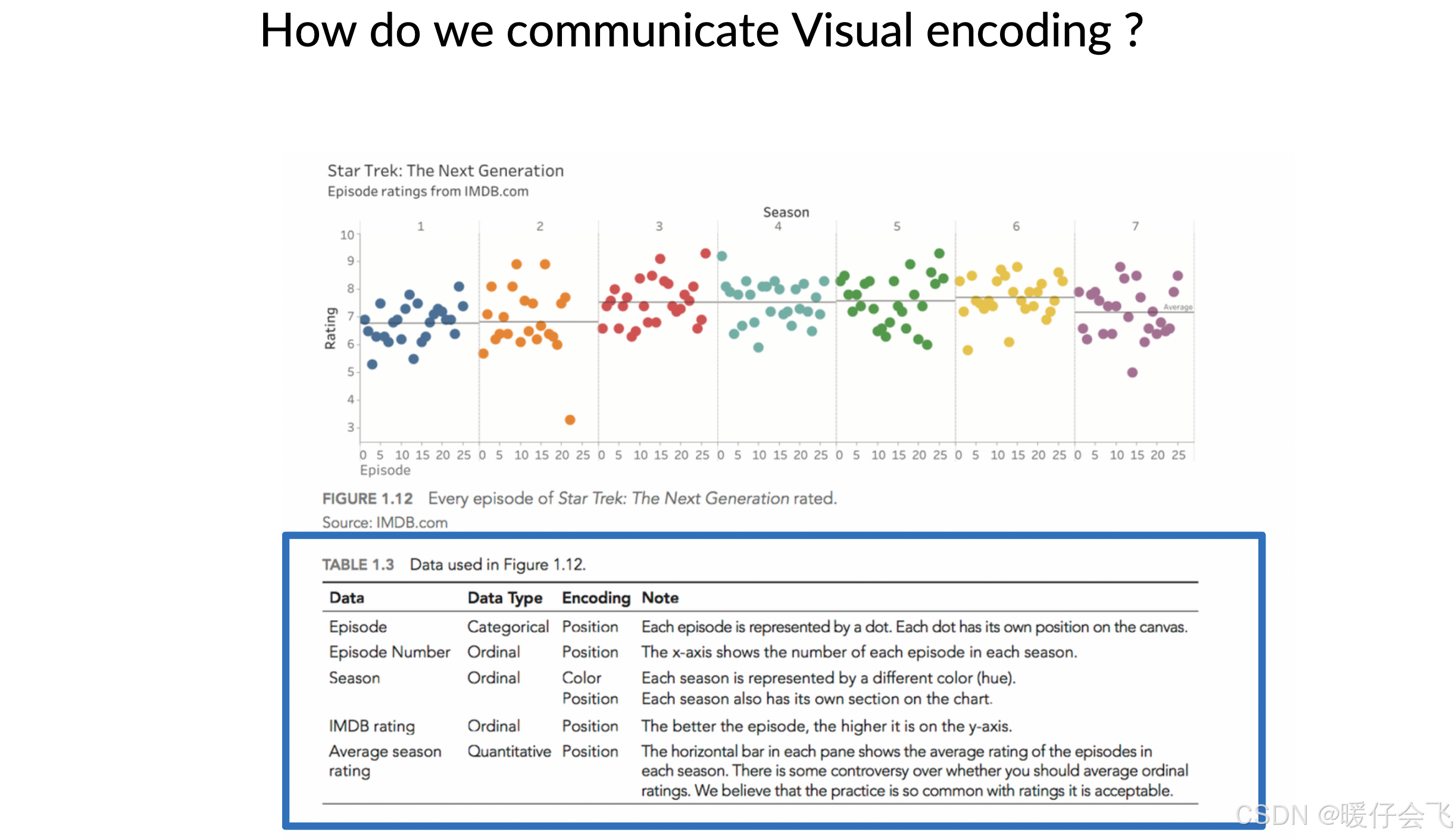
- 这是《星际迷航:下一代》中每集 IMDb 评分的可视化。每个点表示一集,通过不同的位置和颜色来编码多个变量。

- 图表本身展示了视觉编码的效果
-
使用 marks(点) 表示每一集。
-
使用 channels 表达不同变量, 例如:
-
x轴位置 (position):Episode Number(集数)
-
y轴位置(position):IMDB rating(评分)
-
颜色 (color):Season(季)
-
-
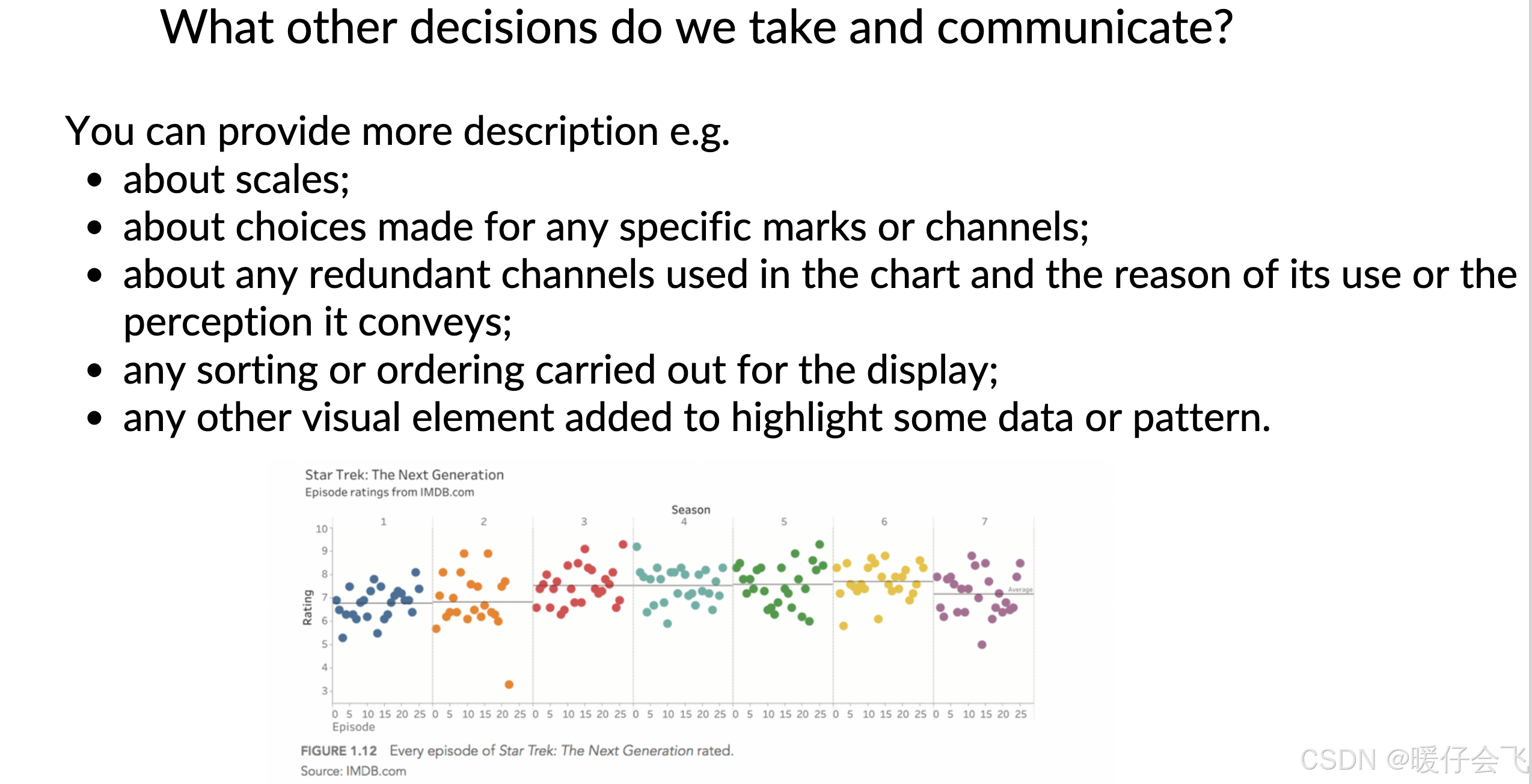
-
除了选择 marks 和 channels,我们编码过程中还可以传达:
用了哪些 scales(比如轴范围、对数 vs 线性)
是否用了 冗余编码(比如用颜色和大小同时表示一个变量)及其原因
有没有进行排序(ordering)或分组(grouping)
是否添加了额外视觉元素用于高亮某些模式
Visual Encoding Design Principles
Principle of Expressiveness (表现力原则)
-
编码要真实准确地表达数据的本质
-
有序的数据 → 用有顺序感的 channel(如位置、长度)
-
无序的数据 → 不要用会误导顺序的 channel(如亮度或渐变)
-
例子:不要用颜色深浅表达类别,会误导“高低”含义

Principle of Effectiveness(有效性原则)
-
重要的数据 → 要用最突出、最易感知的 channel 表达
-
最重要的变量 → 用人眼最敏感的通道(如位置)
-
不重要的变量 → 可以用颜色或形状等次级通道

Channel Effectiveness (通道有效性)
Channel effectiveness 是指用于可视化数据的视觉通道在 **“传达数据价值”**上的表现能力,它包括多个维度,如感知准确性、可区分性、可分离性和视觉突出性等。
Accuracy(准确性)


Discriminability(可区分性)

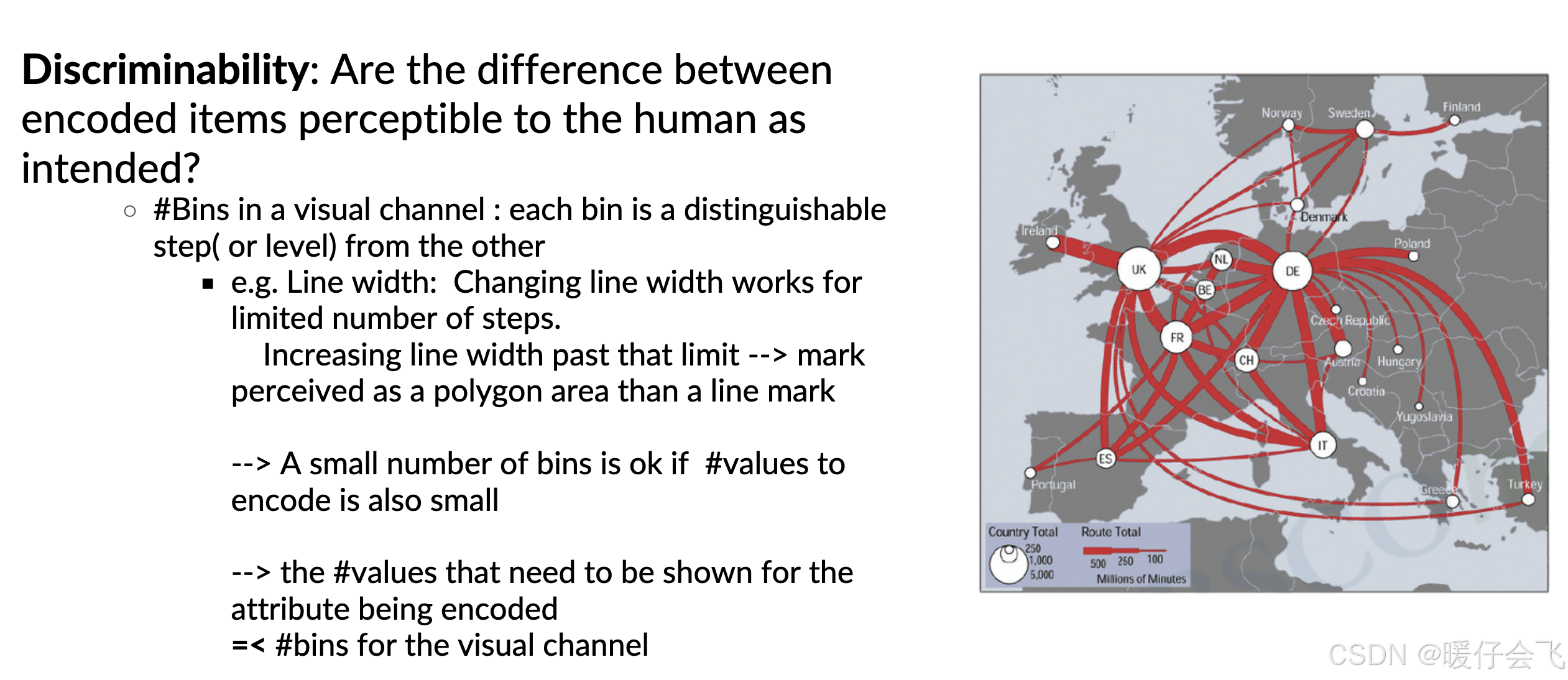
-
在这个图中:
线宽是用来表示“通话时间”这一连续数值变量的。
但人类对 “线宽” 的感知能力是有限的,大约只能分辨 3–5 个等级(bins)。
如果你用太多等级的线宽来表示不同的通话时长,人眼很难区分它们之间的细微差别。
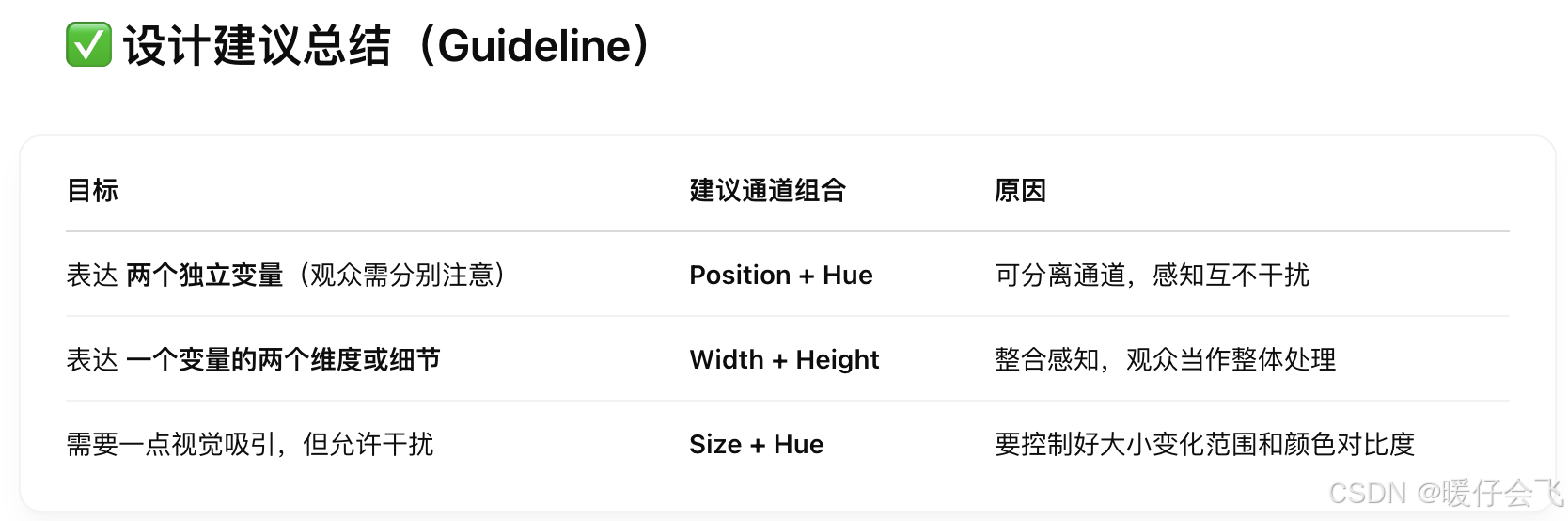
Separability(可分离性)

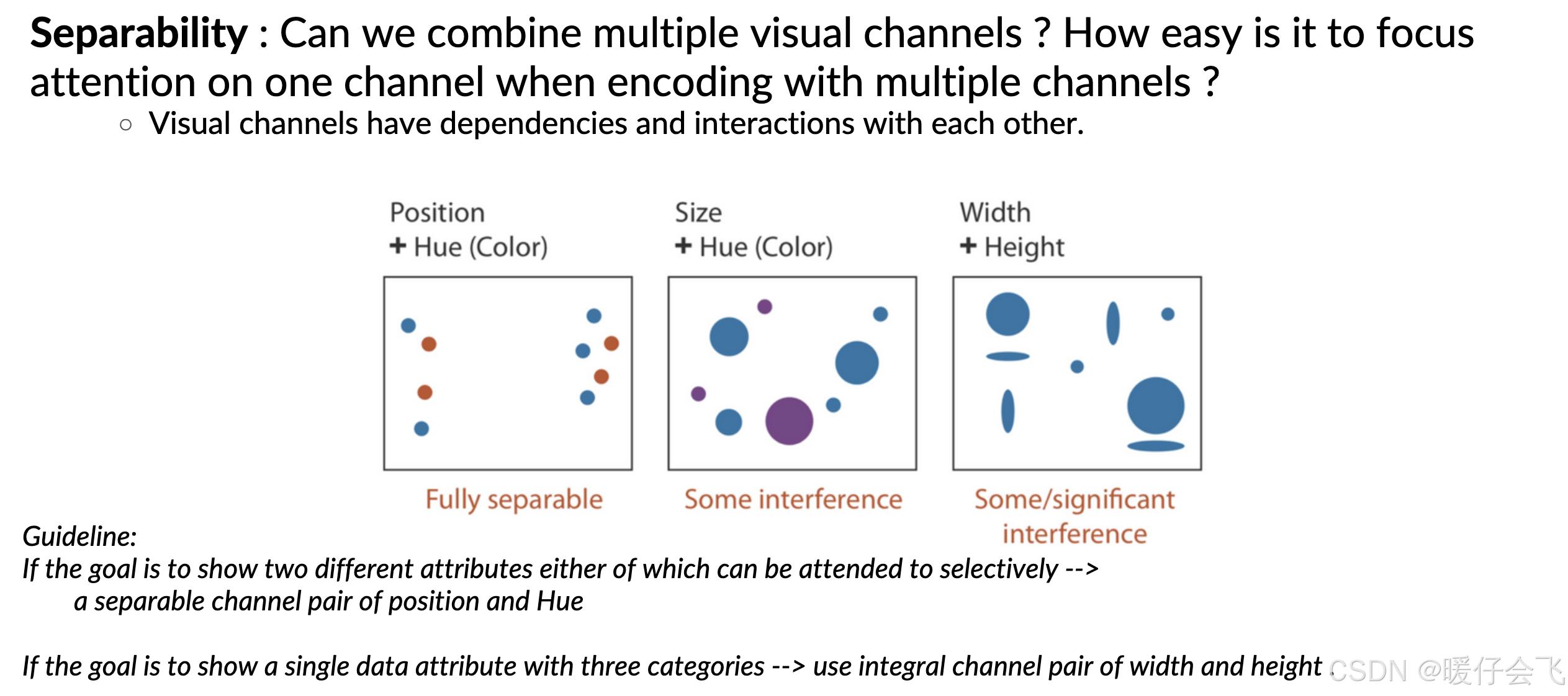
✅ 左边:Position + Hue(位置 + 色相)
示例:每个点的 位置 和 颜色 都编码了不同变量。
位置和颜色所表示的信息几乎不干扰,完全可分离
👉 假设左图用来表示不同行业的收入,(e.g., 收入 vs 行业)收入用位置来表示,而颜色则表示不同行业
🟡 中间:Size + Hue(大小 + 色相)
点的大小表示一个变量(如人数),颜色表示另一个变量(如性别)
用户可能会被大的图形吸引注意力,忽视颜色
或在看颜色时,被图形的大小分散注意力
👉 存在一定干扰,但还算能接受
🔴 右边:Width + Height(宽度 + 高度)
同时编码一个对象的宽和高
人眼很难分别感知宽度和高度的变化,容易直接把它看作面积或形状
👉 如果你只是想表达 一个变量,这种“整合通道(integral channel)”反而更合适(比如面积 = 宽 × 高)
Visual Popout(视觉突出)
Popout 效应指的是:当一个图形元素在视觉特征上明显不同于周围其他元素时,人眼可以在极短时间内迅速捕捉到它。

Other factors affects accuracy(其他影响 accuracy 的因素)


- 人们的 “相对判断” 能力和准确度都要高于 “绝对判断” 因为人类的大脑会做一些主动的边缘填充工作