基础层数据从kafka读取写入hbase的优化方案
背景:
上游kafka的topic只有一个分区,所以spark在消费的时候,无论设置的executor数有多少,最终只有一个executor在执行,如果不指定executor num的话,默认是开启两个executor,有一个executor的资源是浪费的,例如下面显示的情况,其实只有一个executor是active的状态.
在消费的时候,务必指定executor的数量.在只有一个executor的情况,要实现并发读取,就只有多开线程,一个executor代表一个进程,而一个core,代表一个线程.所以,最终的指令是
--num-executors 1 --executor-cores 5 --executor-memory 2g
指令说明,只有一个executor, 给这个executor分配5个core,2g的内存资源.
下面是真实的消费情况
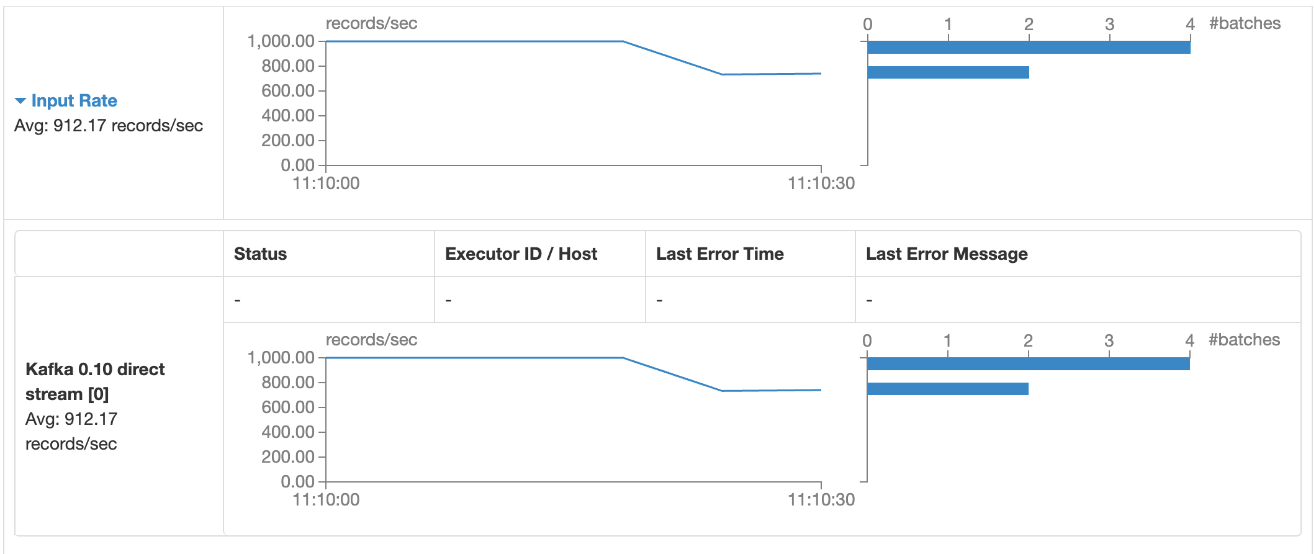
从上面的图中可以看到,每秒消费是912条.但程序中设置的每秒消费1000条,

所以还有优化的空间.
优化措施1: executor-cores
既然executor不能提高,就要提高线程数,也就是core的数量,从5个提高到10个
--num-executors 1 --executor-cores 10 --executor-memory 2g
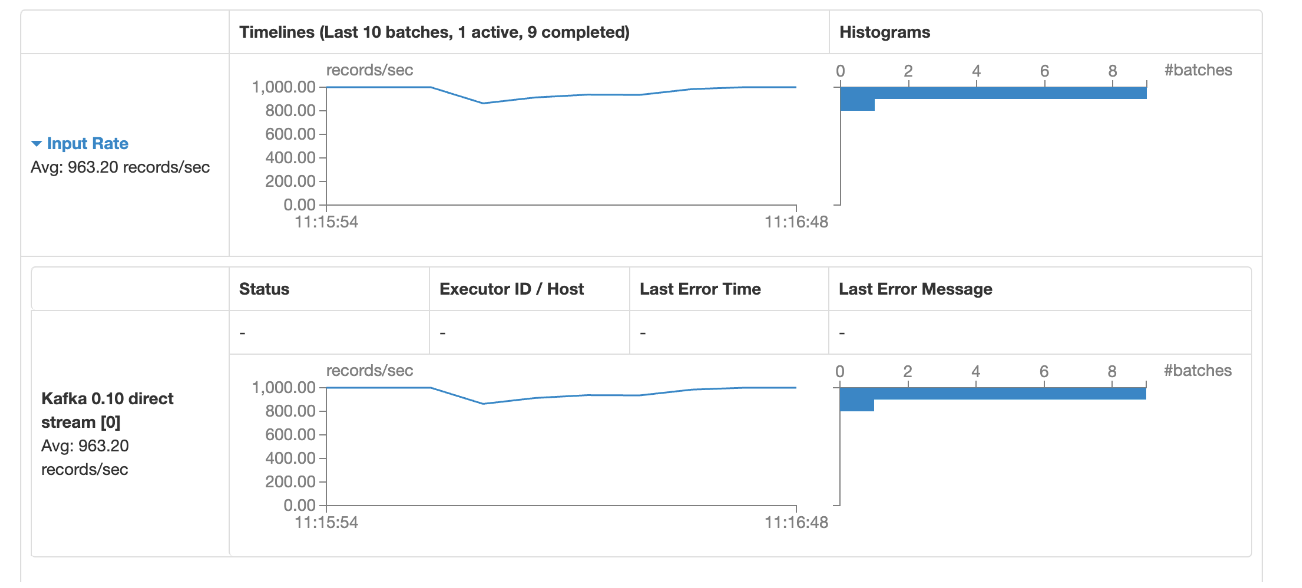
入下图,只启动了一个executor

在增加了线程数的情况下,每秒的写入数据从912条提高到了963条,依旧少于1000条.
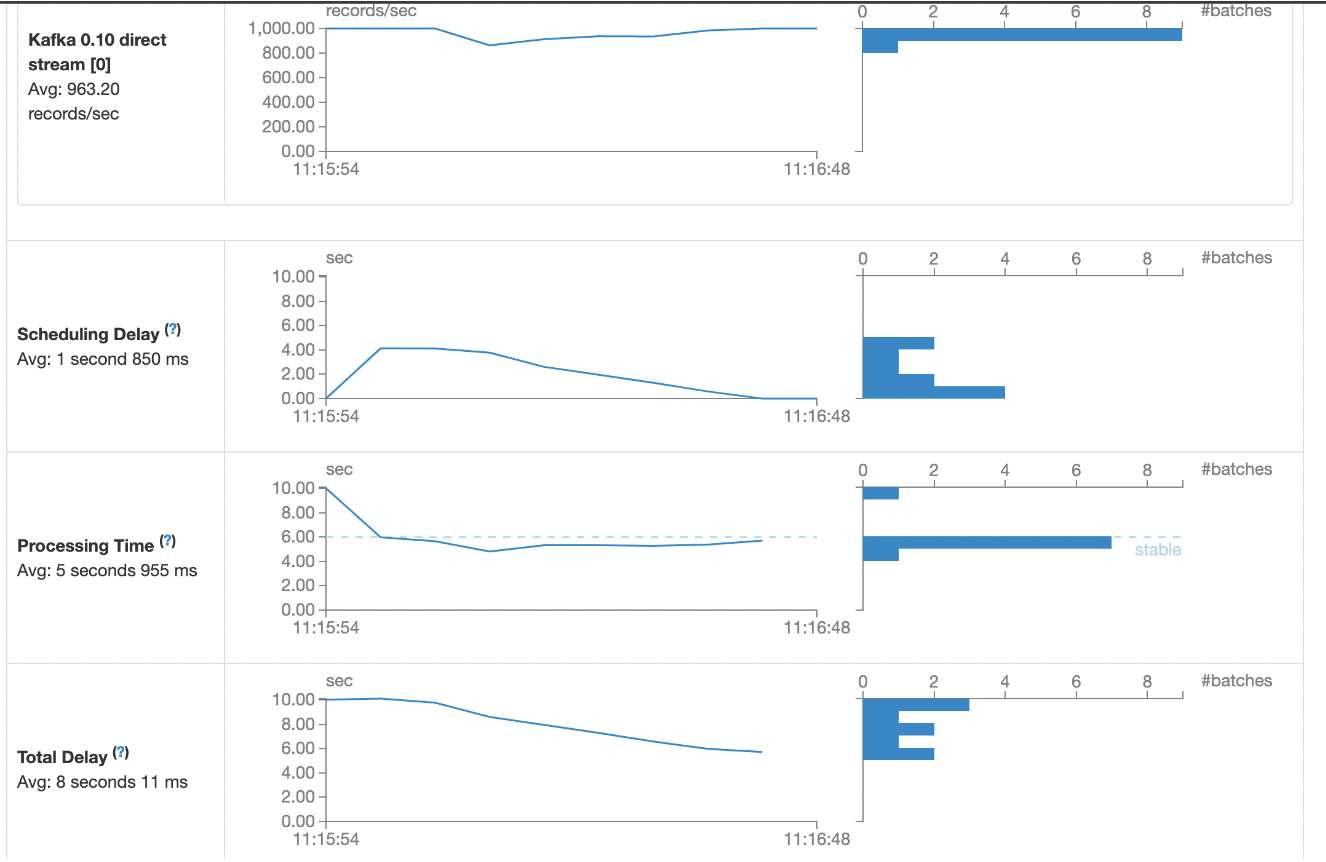
继续提高core的数量,从10个core提高到20core
--num-executors 1 --executor-cores 20 --executor-memory 2g
如下图看到,虽然核心数翻倍,但是数据的写入速度并没有显著提高,所以,core的参数潜力有限.
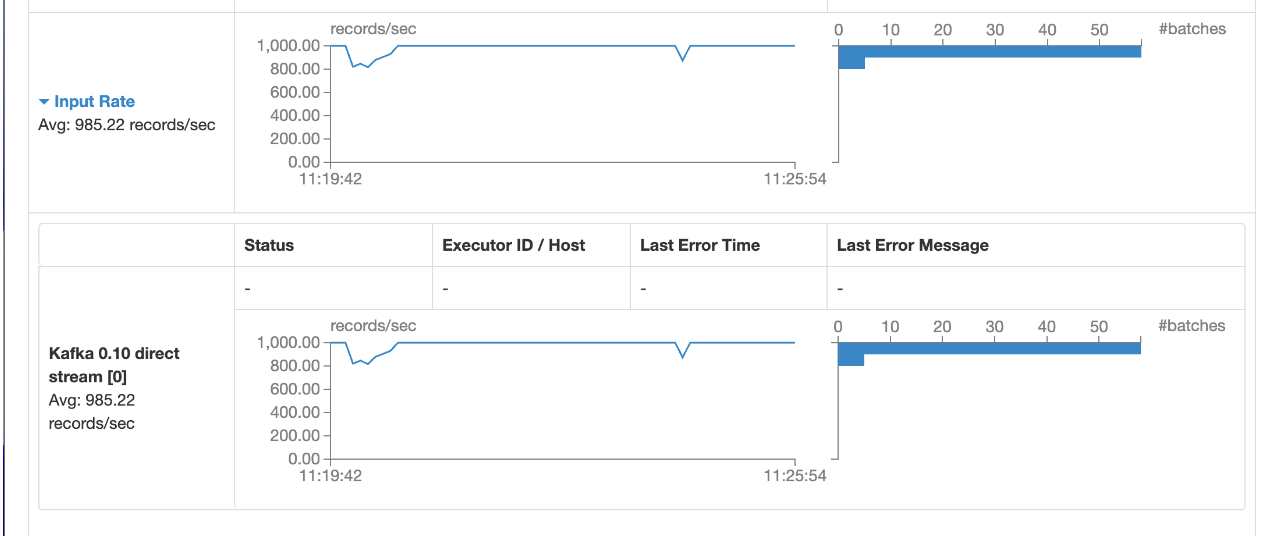
优化措施2: 提高hbase表的预分区数
原本的hbase表是没有预分区的,而是根据数据的不断写入自动分区,写入效率差,根据listid来预分区.分10个分区.
create 'T_PREM_ARAP_613_base_test','info',SPLITS => ['1', '2', '3', '4', '5', '6', '7', '8', '9']
看下图,每秒的写入速度是1000条每秒,达到了预期.

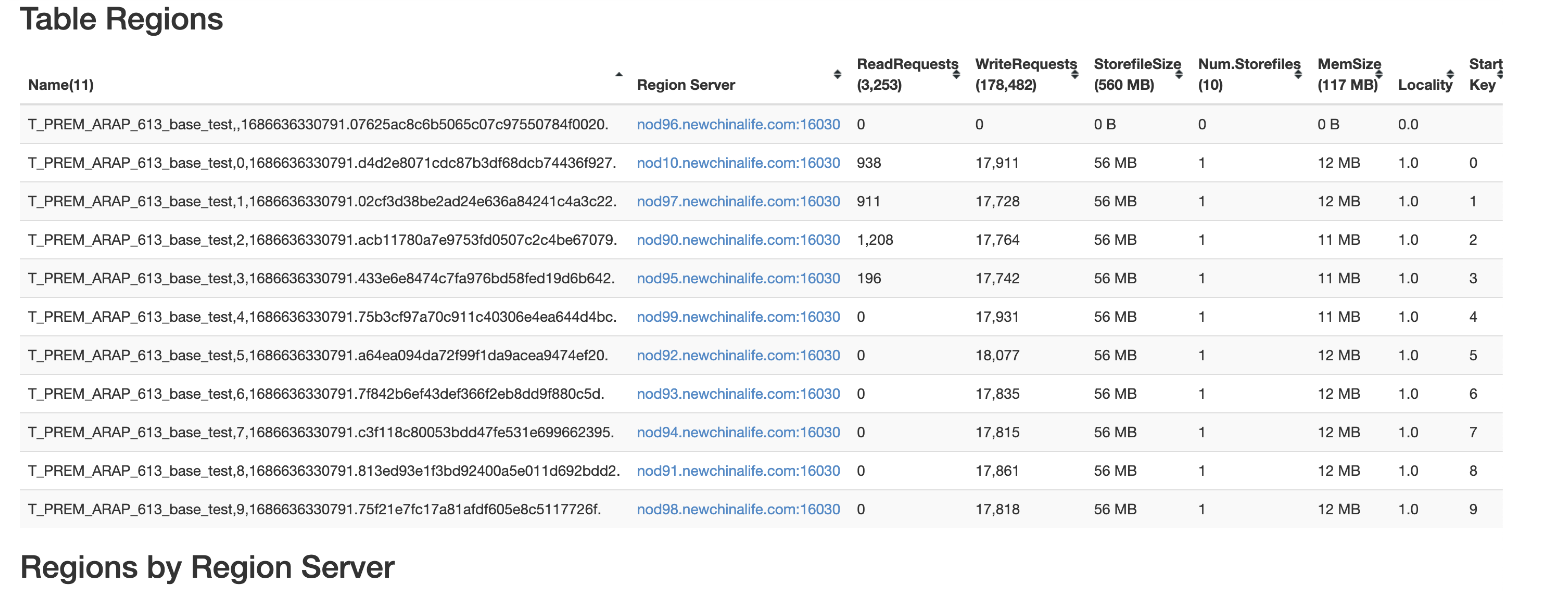

可以看到每个分区的写入请求是均衡的.
甲方提出,一小时的写入是2000万条,约等于6000条每秒.
将表预分区为11个,并按照如下的设置进行测试
--num-executors 1 --executor-cores 11 --executor-memory 2g
region number 11

可以看到每6秒攒不到36000

如何设置并没有达到要求.
继续提高core的数量
--num-executors 1 --executor-cores 50 --executor-memory 8g
region number 11
出现报错信息:
diagnostics: Invalid resource request! Cannot allocate containers as requested resource is greater than maximum allowed allocation. Requested resource type=[vcores], Requested resource=<memory:9011, vCores:50>, maximum allowed allocation=<memory:65536, vCores:32>, please note that maximum allowed allocation is calculated by scheduler based on maximum resource of registered NodeManagers, which might be less than configured maximum allocation=<memory:73739, vCores:32>
诊断:无效的资源请求!无法分配容器,因为请求的资源大于允许的最大分配量。请求的资源类型=[vcores],请求的资源=<memory:9011,vcores:50>,允许的最大分配=<memory:65536,vCore:32>,请注意,允许的最小分配是由调度器根据注册NodeManager的最大资源计算的,可能小于配置的最大分配<memory:773739,vcores_32>
说明: 一个executor的最大core的数量是32个
重新设置core的数为32个
--num-executors 1 --executor-cores 32 --executor-memory 8g
region number 11
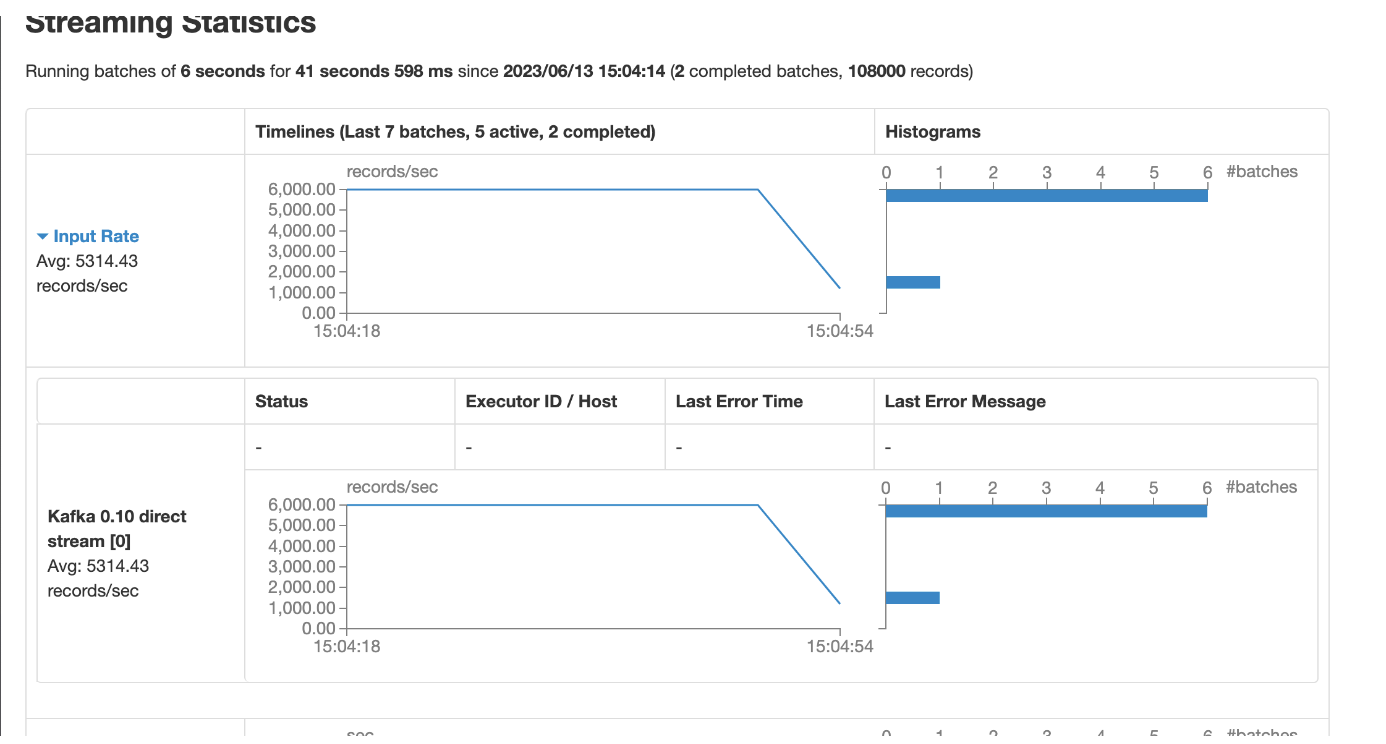
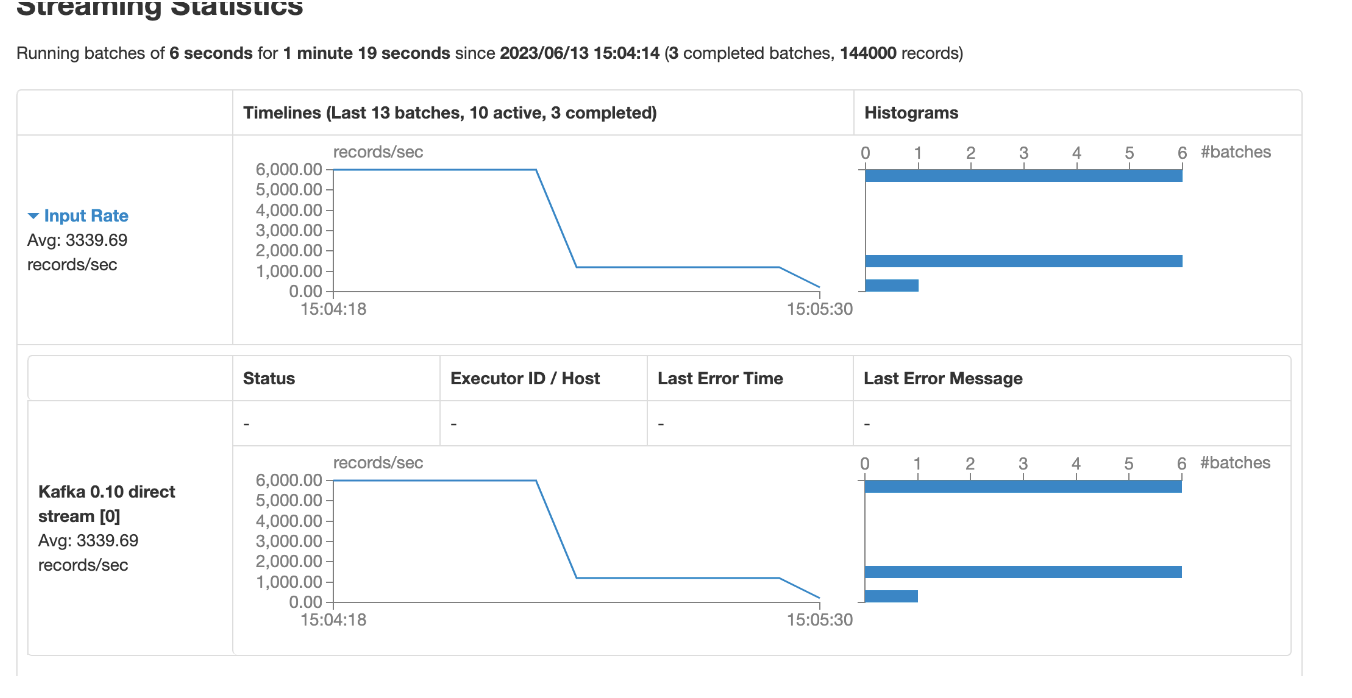

一开始可以的打满,后来没个批次就越来越小了,处理数据速度越来越慢
说明在hbase sink处有瓶颈,继续加大region 的预分区,分30份

create 'T_PREM_ARAP_613_base_test','info',SPLITS => ['1', '4', '7', '10', '13', '16', '19', '22', '25', '28', '31', '34', '37', '40', '43', '46', '49', '52', '55', '58', '61', '64', '67', '70', '73', '76', '79', '82', '85', '88']
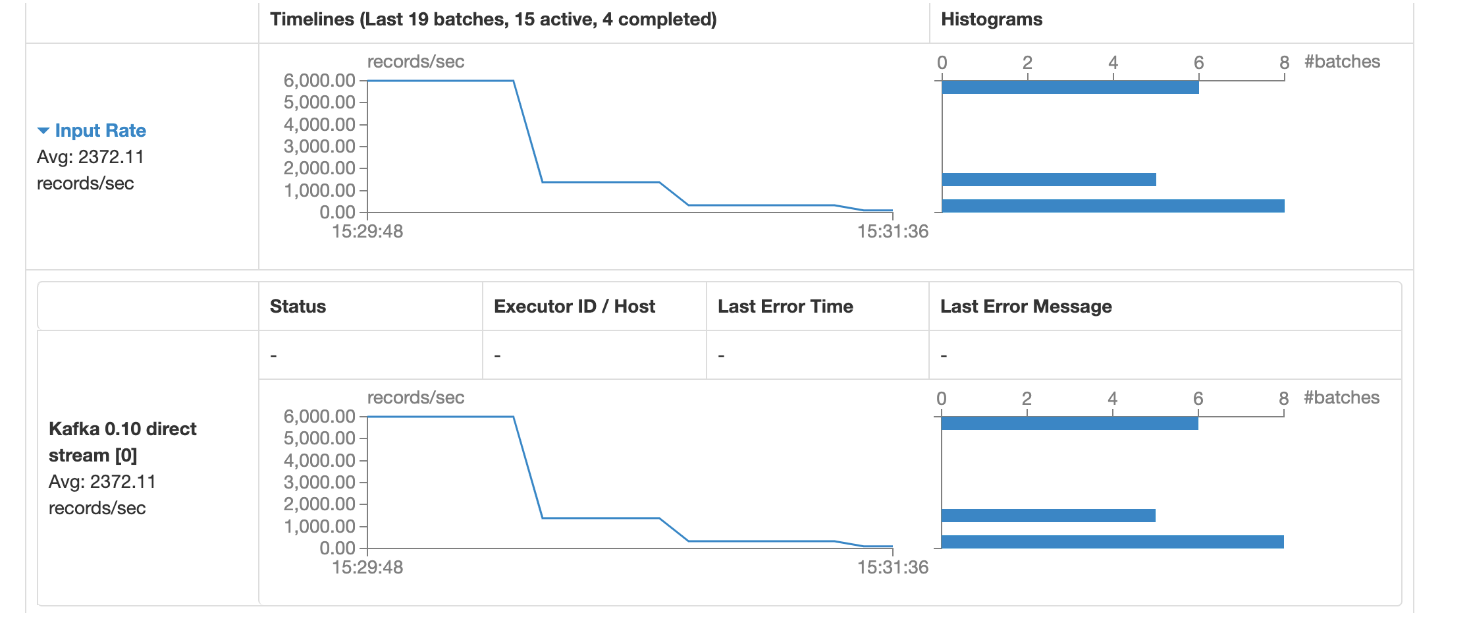
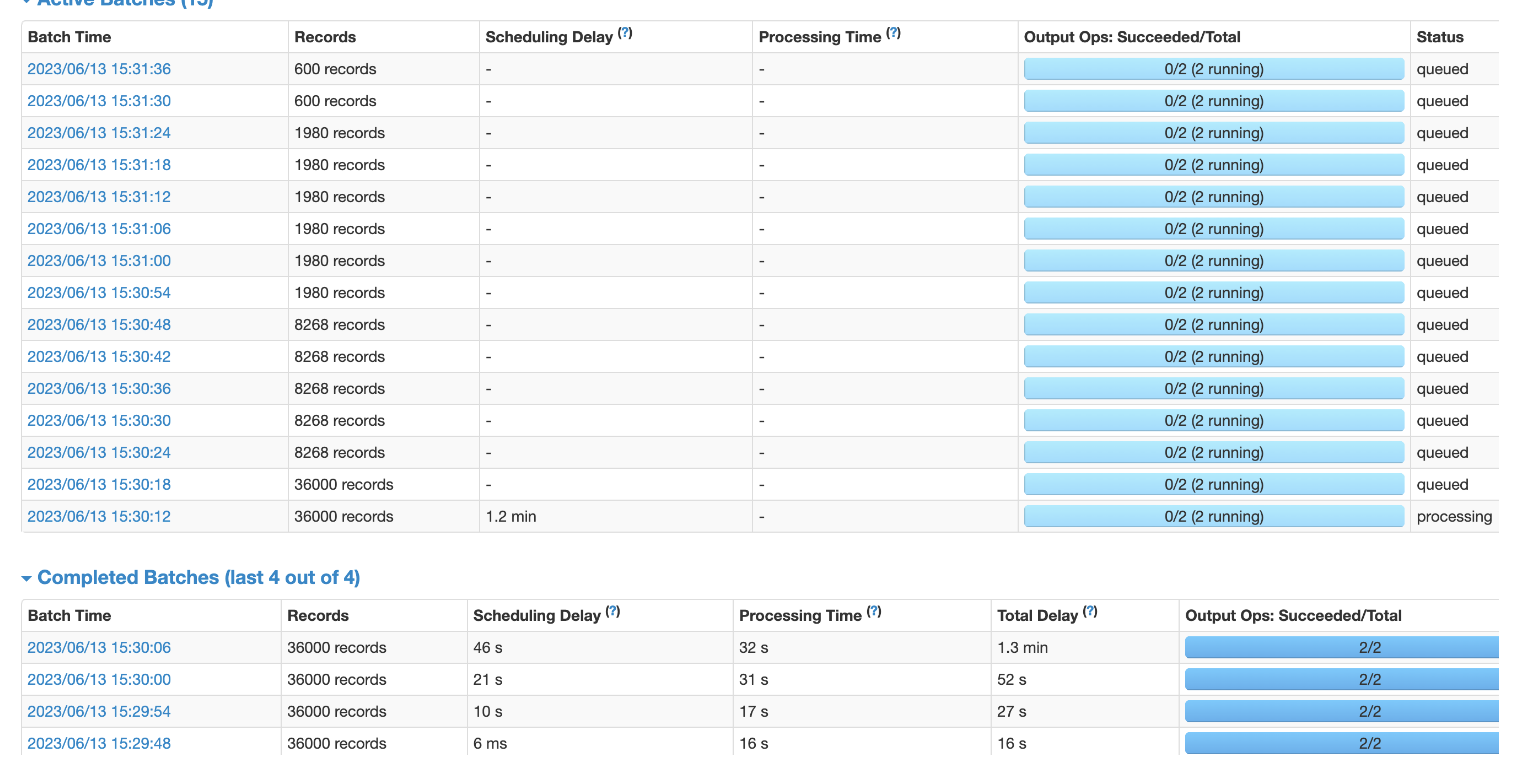

基本维持在1200多条/s,比之前的设置高了100条/s

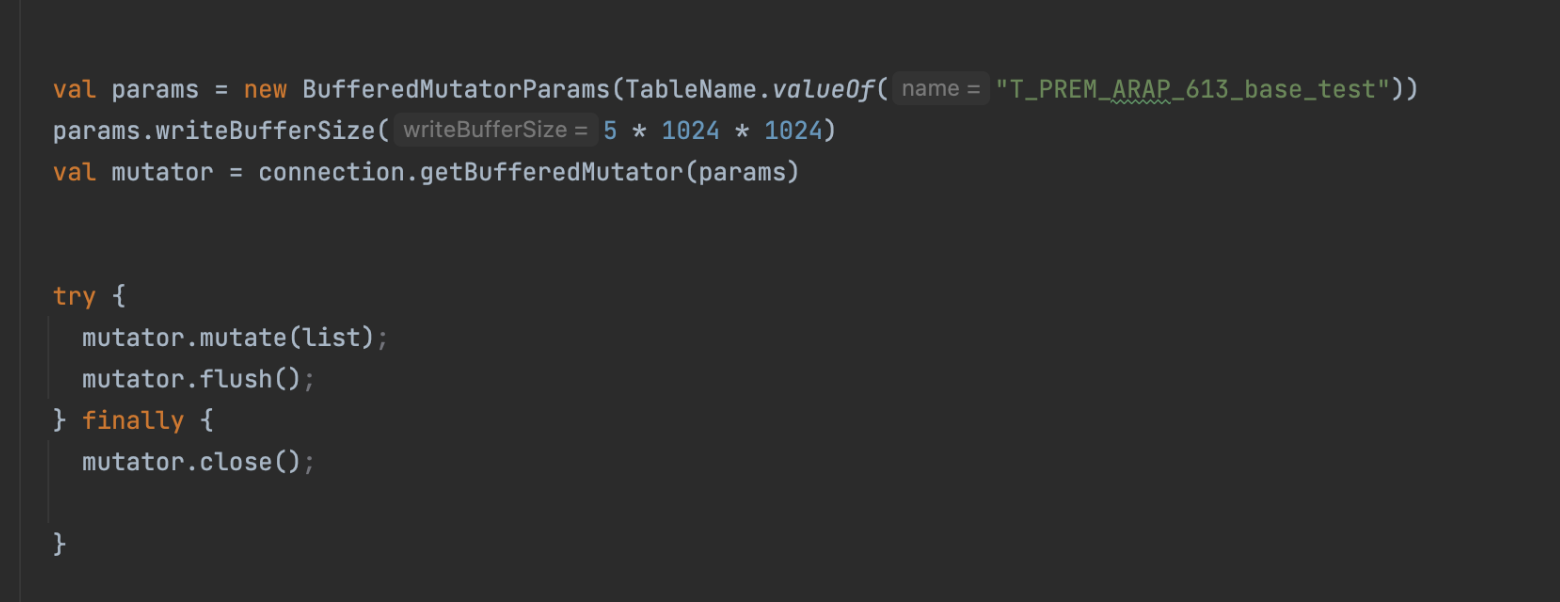
优化措施3(option): 修改hbase的连接池参数
hbase的连接池默认是1个,改为32个

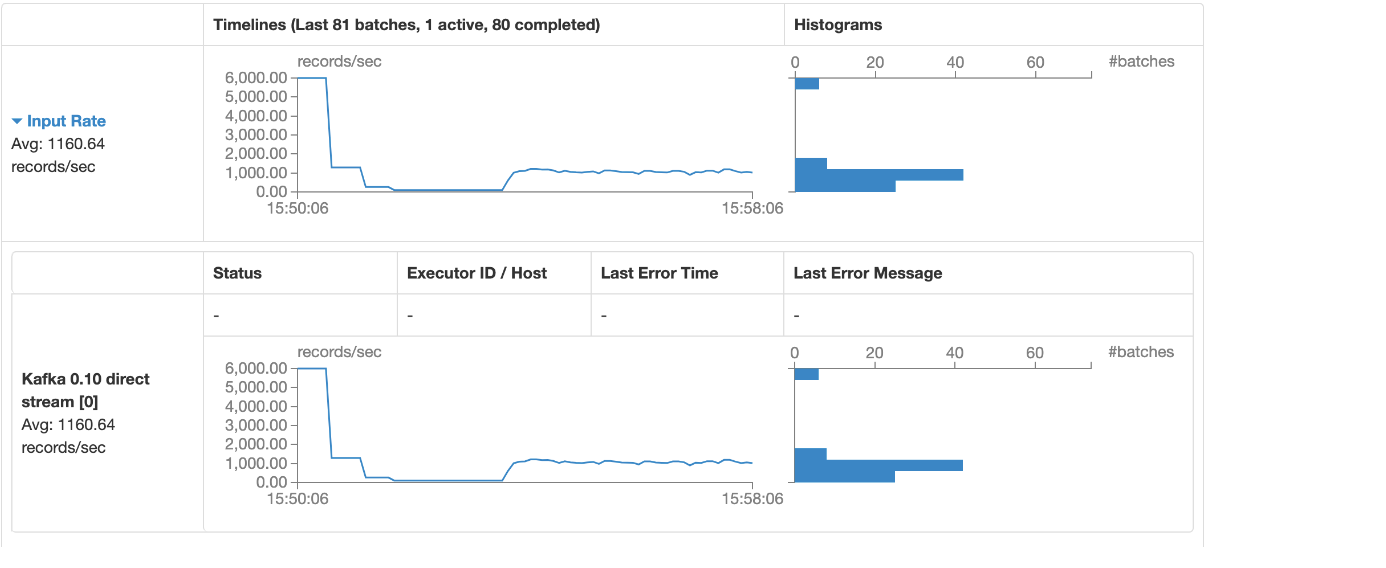
还是维持在1200左右
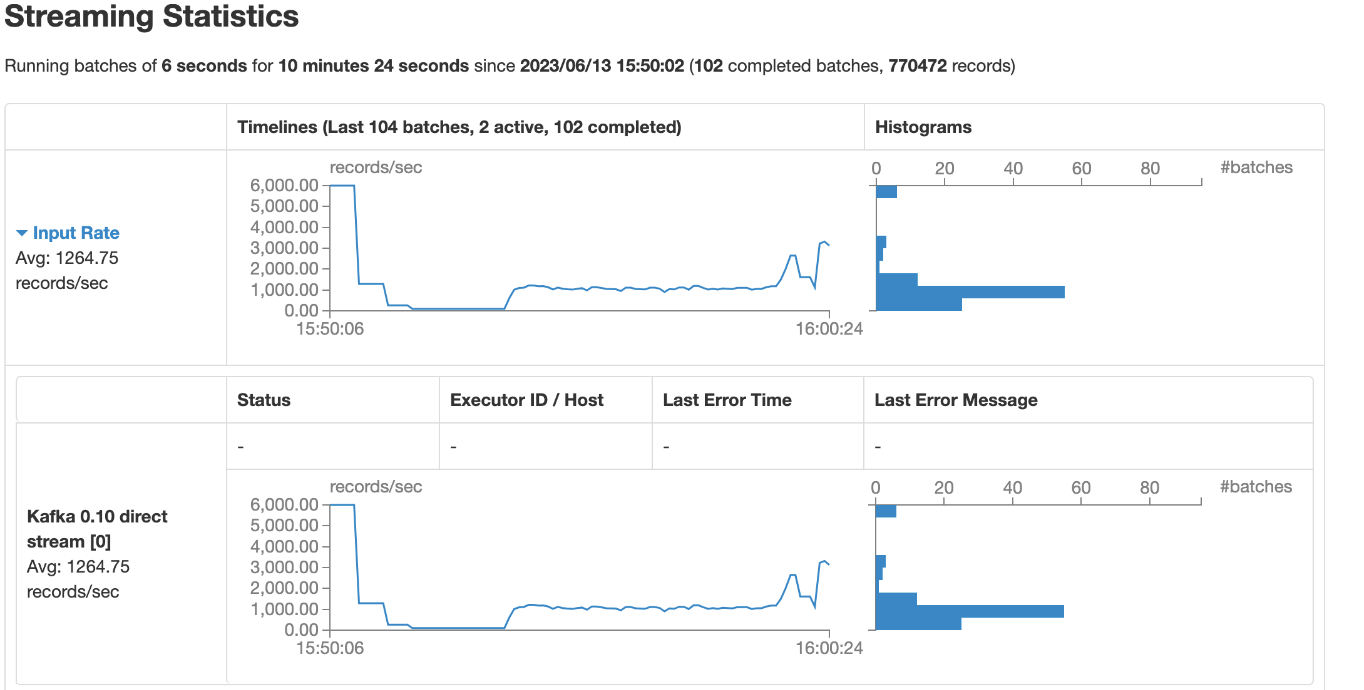
优化措施4:异步
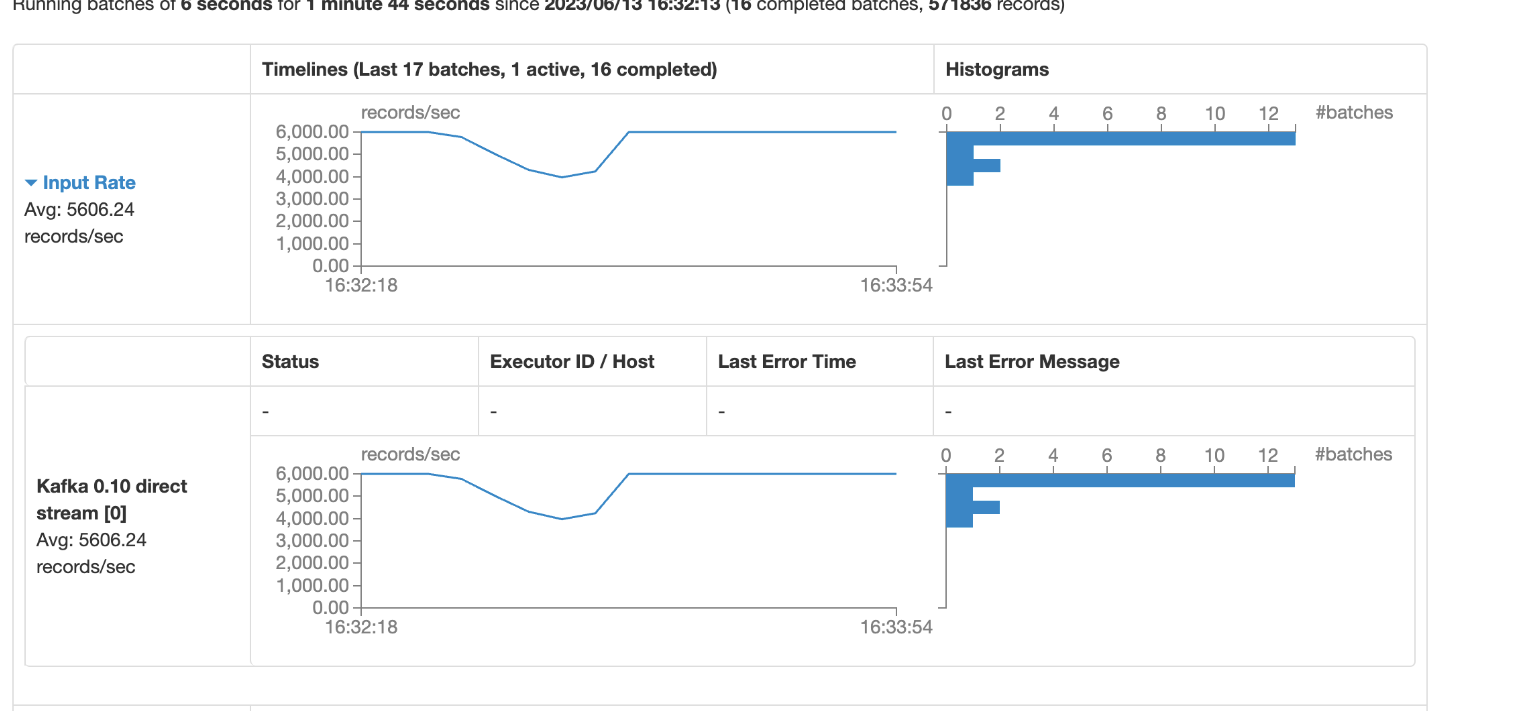
曲线下降平缓,
达到36000降低后又再次回到36000
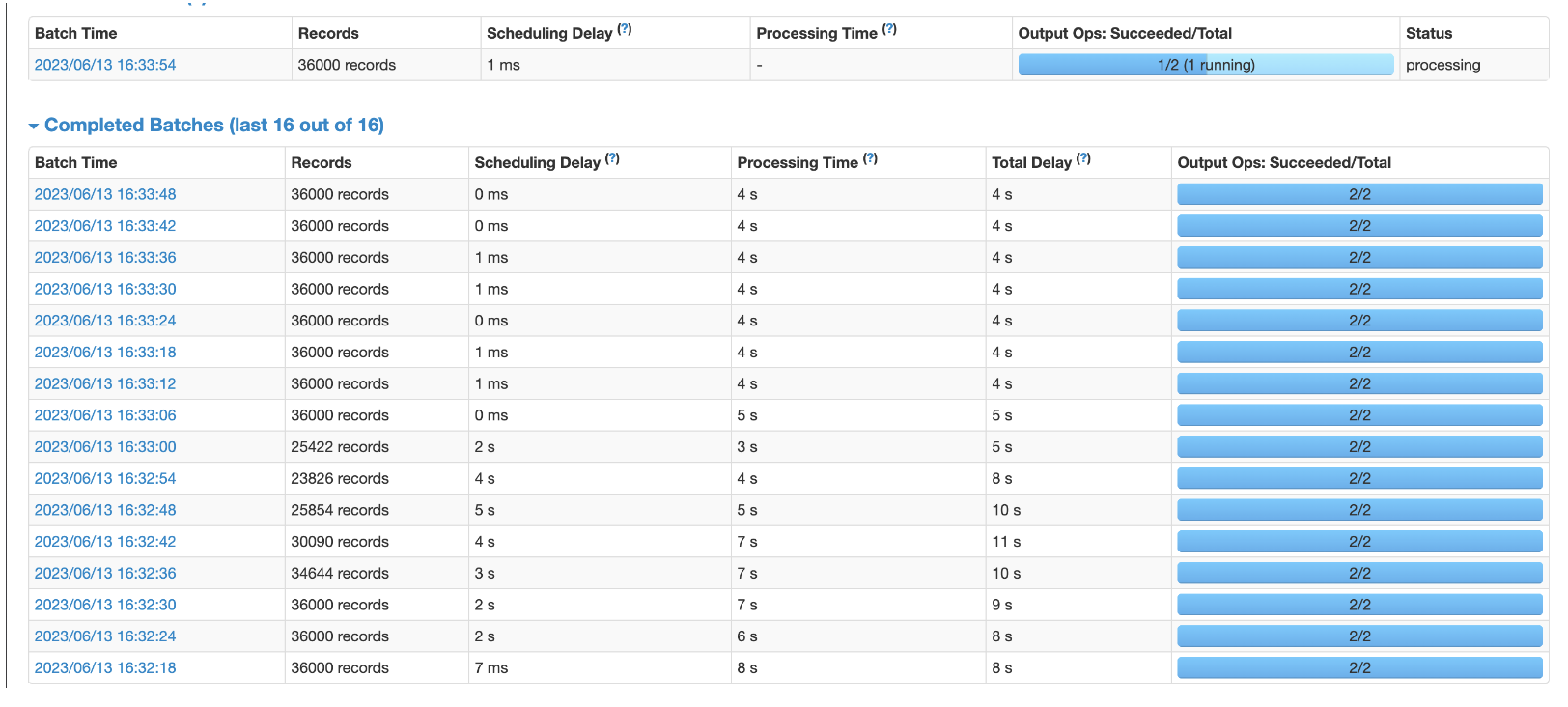
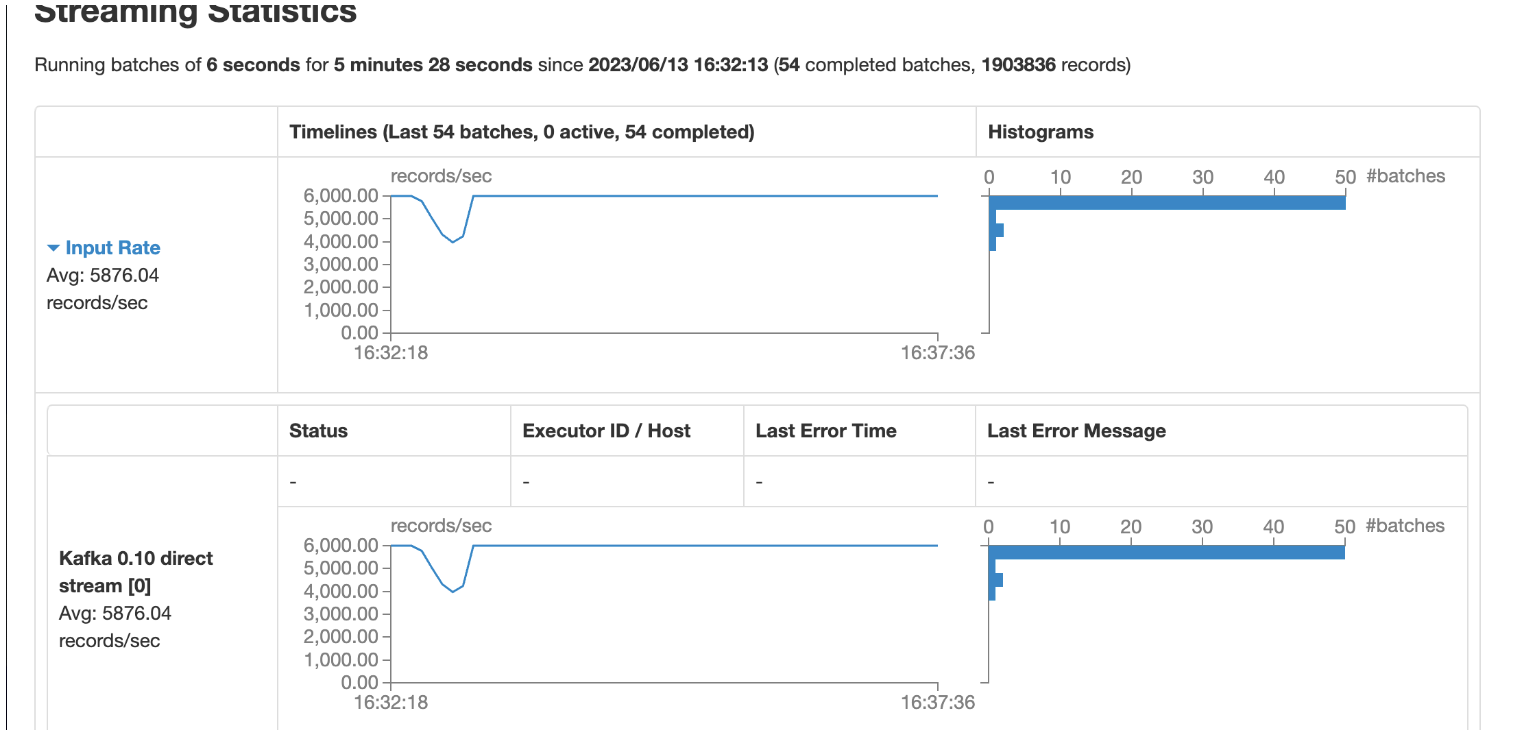
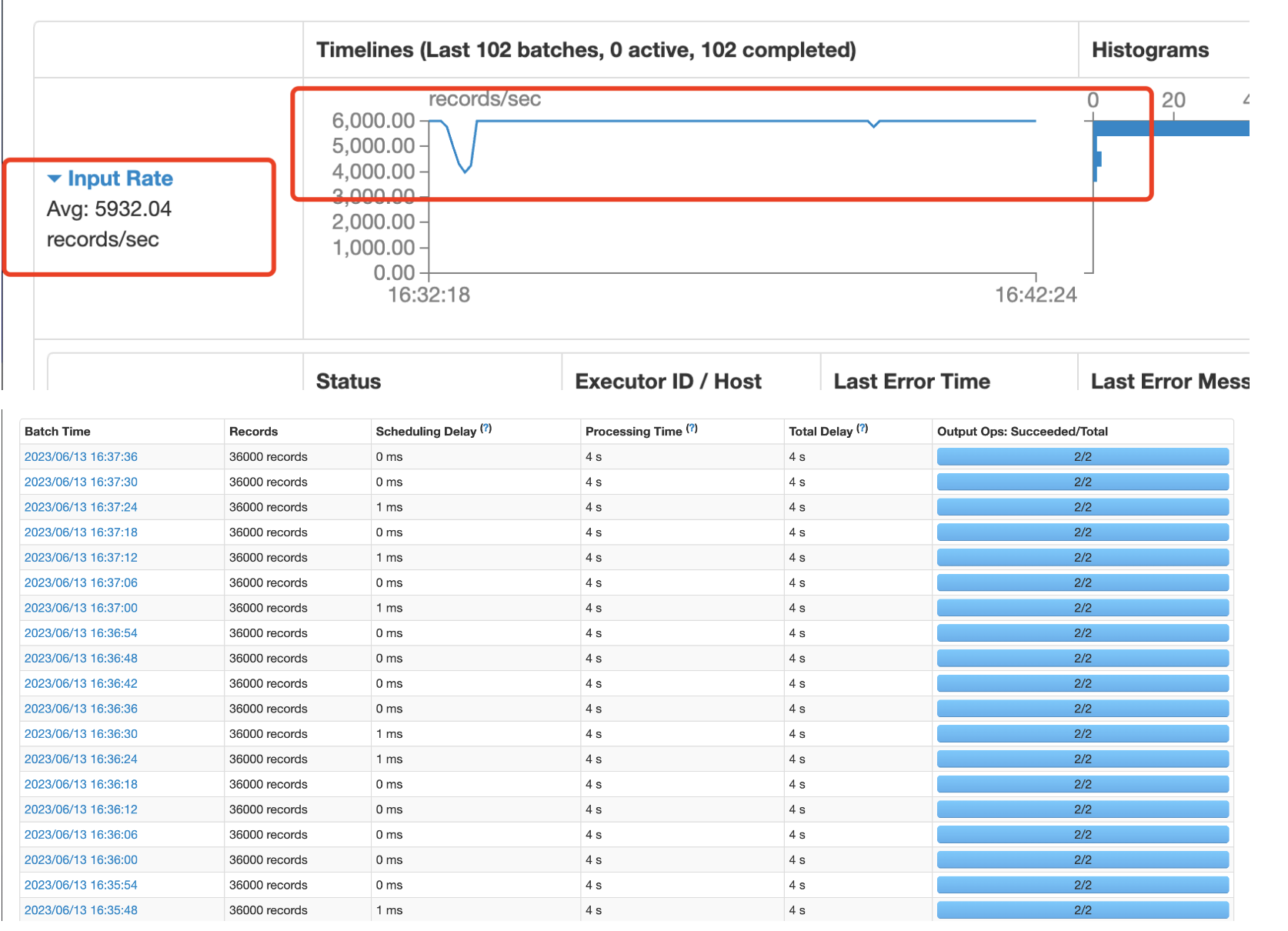
从上图可以看到,速度维持在5900+,且每个6秒一批次,都是正常完成处理.
总结:
优化措施1: executor-cores
优化措施2: 提高hbase表的预分区数
优化措施3(option): 修改hbase的连接池参数
优化措施4:异步