Large Language Model(LLM)的训练和微调
之前一个偏工程向的论文中了,但是当时对工程理论其实不算很了解,就来了解一下
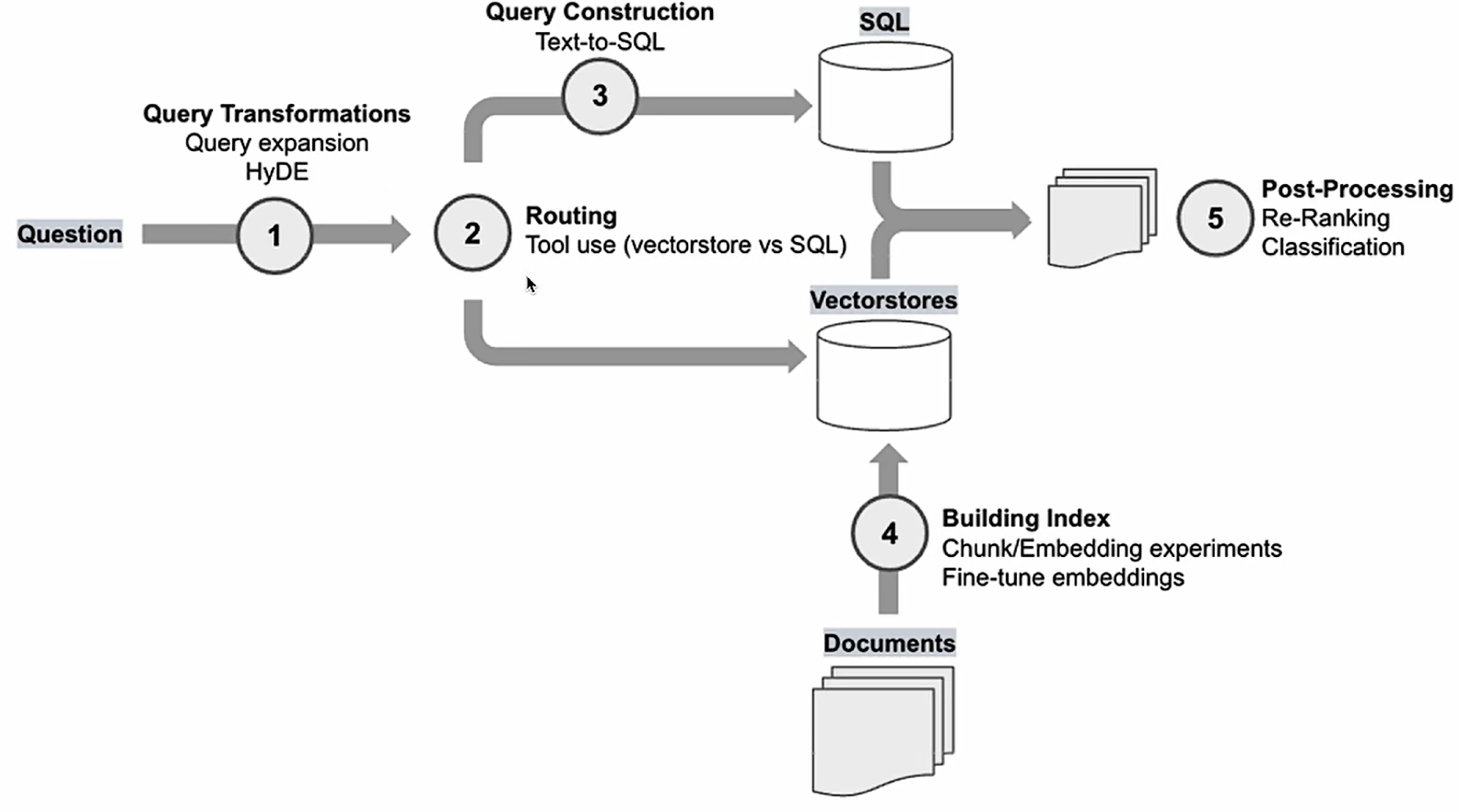
工程流程
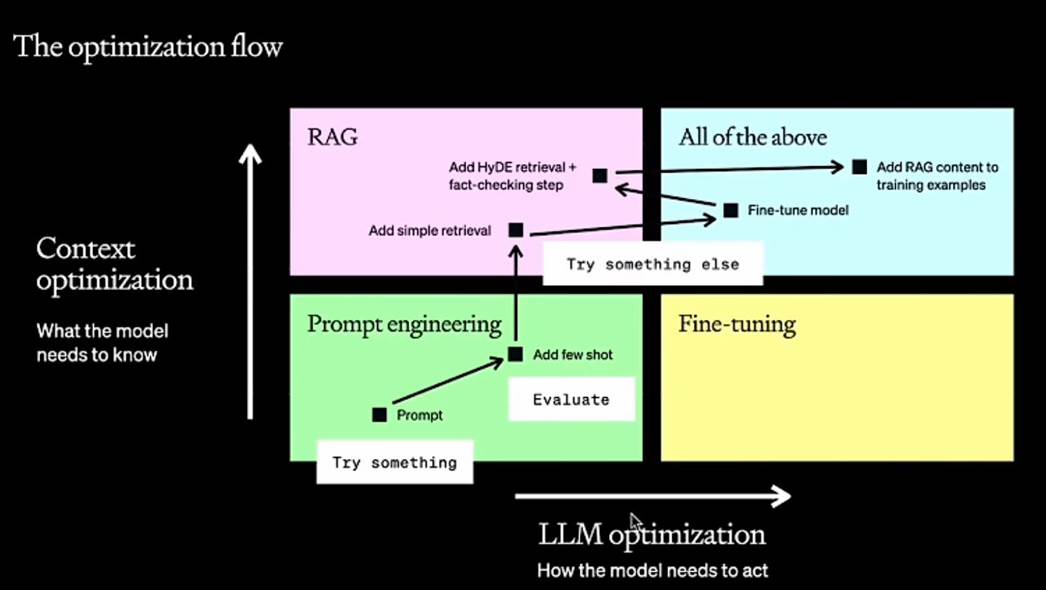
横轴叫智能追寻
竖轴上下文优化
Prompt不行的情况下加shot(提示),如果每次都要加提示,就可以试试知识库增强检索来给提示。
如果希望增强模型对知识的理解,就可以fintune微调一下
Fintune完了加更高级的检索
再最后再增加知识库
Step1:选底座
场景→列出10-50个场景问题→市面主流模型列出来→提示词+fewshot测试
Step2:增加RAG的业务知识
Step3:增加业务知识之后还不行的话那就微调
*一般情况下微调和知识库经常同时使用,时效性比较高的场景只使用微调不太合适
提示词工程使用:
给COT的Fewshot的方式


few shot 例子

如果COT测试场景效果很烂,那么需要fintuning或者换另外一个底座
RAG vs FT
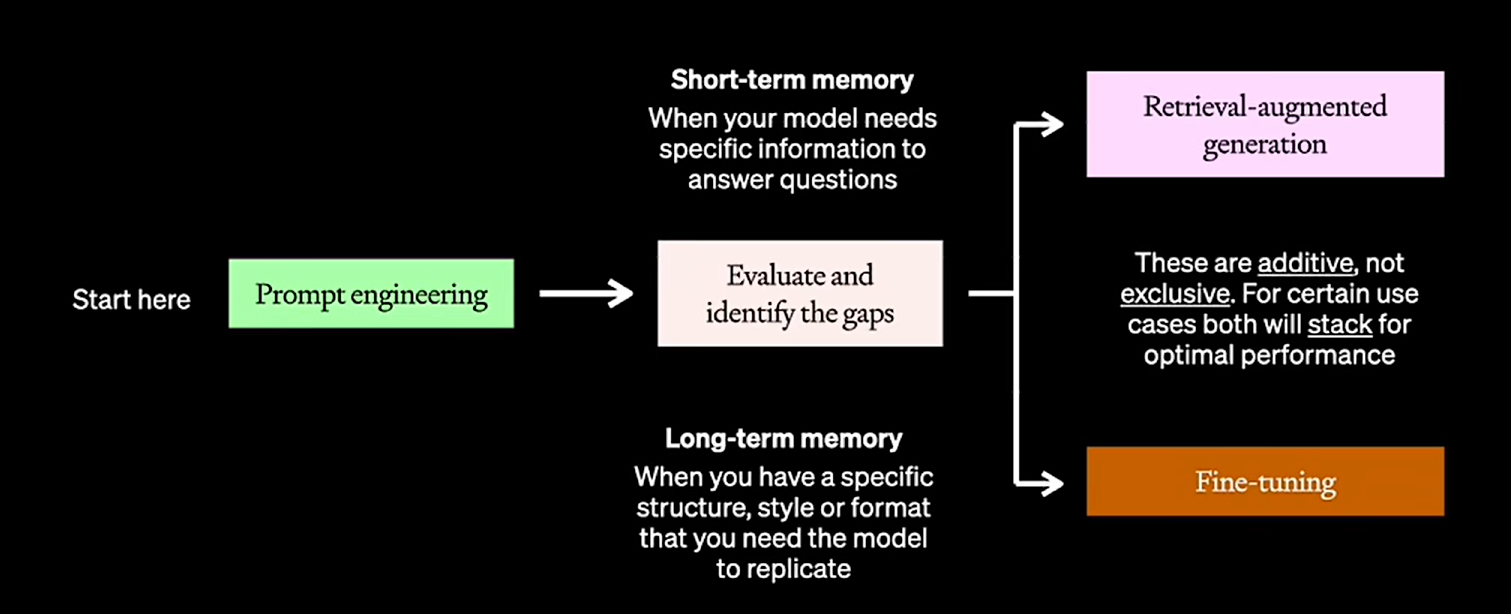
选完基座之后评估表现差多远,然后可以选择长期记忆还是短期记忆
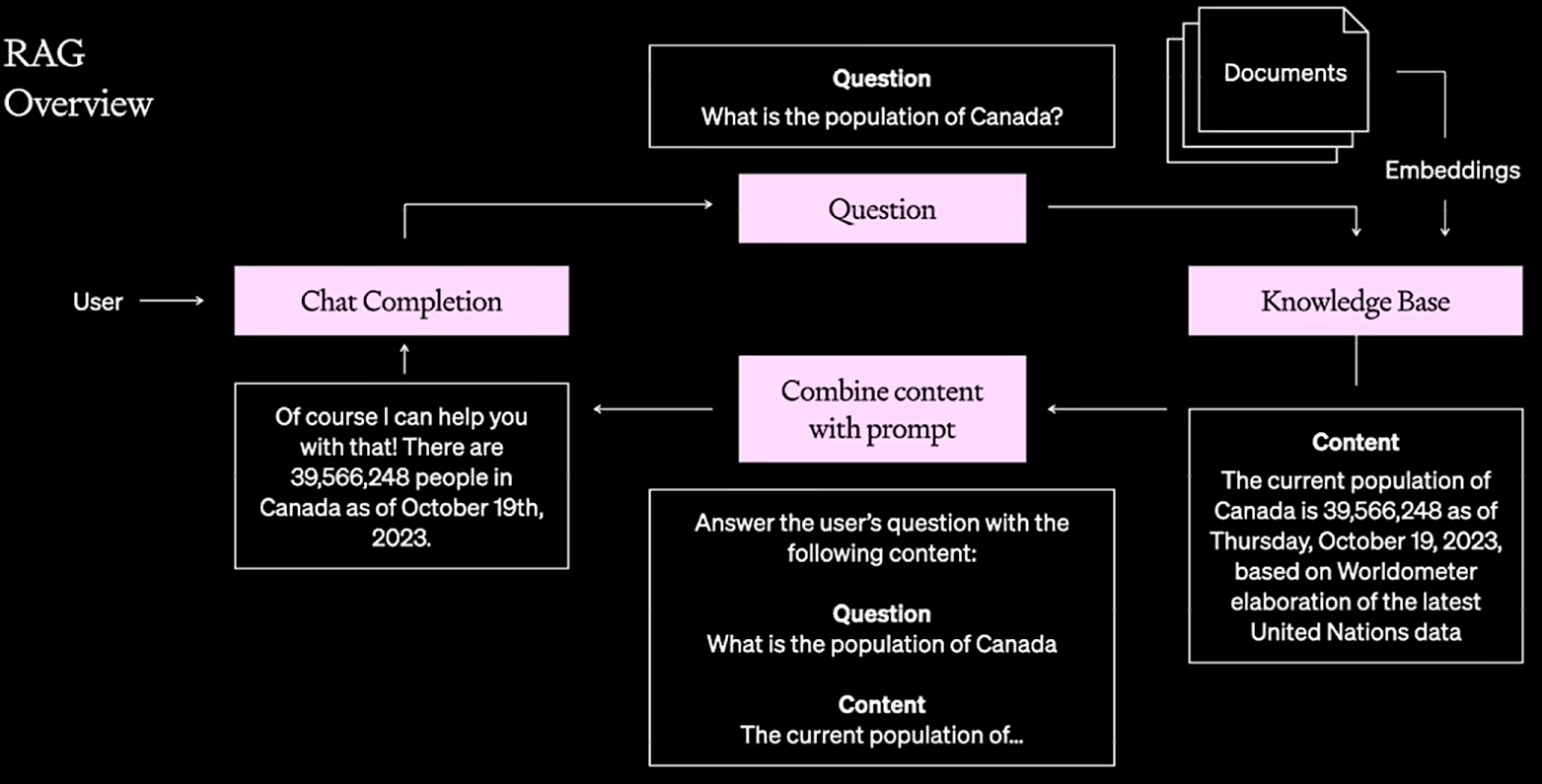
RAG框架
评估RAG框架
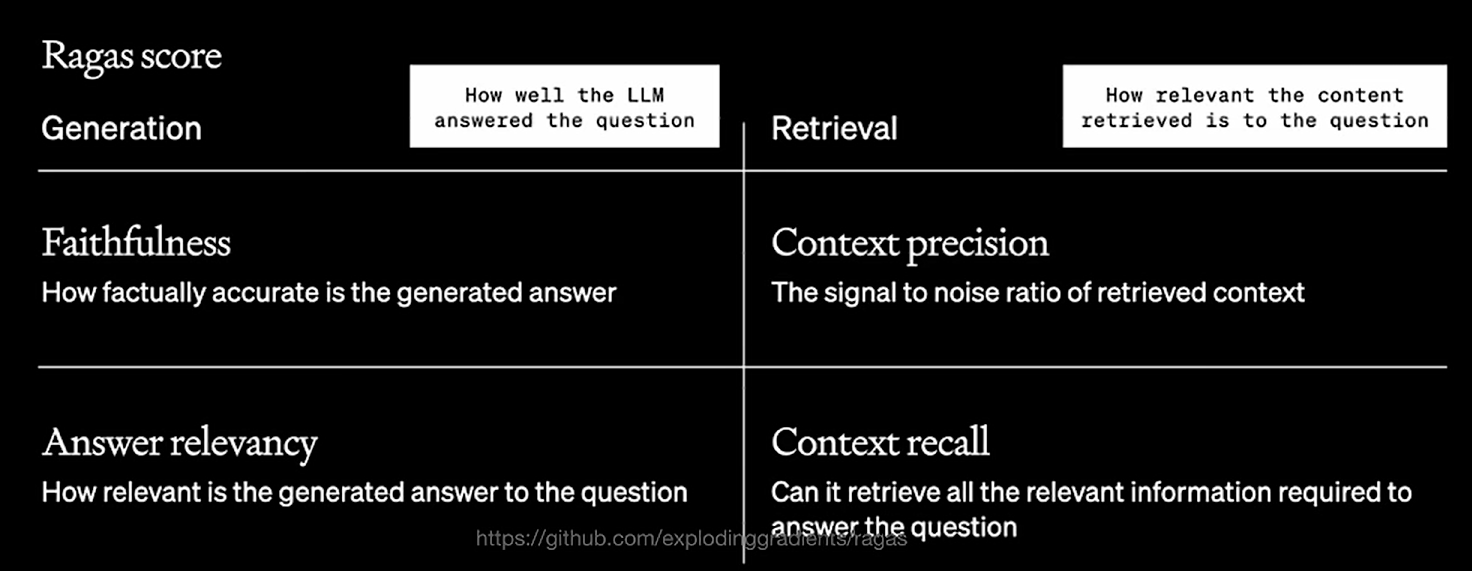
https://github.com/explodinggradients/ragas
FT前后对比
(节省不必要的token)


微调流程

agent
SFT(Supervised Fine-Tuning)
SFT 是最基础的微调方法,也是传统的“有监督学习”方法,尤其适用于有清晰标注数据的任务。
在预训练模型的基础上,让大模型能更好的用自己学到的知识来回答人提出的问题。 指令微调和原模型在网络结构上完全相同,loss基本相同,训练数据规模不同
SFT(任务)
├── 全参数微调(传统方式)
└── LoRA / Adapter / Prefix-Tuning / QLoRA(PEFT 方法)
基本思路:
- 在预训练的基础上,使用标注好的数据集对模型进行进一步训练。
- 目标是让模型更好地适应特定任务或领域,比如回答问题、文本分类、生成任务等。
典型流程:
- 数据集准备:准备任务特定的数据集(例如,人类写的问答对、情感分类标注数据等)。
- 微调:使用这些数据对预训练模型进行微调,通常会通过调整最后几层的权重。
- 输出优化:通过计算损失函数来优化模型输出,使其能生成更符合目标任务要求的结果。
优点:
- 适用于大多数任务,特别是需要解决特定任务的情况。
- 相对简单且有效。
缺点:
- 需要大量标注数据(这对一些任务来说可能成本很高)。
- 微调过程中,可能会丧失一些预训练过程中学到的通用知识,尤其是当训练数据和目标任务相差较大时。
| 概念 | 含义 | 作用 |
|---|---|---|
| Chat Template | 对话格式的模板,如用户和助手的标签、system指令的格式等 | 让模型识别多轮对话结构 |
| Completions Only | 只训练模型的输出部分(completion) | 提高训练效率、模拟真实生成行为 |
| NEFTune | 给词嵌入加噪声提升模型鲁棒性和泛化能力 | 增强模型稳定性、加速收敛 |
Chat Template 对话模板
在训练或推理时,如何组织多轮对话数据的模板格式、
LLMs(如ChatGPT)在处理多轮对话时,需要一个明确的格式来表示:
-
谁在说话(用户 or assistant)
-
说了什么
-
上下文是什么
对话开始的时候加上特殊的token,回答结束的时候也加上特殊的token

在SFT训练中,为了告诉模型“用户说了这些,你应该这样回答”,我们会使用chat template来把整个对话拼接成训练样本。不同模型(LLaMA、ChatGLM、Mistral等)有不同的chat格式,甚至prompt token也不同,所以需要提供“chat template”来适配模型的预训练格式。



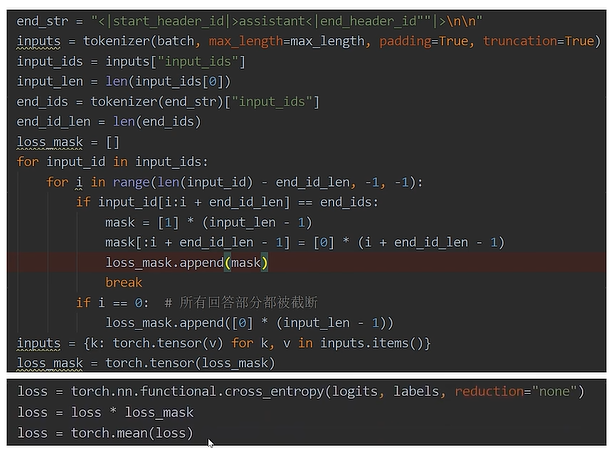
Completions only
这个是 一种 SFT 的训练范式,指的是只用模型的 输出部分(completion) 来计算 loss
在一个完整的 prompt + answer 对里:
Human: What is 2 + 2? Assistant: 4
-
Completion only 就是只让模型学习
4这一部分的输出(即只在Assistant:之后计算loss)。 -
Prompt 部分是不需要模型拟合的。

NEFTune (Noise Embedding Finetuning)
给embedding增加噪音的微调
这个是一个最近提出的 微调增强技术,主要用于增强模型鲁棒性和泛化能力。
🔬 原理:
-
在微调时,对词向量层加入一点小扰动(noise),模拟数据扰动,提升模型的泛化能力。
-
就像在图像任务里加随机噪声增强数据一样,NEFTune 给词嵌入也加“噪声”。
如果原始词嵌入是 E(x),那么训练时使用的是:
E(x) + ε
其中 ε 是一个小的高斯噪声向量。
论文:《NEFTune: Noisy Embeddings Improve Fine-tuning》
实现
调用trl库
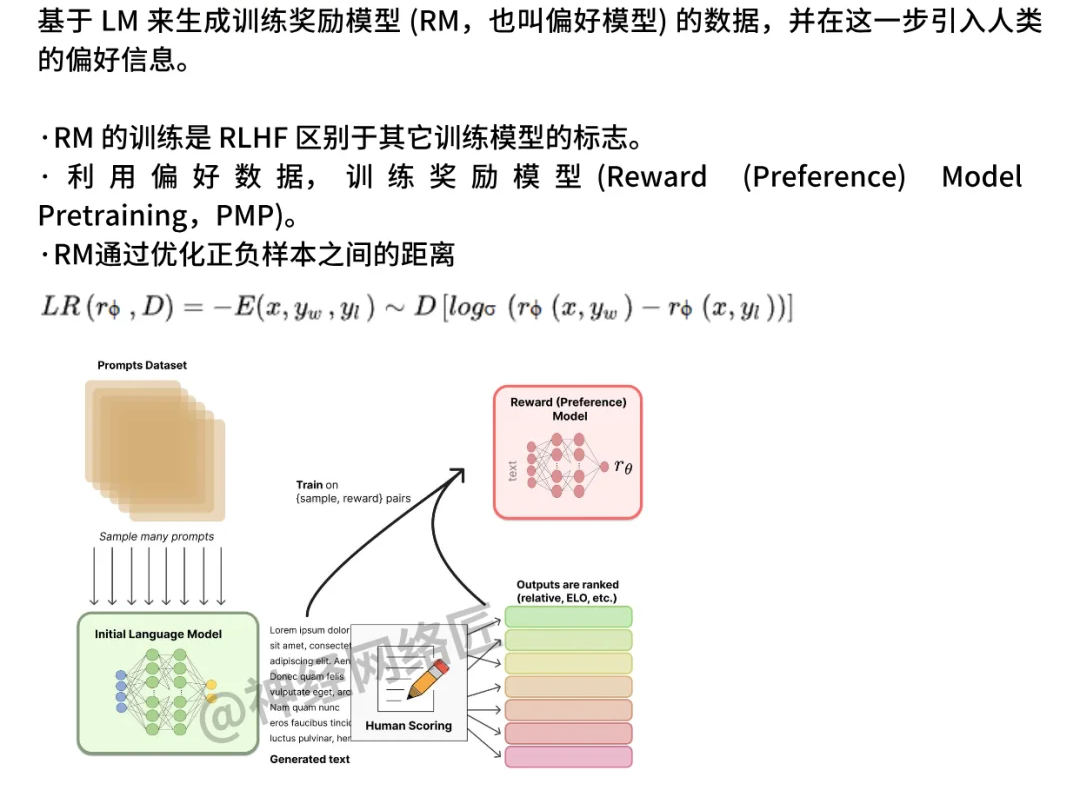
RLHF:Reinforcement Learning with Human Feedback
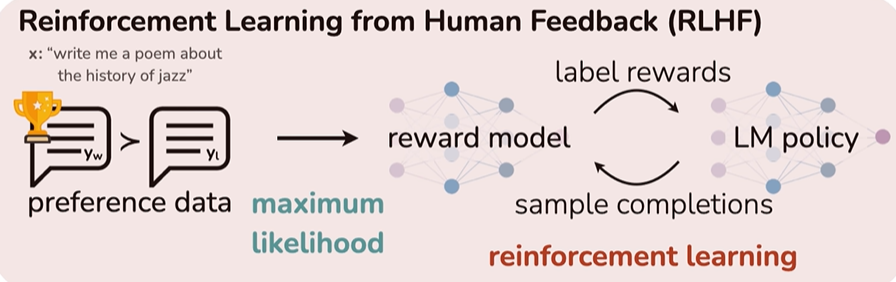
这是最早也最经典的“大模型对齐技术”。
流程可以简单理解为三步:
- SFT(Supervised Fine-Tuning):先用人类写的好回答,让模型学会基本说人话。
- Reward Model(奖励模型):训练一个模型,学会判断“哪个回答更好”。
- PPO(Proximal Policy Optimization):用强化学习方法(PPO)优化模型,鼓励它说更好的回答。虽然off-policy方法在样本效率上更有优势(可以重用历史数据),但PPO放弃这一点是为了换取训练的稳定性和可控性。在RLHF中,策略通常需要逐步适应人类反馈,而on-policy的每次更新都能直接反映当前策略的表现,更适合这种动态调整的过程。
ChatGPT(GPT-3.5)就是用RLHF训出来的
PPO(Proximal Policy Optimization)
PPO 是一种经典的强化学习算法,用于在 RLHF(Reinforcement Learning from Human Feedback) 中微调语言模型。
基本流程
预训练模型(SFT)
作为初始策略 π₀。
训练奖励模型(RM)
采样一堆回答,然后送进 奖励模型(RM)评估得分。
使用 RL(PPO)算法优化策略
使π在 RM 下的得分更高,同时避免偏离初始策略太远。
Loss

Advantage (A_t)优势函数:

我们无法直接知道这些值,因此:训练一个 Value Model 来估计 V(s)!
Value Model 的原理
-
输入:prompt(或者prompt + 输出的一部分)
-
输出:一个标量值 → 估计这个输入会得到多少“总回报”
-
使用的是回归目标(MSE):

本质上:Value Model 就是个评估器,让 PPO 知道“在哪些回答上继续优化”
on-policy:
-
因为你训练时必须 依赖于“当前策略 π” 采样出来的数据,不然这个比值和优势函数会不准确。
-
如果用老数据(旧策略采样的),策略更新方向会不对 → 训练不稳定甚至崩溃。
-
虽然 PPO 引入了“旧策略”的 loss function 来缓解策略变化带来的问题,但它仍然只能用刚刚采样出来的 batch 数据来更新当前策略,不能像 off-policy 那样“重用经验池里的旧数据”。
DPO:Direct Preference Optimization
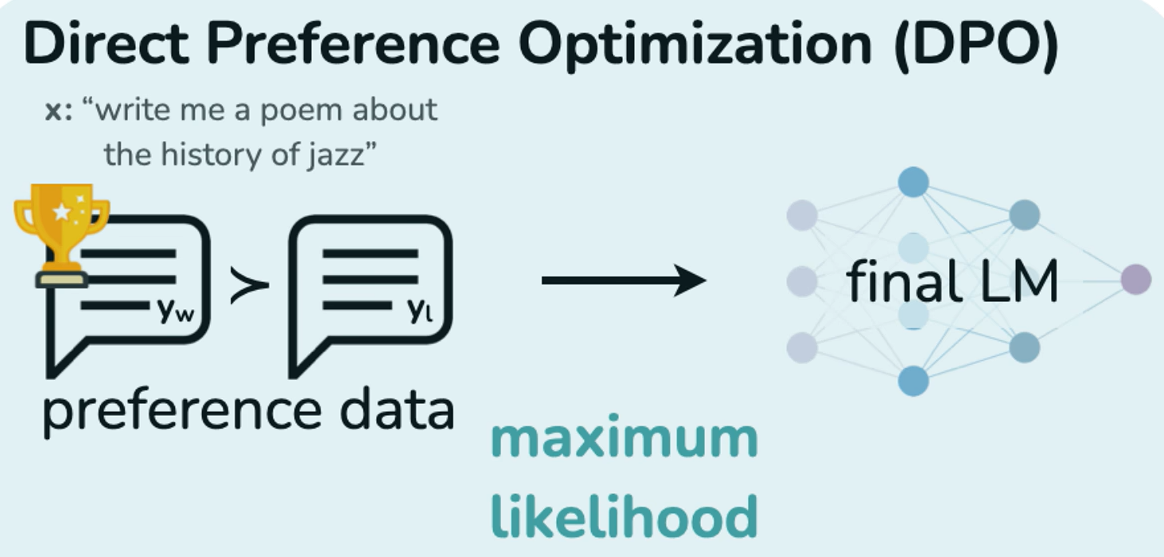
RLHF 太复杂了,reward model 和 PPO 都难搞。
于是有人提出:我们就直接优化模型让它更符合人类偏好,不用 reward model 和 RL 算法。
DPO 就是这样一个方法,直接基于“人类偏好对比数据”(哪个回答更好)来训练模型。
✅ 优点:简单,稳定,训练快,效果还挺好
🎯 所以很多新模型已经开始用 DPO 代替 PPO,比如 Anthropic 的 Claude、Mistral 的 Mixtral 都偏向这种思路。
背景知识
KL散度

Bradley-Terry 模型


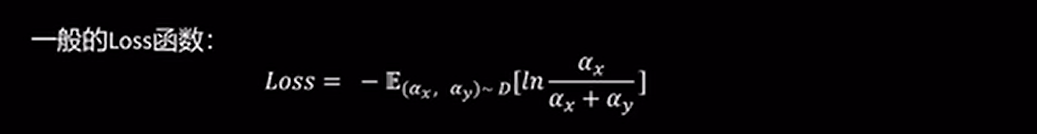
优化目标:x战胜y的概率越趋近于1越好

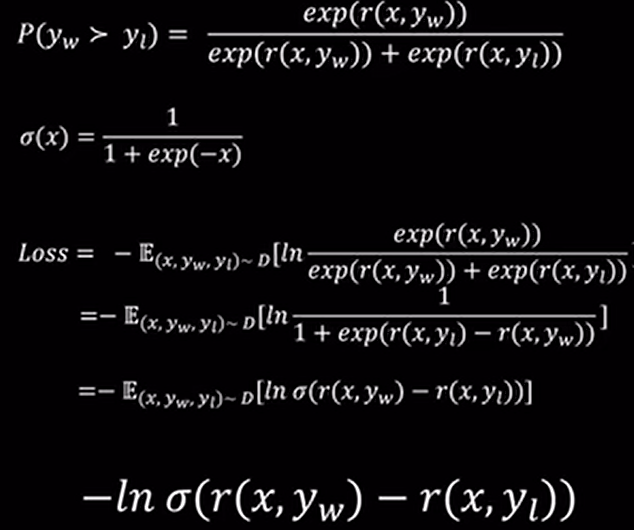
数据构造
DPO 依赖的是**比较数据(preference data)**而不是打分,因此构造偏好数据的关键是:选择 pair,标注偏好。
✅ 常见构造方式:
| 方法 | 描述 | 说明 |
|---|---|---|
| 人工标注 | 给定 prompt 和两个回答,让人选出更好的那个 | 最可靠但最贵 |
| GPT-4 辅助打分 | 用 GPT-4 或 Claude 给出比较意见(谁更好) | 快速、成本低、易偏差 |
| 评分转偏好 | 先对回答打分(如 1-5 分),再转化为偏好 | 可批量自动构建 |
| 多样化采样 | 从多个模型或策略中采样生成不同回答,再两两比较 | 增强数据覆盖面 |
| Pairing with ranking | 利用多个样本打分再排序 → 生成 pair | 适用于 GRPO 或 Soft-DPO |
🔧 技巧与经验:
-
尽量构建 hard pair(两个回答都还不错,差距不大)比 easy pair 更有信息量
-
数据构造建议搭配 初始模型与目标模型的策略分布采样,能更稳定收敛
-
多个偏好数据来源混合(人标、GPT辅助、评分)也能提升泛化性
-
对抗式 sample(故意制造模糊、诱导、奇葩case)可以提升鲁棒性
训练目标
虽然 DPO 不使用显式 reward model,但其实它隐含了一个 reward function

KL散度约束新旧模型的一致性
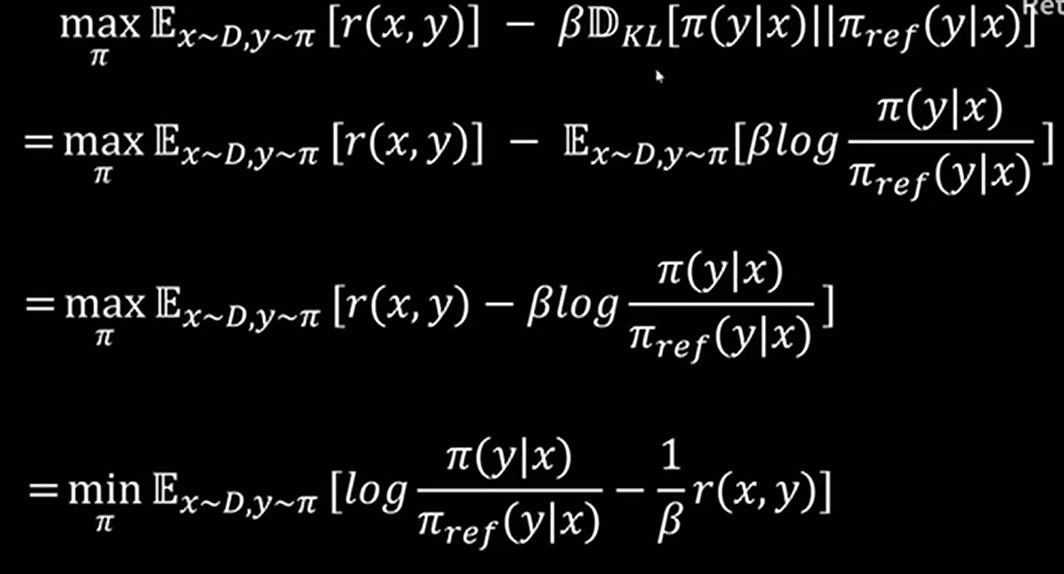
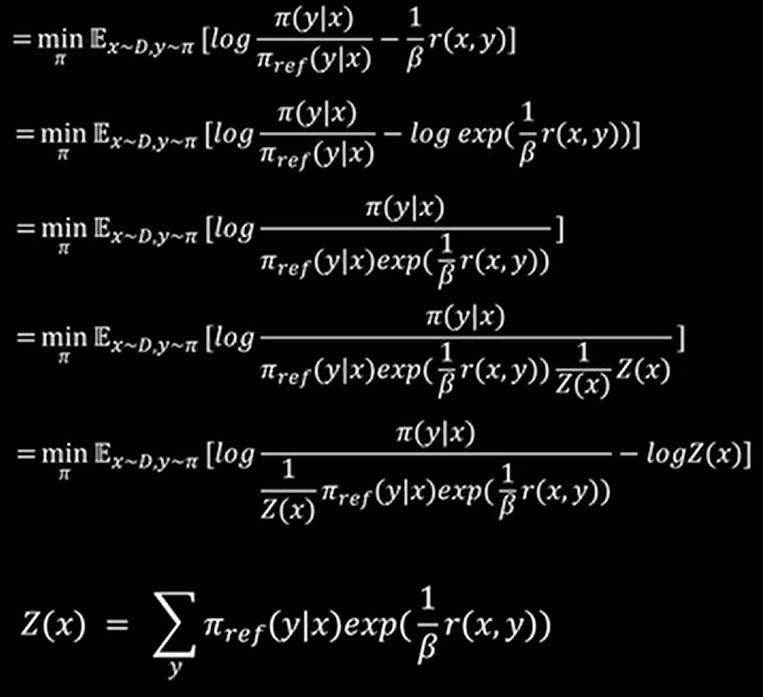
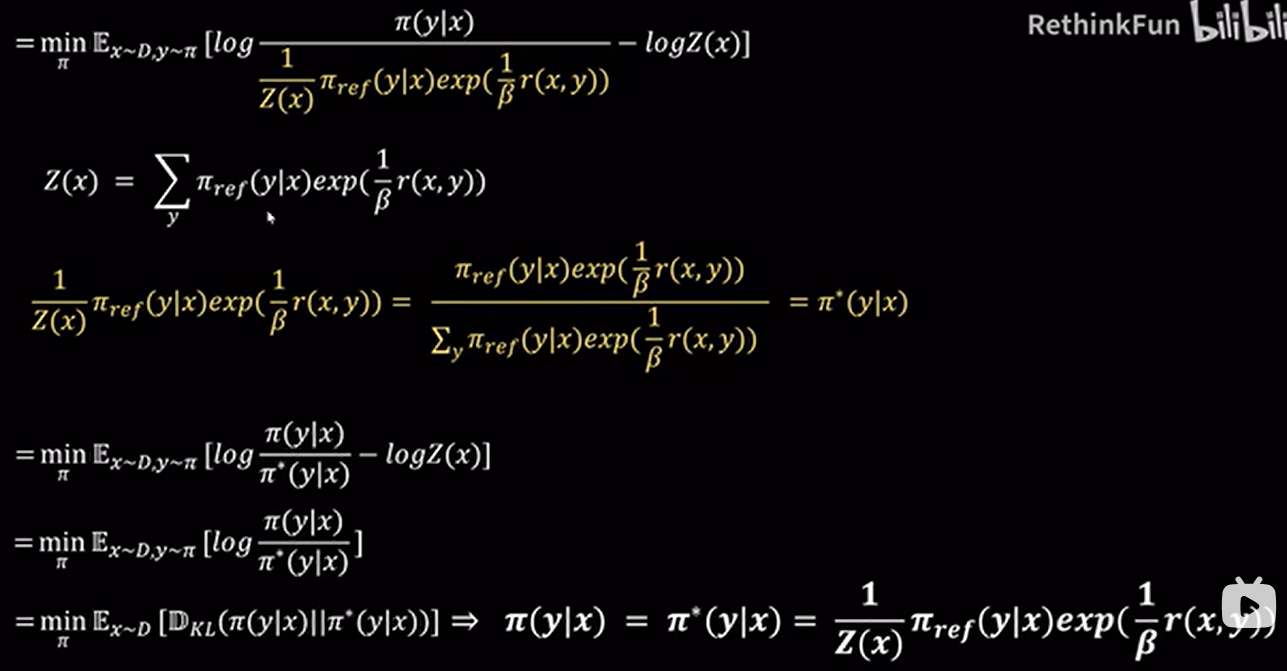
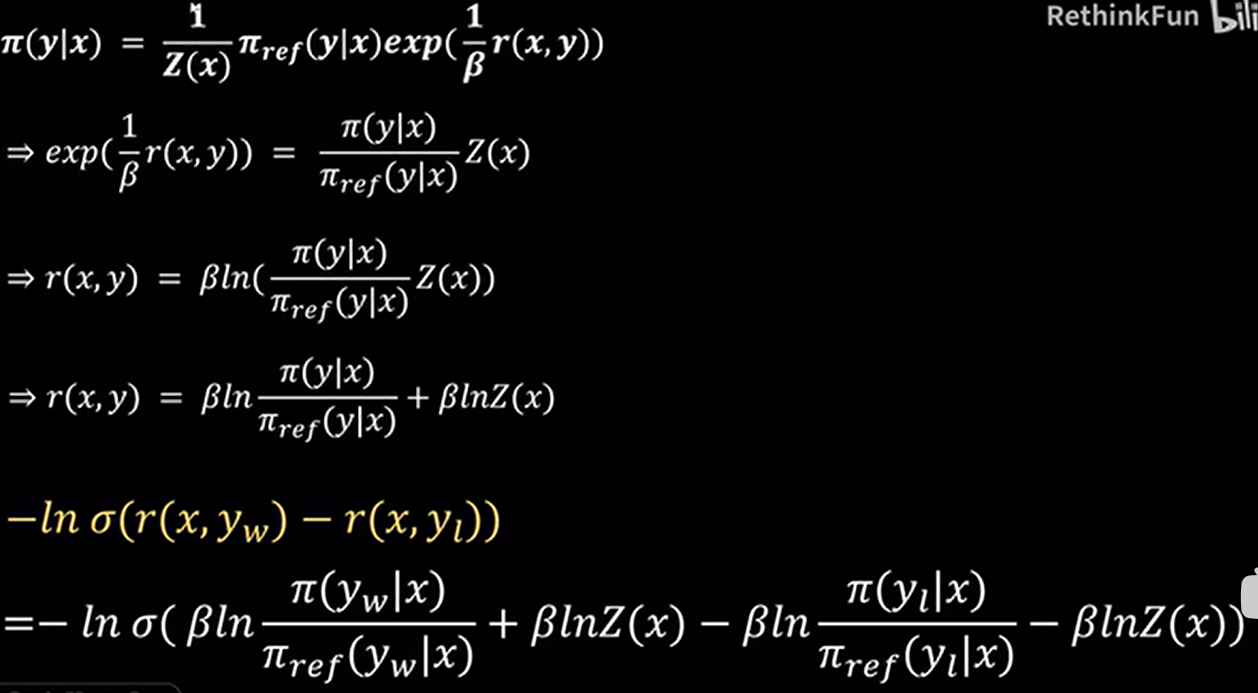
DPO Loss:
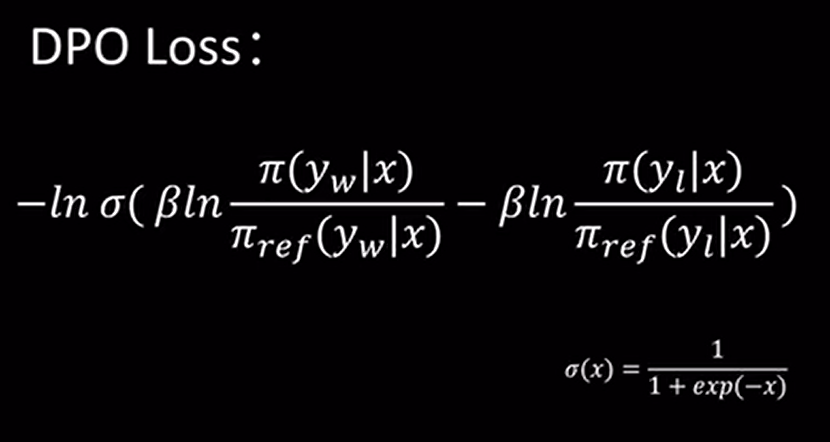

DPO vs PPO
| 项目 | PPO | DPO |
|---|---|---|
| 类别 | 强化学习(RL) | 监督学习范式(偏好对比学习) |
| 是否需要 Reward Model | ✅ 需要 | ❌ 不需要 |
| 输入形式 | prompt + 单个输出 + reward score | prompt + 两个回答(好 / 差) |
| 训练目标 | 最大化 reward,同时不偏离原策略 | 最大化好回答的 logit 分数 > 差回答 |
| 优点 | 稳定、成熟、理论支撑强 | 简单直接、无需训练 reward model、易用 |
| 缺点 | 复杂、训练成本高、reward model 容易偏 | 对偏好数据质量敏感、无显式 reward 可解释性 |
| 代表性使用场景 | ChatGPT、InstructGPT | DPO paper、一些开源RLHF项目如 TRL库 DPO 示例 |

π(target policy) π₀(reference policy)
PPO:显式构建 reward
偏好数据 y⁺ ≻ y⁻ 👉 训练 Reward Model,使其输出
r(y⁺) > r(y⁻)
这个 reward 被当作 PPO 的 r_t,再带入标准的 policy gradient:
![]()
DPO 干脆跳过显式构建 reward,直接训练策略模型:
我直接用 log π(y⁺) - log π(y⁻) 当作隐式 reward 差值
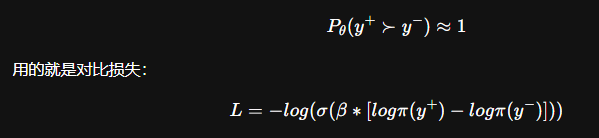
这正好就是一种:
-
近似最大化
E[r] -
同时加了对初始模型
π₀的 KL regularization
直接构建了训练目标,绕开了 reward 模型
GRPO
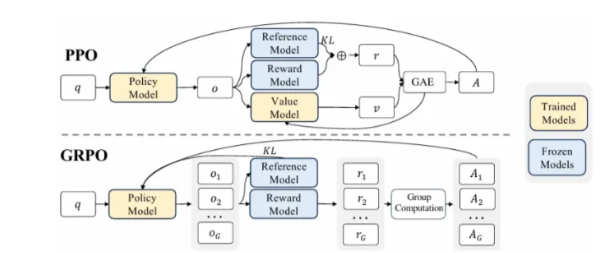
GRPO 是deepseek新提出的偏好优化方法,是 DPO 的升级版,它:
-
推广了 DPO:允许 reward 不再是隐式的对比形式
-
使用更加灵活的偏好概率模型:
![]()
-
可以用不同形式的 reward,甚至融合其他信号(如评分 + 比较)
如果 DPO 是二分类损失,GRPO 更像广义对比学习框架。
| 特性 | DPO | GRPO |
|---|---|---|
| 偏好方式 | 固定为“y⁺ ≻ y⁻”形式 | 可扩展为打分式、多选式、soft-preference 等 |
| reward 计算方式 | 隐式 reward(log prob 差值) | 显式 reward:r(y) 可以是任意函数或外部得分 |
| 训练方式 | 对比学习 + sigmoid loss | 更泛化的策略优化目标(支持不同形式 reward) |
| 应用场景 | 文本偏好对 | 多模态(如图文),长文本,soft ranking 等 |
DAPO
解决了GRPO会遇到熵的坍塌等问题
DAPO 是一种新型的强化学习算法,主要特点包括:
-
解耦裁剪(Decoupled Clipping):分别对高概率和低概率区域使用不同的裁剪策略,以防止策略更新过大导致的不稳定。
![]()
-
动态采样(Dynamic Sampling):在训练过程中动态选择具有信息量的样本,避免无效样本对训练的干扰。
-
Token-Level Policy Gradient Loss:在 token 级别计算策略梯度损失,提升对长序列的优化能力。传统 RL 方法对整个 output sequence 求 reward,然后算个 sequence-level advantage。而 DAPO 切到 token-level loss,这像是不再用 sequence 这个粗粒度单位训练,而是对每一个 token 做微观调节。它和 layer norm / token norm 一样,本质是“对单元粒度做独立归一”,减少梯度振荡、提高模型感知能力。
-
Overlong Reward Shaping:对过长的生成结果进行奖励塑形,减少奖励噪声,提高训练稳定性。
我感觉其实全文透露着一种normalization的思想
| DAPO 技术点 | 体现出的 Normalization 哲学 |
|---|---|
| Decoupled Clip | 对不同 token 的学习幅度进行动态归一/约束 |
| Dynamic Sampling | 对样本的信息贡献度进行归一处理,引导高效训练 |
| Token-level Gradient | 把 sequence 的整体奖励拆成 token 单元,细粒度归一 |
| Overlong Reward Shaping | 避免极长输出 reward 爆炸,类似于梯度 clipping / 激活规整 |
RLAIF:Reinforcement Learning with AI Feedback
RLHF 里人类要一直标注数据,很费钱。
那有没有可能,用另一个大模型来充当“人类”,给出偏好选择呢?
RLAIF 就是这个意思:
“用 AI 模拟人类反馈,再用 RL 方法优化模型”。
比如:拿 GPT-4 来帮你给一些小模型打分,模拟人类反馈。这样可以省下大量人力标注。
Lora
LoRA 并不直接调整模型的所有参数,而是引入了一个低秩矩阵(通过降维方式),在原有网络层之间插入适应层,更新这些适应层的权重
优点:
- 参数更新量小:不需要对整个模型进行微调,仅调整部分适配矩阵。
- 效率高:尤其适合参数量非常大的大模型,能够快速适配不同任务。
- 灵活性强:LoRA 可以与其他方法结合,尤其是在大模型的多任务学习中很有优势。
缺点:
- 相比于全模型微调,可能无法完全捕捉到复杂任务中所需的细节。
- 对任务的依赖性较强,需要根据任务特点调整 LoRA 的使用方式。
训练
预训练模型的权重更新(从通用知识到任务特定知识的转变)可以用一个低秩矩阵来近似表示。具体来说:
- 假设:权重矩阵的更新 ΔW(任务适配带来的变化)具有低秩结构,即可以用两个小矩阵的乘积来表示,而不是直接更新整个权重矩阵。
- 实现:在原始权重矩阵 W 上添加一个低秩更新矩阵 ΔW = A × B,其中 A 和 B 是两个低维矩阵,秩(rank)远小于原始矩阵的维度。

推理时:你可以选择:
-
把 LoRA 的矩阵合并到原模型上,得到一个新的权重
-
或者保留插入结构,在推理时保持低秩路径(节省内存)
在使用 LoRA 等低秩调整方法时,会优先选择调整 Query 和 Value,而不是 Key,
-
在 Self-Attention 机制中,输入的每个元素都会通过与其他元素的 Query 和 Key 计算相似度来生成注意力分数(Attention Scores)。这些分数会与 Value 相乘,得到最终的输出。
-
Query:用于与其他元素计算相似度,决定哪些信息在生成过程中更为重要。
-
Value:决定了模型最终输出的内容,是所有输入信息的加权平均。
-
Query 和 Value 直接参与注意力计算,它们的变化会直接影响模型生成的内容。通过调整这些部分,可以在保留原有模型架构的同时,优化模型对输入信息的理解和生成能力。
-
Key 更多地用于计算注意力分数,决定了哪些信息会被关注,但并不直接决定输出的内容。调整 Key 相比之下,对模型的生成效果影响较小。
LoRA 也可以配合其他训练任务使用:
-
LoRA + PPO(强化学习微调)
-
LoRA + DPO(偏好优化)
-
LoRA + 蒸馏(Distillation)
但最常见的场景是 LoRA + SFT,尤其是在训练资源有限或多个任务微调时非常高效。