Linux——文件(3)软硬连接和动静态库
一、软硬链接的引入
在windows中,我们安装一个软件时,桌面上往往都会有一个图标,双击这个图标我们就可以打开对应的程序,实际上,这个图标并不是可执行程序本身,而是一个快捷方式
这些快捷方式记录着目标程序的目录位置,当我们打开快捷方式它就会找目标文件并打开。在Linux中,软链接就是快捷方式的作用,在Linux中我们使用一下命令创建某文件的快捷方式。(软链接)
ln -s 目标文件名 重命名
![]()
我们发现目标文件和快捷方式的inode不同,说明其本质是两个不同的文件(软连接是一个独立文件,保存的是目标文件的路径。
至于硬链接的命令,只需要把-s的选项去掉即可。但当我们创建硬链接时,我们发现 一个现象:
![]()
硬链接与文件的inode相同,且权限后面的数字都变成了2.所以,硬链接不是独立的文件,本质是一组文件名和已存在的映射关系。至于这个数字代表着什么?其实inode中有一个引用计数的变量,相当于记录着有多少条路径指向着该文件,图中的2就是说明有两个文件名指向同一个文件了。此时,我们就可以把目标文件file.txt删除,虽然会影响软连接,但硬链接还是会存在,也就是说硬链接也可以实现重命名的操作。包括我们目录的隐藏文件.与..我们通过inode对比发现其就是通过软硬链接完成的指令。
注意:目录是无法被创建硬链接的,容易造成闭环路径。
二、动态库和静态库
我们之前提到过,动静态库无非就是把库放在云端和本地使用以及所占空间的区别,但我们今天的重点不在这里,我们要尝试手动制作一个静态库并调用。
1.手动制作静态库的几种方法
首先,我们要写几个.h和.c文件的实现,我们需要把.c文件隐藏,把.h文件暴露出来。
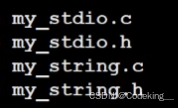
隐藏方法,我们只需要把.c编译成.o文件即可
gcc -c my_stdio.c (生成同名.o)
接下来我们要把所有.o文件打包形成静态库
ar -rc 库名 要打包的文件
关于库名的要求,前缀必须是lib后缀必须是.a,比如libmystdio.a

这样别人想使用只需要把库和.h文件传给他并安装即可使用。那么,对于其他人来讲,如何安装到自己的库中?
我们一般把.h文件都拷贝在/usr/include/目录下(下载的本质就是拷贝)
![]()
这是拷贝后的结果。至于如何下载库,一般把库拷贝到/lib64/下
sudo cp libmystdio.a /lib64/
这样就成功安装到系统中正常使用了。
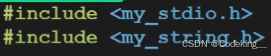
但当我们写完代码后编译时发现报错了?我们明明把库安装到系统中了。
![]()
这是因为我们安装的库属于第三方,系统并不认识,无法完成链接,只认识默认的C/C++标准库,为了解决这个问题,我们介绍gcc的一个新选项
gcc xxx.c -l+库名 例:gcc main.c -lmystdio
库名要去掉前后缀。
以上便是我们手动制作静态库的第一种方法——安装到系统。
第二种方法:更改查找路径
如果我们此时当前目录有库和.h文件,我们可以编译文件并找到.h文件
gcc main.c -o main -lmystdio
但是又报错了,说找不到该库,这就证明了: gcc查库不会在当前路径查!这就给我们提供了第二种思路,更改查找位置,因此我们再引入一个新选项
gcc xxx.c -o xxx -L.(当前路径就是-L.) + -l库名(指明要在当前目录下链接哪个库)
![]()
第三种方法:使用指定路径的库
此方法适用于源文件和库不在同一目录下,只需要说明指定路径即可其他与方法二相同,我们用I选项(大写i)
gcc xxx.c -I路径(.h文件路径) -L库的路径 -l库名
![]()
2.动态库
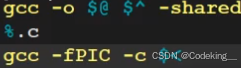
如何形成动态库呢?还是用gcc!只不过后面需要加选项,-shared(生成共享库格式)
同时,我们把.c生成.o时,也需要加一个选项:-fPIC(形成与位置无关码,一会细说)
生成的动态库和静态库的查找位置是相同的。
我们也可以查看某个文件依赖某些库:ldd命令

但是当我们运行时,发现可以编译,但是又找不到库了,我们明明用-l选项指定链接哪个库了,这是因为这是动态库,与静态库不同的是,静态库一旦链接成功就不需要了,因为已经把方法拷贝了,而此时的找不到是操作系统告诉我们的,因此我们需要让操作系统在lib64目录下找到此库,方法:1、把库拷贝到该目录2、在/lib64下创建一个该库的软连接 3、配置环境变量(export) LD_LIBRARY_PATH ,默认查找的路径就是此变量存的路径
在这里补充几点
如果同时提供.so和.a gcc/g++默认用动态库
如果要强制静态链接就必须提供对应静态库
如果只提供静态库,但链接方式是动态,只能进行局部性静态链接。
三、对进程的动态库的理解
我们在进程地址空间部分提到过进程启动时建立PCB与内存关系的映射过程,其中,动态库也是可以映射的,其具体机制为,先从磁盘中获取动态库到内存,然后通过页表把动态库映射到虚拟地址空间的共享区部分,然后我们的task_struct就可以找到对应的库了。一旦有其他进程也想使用这个库,我们就可以再建立一个映射关系进行对应(多对一)
四、重谈虚拟地址空间
1.虚拟地址空间真的在内存时才有吗?
我们在进程篇说过,虚拟地址空间并不是物理意义上的空间,而是进程加载出的虚拟空间,但实际上,这个mm_struct并不是在进程加载时所构建出的。我们先弄清一个问题,在我们的可执行程序编译完但未运行的情况下,是否有地址?
我们通过查看反汇编,发现代码的各个部分其实都有类似地址的符号
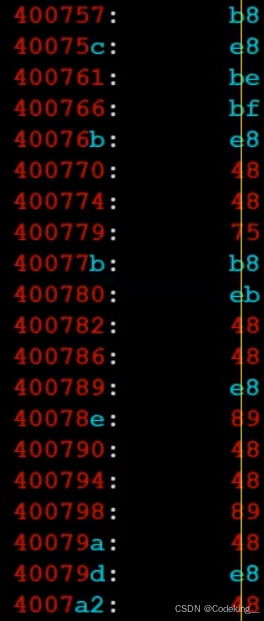
但实际上这并不是真正的物理地址,而是逻辑地址,逻辑地址=起始地址+偏移量。也就是说,如果实际的偏移量是0,那么这些就代表着真正的物理地址,如果是a,那么真正的物理地址就是每一个地址加上偏移量a。换句话说,这些地址就是相当于内存完全清空时所安排的地址,那么不就是我们的虚拟地址空间的概念吗?因此,我们的程序未运行也是有地址的(虚拟地址)。我们可以把逻辑地址和虚拟地址看成一个概念。
下一个问题,mm_struct是如何进行各部分初始化的?
在这里我们直接给出答案:初始化是根据磁盘中的程序的各个节(代码的各部分)进行初始化的。
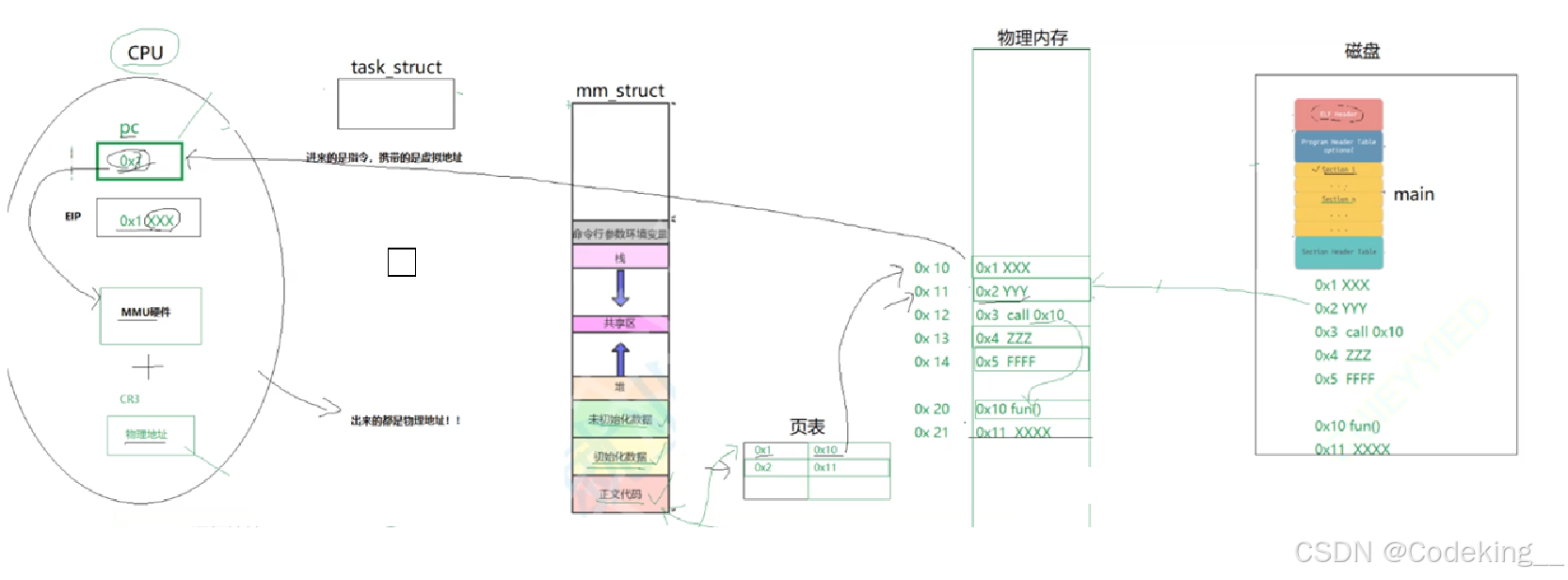
2.CPU执行程序的大致过程
那么我们的CPU是怎么知道这个程序该从哪里执行呢?虚拟地址给了我们答案,我们的各部分代码中,有一个地址就是专门提供给CPU的,让其知道程序的起始执行位置。至于我们其他的地址,比如调用函数等都会占空间,他们从磁盘到内存也需要占一定内存,此时他们就既有虚拟又有物理内存了,因此,页表中就可以一侧记录虚拟地址,一侧记录对应的物理地址了!但是,传给CPU的是虚拟地址!CPU也被骗了!
所以下一个问题是:既然CPU接收到的是虚拟地址,它怎么知道代码的物理地址并执行呢?
在CPU的结构中,有一个叫CR3的寄存器,其记录的是物理地址,它拿到这个物理地址,就会去页表找对应的虚拟地址,进而找到对应的代码并执行!(实际上这个操作是CR3和MMU硬件(也在CPU中)共同完成的操作——查表)
以上就是大致的流程,我们用一段话简化一下
首先,CPU中接收虚拟地址的部分是pc指针, 做查表工作的是CR3和MMU,负责执行地址对应的命令的是EIP。那么大致流程是:
当代码未加载在内存时,磁盘编译好的的程序会自己形成一个虚拟地址空间,当其加载到内存中,代码中的每一个命令除了有自己的虚拟地址外,还会有对应的物理地址。当程序开始执行时,CPU会识别,把虚拟地址传给pc,然后MMU+CR3查找对应的真实物理地址,然后把该地址交给EIP并执行对应的代码!
因此,CPU接收的是虚拟地址,输出的是物理地址。
3.真实的虚拟地址空间mm_struct
我们从宏观上来看,mm_struct像是一个整体被划分成不同区域,但我们看其定义发现,有许多vm_area_struct的指针,也就是说,这个mm_struct中还包含着许多结构体指针,其实这些指针就是代表各个区域!也就是说,我们看似mm_struct被分成了几个区域,实际上是其内部有多个结构体指针,每个指针对应着的就是划分的不同区域,每一个区域分别记录start和end位置,这样我们根据不同的位置就可以分别向物理地址映射了。不同的区域之间是通过链表方式链接的。
—————Linux——文件系列文章就更新到这里,后续若有补充内容会即使更改,本系列知识点较多,小伙伴们可以点赞收藏反复观看。