【Linux】线程池与封装线程
目录
一、线程池:
1、池化技术:
2、线程池优点:
3、线程池应用场景:
4、线程池实现:
二、封装线程:
三、单例模式:
四、其他锁:
五、读者写者问题
一、线程池:
1、池化技术:
池化技术是以空间换时间的一种技术,上述的线程池实际上就是先提前创建一批线程用容器存储着,然后当有任务来临,线程直接从任务列表中获取并且执行任务,这样通过空间来换取时间,可以极大地提高效率
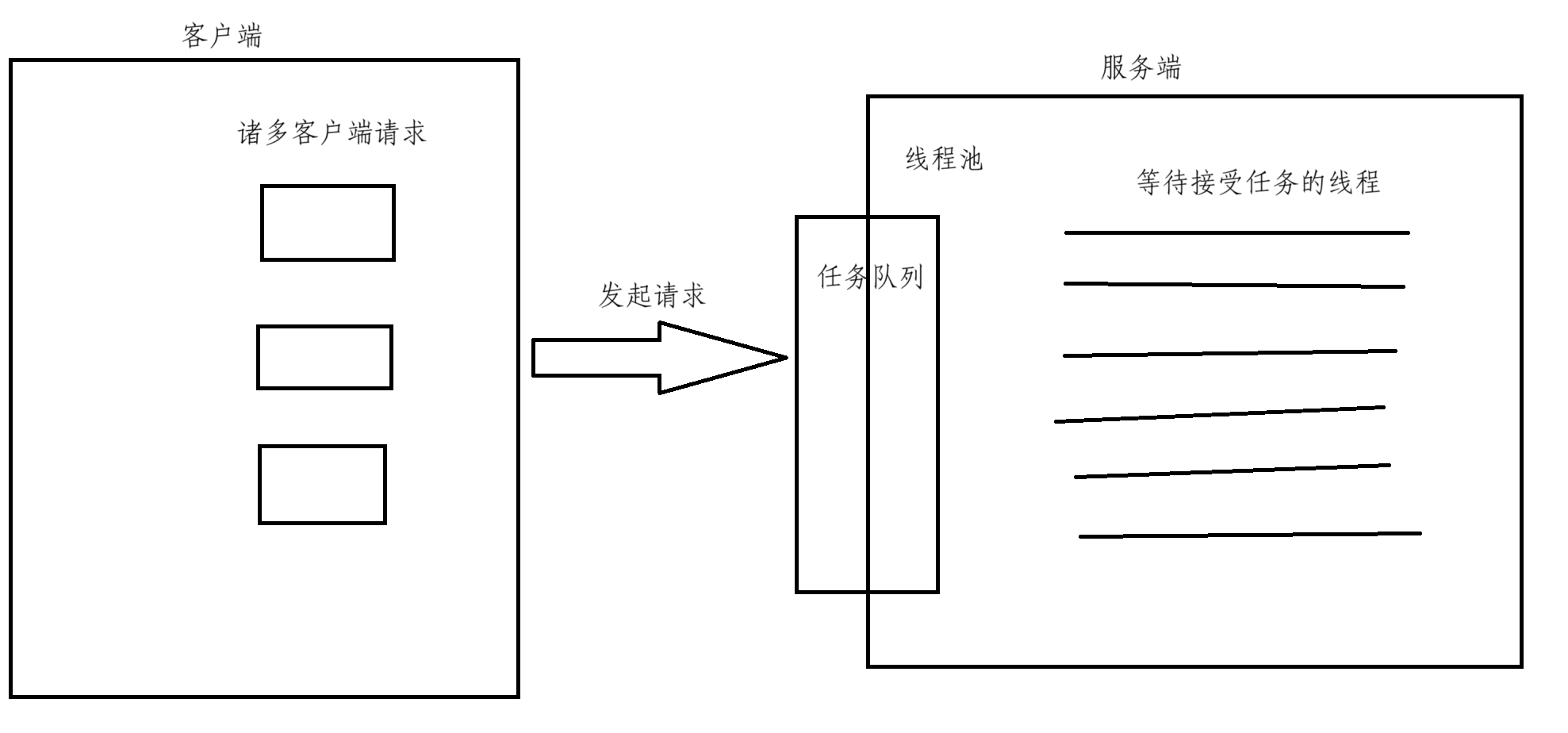
2、线程池优点:
高效,方便
- 线程池是已经创建好线程了,当有任务来临时,只需交给线程即可
- 在调度线程时保证合理性,防止线程的过度调度,保证内核的充分利用
- 避免了在处理短时间任务时创建与销毁线程的代价
但是线程池的数量也不是越多越好,更多的是要与实际开发相结合
3、线程池应用场景:
- 需要大量的线程来完成任务,并且每一个任务耗时短
- 对性能要求苛刻,要快速响应,比如打游戏时候放技能
- 当有可能突然出现大量请求的时候,但是不至于使服务器产生大量线程,也就是短时间产生大量线程使服务器内存达到最大,此时可以用线程池提升该效率问题
4、线程池实现:
#pragma once
#include <iostream>
#include <vector>
#include <queue>
#include <string>
#include <pthread.h>
#include <unistd.h>
#include <ctime>
struct ThreadInfo
{
pthread_t _tid;
std::string ThreadName;
};
static int defaultnum = 5;
template <class T>
class ThreadPool
{
public:
void Lock()
{
pthread_mutex_lock(&_mutex);
}
void UnLock()
{
pthread_mutex_unlock(&_mutex);
}
void ThreadSleep()
{
pthread_cond_wait(&_cond,&_mutex);
}
bool IsEmpty()
{
return _task.empty();
}
std::string GetThreadName(pthread_t tid)
{
for(auto &it : _threads)
{
if(it._tid == tid)
{
return it.ThreadName;
}
}
return "NONE";
}
void Wakeup()
{
pthread_cond_signal(&_cond);
}
public:
ThreadPool(int num = defaultnum)
:_threads(num)
{
pthread_mutex_init(&_mutex,nullptr);
pthread_cond_init(&_cond,nullptr);
}
static void *myhander(void *args)
{
ThreadPool<T> * tp = static_cast<ThreadPool<T> *>(args);
std::string name = tp->GetThreadName(pthread_self());
while(true)
{
tp->Lock();
while(tp->IsEmpty())
{
tp->ThreadSleep();
}
T ret = tp->Pop();
tp->UnLock();
ret();
std::cout << name << "正在运行,结果: " << ret.Getresult() << std::endl;
}
}
T Pop()
{
T t = _task.front();
_task.pop();
return t;
}
void Push(const T &t)
{
Lock();
_task.push(t);
Wakeup();
UnLock();
}
void Start()
{
int num = _threads.size();
for(int i = 0;i < num;i++)
{
_threads[i].ThreadName = "thread-" + std::to_string(i + 1);
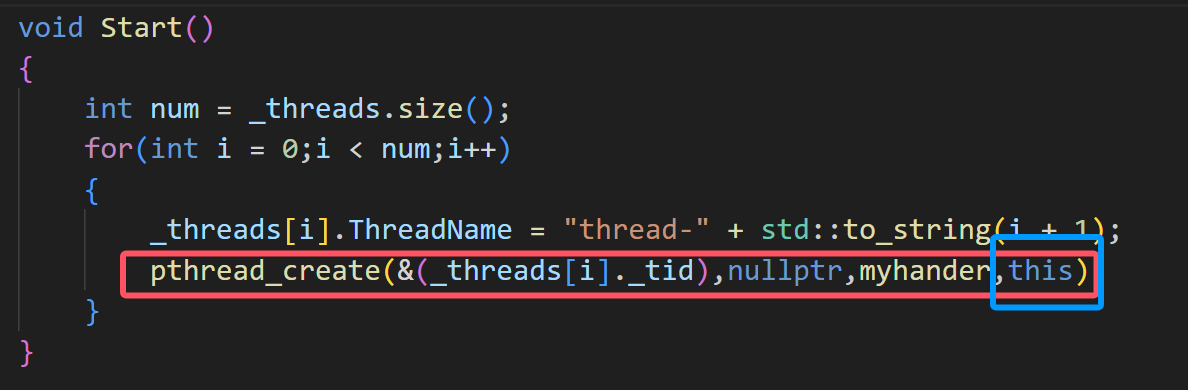
pthread_create(&(_threads[i]._tid),nullptr,myhander,this);
}
}
~ThreadPool()
{
pthread_mutex_destroy(&_mutex);
pthread_cond_destroy(&_cond);
}
private:
std::vector<ThreadInfo> _threads;
std::queue<T> _task;
pthread_mutex_t _mutex;
pthread_cond_t _cond;
};
对于上述线程池代码,有三个要注意的点:
1、myhander函数要设计成静态的,因为如果不设计成静态的,myhander就是成员方法,而成员方法有this指针,这样导致其形参不是void*,所以不能在创建线程的时候直接传,要设置成静态的
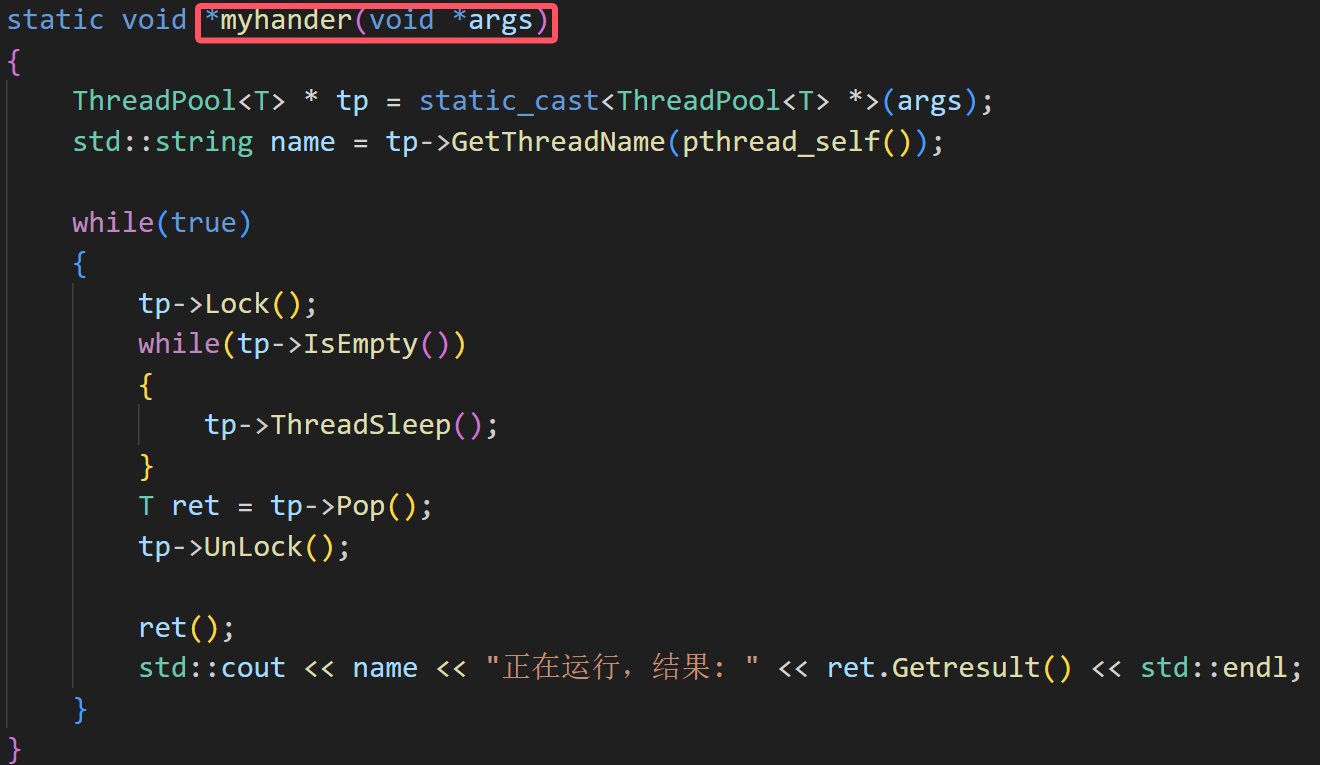
2、但是设置成静态的函数的话,发现编译不过,因为静态的函数可以访问其静态的函数和变量,无法访问成员函数和成员变量,所以在创建线程的时候要传递当前对象,也就是this指针,这样就能够通过对象访问其成员函数了
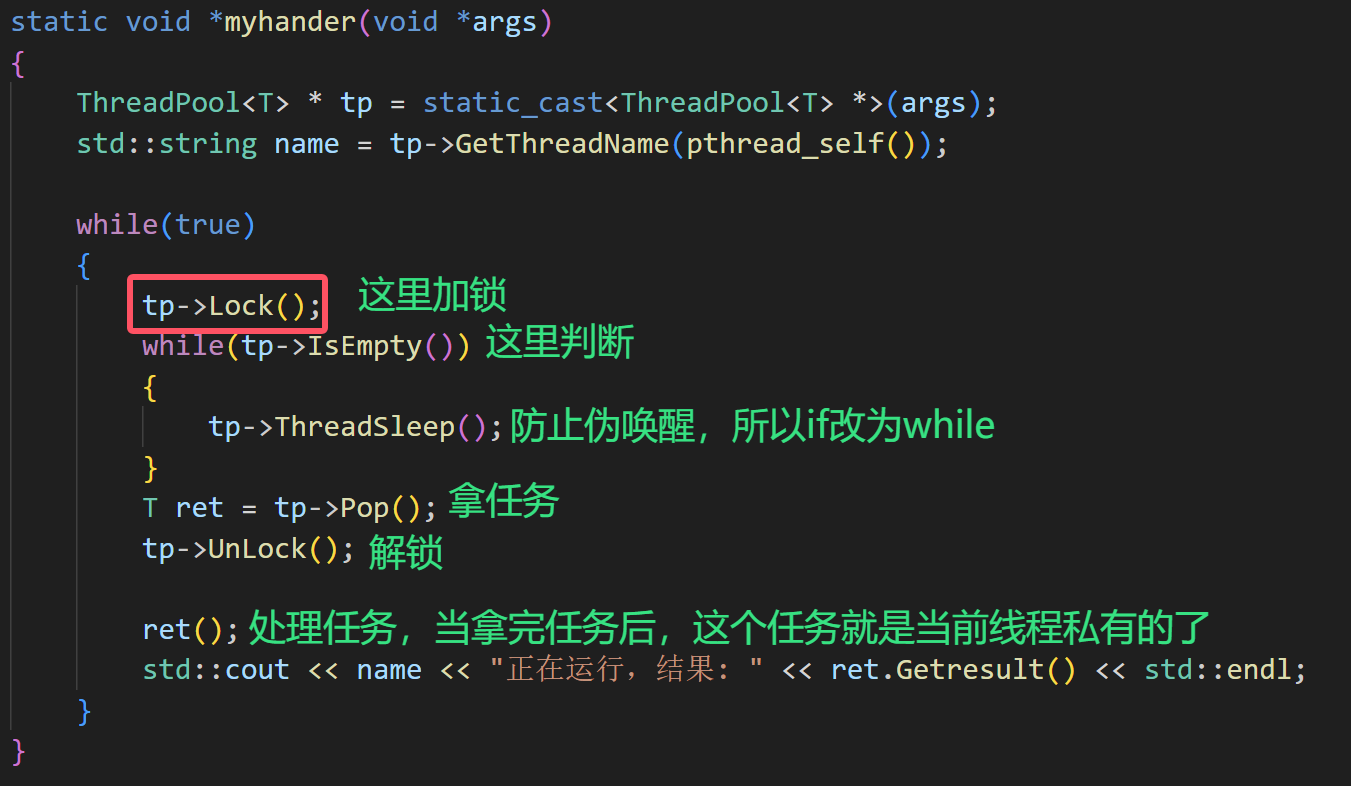
3、这里要引入互斥锁,这是因为线程池中的任务队列会被多个执行流访问,要加锁对其进行保护,我们知道线程执行任务的时候要去任务队列中拿任务,此时就需要判断任务队列是否为空,所以加锁要在判断之前
判断就是如果队列为空,就让当前线程去条件变量中休眠,还有为了防止伪唤醒,所以这里的if要改为while
4、当线程拿到任务的时候,这个任务就是当前线程私有的了,所以处理任务就不要放在临界区了,因为要保证在处理任务的线程是并行的,如果一个线程要等待另一个线程处理完任务就不是并行的了,效率会大大降低
任务设计
我们的任务在之前章节就已经完成了,直接拿过来用即可
#pragma once
#include <iostream>
#include <string>
std::string opers = "+-*/%";
enum
{
Divzero = 1,
Modzero,
Unknow
};
class Task
{
public:
Task()
{
}
Task(int data1, int data2, char oper)
: _data1(data1), _data2(data2), _oper(oper), _exitcode(0),_result(0)
{
}
void run()
{
switch (_oper)
{
case '+':
_result = _data1 + _data2;
break;
case '-':
_result = _data1 - _data2;
break;
case '*':
_result = _data1 * _data2;
break;
case '/':
{
if (_data2 == 0)
_exitcode = Divzero;
else
_result = _data1 / _data2;
}
break;
case '%':
{
if (_data2 == 0) _exitcode = Modzero;
else _result = _data1 % _data2;
}
break;
default:
_exitcode = Unknow;
break;
}
}
void operator ()()
{
run();
}
std::string Getresult()
{
std::string ret = std::to_string(_data1);
ret += _oper;
ret += std::to_string(_data2);
ret += "=";
ret += std::to_string(_result);
ret += "[exitcode=";
ret += std::to_string(_exitcode);
ret += "]";
return ret;
}
std::string GetTask()
{
std::string ret = std::to_string(_data1);
ret += _oper;
ret += std::to_string(_data2);
ret += "=?";
return ret;
}
~Task()
{
}
private:
int _data1;
int _data2;
char _oper;
int _exitcode;
int _result;
};主函数逻辑
主线程就不断地向线程池中push任务即可,然后线程池就会从任务队列中拿任务并处理,怎么处理不用关心,所以这里对我们来说相当于一个黑盒
#include "ThreadPool.hpp"
#include "Task.hpp"
int main()
{
srand(time(nullptr)^getpid());
ThreadPool<Task> *tp = new ThreadPool<Task>();
tp->Start();
while(true)
{
int data1 = rand()%10+1;
usleep(10);
int data2 = rand()%5;
char op = opers[rand()%opers.size()];
Task t(data1,data2,op);
usleep(10);
tp->Push(t);
std::cout<<"主线程启动:" << t.GetTask() <<std::endl;
sleep(1);
}
return 0;
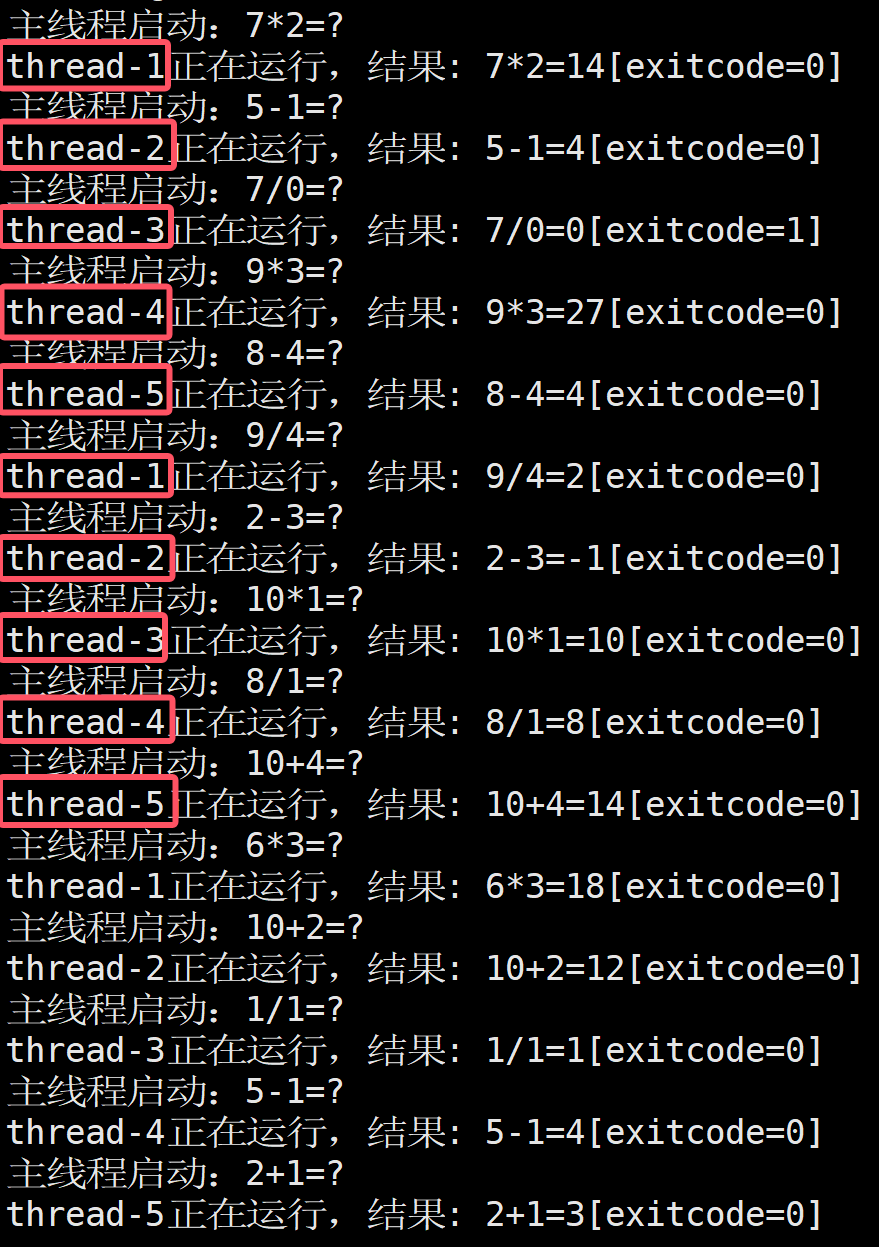
}实验结果:
如下,并且我们发现这里的线程是有顺序性的,这是因为主线程每秒只会push一个任务,然后线程池中每次都只有一个线程获取到任务,其他线程就会在队列中等待,当这个线程处理完任务后,就会到队列的最后等待,此时若主线程有push任务,就会唤醒队列第一个线程,完成任务后又会到队列尾部,这样我们就能够看到顺序性
二、封装线程:
接下来我们尝试封装线程,就像C++中的线程库那样使用而不是使用原生接口
对于一个线程,我们可以给他设置很多属性,其中_data是传进来的参数,_cb是一个回调函数
private:
pthread_t _tid;
std::string _name;
bool _isrunning;
uint64_t _start_time;
T _data;
callback_t _cb;将这些在构造函数进行初始化:
Thread(callback_t cb,T data)
:_tid(0),_name(""),_isrunning(false),_start_time(0),_cb(cb),_data(data)
{}然后设计对外开放的接口,能够像C++库中的线程使用起来
void Run()
{
_name = "thread-" + std::to_string(num++);
_isrunning = true;
_start_time = time(nullptr);
pthread_create(&_tid,nullptr,Running,this);
}
void Entry()
{
_cb(_data);
}
void Join()
{
_isrunning = false;
pthread_join(_tid,nullptr);
}
std::string GetName()
{
return _name;
}
uint64_t Start_Time()
{
return _start_time;
}
bool IsRunning()
{
return _isrunning;
}其中,Running方法要设计成静态的,这是因为和线程池那里一样,如果不是静态方法就是成员函数,这样的话就会多一个形参,所以要设置成静态的,但是静态方法不能直接访问成员变量,所以在创建线程的时候要将this指针也就是当前对象传过去,这样就能够通过对象访问成员函数或成员变量了
static void* Running(void *args)
{
Thread* thread = static_cast<Thread*>(args);
thread->Entry();
return nullptr;
}这里还要设置回调函数
typedef void (*callback_t)(T);其中callback_t是 函数指针类型,他的参数是T,在定义一个Thread类的时候,需要传递一个函数给构造函数,这个cb就是一个函数指针,然后赋值给_cb,后面_cb()调用的就是传递进来的函数
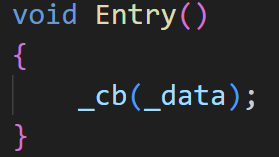
在Entry中的cb(_data)调用的是这个uPrint
主函数逻辑
初始化好要传的参数,准备好回调函数所用的函数,就可以像C++中的线程库进行使用了
class udata
{
public:
std::string _s;
int _data;
};
void uPrint(udata x)
{
while(true)
{
std::cout << "我是一个封装后的线程,我得到了参数 : " << x._s << " 和 " << x._data <<std::endl;
sleep(1);
}
}
int main()
{
udata da;
da._s = "666";
da._data = 111;
Thread<udata> t(uPrint,da);
t.Run();
std::cout << "该线程的名字 : " << t.GetName() <<std::endl;
std::cout << "该线程是否运行 : " << t.IsRunning() <<std::endl;
std::cout << "该线程创建时间 : " << t.Start_Time() <<std::endl;
t.Join();
return 0;
}三、单例模式:
具体可以看看下面这篇文章
【C++11】特殊类的设计 && 单例模式 && 类型转换-CSDN博客![]() https://blog.csdn.net/2303_80828380/article/details/147028880?spm=1001.2014.3001.5501
https://blog.csdn.net/2303_80828380/article/details/147028880?spm=1001.2014.3001.5501
在这里我们是将单例模式在代码中实现出来,也就是将线程池设计成单例模式
1、将构造函数私有化,保证不能够在外部随便创建变量
private:
ThreadPool(int num = defaultnum)
: _threads(num)
{
pthread_mutex_init(&_mutex, nullptr);
pthread_cond_init(&_cond, nullptr);
}2、将拷贝构造和赋值重载删掉,保证不能够通过拷贝来创建新对象
ThreadPool(const ThreadPool<T>& copy) = delete;
const ThreadPool<T>& operator=(const ThreadPool<T>& copy) = delete;3、设计静态的指针指向堆空间,还要有锁,_tp要设计成静态的原因实现单例模式,保证全局唯一实例,_lock为静态的提供全局同步锁,确保多线程下安全创建单例
静态成员变量在类里面声明,在类外面定义,是语法规定的
类内定义,类外初始化,在初始化的时候不要带上static,并且要指定类域,不然的话编译器编译的时候就找不到对应的变量了
template <class T>
class ThreadPool
{
private:
static ThreadPool<T>* _tp;
//不可以像下面初始化
//static ThreadPool<T>* _tp = nullptr;
static pthread_mutex_t _lock;
};
template <class T>
ThreadPool<T>* ThreadPool<T>::_tp = nullptr;
template <class T>
pthread_mutex_t ThreadPool<T>::_lock = PTHREAD_MUTEX_INITIALIZER;4、这里采用懒汉模式创建单例,所以在GetInstance接口中new对象
这里这个函数为静态的,为了访问静态变量_tp,如果不是静态函数的话就访问不了_tp了
static ThreadPool<T>* GetInstance()
{
if(_tp == nullptr)
{
pthread_mutex_lock(&_lock);
if(_tp == nullptr)
{
_tp = new ThreadPool<T>;
}
pthread_mutex_unlock(&_lock);
}
return _tp;
}还要进行两次判空:
我们发现,只有第一个线程进入的时候_tp才会为空,这样的话后面如果多次进行加锁判断释放锁会降低效率,所以这里得二次判断,保证后面不为空的时候直接返回,并且即使第一次有多个线程进入了第一个if,但是,依然是只会有一个线程成功申请锁并进入if,new空间,其余线程即使后来申请到锁了,但是if判断失效,所以就会释放锁,然后后来的线程就会在第一个if那里都进不去,进而增加效率
完整代码:
#pragma once
#include <iostream>
#include <vector>
#include <queue>
#include <string>
#include <pthread.h>
#include <unistd.h>
#include <ctime>
struct ThreadInfo
{
pthread_t _tid;
std::string ThreadName;
};
static int defaultnum = 5;
template <class T>
class ThreadPool
{
public:
void Lock()
{
pthread_mutex_lock(&_mutex);
}
void UnLock()
{
pthread_mutex_unlock(&_mutex);
}
void ThreadSleep()
{
pthread_cond_wait(&_cond, &_mutex);
}
bool IsEmpty()
{
return _task.empty();
}
std::string GetThreadName(pthread_t tid)
{
for (auto &it : _threads)
{
if (it._tid == tid)
{
return it.ThreadName;
}
}
return "NONE";
}
void Wakeup()
{
pthread_cond_signal(&_cond);
}
public:
static void *myhander(void *args)
{
ThreadPool<T> *tp = static_cast<ThreadPool<T> *>(args);
std::string name = tp->GetThreadName(pthread_self());
while (true)
{
tp->Lock();
while (tp->IsEmpty())
{
tp->ThreadSleep();
}
T ret = tp->Pop();
tp->UnLock();
ret();
std::cout << name << "正在运行,结果: " << ret.Getresult() << std::endl;
}
}
T Pop()
{
T t = _task.front();
_task.pop();
return t;
}
void Push(const T &t)
{
Lock();
_task.push(t);
Wakeup();
UnLock();
}
void Start()
{
int num = _threads.size();
for (int i = 0; i < num; i++)
{
_threads[i].ThreadName = "thread-" + std::to_string(i + 1);
pthread_create(&(_threads[i]._tid), nullptr, myhander, this);
}
}
//懒汉模式
static ThreadPool<T>* GetInstance()
{
if(_tp == nullptr) //我们发现,只有第一个线程进入的时候_tp才会为空,这样的话后面如果多次进行加锁判断释放锁会降低效率
{ //所以这里得二次判断,保证后面不为空的时候直接返回,并且即使第一次有多个线程进入了235行,但是
//依然是只会有一个线程成功申请锁并进入if,new空间,其余线程即使后来申请到锁了,但是if判断失效,所以就
//会释放锁,然后后来的线程就会在第一个if那里都进不去,进而增加效率
pthread_mutex_lock(&_lock);
if(_tp == nullptr)
{
_tp = new ThreadPool<T>;
}
pthread_mutex_unlock(&_lock);
}
return _tp;
}
private:
ThreadPool(int num = defaultnum)
: _threads(num)
{
pthread_mutex_init(&_mutex, nullptr);
pthread_cond_init(&_cond, nullptr);
}
~ThreadPool()
{
pthread_mutex_destroy(&_mutex);
pthread_cond_destroy(&_cond);
}
ThreadPool(const ThreadPool<T>& copy) = delete;
const ThreadPool<T>& operator=(const ThreadPool<T>& copy) = delete;
private:
std::vector<ThreadInfo> _threads;
std::queue<T> _task;
pthread_mutex_t _mutex;
pthread_cond_t _cond;
static ThreadPool<T>* _tp;
//static ThreadPool<T>* _tp = nullptr;
static pthread_mutex_t _lock;
};
template <class T>
ThreadPool<T>* ThreadPool<T>::_tp = nullptr;
template <class T>
pthread_mutex_t ThreadPool<T>::_lock = PTHREAD_MUTEX_INITIALIZER;
四、其他锁:
- 悲观锁:在每次取数据时,总是担心数据会被其他线程修改,所以会在取数据前先加锁(读锁,写锁,行锁等),当其他线程想要访问数据时,被阻塞挂起。
- 乐观锁:每次取数据时候,总是乐观的认为数据不会被其他线程修改,因此不上锁。但是在更新数据前,会判断其他数据在更新前有没有对数据进行修改。主要采用两种方式:版本号机制和CAS操作。
- CAS操作:当需要更新数据时,判断当前内存值和之前取得的值是否相等。如果相等则用新值更新。若不等则失败,失败则重试,一般是一个自旋的过程,即不断重试。
- 自旋锁:申请锁失败的时候不将自己挂起,而是不断尝试申请锁
自旋就是不把自己挂起,而是由线程不断地去周而复始的去申请锁,如果申请锁成功则进入,失败则返回重新检测锁的状态
自旋锁相关接口:
自旋锁的类型是pthread_spinlock_t
加解自旋锁:
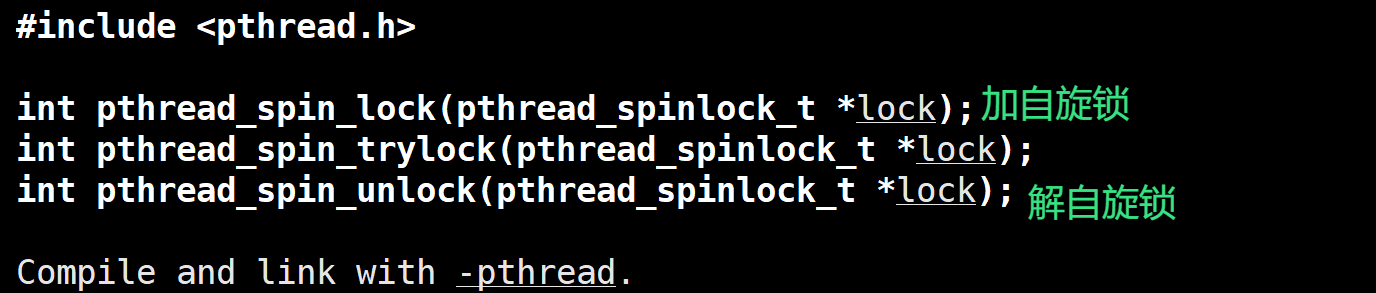
其中:
int pthread_spin_lock(pthread_spinlock_t *lock)失败就不断重试(阻塞式)
int pthread_spin_trylock(pthread_spinlock_t *lock);失败就继续向后运行(非阻塞式)

其实是类似于之前学习的互斥锁,使用和其大差不差
什么时候使用自旋锁:
1、锁持有时间极短
当临界区代码执行时间非常短(如几个指令周期)时,自旋锁的“忙等待”不会显著浪费CPU资源
2、多核/多CPU环境
在多核系统中,等待线程可能在另一个核心上运行,避免因睡眠-唤醒带来的上下文切换开销
3、不可睡眠的上下文
在中断上下文、内核抢占禁用区域等不能睡眠的代码路径中,必须使用自旋锁
4、对实时性要求高
自旋锁的响应延迟低(无上下文切换),适合实时系统或低延迟任务
| 特性 | 自旋锁 | 互斥锁 |
|---|---|---|
| 等待方式 | 忙等待(循环检测) | 睡眠等待(进入阻塞状态) |
| CPU消耗 | 高(持续占用CPU) | 低(释放CPU给其他线程) |
| 适用场景 | 短临界区、多核、不可睡眠 | 长临界区、通用场景 |
| 性能优势 | 低延迟(无上下文切换) | 高吞吐量(减少CPU浪费) |
五、读者写者问题
这个也是遵循"321"原则的
3种关系:
读者和读者,写者和写者,读者和写者
2个角色:
读者和写者
1个交易场所:
阻塞队列或者缓冲区
以上基本是和生产消费者模型是差不多的,不同的是读者和读者之间是没有互斥关系的,最大的原因在于读者是只会读缓冲区中的数据,是不会将数据拿走或者修改的,所以不需要维护读者和读者之间的互斥关系
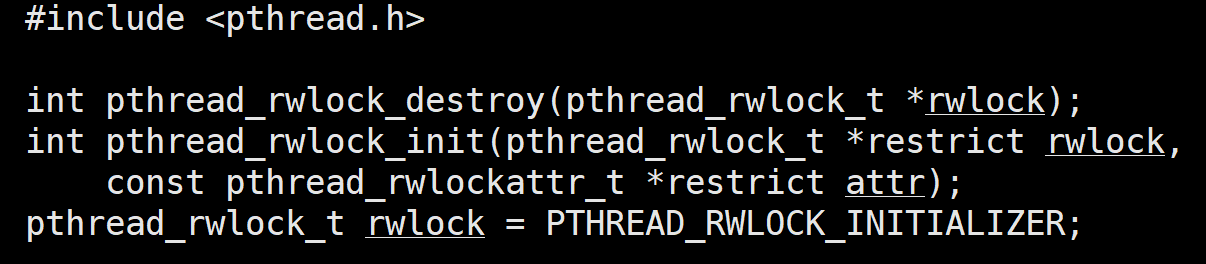
相关接口:
注意:读者和写者的锁不是同一个锁
初始化,销毁自旋锁:
读者进行加锁,解锁

写者进行加锁,解锁

解锁,这个读者写者的锁都能解

读者写者的伪代码:
理解:
读者在读数据的时候,写者是不能够写的,但是其他读者可以读
写者在写数据的时候,读者是不能够读数据的
当所有读者读完数据的时候,再让写者写数据
当写者写完数据的时候,再让读者读数据
接下来实现一个读者优先的伪代码:
void Reader()
{
// 首先就是读者的加锁和解锁操作:
// 首先对读者进行加锁
pthread_mutex_lock(&rlock);
reader_count++; //在这里将读者的数量+1
// 接着判断读者是否为1,如果为1就证明这是第一个读者,此时申请写者的锁,就会有两种情况
// 1、写者没有进行写入,所以写者也就没有申请到锁,所以读者申请成功锁,让以后写者无法进行写入
// 2、写者正在进行写入,所以写者也就持有锁,那么第一个读者也就在这里申请失败锁,进入阻塞队列中等待
if (reader_count == 1)
{
pthread_mutex_lock(&wlock);
}
// 这里是释放的读者自己的锁,如果读者正在读,一定会持有写者的锁的
pthread_mutex_unlock(&rlock);
// 在这里进行读取,因为不需要维护读者之间的互斥关系也就不需要锁,直接进行读取即可
//当读取完后,下面就是减少读者的代码
pthread_mutex_lock(&rlock);
reader_count--; // 将读者的数量-1
//这里进行判断,如果读者的数量为0的时候释放写者的锁,此时写者就能够进行写入了
if (reader_count == 0)
{
pthread_mutex_lock(&wlock);
}
pthread_mutex_unlock(&rlock);
}void Writer()
{
// 然后是写者的加锁,写入数据,解锁
pthread_mutex_lock(&wlock);
//写入数据
pthread_mutex_unlock(&wlock);
}