Kubernetes集群环境搭建与初始化
1.Kubernetes简介:
Kubernetes是Google开源的一个容器编排引擎,它支持自动化部署、大规模可伸缩、应用容器化管理。在生产环境中部署一个应用程序时,通常要部署该应用的多个实例以便对应用请求进行负载均衡。
在Kubernetes中,我们可以创建多个容器,每个容器里面运行一个应用实例,然后通过内置的负载均衡策略,实现对这一组应用实例的管理、发现、访问,而这些细节都不需要运维人员去进行复杂的手工配置和处理。
1.1总体架构:
Kubernetes的架构包括以下主要组件:
(1)控制平面(Control Plane):包括kube-apiserver、etcd、kube-scheduler、kube-controller-manager和cloud-controller-manager。控制平面负责管理集群的状态、调度Pod到合适的节点、监控节点和Pod的健康状况等。它是集群的大脑。
(2)工作节点(Worker Nodes):包括kubelet、kube-proxy和容器运行时。工作节点则负责运行实际的应用容器,每个工作节点都有一个kubelet进程来管理节点上的Pod,还有一个kube-proxy进程来处理网络代理和负载均衡。
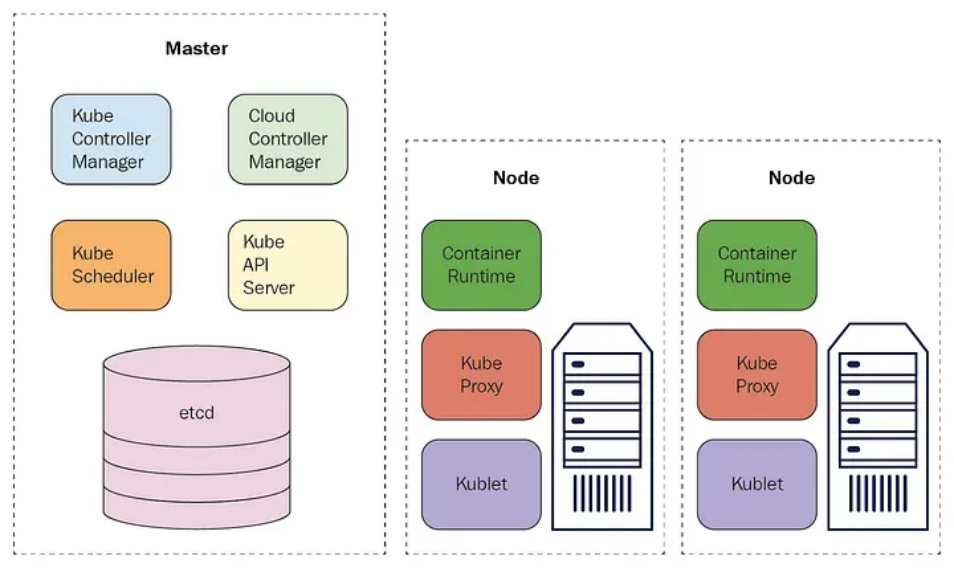
1.2控制平面组建:
控制面组件的架构图:
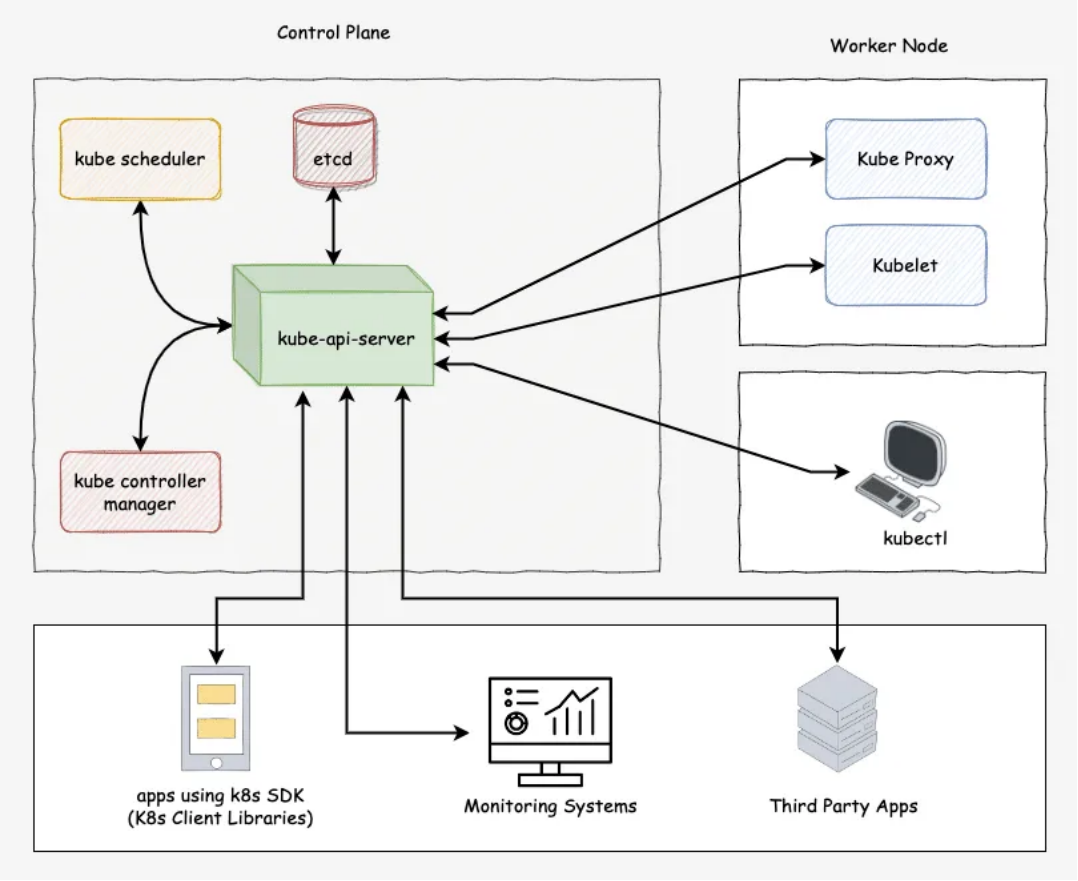
(1)Kube-APIServer
Kube-APIServer 是 Kubernetes 控制平面的核心组件,负责处理所有的 REST 操作,暴露 Kubernetes API。它是整个集群的前端,所有的控制请求都要经过它。
主要功能包括:
①验证和授权:Kube-APIServer 负责验证用户的身份,并根据配置的访问控制策略进行授权,确保只有合法的请求才能对集群进行操作。
②集群状态管理:APIServer 是集群的状态中心,所有的集群状态信息都通过它来访问和更新。
通信枢纽:Kube-APIServer 是其他控制平面组件和工作节点与集群进行通信的桥梁。所有的组件和节点都通过它来获取和更新集群状态。
③当用户或其他组件向 Kube-APIServer 发送请求时,APIServer 首先进行身份验证和授权检查,然后对请求的数据进行验证和处理。处理完成后,APIServer 会将数据存储到 etcd 中,同时通知其他组件进行相应的操作。
(2)Etcd
Etcd 是一个分布式键值存储,用于存储 Kubernetes 集群的所有数据。它是 Kubernetes 集群的源数据存储系统,所有的配置信息、状态信息都存储在 etcd 中。
主要功能:
① 数据存储:Etcd 负责存储所有的集群状态数据,包括 Pod、Service、ConfigMap、Secret 等。
② 数据可靠性:Etcd 通过分布式架构保证数据的高可用性和一致性,确保集群状态数据在发生故障时仍能可靠存储。
③ 数据访问:Etcd 提供了高效的键值对存储和访问接口,支持高频率的读写操作,满足 Kubernetes 对集群状态数据的高频访问需求。
Kube-APIServer 通过 etcd API 进行数据的读写操作。当集群状态发生变化时,APIServer 会将新的状态数据写入 etcd,同时其他组件可以监听 etcd 的变化,从而进行相应的处理。
(3)Kube-Scheduler
Kube-Scheduler 是 Kubernetes 的调度组件,负责将新创建的 Pod 调度到合适的工作节点上。它根据预设的调度策略和节点状态,选择最合适的节点来运行 Pod。
主要功能:
① 资源调度:Kube-Scheduler 根据节点的资源使用情况和 Pod 的资源需求,选择合适的节点来运行 Pod。
② 策略配置:Kube-Scheduler 支持多种调度策略,包括资源优先、亲和性、反亲和性等,用户可以根据需求自定义调度策略。
③ 负载均衡:通过合理的调度策略,Kube-Scheduler 能够有效地分配负载,避免节点过载,确保集群的高效运行。
Kube-Scheduler 通过监听 Kube-APIServer 上的调度请求,获取需要调度的 Pod 列表。然后,它根据预设的调度策略和节点的状态,选择最合适的节点,并将调度结果写回 APIServer,最终由相应的节点来运行 Pod。
(4)Kube-Controller-Manager
Kube-Controller-Manager 是 Kubernetes 控制平面的控制管理组件,负责管理集群的各种控制器。这些控制器是用于处理集群状态变化的后台进程。
主要功能:
① 控制器管理:包括 Node Controller、Replication Controller、Endpoint Controller、Namespace Controller 等,这些控制器分别负责节点管理、副本管理、服务发现、命名空间管理等功能。
自动化操作:控制器通过监听集群状态变化,自动执行相应的操作,如副本调整、故障节点隔离、服务更新等。
② 一致性保证:通过控制器的自动化操作,Kube-Controller-Manager 保证了集群状态的一致性和可靠性。
Kube-Controller-Manager 通过监听 Kube-APIServer 的事件,获取集群状态变化的信息。根据不同的控制器,它会执行相应的操作,如创建或删除 Pod、副本调整、节点故障处理等,并将结果写回 APIServer,从而更新集群状态。
(3)Cloud-Controller-Manager
Cloud-Controller-Manager 是 Kubernetes 控制平面的云服务管理组件,用于将 Kubernetes 与底层的云服务集成。它抽象了底层云平台的差异,使得 Kubernetes 可以在不同的云平台上运行。
功能:
① 云资源管理:包括节点管理、负载均衡、存储管理等功能,支持将 Kubernetes 与各种云服务(如 AWS、GCP、Azure)集成。
② 多云支持:通过抽象底层云平台的差异,Cloud-Controller-Manager 使得 Kubernetes 可以在多种云平台上无缝运行。
③ 自动化操作:通过自动化管理云资源,Cloud-Controller-Manager 提高了 Kubernetes 集群的可用性和灵活性。
Cloud-Controller-Manager 通过调用底层云平台的 API,执行相应的操作,如节点创建、负载均衡配置、存储卷管理等。它通过监听 Kube-APIServer 的事件,获取需要执行的操作,然后调用云平台的 API 来完成相应的操作,并将结果写回 APIServer,从而更新集群状态。
1.3工作节点组件:
工作节点组件的架构图:
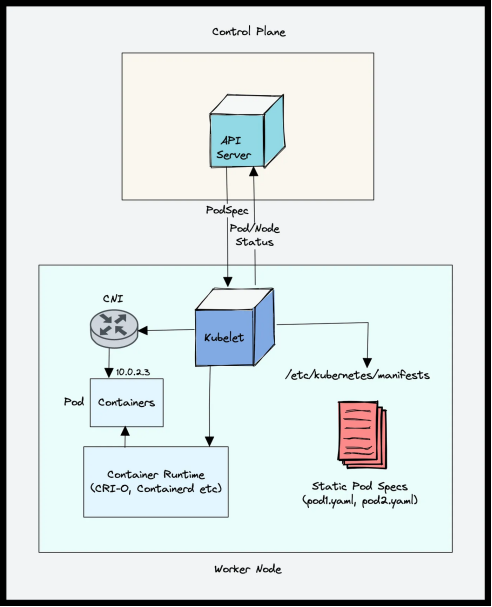
(1)Kubelet
Kubelet 是运行在每个工作节点上的主要代理进程,负责管理节点上的 Pod 和容器。它通过与 Kube-APIServer 交互,确保节点上容器的正确运行。
主要功能:
① Pod 管理:Kubelet 负责启动和停止节点上的 Pod,并监控它们的状态,确保每个 Pod 按照预期运行。
② 状态报告:Kubelet 定期向 Kube-APIServer 报告节点和 Pod 的状态,包括资源使用情况、健康状态等。
③ 配置管理:Kubelet 根据从 Kube-APIServer 获取的配置信息,配置和管理节点上的容器运行环境。
Kubelet 通过监听 Kube-APIServer 的调度信息,获取需要在本节点上运行的 Pod 列表。它根据 Pod 的配置文件,调用容器运行时(如 Docker、containerd)来启动和管理容器。同时,Kubelet 会定期向 Kube-APIServer 发送心跳信号和状态报告,确保控制平面能够及时了解节点和 Pod 的运行状况。
(2)Kube-Proxy
Kube-Proxy 是 Kubernetes 中的网络代理服务,运行在每个工作节点上,负责维护网络规则,管理 Pod 间的网络通信和负载均衡。
主要功能:
① 服务发现:Kube-Proxy 负责维护节点上的网络规则,确保服务 IP 和端口能够正确映射到相应的 Pod 上。
② 负载均衡:Kube-Proxy 通过 IPTables 或 IPVS 实现服务的负载均衡,将请求分发到后端的多个 Pod 上。
③ 网络路由:Kube-Proxy 处理网络流量,确保节点内外的通信能够正确路由到目标 Pod。
Kube-Proxy 通过监听 Kube-APIServer 获取服务和端点的变化信息,然后根据这些信息动态更新节点上的网络规则。它使用 IPTables 或 IPVS 来实现网络流量的转发和负载均衡,确保请求能够正确分发到相应的 Pod 上。
(3)Pod
Kubernetes 的世界里,Pod 是对容器的进一步抽象和组织,最小的可部署计算单元,也是 Kubernetes 管理的最小对象。它包含一个或多个容器,是一组紧密相关的容器集合,这些容器共享存储、网络和一些配置信息,它们总是被一起调度和管理,在共享的上下文中运行。可以将 Pod 理解为一个 “逻辑主机”,其中包含一个或多个应用容器,这些容器相对紧密地耦合在一起,共同完成特定的任务。
以一个典型的 Web 应用为例,它可能包含一个 Web 服务器容器(如 Nginx)和一个应用程序容器(如基于 Node.js 或 Python 的后端服务)。为了实现两者之间的高效通信,我们可以将这两个容器放在同一个 Pod 中。由于它们共享相同的网络命名空间,Web 服务器容器可以直接通过localhost与应用程序容器进行通信,无需进行复杂的网络配置和地址解析,大大简化了通信流程。
同时,Pod 中的容器还可以共享存储资源。比如,我们可以为上述 Web 应用的 Pod 挂载一个存储卷,用于存储应用程序的日志文件。Web 服务器容器和应用程序容器都可以访问这个存储卷,将各自产生的日志写入其中,方便统一管理和分析。
(4)容器运行时
容器运行时(Container Runtime)是 Kubernetes 中用于运行和管理容器的组件,常见的容器运行时有 Docker、containerd、CRI-O 等。
主要功能:
① 容器管理:容器运行时负责启动、停止和监控容器的运行状态。
② 资源隔离:容器运行时通过 cgroup、namespace 等机制实现容器的资源隔离和限制。
③ 镜像管理:容器运行时负责从镜像仓库拉取容器镜像,并在节点上进行存储和管理。
Kubelet 通过 CRI(Container Runtime Interface)与容器运行时进行交互,向其发送启动和停止容器的指令。容器运行时根据这些指令,调用底层操作系统的容器技术(如 cgroup、namespace)来管理容器的生命周期和资源使用。同时,容器运行时还负责从镜像仓库拉取和管理容器镜像,确保容器能够按需启动。
(5)Node Local Controller
Node Local Controller 是 Kubernetes 中的一种节点本地控制器,负责在每个节点上执行一些特定的控制任务,如本地存储管理、节点健康检查等。
主要功能:
① 本地存储管理:Node Local Controller 负责管理节点上的本地存储资源,如临时存储卷、持久化存储卷等。
② 节点健康检查:通过定期检查节点的运行状态,Node Local Controller 能够及时发现并报告节点的健康问题。
③ 资源分配:根据节点的资源使用情况,Node Local Controller 可以调整资源分配策略,确保节点上的 Pod 能够高效运行。
Node Local Controller 运行在每个工作节点上,通过监听 Kubelet 和 Kube-APIServer 的事件,获取节点的状态信息。根据这些信息,它执行相应的控制操作,如调整存储卷、进行健康检查等,并将结果报告给 Kube-APIServer,从而更新集群的状态。
1.4Kubernetes网络模型:
(1)Pod 和 Service 的网络通信
Kubernetes 的网络模型基于 Pod 和 Service 的通信,通过统一的 IP 地址和端口分配,确保集群内的各个组件能够无缝通信。
(2)Pod 网络
每个 Pod 一个 IP:每个 Pod 都有一个唯一的 IP 地址,这个 IP 地址在整个集群内都是可达的。
① Pod 间通信:Pod 可以直接通过 IP 地址互相通信,无需进行 NAT(网络地址转换)。
② Pod 网络插件:Kubernetes 支持多种网络插件(如 Flannel、Calico、Weave),它们通过 CNI(Container Network Interface)接口与 Kubernetes 集成,提供灵活的网络实现。
(3)Service 网络
① 虚拟 IP:Service 在 Kubernetes 中有一个虚拟 IP 地址(Cluster IP),用于暴露一组 Pod。
② 服务发现:Service 的 IP 地址和端口通过 DNS 解析,使得客户端可以通过服务名访问相应的服务。
③ 负载均衡:Service 自动将请求分发到后端的多个 Pod 上,实现负载均衡。
1.5补充:
(1)kubeadm简介
kubeadm是Kubernetes主推的部署工具之一,主要用于快速创建和初始化Kubernetes集群
(2)kubectl简介
kubectl 是 Kubernetes 的一个命令行管理工具,可用于 Kubernetes 上的应用部署和日常管理。
2.Kubernetes集群的规划:
| 节点类型 | 主机名 | IP地址 | 硬件配置 |
| 控制平面节点 | master01 | 192.168.58.30 | CPU:4核;内存:2GB;硬盘:60GB |
| 工作节点 | node01 | 192.168.58.31 | CPU:2核;内存:2GB;硬盘:30GB |
| 工作节点 | node02 | 192.168.58.32 | CPU:2核;内存:2GB;硬盘:30GB |
3.准备主机节点:
3.1准备master01主机节点:
3.1.1克隆主机:
1.选中 配置好的CentOS-Stream-8主机(参考:基于VMware的Cent OS Stream 8安装与配置及远程连接软件的介绍_centos8stream-CSDN博客)。
2.然后通过,鼠标右键-》管理-》克隆,进入下图所示的克隆向导界面。
3.然后点击“下一页”,进入下图所示的界面。
4.然后点击“下一页”,进入下图所示的界面。
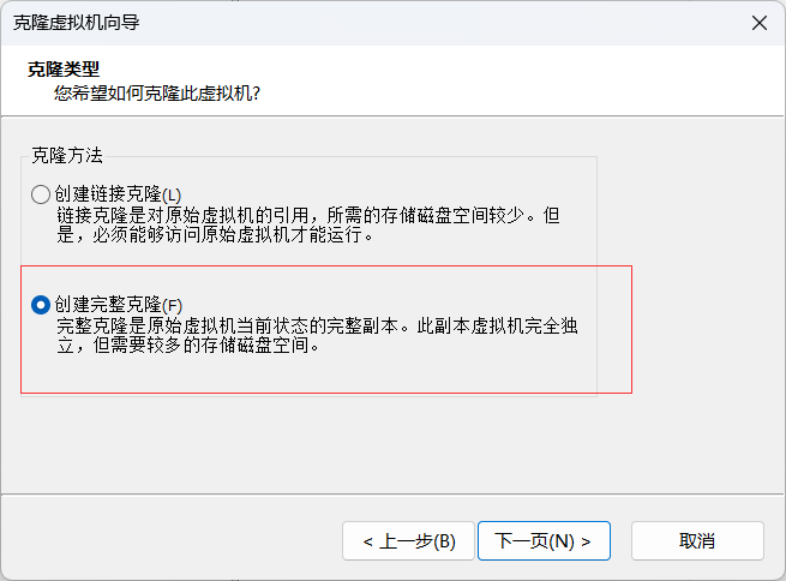
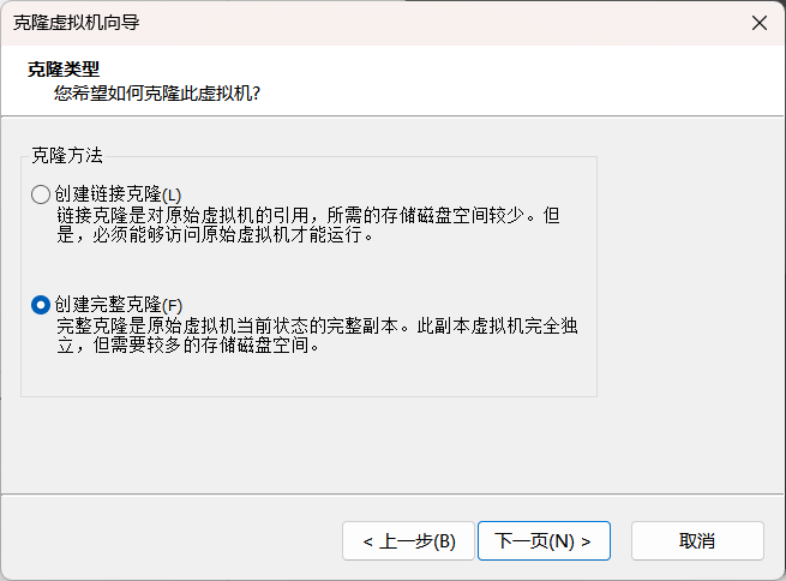
5.在上图所示的界面中,选择“创建完整克隆”,点击“下一页”,进入下图所示的界面。
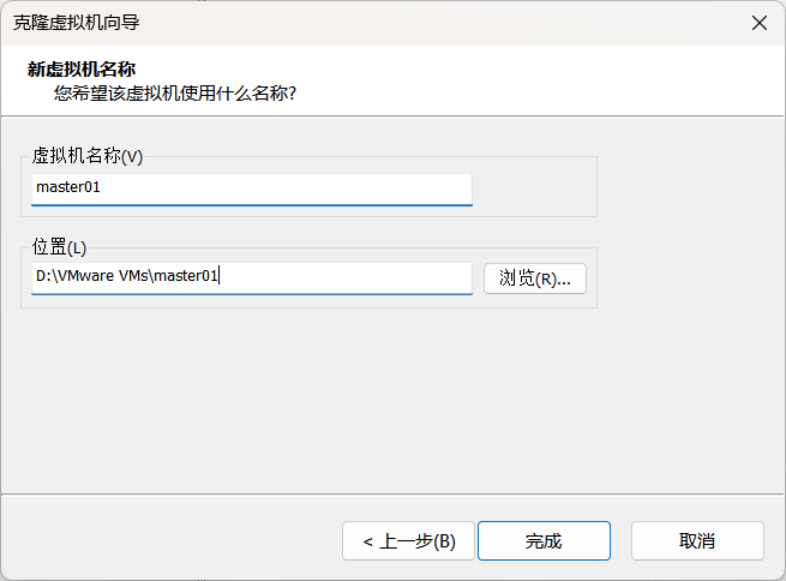
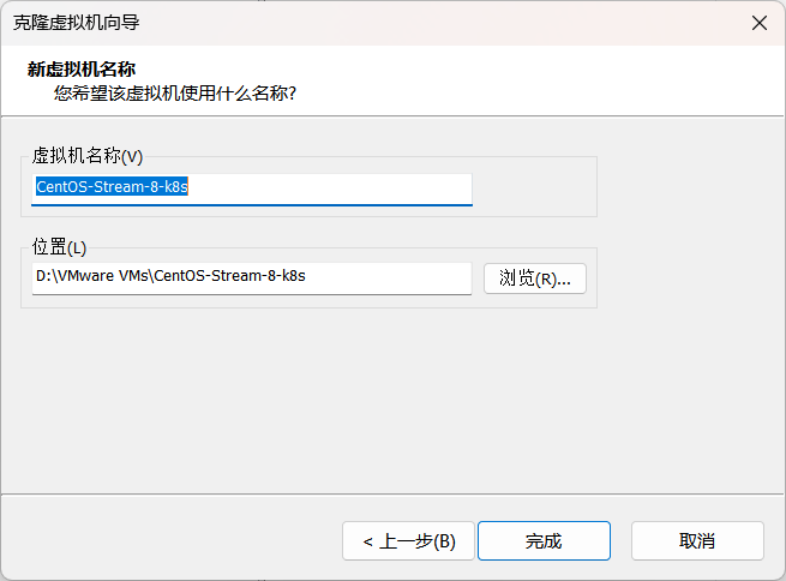
6.在上图所示的界面中,设置好新虚拟机的名字,点击完成,进行克隆,具体如下图所示。
7.克隆完成后,如下图所示。
8.在上图所示的界面中,点击关闭,查看新克隆出来的虚拟机master01,具体如下图所示。
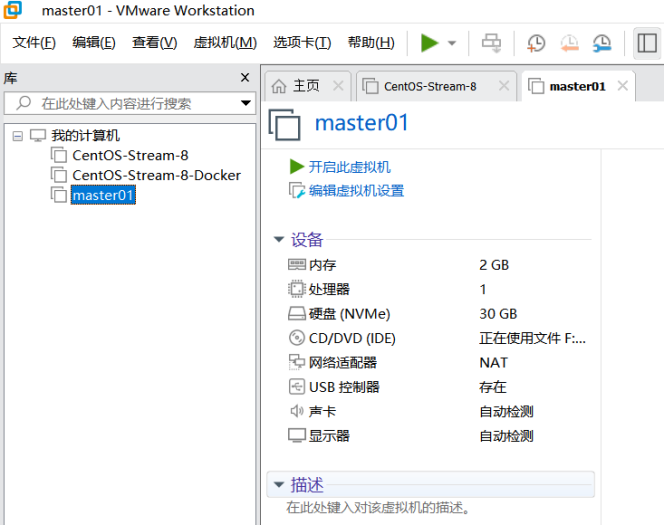
9.点击上图中的“开启此虚拟机”,启动master01,输入账号和密码,进入系统,如下图所示。
至此,通过从CentOS-Stream虚拟机进行克隆,我们完成了master的初始化。
3.1.2开启网络:
1.查看当前的网络连接信息。
nmcli connection show
2.使用以下命令修改网络连接配置。
nmcli connection modify ens160 ipv4.addr 192.168.58.30/24 ipv4.gateway 192.168.58.2 connection.autoconnect yes ipv4.dns "114.114.114.114"3.执行结果,具体如下图。

注意这里的ens160和图中的ens160是相对应的。
4.通过以下命令激活网络连接配置,使它生效。
nmcli connection up ens160
5. 在Firefox火狐狸浏览器中,访问百度首页,以确保网络联通。
3.1.3设置主机名:
1.使用以下命令将主机名更改为master01。
hostnamectl set-hostname master01
bash
3.1.4关闭交换区:
Linux中的交互区相当于与Window系统中的虚拟内存。交换器影响应用程序运行的性能与稳定性。从Kubernetes1.8版本开始要求关闭系统的交换区功能,否则Kubernetes1.8无法启动。
1.执行以下命令临时关闭交换区。
swapoff -a2.查看当前内存,可以发现Swap的各项值均为0,表明交换区已经关闭。
free -m
3. 为了重启后依然关闭交换区,使用sed命令将/etc/fstab中Swap自动挂载的语句注释掉。
sed -ri 's/.*swap.*/#&/' /etc/fstab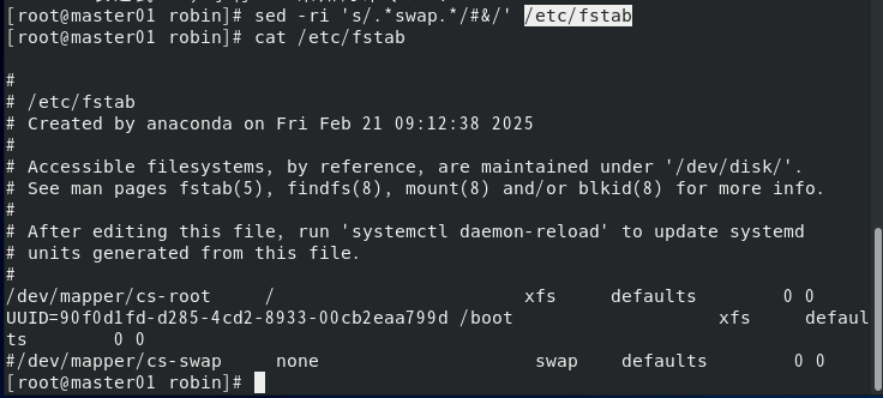
3.1.5设置系统同步时间:
1. Kubernetes集群各节点的时间必须同步。Linux系统中,通常通过安装npdate和chrony来提供时间同步功能。本实验安装chrony。
yum install -y chrony2.修改/etc/chrony.conf配置文件,注释掉原有的时间服务器地址(如果有),然后增加阿里云和腾讯云的时间服务器。
server ntp1.aliyun.com iburst
server ntp2.aliyun.com iburst
server ntp1.tencent.com iburst
server ntp2.tencent.com iburst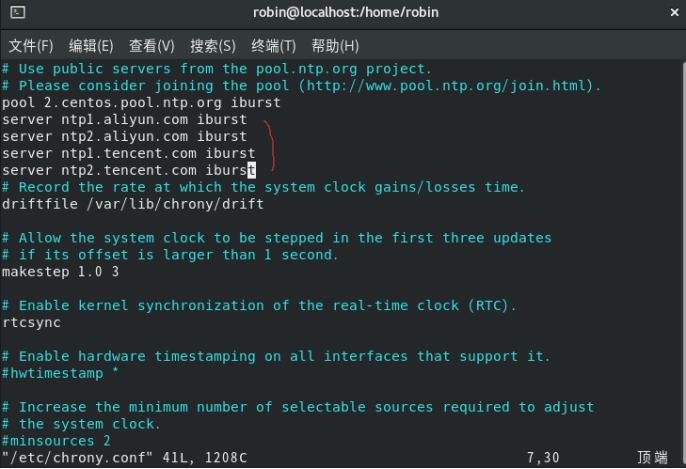
3. 重启chrony, 并查看同步情况以测试时间同步设置。
systemctl restart chronyd.service
chronyc sources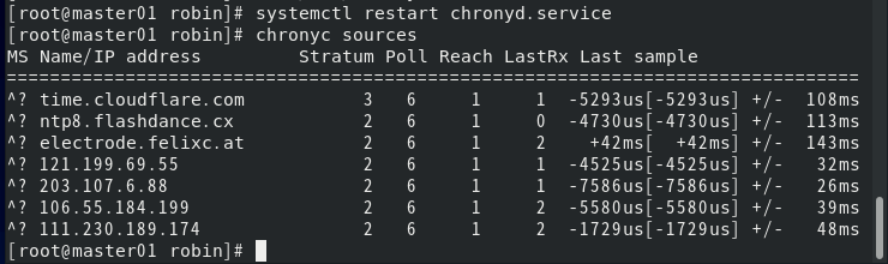
3.1.6配置主机名解析:
1.将以下主机名(主机域名)与IP地址之间的映射信息追加到/etc/hosts配置文件中。
# 这里使用自己规划主机的IP和域名
192.168.58.30 master01
192.168.58.31 node01
192.168.58.32 node02
3.1.7安装IPVS相关工具:
IPVS(IP Virtual Server)是Linux内核的一部分,主要用于实现高性能的第四层负载均衡。它运行在主机上,将来自客户端的请求根据预设的调度算法分发到一组真实服务器上,这些真实服务器提供实际的服务。
IPVS相比其他负载均衡解决方案(如LVS的NAT模式、HAProxy等)的优势在于其高性能和低延迟。由于IPVS在内核级别工作,它可以绕过用户空间的数据拷贝和上下文切换,从而提供更高的吞吐量和更低的延迟。此外,IPVS还支持多种调度算法和持久性机制,使其能够适应不同的负载均衡需求。
IPVS的管理程序是ipvsadm。ipvsadm支持直接路由、IP隧道和NAT这中转发模式。
ipset是Linux内核提供的一种高效的数据存储和查询工具,专为管理大规模IP地址设计。ipset允许管理员创建、管理和查询IP集合,这些集合可以包含IP地址、端口、网络等元素。通过使用ipset,管理员可以更方便地管理大量的IP地址,特别是在需要频繁更新或查询IP地址时。
1.安装ipset和ipvsadm。
yum install -y ipset ipvsadm2.为kub-proxy启用IPVS的前提是加载相应的Linux内核模块。配置/etc/sysconfig/ipvsadm/ipvs.modules脚本文件,以加载所需的内核模块。
mkdir -p /etc/sysconfig/ipvsadm
cat > /etc/sysconfig/ipvsadm/ipvs.modules <<EOF
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack
EOF3.给定文件权限。
chmod 755 /etc/sysconfig/ipvsadm/ipvs.modules4.执行该脚本,检查是否已经加载IPVS所需的模块。
bash /etc/sysconfig/ipvsadm/ipvs.modules
lsmod | grep -e ip_vs -e nf_conntrack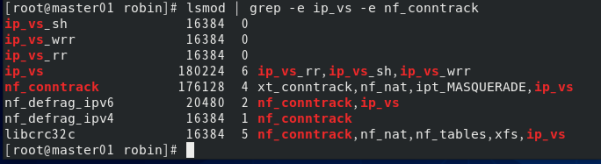
3.2安装containerd相关工具:
从Kubernetes1.23版本开始,容器运行时默认不再采用docker/dockershim,而建议采用containerd。因此,本实验采用containerd。
3.2.1调整内核参数:
1.与Docker作为容器运行时不同,containerd要配置相关内核参数。
执行以下命令加载所需的两个内核模块。
modprobe overlay
modprobe br_netfilter2.要允许iptables检查桥连接流量,就要显示加载br_netfilter模块。
通过以下命令,检查br_netfilter是否加载成功,具体下图所示。
lsmod | grep br_netfilter
3.通过以下命令在/etc/modules-load.d/目录下创建一个新的配置文件(br_netfilter.conf)。
echo "br_netfilter" | tee -a /etc/modules-load.d/br_netfilter.conf3.2.2开启路由转发及网桥过滤:
1.编辑/etc/modules-load.d/containerd.conf文件,在其中加入以下内容以配置containerd所需的内核参数。
cat > /etc/modules-load.d/containerd.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward=1
EOF2.前面两个参数的用途是让Linux节点的iptables能够正确查看桥接流量,最后一个参数用于启用IP转发。
执行以下命令使以上内核参数的调整生效。
sysctl -p /etc/modules-load.d/containerd.conf
3.2.3下载containerd软件包:
wget https://github.com/containerd/containerd/releases/download/v1.6.8/cri-containerd-1.6.8-linux-amd64.tar.gz
3.2.4将该软件包解压到系统根目录:
tar -zxvf cri-containerd-1.6.8-linux-amd64.tar.gz -C /3.2.5修改/etc/containerd/config.toml配置文件.
1.containerd 的配置文件位于/etc/containerd/config.toml,默认是没有的,通过以下命令生成一个默认配置。
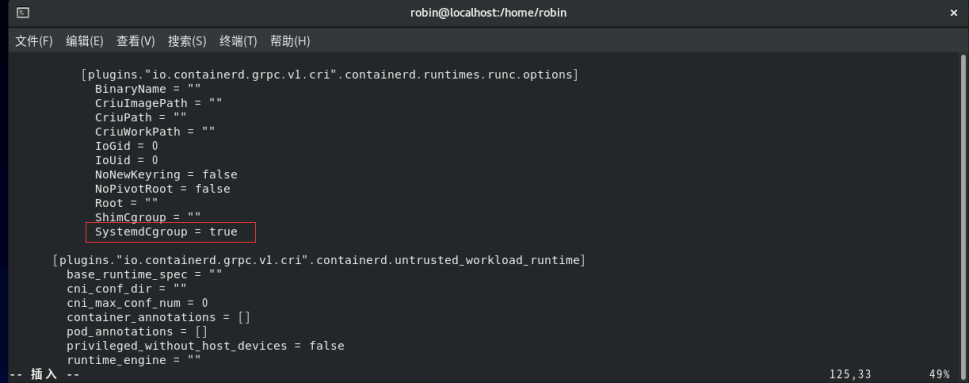
mkdir /etc/containerd
containerd config default > /etc/containerd/config.toml2.将SystemCgroup值设置为true。
3. 将sandbox_image值设置为国内基础镜像源地址。
sandbox_image = "registry.aliyuncs.com/google_containers/pause:3.8"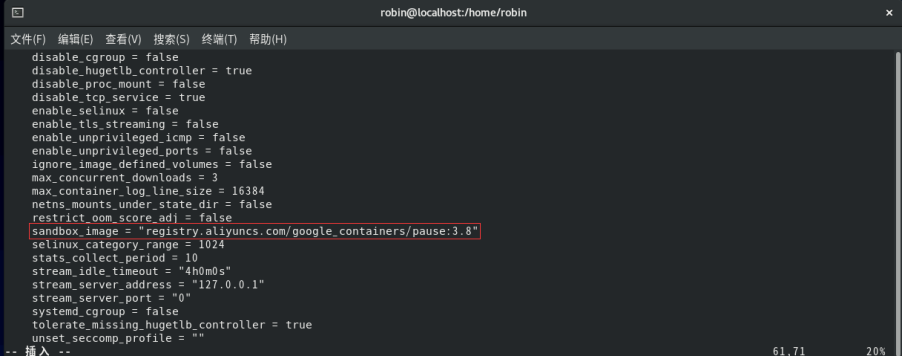
4. 修改中央仓库地址(镜像源)。
[plugins."io.containerd.grpc.v1.cri".registry.mirrors]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."docker.io"]
endpoint = ["https://docker.m.daocloud.io"]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."k8s.gcr.io"]
endpoint = ["https://registry.cn-hangzhou.aliyuncs.com/google_containers"]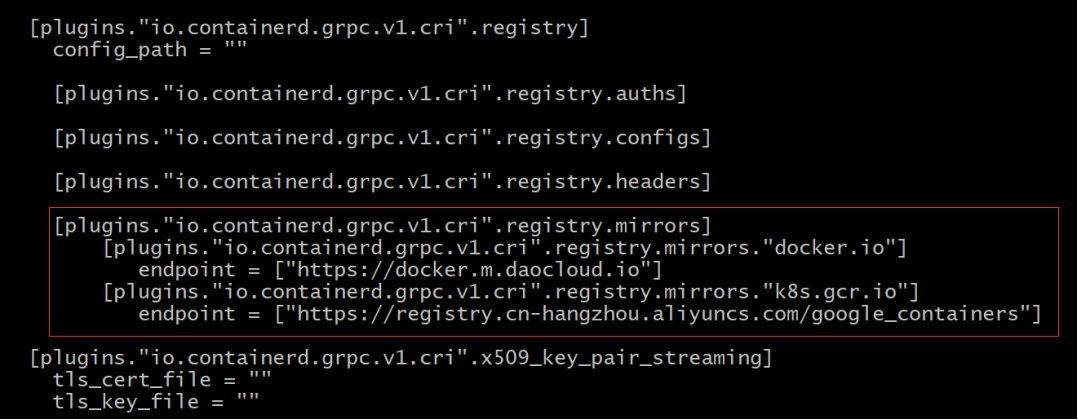
3.2.6 启动containerd并设置开机启动:
systemctl daemon-reload
systemctl enable containerd
systemctl start containerd3.2.7查看containerd的版本信息:
crictl version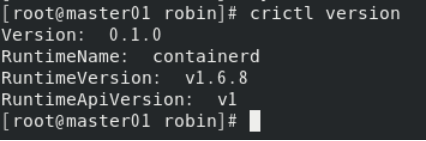
3.3添加Kubernetes组件的阿里云软件源:
1.创建/etc/yum.repos.d/kubernerts.repo,然后在其中添加以下配置。
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg2.执行以下命令查看当前可以安装的Kubernetes版本。
yum list kubeadm.x86_64 --showduplicates|sort -r |grep 1.25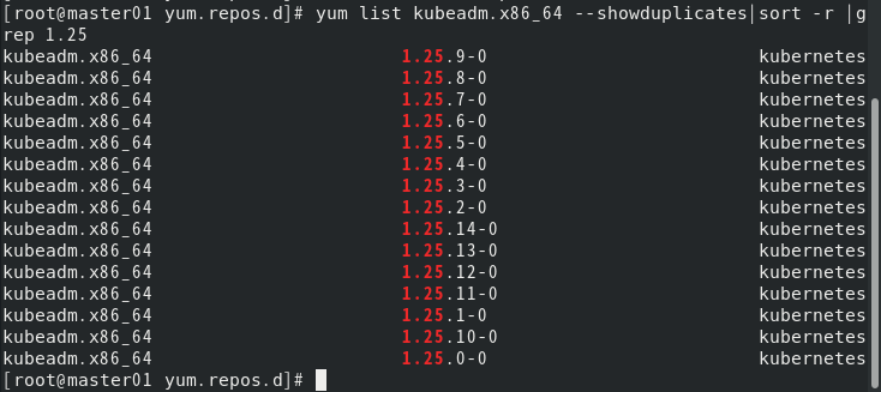
3.4 安装kubeadm、kubelet和kubectl:
kubeadm是用于初始化集群的工具
kubelet用来在集群的每个节点上启动Pop和容器
kubectl用来与集群通信的命令行工具。
1.执行以下命令进行安装。
yum install -y kubelet-1.25.4 kubeadm-1.25.4 kubectl-1.25.42.安装完毕后,启动kublete并将其设置为开机自动启动。
systemctl enable kubelet
systemctl start kubelet3.运行以下命令查看kubelet的当前版本。
kubelet --version
4. 拍摄快照和母机:
4.1拍摄快照存档:
选中master01虚拟机,点击鼠标右键,通过拍照-》拍摄快照进行快照存档,具体如下图所示。
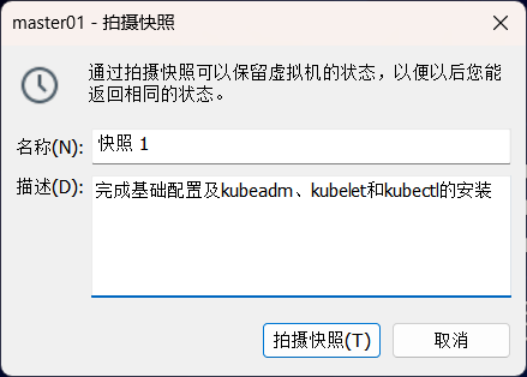
4.2母机克隆:
1.基于master01主机,克隆产生k8s母机,具体如下图所示。
5.准备node1节点主机:
5.1克隆node1节点主机:
基于CentOS-Stream-8-k8s主机克隆产生node1节点主机。
5.2设置IP地址:
1.查看当前的网络连接信息,具体命令如下所示。
nmcli connection show2.使用以下命令修改网络连接配置。
nmcli connection modify ens160 ipv4.addr 192.168.58.31/24 ipv4.gateway 192.168.58.2 connection.autoconnect yes ipv4.dns "114.114.114.114"3.通过以下命令激活网络连接配置,使它生效。
nmcli connection up ens1604.、在Firefox火狐狸浏览器中,访问百度首页,以确保网络联通。
5.3 设置主机名:
使用以下命令将主机名更改为node01。
hostnamectl set-hostname node01
bash6.准备node2节点主机:
6.1克隆node2节点主机:
基于CentOS-Stream-8-k8s主机克隆产生node2节点主机。
6.2设置IP地址:
1.查看当前的网络连接信息,具体命令如下所示。
nmcli connection show2.使用以下命令修改网络连接配置。
nmcli connection modify ens160 ipv4.addr 192.168.58.32/24 ipv4.gateway 192.168.58.2 connection.autoconnect yes ipv4.dns "114.114.114.114"3.通过以下命令激活网络连接配置,使它生效。
nmcli connection up ens1604.在Firefox火狐狸浏览器中,访问百度首页,以确保网络联通。
6.3 设置主机名:
使用以下命令将主机名更改为node02。
hostnamectl set-hostname node02
bash7.SSH免密登录配置:
7.1master01主机SSH免密登录:
7.1.1在master01主机中,使用以下指令创建master01主机自己的SSH密钥对(公钥+私钥):
ssh-keygen -t rsa注意这里一路回车就可以。
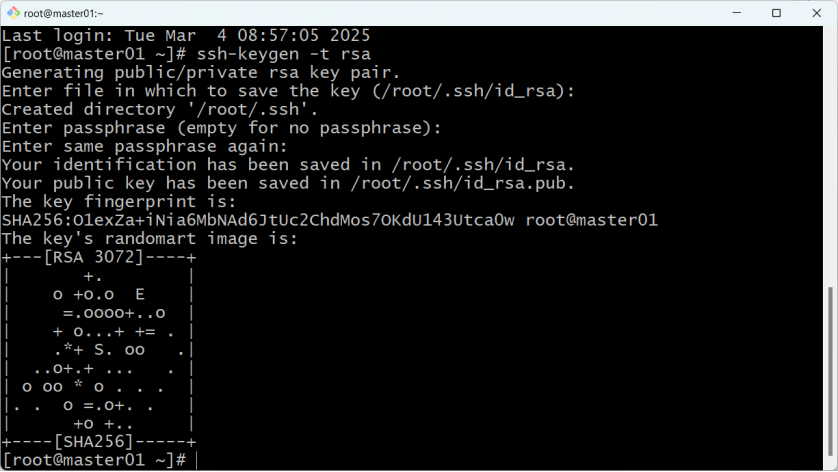
如果询问是否重新覆盖已有的密钥,请输入y就行。
7.1.2使用“ssh-copy-id 用户名@主机名”命令,把本机公钥拷贝到master01节点:
ssh-copy-id root@master01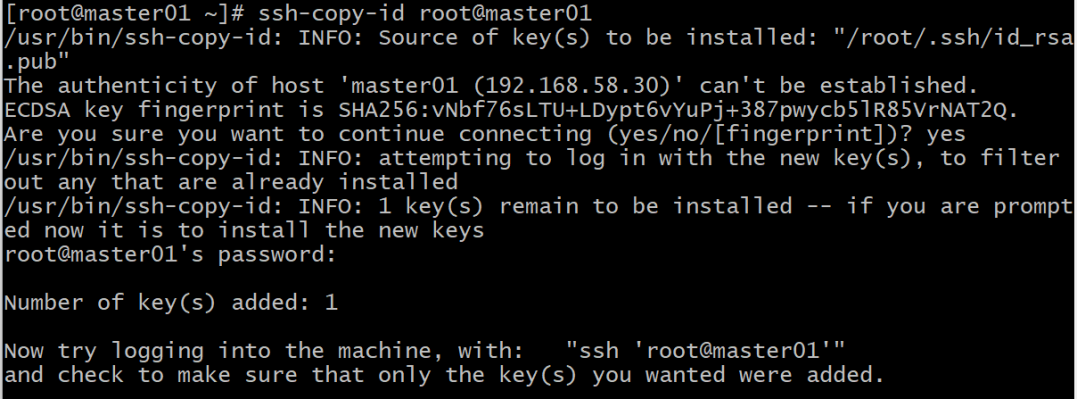
注意此过程中,需要输入master01主机root用户的密码。
接着,使用“ssh 用户名@主机名”的命令形式进行SSH免密登录。
ssh root@master01
如果执行该命令,不再需要输入密码,那么代表配置成功。否则,失败!
7.1.3使用“ssh-copy-id 用户名@主机名”命令,把本机公钥拷贝到node01节点:
ssh-copy-id root@node01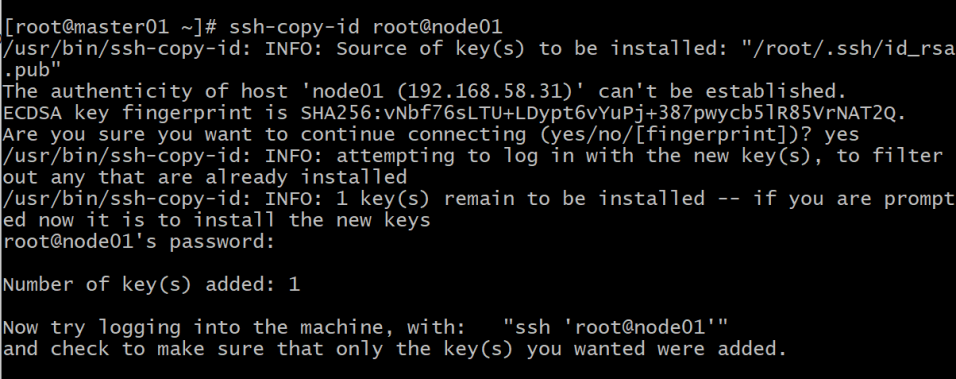
注意此过程中,需要输入node01主机root用户的密码。
接着,使用“ssh 用户名@主机名”的命令形式进行SSH免密登录。
ssh root@node01
如果执行该命令,不再需要输入密码,那么代表配置成功。否则,失败!
7.1.4 使用exit命令从node01回到master01主机:
exit然后使用“ssh-copy-id 用户名@主机名”命令,把本机RSA公钥拷贝到node02节点。
ssh-copy-id root@node02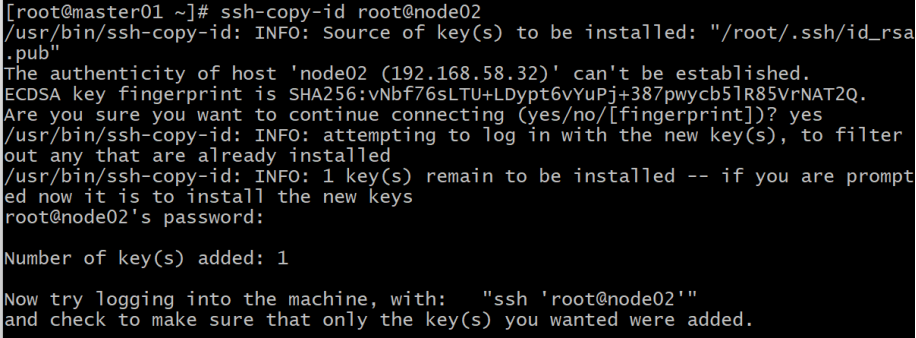
注意此过程中,需要输入node02主机root用户的密码。
接着,使用“ssh 用户名@主机名”的命令形式进行SSH免密登录。
ssh root@node02如果执行该命令,不再需要输入密码,且登录node02成功;那么代表配置成功。否则,失败!
7.2node01主机SSH免密登入:
7.2.1在node01主机中,使用以下指令创建node01主机自己的SSH密钥对(公钥+私钥):
ssh-keygen -t rsa注意这里一路回车就可以。
如果询问是否重新覆盖已有的密钥,请输入y就行。
7.2.2使用“ssh-copy-id 用户名@主机名”命令,把本机公钥拷贝到master01节点:
ssh-copy-id root@master01接着,使用“ssh 用户名@主机名”的命令形式进行SSH免密登录。
ssh root@master01如果执行该命令,不再需要输入密码,且登录master01成功;那么代表配置成功。否则,失败!
7.2.3使用exit命令回到node01主机:
exit然后使用“ssh-copy-id 用户名@主机名”命令,把本机公钥拷贝到node01节点。
ssh-copy-id root@node01接着,使用“ssh 用户名@主机名”的命令形式进行SSH免密登录。
ssh root@node01如果执行该命令,不再需要输入密码,那么代表配置成功。否则,失败!
7.2.4使用“ssh-copy-id 用户名@主机名”命令,把本机RSA公钥拷贝到node02节点:
ssh-copy-id root@node02接着,使用“ssh 用户名@主机名”的命令形式进行SSH免密登录。
ssh root@node02如果执行该命令,不再需要输入密码,且登录node02成功;那么代表配置成功。否则,失败!
7.3node02主机SSH免密登录:
7.3.1在node02主机中,使用以下指令创建node01主机自己的SSH密钥对(公钥+私钥):
ssh-keygen -t rsa注意这里一路回车就可以。
如果询问是否重新覆盖已有的密钥,请输入y就行。
7.3.2使用“ssh-copy-id 用户名@主机名”命令,把本机公钥拷贝到master01节点:
ssh-copy-id root@master01接着,使用“ssh 用户名@主机名”的命令形式进行SSH免密登录。
ssh root@master01如果执行该命令,不再需要输入密码,且登录master01成功;那么代表配置成功。否则,失败!
7.3.3使用exit命令回到node02主机:
exit然后使用“ssh-copy-id 用户名@主机名”命令,把本机公钥拷贝到node01节点。
ssh-copy-id root@node01接着,使用“ssh 用户名@主机名”的命令形式进行SSH免密登录。
ssh root@node01如果执行该命令,不再需要输入密码,那么代表配置成功。否则,失败!
7.3.4使用exit命令回到node02:
exit使用“ssh-copy-id 用户名@主机名”命令,把本机RSA公钥拷贝到node02节点。
ssh-copy-id root@node02接着,使用“ssh 用户名@主机名”的命令形式进行SSH免密登录。
ssh root@node02如果执行该命令,不再需要输入密码,且登录node02成功;那么代表配置成功。否则,失败!
8. Kubernetes集群初始化:
8.1初始化master01控制平面节点:
使用kubeadm命令初始化控制平面节点有以下两种方式。
①使用配置文件。这种方式使用--config选项指定配置文件。不过我们通常使用kubeadm config命令生成默认的配置文件,再根据需要修改后即可完成初始化。
②直接命令行选项参数进行初始化配置。
本实验采用直接命令行选项参数的方式初始化控制平面节点。
1.在master01中,执行以下命令。
kubeadm init \
--apiserver-advertise-address 192.168.56.30 \ # 使用自己主机IP
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version v1.25.4 \
--service-cidr=10.96.0.0/12 \
--pod-network-cidr=10.244.0.0/16 \
--ignore-preflight-errors=all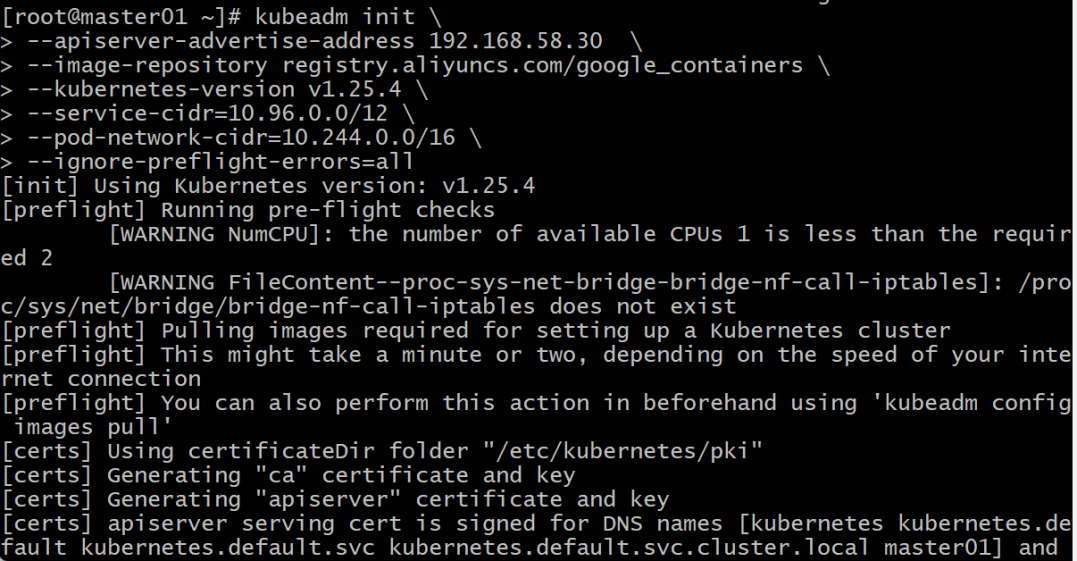
2.第一次执行该命令的时候,会非常慢。如果支持成功,最终结果如下图 :
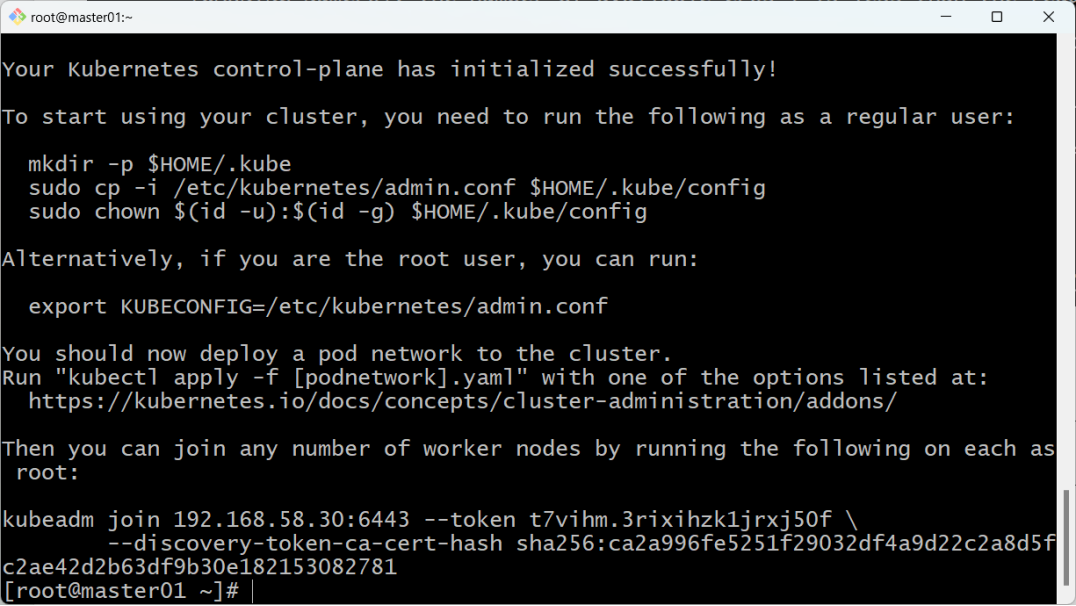
3. 同时,注意上图中的以下提示(复制自己生成的):
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.58.30:6443 --token t7vihm.3rixihzk1jrxj50f \
--discovery-token-ca-cert-hash sha256:ca2a996fe5251f29032df4a9d22c2a8d5fc2ae42d2b63df9b30e1821530827818.2为kubectl命令提供配置文件:
通过上一步的kubeadm init,系统为我们生成了一个Kubernetes系统管理员权限的认证配置文件/etc/kubernetes/admin.conf。
1.现在我们按照图8-2的提示,将该配置文件复制到该目录的config子目录以便运行kubectl。
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config2.执行完上述命令,我们就可以使用kubectl命令查看当前的集群节点信息。
kubectl get node
目前集群中有且仅有一个节点,master01控制平面节点。
8.3将工作节点加入集群:
8.3.1在node01主机中,根据图8-2的提示,执行以下命令将其加入到集群中:
使用自己生成的。
kubeadm join 192.168.58.30:6443 --token t7vihm.3rixihzk1jrxj50f \
--discovery-token-ca-cert-hash sha256:ca2a996fe5251f29032df4a9d22c2a8d5fc2ae42d2b63df9b30e182153082781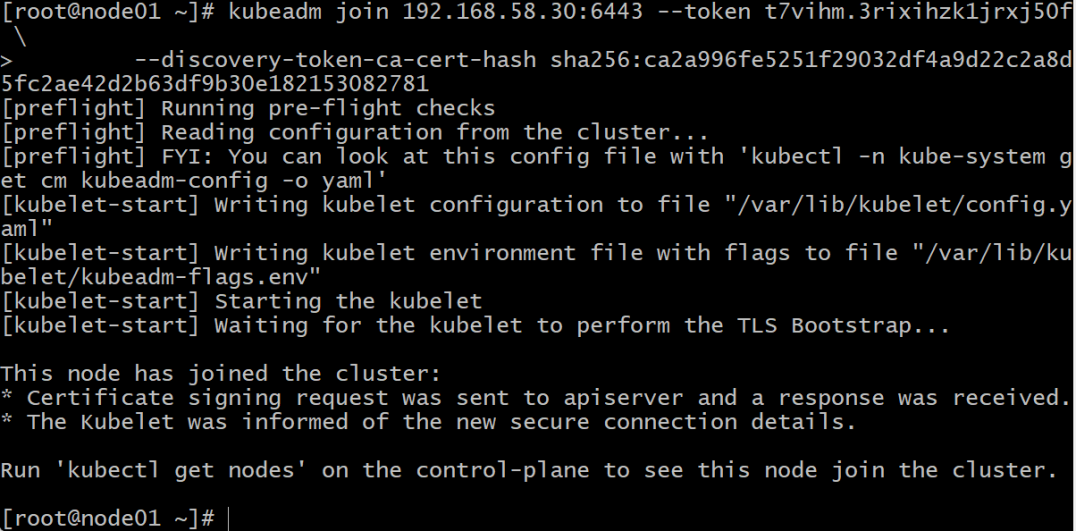
8.3.2 在node02主机中,根据图8-2的提示,执行以下命令将其加入到集群中:
kubeadm join 192.168.58.30:6443 --token t7vihm.3rixihzk1jrxj50f \
--discovery-token-ca-cert-hash sha256:ca2a996fe5251f29032df4a9d22c2a8d5fc2ae42d2b63df9b30e182153082781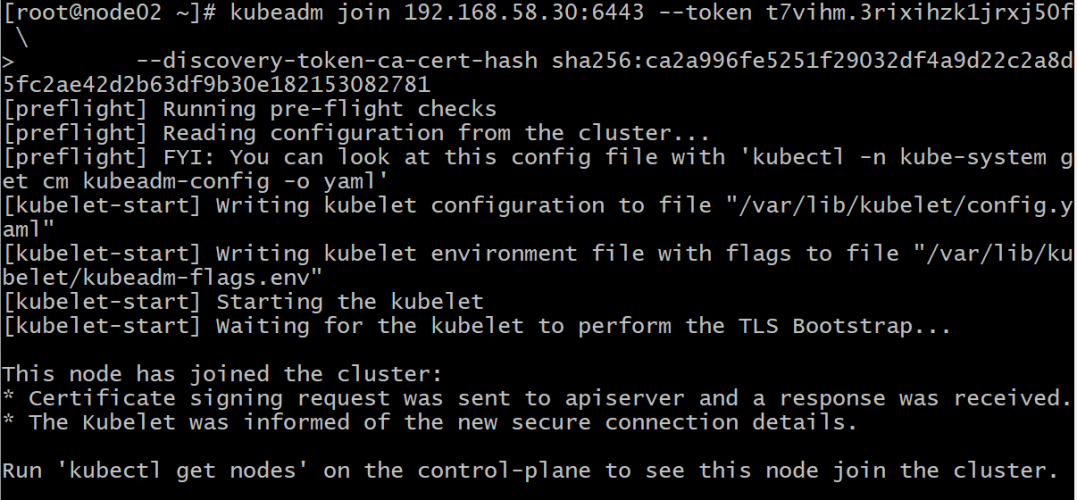
8.8.3 在master01主机中,执行以下命令,查看节点信息:
kubectl get node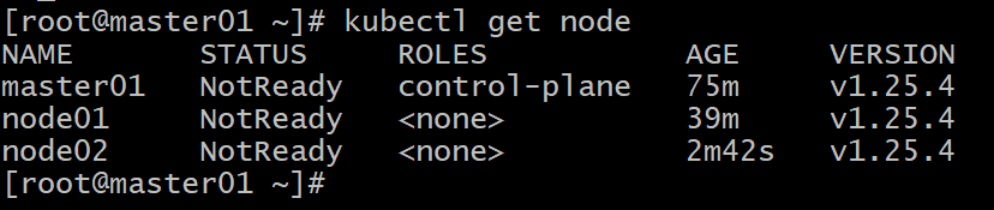
集群中右增加了两个工作节点。
另外,请注意加入工作节点令牌默认有效期为24小时,过去之后该令牌就不可用了。如果有需要。最简单的就是在master01主机,使用以下命令创建新的令牌。
kubeadm token create --print-join-command
9. 安装Pod网络插件:
Calico是一款开源的网络和安全解决方案,专为容器化应用而设计,基于Kubernetes的网络插件模型.Calico为每个容器或虚拟机分配一个独立的网络命名空间,以避免潜在的网络冲突。这些命名空间各自拥有独特的IP地址和路由表。
9.1在master01主机中,从官网下载安装Calico插件所需的配置文件calico.yaml:
wget https://docs.projectcalico.org/manifests/calico.yaml9.2修改calico.yam配置文件,将其中的值为之前执行kubeadm init命令时通过--pod-network-cidr选项指定的Pod网络地址:
-name:CALICO_IPV4POOL_CIDR
Value:”10.244.0.0/16”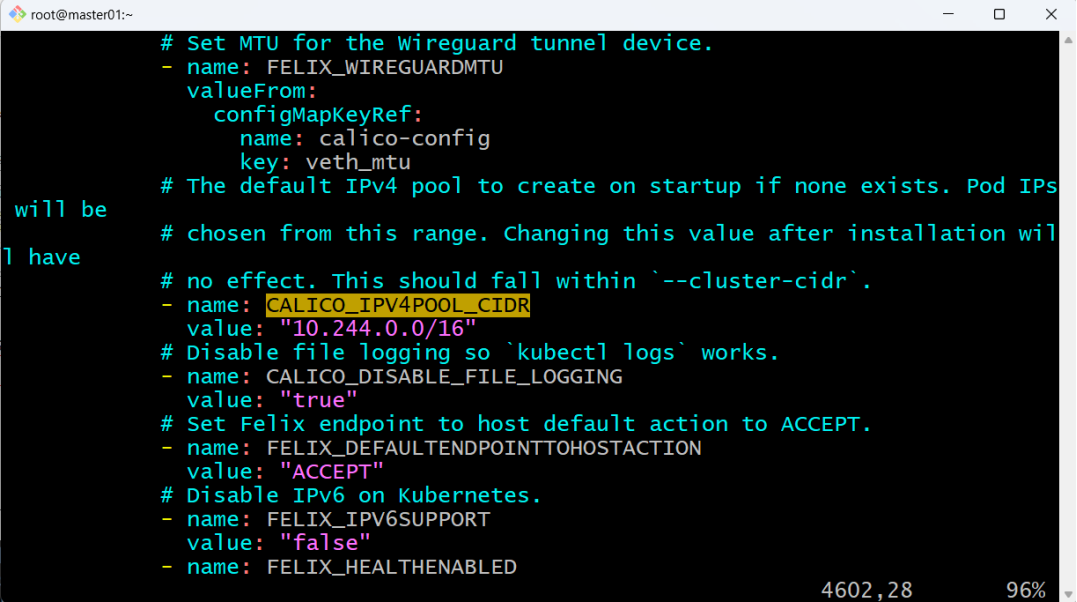
9.3 执行以下命令使用配置calico.yaml,在集群中部署Calico插件(创建多种Kubernetes资源):
kubectl apply -f calico.yaml
这个过程可能有点慢,请耐心等待。
9.4查看名称空间kube-system下的所有Pod:
kubectl get pods -n kube-system 9.5执行以下命令进一步查看Calica插件在各节点上的部署情况:
kubectl get po -A -o wide|grep calico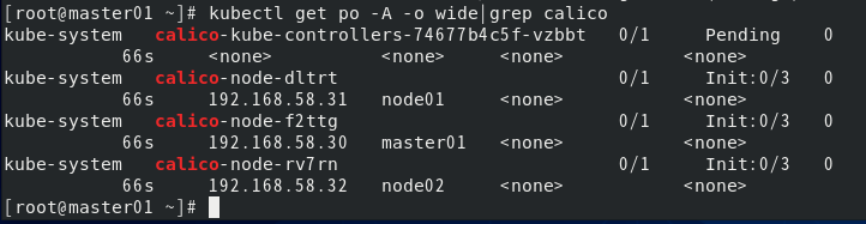
10. 测试Kubernetes集群:
尝试在Kubernetes集群部署运行nginx,以测试Kubernetes集群的可用性。
10.1在master01主机上,执行以下命令创建高一个简单的Deployment以运行nginx:
kubectl create deployment nginx --image=nginx:latest
10.2 在master01主机上,执行以下命令将该deployment 发布为Service以供外部访问:
kubectl expose deployment nginx --port 80 --type=NodePort
以上命令用于将一个名为 nginx 的 Deployment 暴露为一个 NodePort 类型的 Service,从而允许外部流量通过集群的节点访问该 Deployment 中的 Pod。
- kubectl expose deployment nginx:将名为 nginx 的 Deployment 暴露为一个 Service。
- --port 80:指定 Service 的端口为 80,这意味着从外部访问时,请求会被转发到 Pod 的 80 端口。
- --type=NodePort:指定 Service 的类型为 NodePort。NodePort 类型的 Service 会在每个节点上开放一个端口(通常在 30000-32767 范围内),从而允许外部流量通过节点访问集群内的 Pod。
10.3 在master01主机上,查看创建的Pod和Service是否正常运行:
kubectl get pod,svc
注意上图中的READY正常应该为1/1。
如果这里READY为0,可以通过使用 kubectl logs <pod-name> 查看容器日志或者使用 kubectl describe pod <pod-name> 查看详细信息。
如果日志显示拉取镜像失败,那么仔细检查图3-23中containerd镜像源配置或者使用以下命令强行直接拉取镜像。
ctr images pull docker.m.daocloud.io/library/nginx:latest10.4通过以下命令访问发布的nginx服务器:
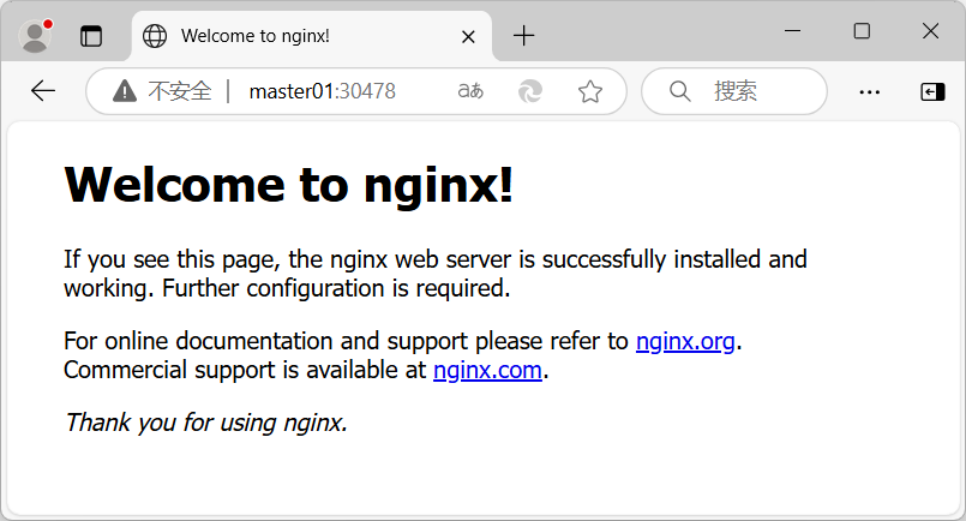
curl http://master01:30478
curl http://node01:30478
curl http://node02:30478或者直接通过浏览器进行访问,具体如下图所示。
到此整个实验结束。