蓝桥杯备赛知识点总结

一、数论
如果想要计算整除向上取整(x+y-1)/y 或者(x-1)/y +1
最大公约数:
int gcd(int a,int b){
return b==0?a:gcd(b,a%b);
}
最小公倍数:
int lcm(int a,int b){
return a/gcd(a,b)*b;
}埃氏筛法:
// C++ program to print all primes smaller than or equal to
// n using Sieve of Eratosthenes
#include <bits/stdc++.h>
using namespace std;
void SieveOfEratosthenes(int n)
{
// Create a boolean array "prime[0..n]" and initialize
// all entries it as true. A value in prime[i] will
// finally be false if i is Not a prime, else true.
vector<bool> prime(n + 1, true);
for (int p = 2; p * p <= n; p++) {
if (prime[p] == true) {
// Update all multiples of p greater than or
// equal to the square of it numbers which are
// multiple of p and are less than p^2 are
// already been marked.
for (int i = p * p; i <= n; i += p)
prime[i] = false;
}
}
// Print all prime numbers
for (int p = 2; p <= n; p++)
if (prime[p])
cout << p << " ";
}
// Driver Code
int main()
{
int n = 30;
cout << "Following are the prime numbers smaller "
<< " than or equal to " << n << endl;
SieveOfEratosthenes(n);
return 0;
}唯一分解定理:
#include<bits/stdc++.h>
using namespace std;
vector<pair<int,int>> nums;
int main(){
int x;
cin>>x;
for(int i=2;i<x/i;i++){
if(x%i){continue;}
int cnt=0;
while(x%i==0){cnt++;x/=i;}
nums.push_back({i,cnt});
}
if(x>1){
nums.push_back({x,1});
}
int v=nums.size();
for(const auto i: nums){
cout<<i.first<<"^"<<i.second<<endl;
}
return 0;
}快速幂:
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
int qmi(ll a,ll b){
ll res=1;
while(b){
if(b&1){res=res*a;}
a=a*a;
b>>=1;
}
return res;
}
int main(){
ll x,n;
cin>>x>>n;
ll ans=qmi(x,n);
cout<<ans;
return 0;
}费马小定理:
当 p 是质数时,a 的 (p−1)次方除以 p 的余数必为1
逆元:
ll inv(ll x){
return qmi(x,p-2);
}欧拉函数:

二、组合数学
杨辉三角
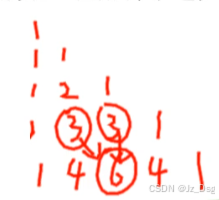
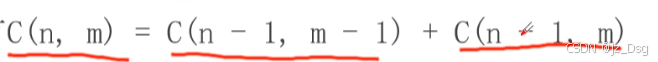
dp法求组合数:
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
vector<vector<int>> dp;
int main(){
ll n,m,c;
cin>>n>>m>>c;
dp.resize(n+1);
for(int i=0;i<=n;i++){
dp[i].resize(m+1);
dp[i][0]=1;
}
for(int i=1;i<=n;i++){
for(int j=1;j<=m;j++){
dp[i][j]=(dp[i-1][j]+dp[i-1][j-1])%c;
}
}
cout<<dp[n][m]<<endl;
return 0;
}const int N = 70;
LL C[N][N];
void init() {
for (int i = 0; i < N; i ++)
for (int j = 0; j <= i; j ++)
if (!j) C[i][j] = 1;
else C[i][j] = C[i - 1][j - 1] + C[i - 1][j];
}
int main() {
ios::sync_with_stdio(false);
cin.tie(nullptr), cout.tie(nullptr);
init();
LL ans = 0;
int n, m; cin >> n >> m;
for (int i = n; i <= m; i ++) ans += C[m][i];
cout << ans << endl;
return 0;
}预处理法求组合函数:仅仅适用于p为质数时候
公式: p+q=p⊕q+2×(p&q)
这个公式的核心思想是:二进制加法可以分解为无进位加法(XOR)和进位(AND)的组合。
三、并查集
- 寻找根节点,函数:find(int u),也就是判断这个节点的祖先节点是哪个
- 将两个节点接入到同一个集合,函数:join(int u, int v),将两个节点连在同一个根节点上
- 判断两个节点是否在同一个集合,函数:isSame(int u, int v),就是判断两个节点是不是同一个根节点
int n = 1005; // n根据题目中节点数量而定,一般比节点数量大一点就好
vector<int> father = vector<int> (n, 0); // C++里的一种数组结构
// 并查集初始化
void init() {
for (int i = 0; i < n; ++i) {
father[i] = i;
}
}
// 并查集里寻根的过程
int find(int u) {
return u == father[u] ? u : father[u] = find(father[u]); // 路径压缩
}
// 判断 u 和 v是否找到同一个根
bool isSame(int u, int v) {
u = find(u);
v = find(v);
return u == v;
}
// 将v->u 这条边加入并查集
void join(int u, int v) {
u = find(u); // 寻找u的根
v = find(v); // 寻找v的根
if (u == v) return ; // 如果发现根相同,则说明在一个集合,不用两个节点相连直接返回
father[v] = u;
}四、二维前缀和
#include<iostream>
using namespace std;
const int N = 1e4+10;
int n,m,q;
int a[N][N],s[N][N];
int main(){
scanf("%d %d %d",&n,&m,&q);
for(int i=1;i<=n;i++)
for(int j=1;j<=m;j++)
scanf("%d",&a[i][j]);3
for(int i=1;i<=n;i++)
for(int j=1;j<=m;j++)
s[i][j]=s[i][j-1]+s[i-1][j]-s[i-1][j-1]+a[i][j];
while(q--){
int l1,r1,l2,r2;
scanf("%d %d %d %d",&l1,&r1,&l2,&r2);
printf("%d",s[l2][r2]-s[l2][r1-1]-s[l1-1][r2]+s[l1-1][l2-1]);
}
return 0;
}
一维差分
#include <bits/stdc++.h>
using namespace std;
const int N = 1e5 + 10;
int a[N], diff[N]; // a为原数组,diff为差分数组
// 插入操作:对区间 [l, r] 加上c
void insert(int l, int r, int c) {
diff[l] += c;
diff[r + 1] -= c;
}
int main() {
int n, m;
cin >> n >> m;
for (int i = 1; i <= n; i++) {
cin >> a[i];
// 初始化差分数组:将每个元素视为对自身区间的插入
insert(i, i, a[i]);
}
while (m--) {
int l, r, c;
cin >> l >> r >> c;
insert(l, r, c); // 应用区间修改
}
// 计算前缀和得到最终结果
for (int i = 1; i <= n; i++) {
diff[i] += diff[i - 1];
cout << diff[i] << " ";
}
return 0;
}二维差分
#include <iostream>
using namespace std;
const int N = 1010;
int a[N][N], diff[N][N]; // a为原矩阵,diff为差分矩阵
// 插入操作:对子矩阵 (x1,y1)-(x2,y2) 加上c
void insert(int x1, int y1, int x2, int y2, int c) {
diff[x1][y1] += c;
diff[x2 + 1][y1] -= c;
diff[x1][y2 + 1] -= c;
diff[x2 + 1][y2 + 1] += c;
}
int main() {
int n, m, q;
cin >> n >> m >> q;
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= m; j++) {
cin >> a[i][j];
// 初始化差分矩阵:将每个元素视为对单点的插入
insert(i, j, i, j, a[i][j]);
}
}
while (q--) {
int x1, y1, x2, y2, c;
cin >> x1 >> y1 >> x2 >> y2 >> c;
insert(x1, y1, x2, y2, c); // 应用子矩阵修改
}
// 计算二维前缀和得到最终矩阵
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= m; j++) {
diff[i][j] += diff[i - 1][j] + diff[i][j - 1] - diff[i - 1][j - 1];
cout << diff[i][j] << " ";
}
cout << endl;
}
return 0;
}五、单调栈
// 版本一
class Solution {
public:
vector<int> dailyTemperatures(vector<int>& T) {
// 递增栈
stack<int> st;
vector<int> result(T.size(), 0);
st.push(0);
for (int i = 1; i < T.size(); i++) {
if (T[i] < T[st.top()]) { // 情况一
st.push(i);
} else if (T[i] == T[st.top()]) { // 情况二
st.push(i);
} else {
while (!st.empty() && T[i] > T[st.top()]) { // 情况三
result[st.top()] = i - st.top();
st.pop();
}
st.push(i);
}
}
return result;
}
};// 版本二
class Solution {
public:
vector<int> dailyTemperatures(vector<int>& T) {
stack<int> st; // 递增栈
vector<int> result(T.size(), 0);
for (int i = 0; i < T.size(); i++) {
while (!st.empty() && T[i] > T[st.top()]) { // 注意栈不能为空
result[st.top()] = i - st.top();
st.pop();
}
st.push(i);
}
return result;
}
};六、st表
用于多次查询区间中最大值或者最小值
#include <iostream>
#include <vector>
#include <cmath>
using namespace std;
const int MAXN = 1e5 + 5;
const int LOGN = 20; // 覆盖2^20的区间长度
int st[MAXN][LOGN]; // ST表存储最大值
int log_table[MAXN]; // 预处理log2向下取整
// 预处理log_table数组
void init_log(int n) {
log_table[1] = 0;
for (int i = 2; i <= n; i++)
log_table[i] = log_table[i/2] + 1;
}
// 构建ST表
void build_st(const vector<int>& arr) {
int n = arr.size();
for (int i = 0; i < n; i++)
st[i][0] = arr[i]; // 初始化长度为1的区间
for (int j = 1; (1 << j) <= n; j++) {
for (int i = 0; i + (1 << j) - 1 < n; i++) {
int prev = 1 << (j-1);
st[i][j] = max(st[i][j-1], st[i + prev][j-1]);
}
}
}
// 查询区间[l, r]的最大值
int query_max(int l, int r) {
int k = log_table[r - l + 1];
return max(st[l][k], st[r - (1 << k) + 1][k]);
}
int main() {
int n, q;
cout << "输入数组长度和查询次数: ";
cin >> n >> q;
vector<int> arr(n);
cout << "输入数组元素: ";
for (int i = 0; i < n; i++)
cin >> arr[i];
init_log(n); // 初始化log表
build_st(arr); // 构建ST表
while (q--) {
int l, r;
cout << "输入查询区间[l, r] (0-based): ";
cin >> l >> r;
if (l > r) swap(l, r);
cout << "最大值: " << query_max(l, r) << endl;
}
return 0;
}七、树状数组
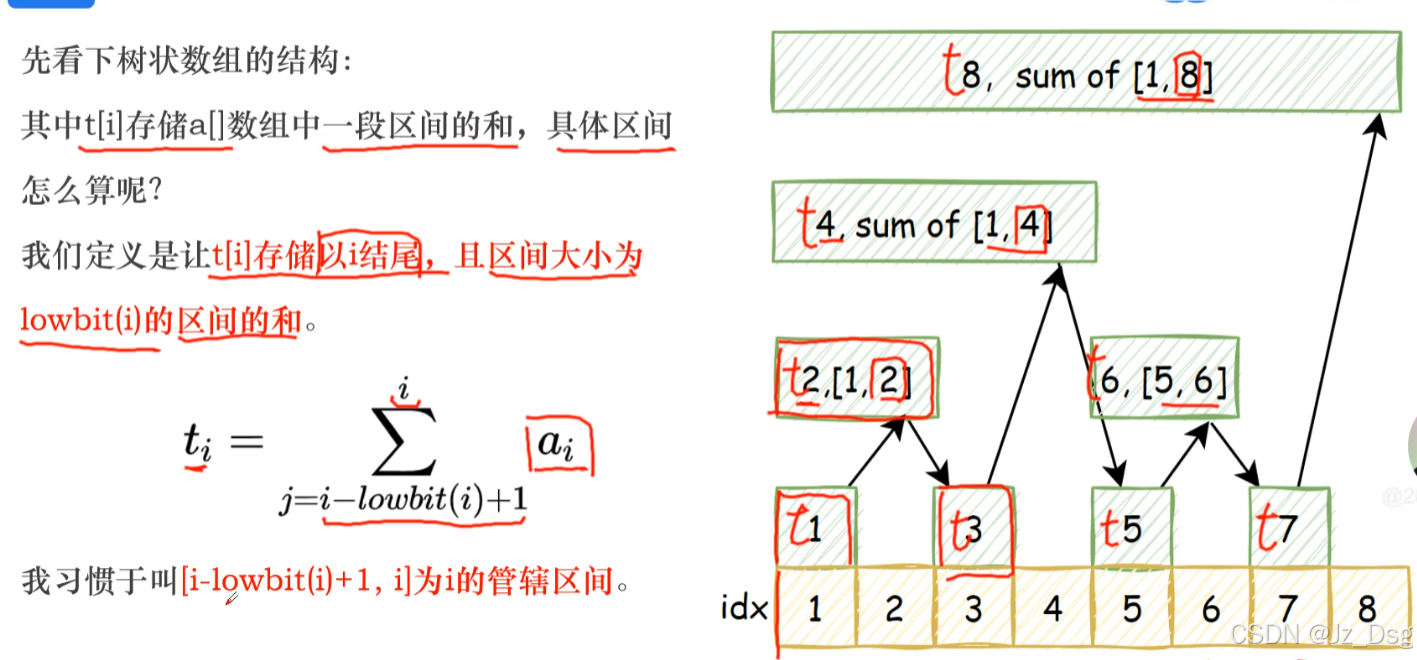 动态求区间和
动态求区间和
#include <bits/stdc++.h>
using namespace std;
int n, m; // 数据数量和操作次数
int tree[2000010]; // 树状数组(大小通常开2*n)
// 核心函数:获取数字二进制表示中最低位的1对应的值
int lowbit(int k) {
return k & -k; // 例如:k=6(110), lowbit(k)=2(10)
}
// 单点更新:在位置x处增加k
void add(int x, int k) {
while (x <= n) { // 从叶子节点向上更新
tree[x] += k; // 更新当前节点
x += lowbit(x); // 跳转到父节点(x += 最低位的1)
}
}
// 前缀和查询:计算[1, x]的区间和
int sum(int x) {
int ans = 0;
while (x != 0) { // 从右往左累加区间块
ans += tree[x]; // 累加当前节点值
x -= lowbit(x); // 跳转到前驱节点(x -= 最低位的1)
}
return ans;
}
int main() {
cin >> n >> m;
// 初始化树状数组(等效于逐个插入元素)
for (int i = 1; i <= n; i++) {
int a;
scanf("%d", &a);
add(i, a); // 将初始值插入树状数组
}
// 处理操作
for (int i = 1; i <= m; i++) {
int a, b, c;
scanf("%d%d%d", &a, &b, &c);
if (a == 1) {
add(b, c); // 在位置b处加c
} else if (a == 2) {
// 区间和 = [1,c]的和 - [1,b-1]的和
cout << sum(c) - sum(b - 1) << endl;
}
}
}-
八、字符串哈希
- 原理:选择两个大素数作为基数(Base)和模数(MOD),计算哈希值后取模。
- 公式:
hash[i]=(hash[i−1]×Base+str[i])mod MODhash[i]=(hash[i−1]×Base+str[i])modMOD
例如,Base=13,MOD=101时,字符串"abc"的哈希值为97 - 优点:冲突概率较低,适合多数场景。
-
#include<bits/stdc++.h> using namespace std; int n; const int base=131; long long mod=19260817; vector<int> hashnum; long long myhash(string s){ int n=s.size(); long long minhash; for(int i=0;i<n;i++){ minhash=minhash*base+s[i]%mod; } return minhash; } int main(){ cin>>n; hashnum.resize(n); for(int i=0;i<n;i++){ string s; cin>>s; hashnum[i]=myhash(s); } sort(hashnum.begin(),hashnum.end()); int ans=0; for(int i=0;i<n;i++){ if(hashnum[i]!=hashnum[i-1]){ ans++; } } cout<<ans; return 0; } -
#include <iostream> #include <string> #include <vector> using namespace std; class StringHash { private: static const int Base = 131; // 推荐的大素数,减少哈希冲突 static const int MOD = 1e9 + 7; // 大素数模数 vector<long long> hash; // 前缀哈希数组 vector<long long> p; // Base的幂次数组 public: // 初始化哈希数组和幂次数组 void init(const string &s) { int n = s.size(); hash.resize(n + 1, 0); p.resize(n + 1, 1); for (int i = 1; i <= n; ++i) { p[i] = (p[i-1] * Base) % MOD; // 计算Base^i % MOD hash[i] = (hash[i-1] * Base + s[i-1]) % MOD; // 前缀哈希计算 } } // 获取子串s[l..r)的哈希值(左闭右开区间) long long getHash(int l, int r) { if (l >= r) return 0; long long res = (hash[r] - hash[l] * p[r - l]) % MOD; return res < 0 ? res + MOD : res; // 处理负数结果 } }; int main() { string s = "abcabc"; StringHash sh; sh.init(s); // 示例:查询子串哈希 cout << "子串 [0,3) 的哈希值: " << sh.getHash(0, 3) << endl; // abc cout << "子串 [3,6) 的哈希值: " << sh.getHash(3, 6) << endl; // abc // 判断两个子串是否相等 if (sh.getHash(0, 3) == sh.getHash(3, 6)) { cout << "子串 abc 和 abc 哈希相等" << endl; } return 0; }九、图论
拓补排序
vector<int> topologicalSort(int n, vector<vector<int>>& edges) {
vector<vector<int>> adj(n + 1); // 邻接表(节点编号从1开始)
vector<int> inDegree(n + 1, 0); // 入度数组
vector<int> result; // 拓扑序列
// 1. 建图并统计入度
for (auto& e : edges) {
int u = e[0], v = e[1];
adj[u].push_back(v);
inDegree[v]++;
}
// 2. 初始化队列(入度为0的节点)
queue<int> q;
for (int i = 1; i <= n; i++) {
if (inDegree[i] == 0) q.push(i);
}
// 3. BFS处理拓扑排序
while (!q.empty()) {
int u = q.front();
q.pop();
result.push_back(u);
for (int v : adj[u]) {
inDegree[v]--;
if (inDegree[v] == 0) q.push(v);
}
}
// 4. 检测环:若结果长度≠节点数,说明存在环
if (result.size() != n) return {};
return result;
}Floyd
#include <bits/stdc++.h>
using namespace std;
const int N = 405;
const int INF = 0x3f3f3f3f; // 避免INT_MAX溢出
int graph[N][N];
int n, m, q;
int main() {
// 初始化邻接矩阵
memset(graph, 0x3f, sizeof(graph)); // 快速初始化为INF
cin >> n >> m >> q;
for(int i=1; i<=n; i++) graph[i][i] = 0;
// 输入边
while(m--){
int u, v, w;
cin >> u >> v >> w;
if(w < graph[u][v]){ // 处理重复边
graph[u][v] = w;
graph[v][u] = w; // 无向图
}
}
// Floyd-Warshall算法
for(int k=1; k<=n; k++){
for(int i=1; i<=n; i++){
for(int j=1; j<=n; j++){
if(graph[i][k] != INF && graph[k][j] != INF){
graph[i][j] = min(graph[i][j], graph[i][k] + graph[k][j]);
}
}
}
}
// 查询
while(q--){
int st, ed;
cin >> st >> ed;
cout << (graph[st][ed] == INF ? -1 : graph[st][ed]) << '\n';
}
return 0;
}dijistra
#include <bits/stdc++.h>
using namespace std;
typedef pair<int, int> PII;
const int N = 1e5 + 10, INF = 0x3f3f3f3f;
int n, m, s; // 点数、边数、起点
int h[N], e[N], w[N], ne[N], idx; // 邻接表存图
int dist[N]; // 存储最短距离
bool vis[N]; // 标记是否已确定最短路径
void add(int a, int b, int c) {
e[idx] = b, w[idx] = c, ne[idx] = h[a], h[a] = idx++;
}
void dijkstra() {
memset(dist, 0x3f, sizeof dist);
dist[s] = 0;
priority_queue<PII, vector<PII>, greater<PII>> heap;
heap.push({0, s});
while (!heap.empty()) {
auto t = heap.top();
heap.pop();
int ver = t.second, distance = t.first;
if (vis[ver]) continue; // 已确定最短路径则跳过
vis[ver] = true;
// 遍历邻接点更新距离
for (int i = h[ver]; i != -1; i = ne[i]) {
int j = e[i];
if (dist[j] > distance + w[i]) {
dist[j] = distance + w[i];
heap.push({dist[j], j});
}
}
}
}
int main() {
memset(h, -1, sizeof h);
cin >> n >> m >> s;
while (m--) {
int a, b, c;
cin >> a >> b >> c;
add(a, b, c); // 有向图,无向图需反向添加
}
dijkstra();
for (int i = 1; i <= n; i++)
cout << (dist[i] == INF ? -1 : dist[i]) << " ";
return 0;
}最小生成树
prim找距离最小的点
#include<iostream>
#include<vector>
#include <climits>
using namespace std;
int main() {
int v, e;
int x, y, k;
cin >> v >> e;
// 填一个默认最大值,题目描述val最大为10000
vector<vector<int>> grid(v + 1, vector<int>(v + 1, 10001));
while (e--) {
cin >> x >> y >> k;
// 因为是双向图,所以两个方向都要填上
grid[x][y] = k;
grid[y][x] = k;
}
// 所有节点到最小生成树的最小距离
vector<int> minDist(v + 1, 10001);
// 这个节点是否在树里
vector<bool> isInTree(v + 1, false);
// 我们只需要循环 n-1次,建立 n - 1条边,就可以把n个节点的图连在一起
for (int i = 1; i < v; i++) {
// 1、prim三部曲,第一步:选距离生成树最近节点
int cur = -1; // 选中哪个节点 加入最小生成树
int minVal = INT_MAX;
for (int j = 1; j <= v; j++) { // 1 - v,顶点编号,这里下标从1开始
// 选取最小生成树节点的条件:
// (1)不在最小生成树里
// (2)距离最小生成树最近的节点
if (!isInTree[j] && minDist[j] < minVal) {
minVal = minDist[j];
cur = j;
}
}
// 2、prim三部曲,第二步:最近节点(cur)加入生成树
isInTree[cur] = true;
// 3、prim三部曲,第三步:更新非生成树节点到生成树的距离(即更新minDist数组)
// cur节点加入之后, 最小生成树加入了新的节点,那么所有节点到 最小生成树的距离(即minDist数组)需要更新一下
// 由于cur节点是新加入到最小生成树,那么只需要关心与 cur 相连的 非生成树节点 的距离 是否比 原来 非生成树节点到生成树节点的距离更小了呢
for (int j = 1; j <= v; j++) {
// 更新的条件:
// (1)节点是 非生成树里的节点
// (2)与cur相连的某节点的权值 比 该某节点距离最小生成树的距离小
// 很多录友看到自己 就想不明白什么意思,其实就是 cur 是新加入 最小生成树的节点,那么 所有非生成树的节点距离生成树节点的最近距离 由于 cur的新加入,需要更新一下数据了
if (!isInTree[j] && grid[cur][j] < minDist[j]) {
minDist[j] = grid[cur][j];
}
}
}
// 统计结果
int result = 0;
for (int i = 2; i <= v; i++) { // 不计第一个顶点,因为统计的是边的权值,v个节点有 v-1条边
result += minDist[i];
}
cout << result << endl;
}kruskal找最短边
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
// l,r为 边两边的节点,val为边的数值
struct Edge {
int l, r, val;
};
// 节点数量
int n = 10001;
// 并查集标记节点关系的数组
vector<int> father(n, -1); // 节点编号是从1开始的,n要大一些
// 并查集初始化
void init() {
for (int i = 0; i < n; ++i) {
father[i] = i;
}
}
// 并查集的查找操作
int find(int u) {
return u == father[u] ? u : father[u] = find(father[u]); // 路径压缩
}
// 并查集的加入集合
void join(int u, int v) {
u = find(u); // 寻找u的根
v = find(v); // 寻找v的根
if (u == v) return ; // 如果发现根相同,则说明在一个集合,不用两个节点相连直接返回
father[v] = u;
}
int main() {
int v, e;
int v1, v2, val;
vector<Edge> edges;
int result_val = 0;
cin >> v >> e;
while (e--) {
cin >> v1 >> v2 >> val;
edges.push_back({v1, v2, val});
}
// 执行Kruskal算法
// 按边的权值对边进行从小到大排序
sort(edges.begin(), edges.end(), [](const Edge& a, const Edge& b) {
return a.val < b.val;
});
// 并查集初始化
init();
// 从头开始遍历边
for (Edge edge : edges) {
// 并查集,搜出两个节点的祖先
int x = find(edge.l);
int y = find(edge.r);
// 如果祖先不同,则不在同一个集合
if (x != y) {
result_val += edge.val; // 这条边可以作为生成树的边
join(x, y); // 两个节点加入到同一个集合
}
}
cout << result_val << endl;
return 0;
}
BF
#include <iostream>
#include <vector>
#include <list>
#include <climits>
using namespace std;
int main() {
int n, m, p1, p2, val;
cin >> n >> m;
vector<vector<int>> grid;
// 将所有边保存起来
for(int i = 0; i < m; i++){
cin >> p1 >> p2 >> val;
// p1 指向 p2,权值为 val
grid.push_back({p1, p2, val});
}
int start = 1; // 起点
int end = n; // 终点
vector<int> minDist(n + 1 , INT_MAX);
minDist[start] = 0;
for (int i = 1; i < n; i++) { // 对所有边 松弛 n-1 次
for (vector<int> &side : grid) { // 每一次松弛,都是对所有边进行松弛
int from = side[0]; // 边的出发点
int to = side[1]; // 边的到达点
int price = side[2]; // 边的权值
// 松弛操作
// minDist[from] != INT_MAX 防止从未计算过的节点出发
if (minDist[from] != INT_MAX && minDist[to] > minDist[from] + price) {
minDist[to] = minDist[from] + price;
}
}
}
if (minDist[end] == INT_MAX) cout << "unconnected" << endl; // 不能到达终点
else cout << minDist[end] << endl; // 到达终点最短路径
}SPFA
#include <cstring>
#include <queue>
using namespace std;
const int MAXN = 1e5 + 5; // 根据题目调整最大节点数
const int INF = 0x3f3f3f3f; // 表示无穷大
struct Edge {
int v; // 目标节点
int w; // 边权
};
vector<Edge> e[MAXN]; // 邻接表存图
int dis[MAXN]; // 起点到各点的最短距离
int cnt[MAXN]; // 记录到某节点的最短路边数(用于负环检测)
bool vis[MAXN]; // 标记节点是否在队列中
// SPFA 主函数
// 返回值: true=无负环,false=存在负环
// 参数: n=总节点数,s=起点
bool spfa(int n, int s) {
// 初始化距离和队列
memset(dis, 0x3f, sizeof(dis)); // 初始化为INF
memset(cnt, 0, sizeof(cnt));
memset(vis, 0, sizeof(vis));
queue<int> q;
dis[s] = 0;
q.push(s);
vis[s] = true;
while (!q.empty()) {
int u = q.front();
q.pop();
vis[u] = false; // 出队后取消标记
// 遍历所有邻接边
for (auto &ed : e[u]) {
int v = ed.v, w = ed.w;
// 松弛操作:尝试缩短 dis[v]
if (dis[v] > dis[u] + w) {
dis[v] = dis[u] + w;
cnt[v] = cnt[u] + 1; // 更新路径边数
// 存在负环的判定条件
if (cnt[v] >= n) return false;
// 若v不在队列中,则入队
if (!vis[v]) {
q.push(v);
vis[v] = true;
}
}
}
}
return true; // 未发现负环
}十、动态规划
LCS最长公共子序列
// 计算LCS长度
int lengthOfLCS(string s1, string s2) {
int m = s1.size(), n = s2.size();
vector<vector<int>> dp(m + 1, vector<int>(n + 1, 0));
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
if (s1[i] == s2[j]) {
dp[i + 1][j + 1] = dp[i][j] + 1;
} else {
dp[i + 1][j + 1] = max(dp[i][j + 1], dp[i + 1][j]);
}
}
}
return dp[m][n];
}
// 输出一个具体的LCS序列
string getLCS(string s1, string s2) {
int m = s1.size(), n = s2.size();
vector<vector<int>> dp(m + 1, vector<int>(n + 1, 0));
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
if (s1[i] == s2[j]) {
dp[i + 1][j + 1] = dp[i][j] + 1;
} else {
dp[i + 1][j + 1] = max(dp[i][j + 1], dp[i + 1][j]);
}
}
}
string lcs;
int i = m, j = n;
while (i > 0 && j > 0) {
if (s1[i - 1] == s2[j - 1]) {
lcs.push_back(s1[i - 1]);
i--, j--;
} else if (dp[i - 1][j] > dp[i][j - 1]) {
i--;
} else {
j--;
}
}
reverse(lcs.begin(), lcs.end());
return lcs;
}LIS最长上升子序列
/ 计算LIS长度
int lengthOfLIS_DP(vector<int>& nums) {
int n = nums.size();
vector<int> dp(n, 1);
int max_len = 1;
for (int i = 0; i < n; ++i) {
for (int j = 0; j < i; ++j) {
if (nums[j] < nums[i]) {
dp[i] = max(dp[i], dp[j] + 1);
}
}
max_len = max(max_len, dp[i]);
}
return max_len;
}
// 输出一个具体的LIS序列
vector<int> getLIS(vector<int>& nums) {
int n = nums.size();
vector<int> dp(n, 1), prev(n, -1);
int max_len = 1, end_idx = 0;
for (int i = 0; i < n; ++i) {
for (int j = 0; j < i; ++j) {
if (nums[j] < nums[i] && dp[i] < dp[j] + 1) {
dp[i] = dp[j] + 1;
prev[i] = j;
}
}
if (dp[i] > max_len) {
max_len = dp[i];
end_idx = i;
}
}
vector<int> lis;
while (end_idx != -1) {
lis.push_back(nums[end_idx]);
end_idx = prev[end_idx];
}
reverse(lis.begin(), lis.end());
return lis;
}1. 01背包问题
特点:每件物品只能选或不选(0或1次)。
二维数组模板(时间复杂度O(NV),空间复杂度O(NV))
int dp[N][V]; // N为物品数,V为背包容量
for (int i = 1; i <= n; i++) {
int w = weight[i], v = value[i];
for (int j = 0; j <= V; j++) {
if (j < w) dp[i][j] = dp[i-1][j];
else dp[i][j] = max(dp[i-1][j], dp[i-1][j-w] + v);
}
}
// 结果:dp[n][V]关键点:状态从上一行(i-1)转移而来。
一维数组优化(空间复杂度O(V))
int dp[V+1] = {0};
for (int i = 1; i <= n; i++) {
int w = weight[i], v = value[i];
for (int j = V; j >= w; j--) { // 逆序遍历防止覆盖
dp[j] = max(dp[j], dp[j-w] + v);
}
}
// 结果:dp[V]关键点:逆序更新确保每个物品仅被计算一次。
2. 完全背包问题
特点:每件物品可选无限次。
二维数组模板
int dp[N][V];
for (int i = 1; i <= n; i++) {
int w = weight[i], v = value[i];
for (int j = 0; j <= V; j++) {
if (j < w) dp[i][j] = dp[i-1][j];
else dp[i][j] = max(dp[i-1][j], dp[i][j-w] + v); // 区别:当前行转移
}
}
// 结果:dp[n][V]关键点:状态从当前行转移,允许重复选择。
一维数组优化
int dp[V+1] = {0};
for (int i = 1; i <= n; i++) {
int w = weight[i], v = value[i];
for (int j = w; j <= V; j++) { // 正序遍历允许重复
dp[j] = max(dp[j], dp[j-w] + v);
}
}
// 结果:dp[V]关键点:正序更新允许多次选择同一物品。
3. 多重背包问题
特点:第i种物品最多选s[i]次。
二维数组模板(朴素版)
int dp[N][V];
for (int i = 1; i <= n; i++) {
int w = weight[i], v = value[i], s = cnt[i];
for (int j = 0; j <= V; j++) {
dp[i][j] = dp[i-1][j];
for (int k = 1; k <= s && k*w <= j; k++) {
dp[i][j] = max(dp[i][j], dp[i-1][j-k*w] + k*v);
}
}
}
// 结果:dp[n][V]关键点:三层循环遍历物品、容量和选取次数。
一维数组优化(二进制拆分)
#include <iostream>
#include <vector>
using namespace std;
int main() {
int N, W;
cin >> N >> W;
vector<int> dp(W + 1, 0);
vector<pair<int, int>> items; // 存储拆分后的物品(重量,价值)
for (int i = 0; i < N; i++) {
int w, v, s;
cin >> w >> v >> s;
// 二进制拆分
int k = 1;
while (k <= s) {
items.push_back({w * k, v * k});
s -= k;
k *= 2;
}
if (s > 0) {
items.push_back({w * s, v * s});
}
}
// 01 背包动态规划
for (auto &item : items) {
int w = item.first, v = item.second;
for (int j = W; j >= w; j--) {
dp[j] = max(dp[j], dp[j - w] + v);
}
}
cout << dp[W] << endl;
return 0;
}关键点:通过二进制拆分将问题转化为01背包,降低复杂度
十一、二分查找
while(l<r)
尽量向左找目标
//在a数组中寻找第一个>=x的数,并返回其下标
int bsearch_1(int l, int r)
{
while (l < r)
{
int mid = l + r >> 1;//或写成(l+r)/2
if (a[mid]>=x) r = mid;
else l = mid + 1;
}
return l;//因为while循环当l==r时终止,return r也可以
}
尽量向右找目标
//在a数组中寻找最后一个<=x的数,并返回其下标
int bsearch_2(int l, int r)
{
while (l < r)
{
int mid = l + r + 1 >> 1;//或写成(l+r+1)/2
if (a[mid]<=x) l = mid;
else r = mid - 1;
}
return l;//因为while循环当l==r时终止,return r也可以
}
#include <iostream>
// 边长数组,这样我们就不用担心数据装不下了
#include <vector>
using namespace std;
vector<int > vec;
int main() {
int n, m;
int t;
cin >> n >> m;
int index;
// 向数组尾部放入数据,因为这个特性,vector也可以当成stack用
while(n--) cin >> t, vec.push_back(t);
while(m--) {
cin >> t;
// 在序列里查找目标数据
index = lower_bound(vec.begin(), vec.end(), t) - vec.begin();
// 如果目标数据找到了,输出答案,注意我们的数组下标是从0开始的
if (t == vec[index]) cout << index + 1 << ' ';
// 没找到记得输出-1哦
else cout << -1 << ' ';
}
return 0;1. 核心功能差异
| 函数 | 返回值条件(升序序列) | 返回值条件(降序序列) | 示例(升序序列 {1,3,4,4,6}) |
|---|---|---|---|
lower_bound | 第一个≥目标值的元素位置 | 第一个≤目标值的元素位置 | lower_bound(4) → 指向第一个4(索引2) |
upper_bound | 第一个>目标值的元素位置 | 第一个<目标值的元素位置 | upper_bound(4) → 指向6(索引4) |
关键点:
- 升序时:
lower_bound包含等于,upper_bound排除等于。 - 降序时:需通过比较函数(如
greater<int>())反转逻辑,此时lower_bound寻找第一个小于等于的元素,upper_bound寻找第一个小于的元素 。
#include <iostream>
using namespace std;
const int N = 100010;
int n, q;
int a[N];
// 查找左边界:第一个等于x的位置
int find_left(int x) {
int l = 0, r = n - 1;
while (l <= r) {
int mid = (l + r) >> 1;
if (a[mid] >= x) r = mid - 1; // 向左逼近
else l = mid + 1;
}
// 检查是否找到
return (l < n && a[l] == x) ? l : -1;
}
// 查找右边界:最后一个等于x的位置
int find_right(int x) {
int l = 0, r = n - 1;
while (l <= r) {
int mid = (l + r) >> 1;
if (a[mid] <= x) l = mid + 1; // 向右逼近
else r = mid - 1;
}
// 检查是否找到
return (r >= 0 && a[r] == x) ? r : -1;
}一、l <= r 模板(左闭右闭区间)
1. 适用场景
- 精确查找目标值是否存在
- 寻找第一个满足条件的元素(如第一个错误版本)
- 适用于明确闭区间
[left, right]的情况,确保所有元素都被覆盖 。
2. 代码模板
int binarySearch(vector<int>& nums, int target) {
int l = 0, r = nums.size() - 1; // 闭区间初始化
while (l <= r) { // 终止条件:l > r
int mid = l + (r - l) / 2; // 防溢出写法
if (nums[mid] == target) {
return mid; // 找到目标值
} else if (nums[mid] < target) {
l = mid + 1; // 目标在右半区间
} else {
r = mid - 1; // 目标在左半区间
}
}
return -1; // 未找到
}3. 特点
- 循环条件:
l <= r确保所有元素被检查,包括l == r的情况 。 - 边界更新:每次严格缩小范围,避免死循环。
- 典型应用:基础二分查找(如 LeetCode 704)。
二、l < r 模板(左闭右开区间)
1. 适用场景
- 寻找插入位置(如
lower_bound/upper_bound) - 处理边界问题(如第一个/最后一个满足条件的元素)
- 适用于左闭右开区间
[left, right),常用于迭代器或数组尾部。
2. 代码模板
// 寻找第一个 >= target 的位置(lower_bound)
int lowerBound(vector<int>& nums, int target) {
int l = 0, r = nums.size(); // 右开区间初始化
while (l < r) { // 终止条件:l == r
int mid = l + (r - l) / 2; // 防溢出写法
if (nums[mid] >= target) {
r = mid; // 目标在左半区间(包含 mid)
} else {
l = mid + 1; // 目标在右半区间(排除 mid)
}
}
return l; // 若未找到,返回插入位置
}
// 寻找第一个 > target 的位置(upper_bound)
int upperBound(vector<int>& nums, int target) {
int l = 0, r = nums.size();
while (l < r) {
int mid = l + (r - l) / 2;
if (nums[mid] > target) {
r = mid;
} else {
l = mid + 1;
}
}
return l; // 返回插入位置(最后一个等于 target 的下一个位置)
}3. 特点
- 循环条件:
l < r确保区间范围逐步缩小,最终l == r。 - 边界更新:右边界
r不包含在搜索范围内,需注意最终结果的验证(如nums[l]是否等于目标值)。 - 典型应用:查找插入位置(LeetCode 35)或重复元素的边界 。
三、核心区别与选择原则
| 特性 | l <= r(闭区间) | l < r(左闭右开) |
|---|---|---|
| 初始区间 | [0, n-1] | [0, n) |
| 终止条件 | l > r(所有元素已检查) | l == r(区间为空) |
| 更新逻辑 | mid ± 1 严格缩小范围 | r = mid 或 l = mid + 1 |
| 适用场景 | 精确查找、存在性判断 | 边界查找、插入位置、重复元素处理 |
| 防溢出写法 | mid = l + (r - l) / 2 | 同上 |
十三、高精度
加法:
#include <vector>
#include <string>
using namespace std;
vector<int> add(vector<int>& A, vector<int>& B) {
if (A.size() < B.size()) return add(B, A); // 保证A位数≥B
vector<int> C;
int t = 0; // 进位
for (int i = 0; i < A.size(); i++) {
t += A[i];
if (i < B.size()) t += B[i];
C.push_back(t % 10);
t /= 10;
}
if (t) C.push_back(t);
return C;
}
// 调用示例
string a = "999999999", b = "1";
vector<int> A, B;
for (int i = a.size()-1; i >= 0; i--) A.push_back(a[i]-'0');
for (int i = b.size()-1; i >= 0; i--) B.push_back(b[i]-'0');
vector<int> C = add(A, B);
// 逆序输出结果:for (int i = C.size()-1; i >= 0; i--) cout << C[i];减法:
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
const int N=505;
vector<int> a, b;
// 修正比较函数:判断a是否>=b
bool cmp(vector<int>& x, vector<int>& y) { // 添加引用避免拷贝
if (x.size() != y.size())
return x.size() > y.size();
for (int i = x.size()-1; i >= 0; i--) {
if (x[i] != y[i])
return x[i] > y[i];
}
return true;
}
// 修正减法函数:使用参数y的数据
vector<int> sub(vector<int>& x, vector<int>& y) { // 添加引用避免拷贝
vector<int> c;
for (int i = 0, t = 0; i < x.size(); i++) {
t = x[i] - t;
if (i < y.size()) t -= y[i]; // 正确使用y[i]
c.push_back((t + 10) % 10);
t = (t < 0) ? 1 : 0;
}
while (c.size() > 1 && c.back() == 0) c.pop_back();
return c;
}
int main() {
string s1, s2;
cin >> s1 >> s2;
for (int i = s1.size()-1; i >= 0; i--) a.push_back(s1[i]-'0');
for (int i = s2.size()-1; i >= 0; i--) b.push_back(s2[i]-'0');
vector<int> c;
if (cmp(a, b)) {
c = sub(a, b);
} else {
cout << "-"; // 处理负号
c = sub(b, a);
}
for (int i = c.size()-1; i >= 0; i--)
cout << c[i];
return 0;
}乘法:
#include <bits/stdc++.h>
using namespace std;
vector<int> mul(vector<int>& x, vector<int>& y) {
vector<int> c(x.size() + y.size(), 0);
for (int i = 0; i < x.size(); i++)
for (int j = 0; j < y.size(); j++)
c[i + j] += x[i] * y[j];
int carry = 0;
for (int i = 0; i < c.size(); i++) {
c[i] += carry;
carry = c[i] / 10;
c[i] %= 10;
}
while (c.size() > 1 && c.back() == 0) c.pop_back();
return c;
}
int main() {
string s1, s2;
cin >> s1 >> s2;
vector<int> a, b;
// 逆序存储,个位在前
for (int i = s1.size()-1; i >=0; i--) a.push_back(s1[i] - '0');
for (int i = s2.size()-1; i >=0; i--) b.push_back(s2[i] - '0');
vector<int> c = mul(a, b);
// 逆序输出
for (int i = c.size()-1; i >=0; i--) cout << c[i];
return 0;
}十四、取消同步流
ios::sync_with_stdio(0),cin.tie(0),cout.tie(0);
//取消同步流