HTML应用指南:利用GET请求获取全国德克士门店位置信息
在当今快节奏的都市生活中,餐饮品牌的门店布局不仅反映了其市场策略,更折射出消费者对便捷、品质和品牌认同的追求。德克士(Dicos)作为中国本土领先的西式快餐品牌之一,自1996年成立以来,凭借其独特的“东方口味西式快餐”定位,迅速在全国范围内扩张,成为肯德基、麦当劳之外的重要竞争者。其门店分布广泛覆盖一二线城市,并逐步向三四线城市下沉,展现出强大的市场渗透力和品牌影响力。
本文将深入探讨GET请求在获取德克士官方网站的门店分布信息中的实际应用,并展示如何使用Python的requests库发送GET请求,从德克士官方网站提取详细的门店位置信息,涵盖全国范围内的所有德克士店铺,处理响应数据的方法,包括解析JSON格式的数据或者HTML页面,以便有效地提取所需信息,通过多维度的数据分析视角,挖掘德克士门店分布中隐含的市场策略与消费趋势。这项研究不仅能为餐饮行业从业者提供选址决策支持,也可为商业地理学研究提供新的数据支撑,更可为广大消费者带来更加便捷的门店查询体验。
德克士官方网站:德克士官网
我们第一步先找到门店数据的存储位置,然后看3个关键部分标头、负载、 预览;
标头:通常包括URL的连接,也就是目标资源的位置;
负载:对于GET请求:负载通常包含了传递的参数,有些网页负载可能为空,或者没有负载,因为所有参数都通过URL传递,这里我们可以看到它的传参包括,关键词,是明文传输;
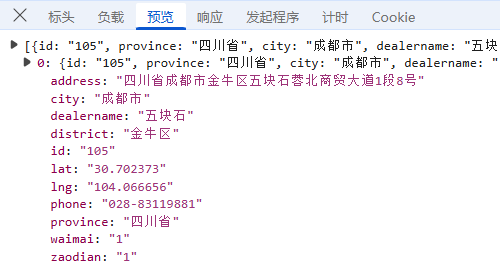
预览:指的是对响应内容的快速查看或摘要显示,可以帮助用户快速了解返回的数据结构或内容片段;
接下来就是数据获取部分,先讲一下方法思路,一共三个步骤;
方法思路
- 找到对应数据存储位置,获取所有店铺列表的相关标签数据;
- 我们通过改变查询关键字(地址查询场景的高频词字典),来遍历全国门店数据;
- 坐标转换,通过coord-convert库实现GCJ-02转WGS84;
第一步:我们先找到对应数据存储位置,获取所有店铺列表,经过测试,每次查询一类关键词会返回一个html,我们通过修改关键词来进行数据获取,为了方便我们直接建立一个包含地址查询场景的高频词字典,通过遍历关键词来查询全国数据;
第二步:利用GET请求遍历获取所有店铺列表,并根据标签进行去重和保存,另存为csv;
完整代码#运行环境 Python 3.11
import requests
import csv
# 请求的基本 URL
base_url = "https://www.dicos.com.cn/wap/index.php"
# 关键词列表
keywords = ["省", "市", "区", "县", "镇", "乡", "村", "街道", "社区", "居委会","路", "街", "道", "巷", "胡同", "弄", "里", "大道",
"号", "栋", "单元", "楼", "层", "室", "小区", "花园", "大厦", "公寓", "别墅", "广场", "中心", "东", "南", "西", "北",
"前", "后", "左", "右", "屯", "寨", "堡", "圩", "埭", "湾", "庄"]
# 存储所有商店信息的列表
all_stores_info = []
# 遍历每个关键词
for keyword in keywords:
print(f"\n正在查询关键词: {keyword}")
# 请求参数
params = {
'a': 'store',
'address': keyword
}
# 发送 GET 请求
response = requests.get(base_url, params=params)
# 检查请求是否成功
if response.status_code == 200:
# 获取返回的 JSON 数据
data = response.json()
# 检查数据是否有效并处理
if isinstance(data, list): # 直接检查是否为列表
print(f"找到 {len(data)} 条记录")
for store in data:
store_info = {
"关键词": keyword, # 添加查询关键词字段
"商店名称": store.get("dealername", "未知商店"),
"地址": store.get("address", "未知地址"),
"电话": store.get("phone", "无电话"),
"省": store.get("province", "未知省"),
"市": store.get("city", "未知市"),
"区": store.get("district", "未知区"),
"纬度": store.get("lat", "无纬度"),
"经度": store.get("lng", "无经度"),
"是否有外卖": store.get("waimai", "未知"),
"是否有早点": store.get("zaodian", "未知")
}
all_stores_info.append(store_info)
# 打印每个商店的详细信息
print("\n商店信息:")
for key, value in store_info.items():
print(f"{key}: {value}")
print("-" * 50) # 分隔线
else:
print(f"关键词 '{keyword}' 未找到有效的商店信息。")
else:
print(f"请求失败,状态码: {response.status_code},关键词: {keyword}")
# 数据去重处理
print("\n开始数据去重...")
unique_stores = {}
duplicate_count = 0
for store in all_stores_info:
# 使用商店名称和地址的组合作为唯一标识
store_key = (store["商店名称"], store["地址"])
# 如果是新的商店,添加到字典中
if store_key not in unique_stores:
unique_stores[store_key] = store
else:
duplicate_count += 1
# 如果已存在,且新数据包含更多信息,则更新
existing_store = unique_stores[store_key]
for field in ["电话", "省", "市", "区", "纬度", "经度", "是否有外卖", "是否有早点"]:
if existing_store[field] in ["无电话", "未知省", "未知市", "未知区", "无纬度", "无经度", "未知"] and store[
field] not in ["无电话", "未知省", "未知市", "未知区", "无纬度", "无经度", "未知"]:
existing_store[field] = store[field]
# 将去重后的数据转换回列表
deduplicated_stores = list(unique_stores.values())
print(f"去重完成!移除了 {duplicate_count} 条重复记录")
print(f"去重前总记录数: {len(all_stores_info)}")
print(f"去重后总记录数: {len(deduplicated_stores)}")
# 保存去重后的数据到 CSV 文件
if deduplicated_stores: # 如果有数据才保存
csv_filename = 'dicos_stores_.csv'
with open(csv_filename, mode='w', newline='', encoding='utf-8-sig') as file:
# 获取字段名(表头)
fieldnames = deduplicated_stores[0].keys()
# 创建 CSV writer 对象
writer = csv.DictWriter(file, fieldnames=fieldnames)
# 写入表头
writer.writeheader()
# 写入数据
writer.writerows(deduplicated_stores)
print(f"\n去重后的数据已保存到 {csv_filename}")
else:
print("\n未找到任何商店信息。")
这里有一个小tips,因为是通过高频关键词遍历的,会出现仍然会漏掉某些数据的可能性;
这里我们建立一个包含地址查询场景的高频词字典,并遍历查询每个关键词下的德克士店铺,获取数据标签如下,address(地址)、city(市)、dealername(商店名称)、district(区)、lat、lng(坐标)、phone(电话)、province(省)、waimai(是否有外卖)、zaodian(是否有早点),其他一些非关键标签,这里省略;
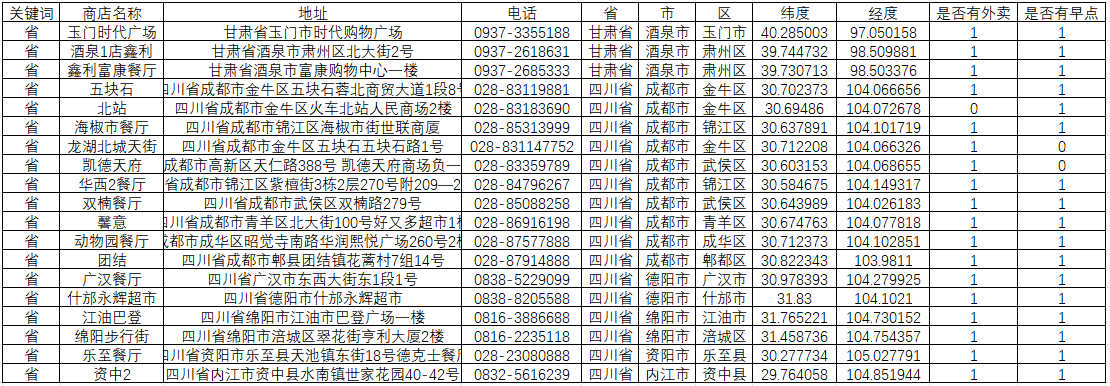
第三步:坐标系转换,由于德克士门店使用的坐标系从网页端并看不出来,那么我们通过高德的坐标拾取器进行验证,发现一致,则我们断定他使用的是高德坐标系(GCJ-02),为了在ArcGIS上准确展示而不发生偏移,我们需要将门店的坐标从GCJ-02转换为WGS-84坐标系。我们可以利用coord-convert库中的gcj2wgs(lng, lat)函数,也可以用免费这个网站:批量转换工具:地图坐标系批量转换 - 免费在线工具 (latlongconverter.online);
对CSV文件中的门店坐标列进行转换。完成坐标转换后,再将数据导入ArcGIS进行可视化;
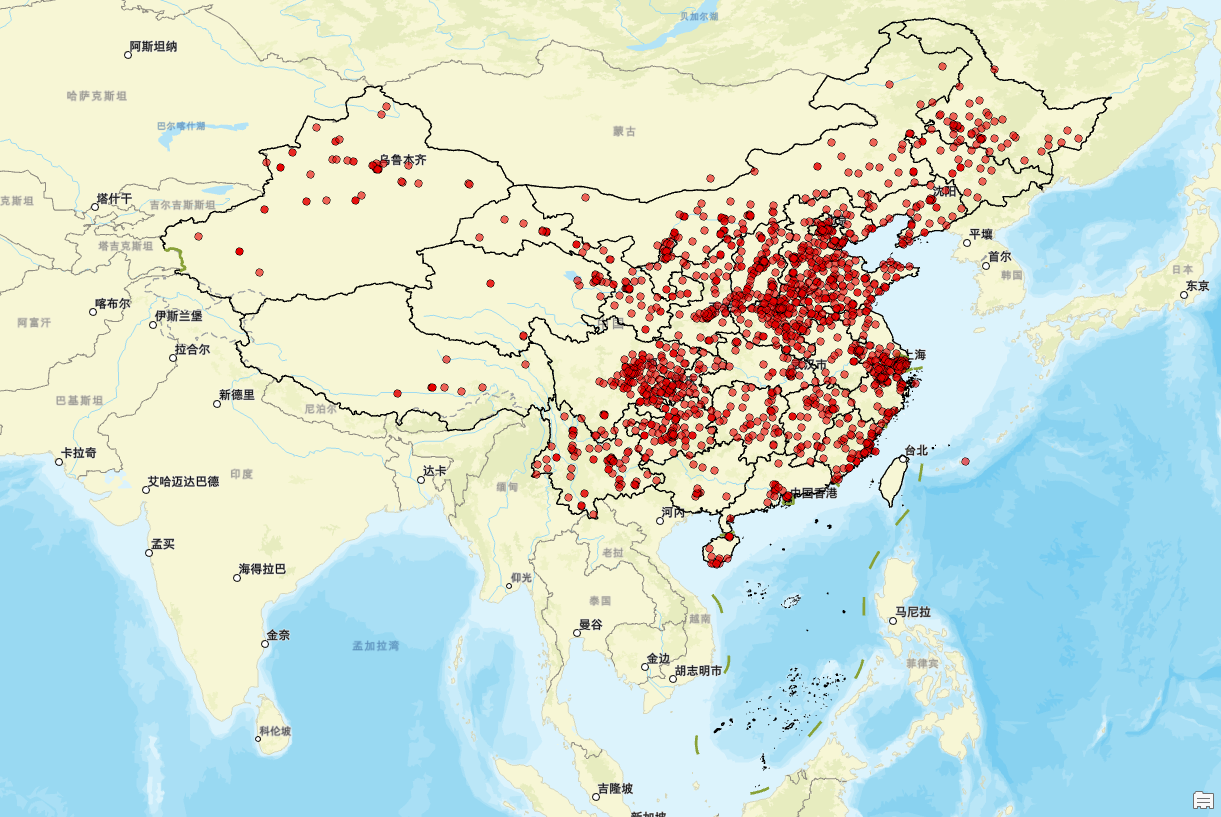
接下来,我们进行看图说话:
德克士门店的分布特征显示出显著的地域性和经济性特点。首先,在东部沿海地区,特别是长江三角洲(包括上海、江苏和浙江)以及珠江三角洲(广东),门店分布最为密集。这些区域不仅是我国经济最发达的地方,也是人口密度最高的地区之一,拥有强大的消费能力。此外,中部地区的河南、湖北、湖南等省份也有较多的德克士门店分布,尤其是在省会城市和经济发展较好的城市中。
相比之下,西部地区如新疆、西藏、青海等地,德克士门店的分布则显得较为稀疏。这些地方地广人稀,经济发展水平相对较低,限制了门店的扩展。同样地,北部边远地区,比如内蒙古和黑龙江,门店分布也较少,这与当地的人口密度和消费市场潜力密切相关。
从城市与农村的角度来看,德克士门店主要集中在大城市及经济较发达的中小城市内,在一些农村或偏远地区则很少见。这表明德克士倾向于选择那些市场潜力大、消费者购买力强的城市进行布局。同时,在地理特征方面,平原地区如华北平原和长江中下游平原是德克士门店的重点分布区;而在山区和高原地带,由于地形复杂且交通不便,门店数量相对较少。
交通枢纽城市,例如北京、上海、广州和深圳,由于其高流量的人群往来,成为德克士门店的重要集中点。这些城市的商业活动频繁,为餐饮业提供了广阔的市场空间。
文章仅用于分享个人学习成果与个人存档之用,分享知识,如有侵权,请联系作者进行删除。所有信息均基于作者的个人理解和经验,不代表任何官方立场或权威解读。