一周学会Pandas2 Python数据处理与分析-Pandas2读取CSV
锋哥原创的Pandas2 Python数据处理与分析 视频教程:
2025版 Pandas2 Python数据处理与分析 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili

CSV格式文件是使用和处理最多的文件格式,Pandas2提供的read_csv()方法来读取csv文件,提供了很多强大的功能参数支持,让我们开发非常方便。
首先我们去看下read_csv()的方法的参数定义:
def read_csv(
filepath_or_buffer: FilePath | ReadCsvBuffer[bytes] | ReadCsvBuffer[str],
*,
sep: str | None | lib.NoDefault = lib.no_default,
delimiter: str | None | lib.NoDefault = None,
# Column and Index Locations and Names
header: int | Sequence[int] | None | Literal["infer"] = "infer",
names: Sequence[Hashable] | None | lib.NoDefault = lib.no_default,
index_col: IndexLabel | Literal[False] | None = None,
usecols: UsecolsArgType = None,
# General Parsing Configuration
dtype: DtypeArg | None = None,
engine: CSVEngine | None = None,
converters: Mapping[Hashable, Callable] | None = None,
true_values: list | None = None,
false_values: list | None = None,
skipinitialspace: bool = False,
skiprows: list[int] | int | Callable[[Hashable], bool] | None = None,
skipfooter: int = 0,
nrows: int | None = None,
# NA and Missing Data Handling
na_values: Hashable
| Iterable[Hashable]
| Mapping[Hashable, Iterable[Hashable]]
| None = None,
keep_default_na: bool = True,
na_filter: bool = True,
verbose: bool | lib.NoDefault = lib.no_default,
skip_blank_lines: bool = True,
# Datetime Handling
parse_dates: bool | Sequence[Hashable] | None = None,
infer_datetime_format: bool | lib.NoDefault = lib.no_default,
keep_date_col: bool | lib.NoDefault = lib.no_default,
date_parser: Callable | lib.NoDefault = lib.no_default,
date_format: str | dict[Hashable, str] | None = None,
dayfirst: bool = False,
cache_dates: bool = True,
# Iteration
iterator: bool = False,
chunksize: int | None = None,
# Quoting, Compression, and File Format
compression: CompressionOptions = "infer",
thousands: str | None = None,
decimal: str = ".",
lineterminator: str | None = None,
quotechar: str = '"',
quoting: int = csv.QUOTE_MINIMAL,
doublequote: bool = True,
escapechar: str | None = None,
comment: str | None = None,
encoding: str | None = None,
encoding_errors: str | None = "strict",
dialect: str | csv.Dialect | None = None,
# Error Handling
on_bad_lines: str = "error",
# Internal
delim_whitespace: bool | lib.NoDefault = lib.no_default,
low_memory: bool = _c_parser_defaults["low_memory"],
memory_map: bool = False,
float_precision: Literal["high", "legacy"] | None = None,
storage_options: StorageOptions | None = None,
dtype_backend: DtypeBackend | lib.NoDefault = lib.no_default,
)pd.read_csv() 是 pandas 中最常用的数据读取方法之一,用于从 CSV 文件中读取数据并创建 DataFrame。以下是其主要参数的详细说明:
基本参数
-
filepath_or_buffer:
-
必需参数,可以是文件路径、URL 或任何带有 read() 方法的对象
-
示例:
'data.csv','https://example.com/data.csv'
-
-
sep/delimiter:
-
字段分隔符,默认为
',' -
示例:
'\t'用于制表符分隔的文件
-
-
header:
-
指定作为列名的行号,默认为
0(第一行) -
设置为
None表示没有标题行 -
示例:
header=0,header=None
-
-
names:
-
用于结果的列名列表
-
如果文件不包含标题行,则应设置
header=None -
示例:
names=['col1', 'col2', 'col3']
-
数据解析参数
-
index_col:
-
用作行索引的列编号或列名
-
示例:
index_col=0,index_col='date'
-
-
usecols:
-
指定要读取的列,可以是列名列表或列索引列表
-
示例:
usecols=[0, 1, 2],usecols=['col1', 'col2']
-
-
dtype:
-
指定列的数据类型
-
示例:
dtype={'col1': 'float64', 'col2': 'int32'}
-
-
parse_dates:
-
尝试将指定列解析为日期
-
示例:
parse_dates=['date'],parse_dates=True(尝试解析所有日期)
-
-
date_parser:
-
用于解析日期的函数
-
通常与
parse_dates一起使用
-
-
converters:
-
列转换函数的字典
-
示例:
converters={'col1': lambda x: x.lower()}
-
缺失值处理
-
na_values:
-
应识别为 NA/NaN 的字符串列表
-
示例:
na_values=['NA', 'N/A', 'missing']
-
-
keep_default_na:
-
是否包含默认的 NaN 值列表,默认为 True
-
如果为 False,则仅识别
na_values指定的值
-
-
na_filter:
-
是否检测缺失值标记,默认为 True
-
设置为 False 可以提高读取大文件的速度
-
文件处理参数
-
nrows:
-
从文件开头读取的行数
-
示例:
nrows=1000(只读取前1000行)
-
-
skiprows:
-
从文件开头跳过的行数或行号列表
-
示例:
skiprows=5,skiprows=[0, 2]
-
-
skipfooter:
-
从文件末尾跳过的行数
-
示例:
skipfooter=3(跳过最后3行)
-
-
encoding:
-
文件编码,如
'utf-8','gbk','latin1'等 -
示例:
encoding='utf-8'
-
-
engine:
-
使用的解析引擎,可选 'c' (更快) 或 'python' (功能更全)
-
示例:
engine='python'
-
性能优化参数
-
chunksize:
-
返回迭代器对象,每次迭代返回指定行数
-
用于处理大文件
-
示例:
chunksize=10000
-
-
memory_map:
-
如果为 True,则使用内存映射文件进行读取
-
对于大文件可以提高性能
-
-
low_memory:
-
分块处理文件以减少内存使用,默认为 True
-
设置为 False 可以提高速度但增加内存使用
-
其他参数
-
thousands:
-
千位分隔符
-
示例:
thousands=','(将 "1,000" 解析为 1000)
-
-
decimal:
-
小数点字符,默认为
'.' -
示例:
decimal=','(用于欧洲格式的小数点)
-
-
comment:
-
标识注释开始的字符
-
示例:
comment='#'(跳过以 # 开头的行)
-
-
verbose:
-
是否输出解析信息,默认为 False
-
-
skip_blank_lines:
-
如果为 True,则跳过空行,默认为 True
-
无列名CSV文件处理header,names
对于无列名csv数据处理示例:
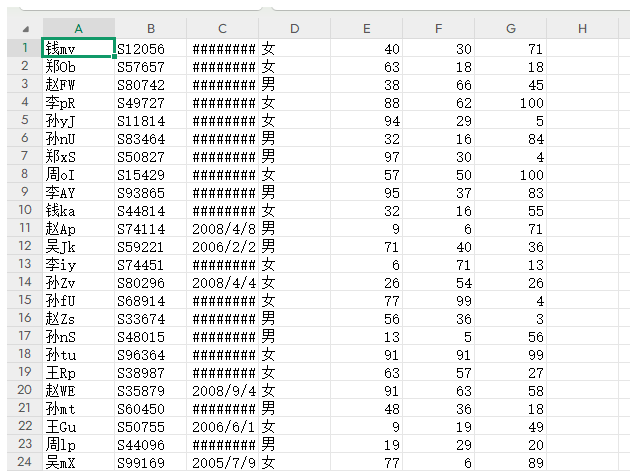
没有列头的csv文件处理 header设置None,names指定列名称
import pandas as pd
# 没有列头的csv文件处理 header设置None,names指定列名称
df = pd.read_csv('student_scores2.csv', header=None,
names=['姓名', '学号', '出生日期', '性别', '语文分数', '数学分数', '英语分数'])运行输出:
行索引index_col
index_col指定行索引,用作行索引的列编号或列名。
示例:
import pandas as pd
df = pd.read_csv('student_scores.csv', index_col='学号')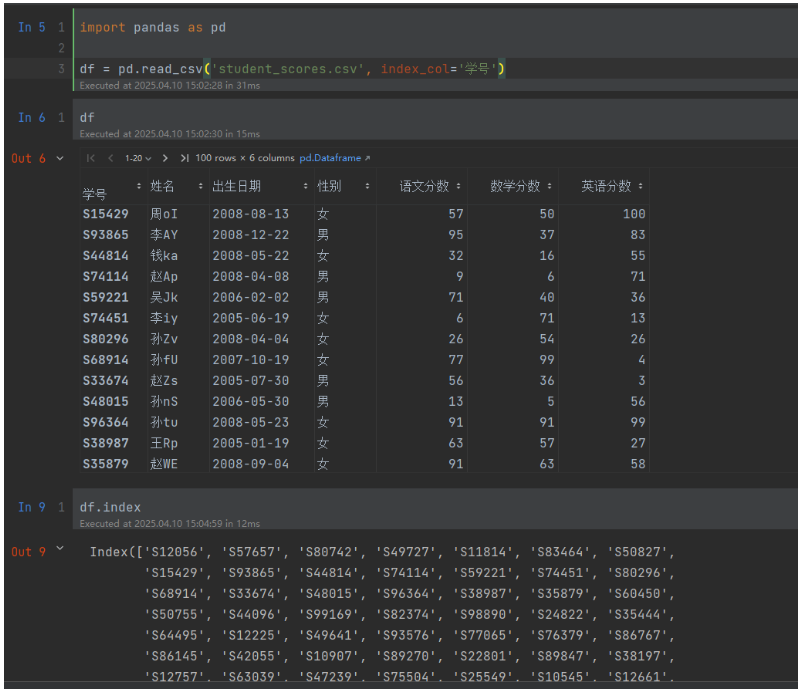
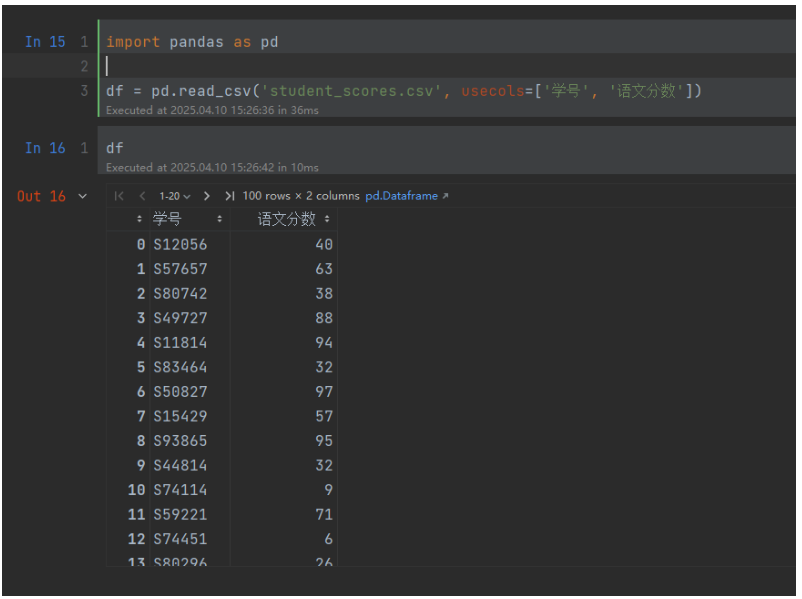
使用部分列usecols
指定要读取的列,可以是列名列表或列索引列表。示例: usecols=[0, 1, 2], usecols=['col1', 'col2']。
示例:
import pandas as pd
df = pd.read_csv('student_scores.csv', usecols=['学号', '语文分数'])运行结果:
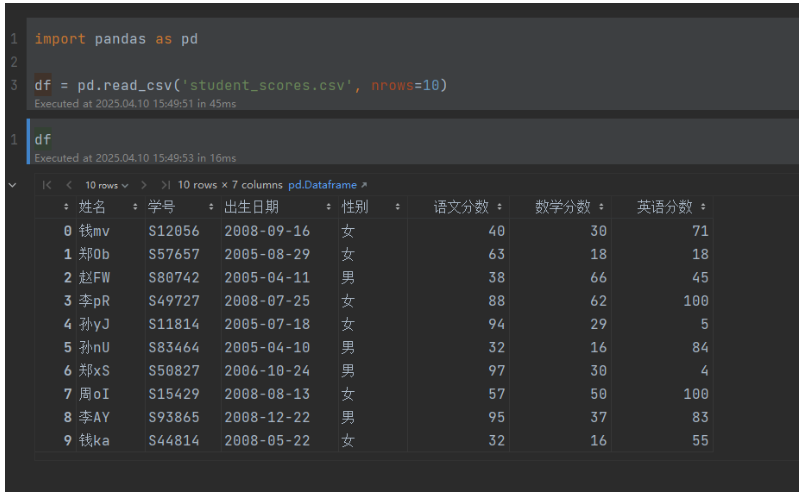
读取指定行nrows
读取前10行数据:
import pandas as pd
df = pd.read_csv('student_scores.csv', nrows=10)运行输出:
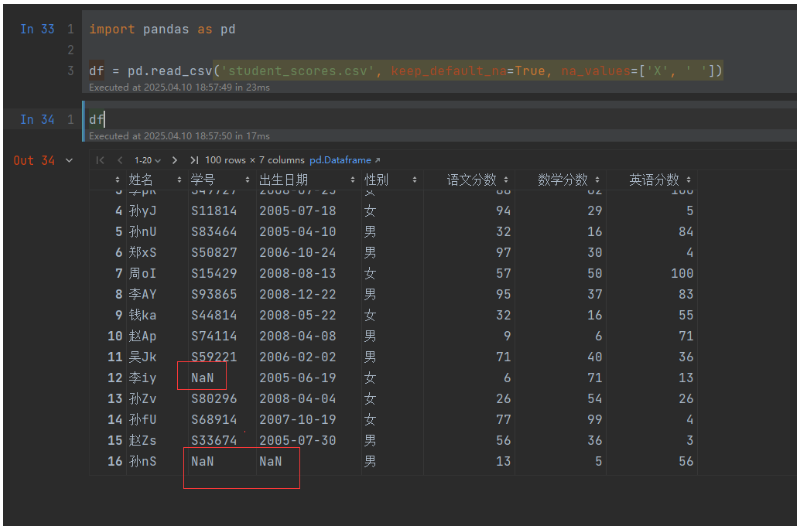
空值替换na_values和keep_default_na
na_values参数的值是一组用于替换NA/NaN的值。如果传参,需要指定特定列的空值。以下值默认会被认定为空值
['-1.#IND', '1.#QNAN', '1.#IND', '-1.#QNAN', '#N/A N/A', '#N/A', 'N/A', 'n/a', 'NA', '#NA', 'NULL', 'null', 'NaN', '-NaN', 'nan', '-nan', '']使用na_values时需要关注下面keep_default_na的配合使用和影响,keep_default_na是否包含默认的 NaN 值列表,默认为 True。
下面是一个示例:,空字符串和X作为Na值。
import pandas as pd
df = pd.read_csv('student_scores.csv', keep_default_na=True, na_values=['X', ' '])