第二章 Python爬虫篇—数据解析与提取
目录
一.数据解析概述
二.re解析和正则表达式
三.bs4解析-HTML语法
四.Xpath解析
此章节主要讲解:数据解析概述、re模块、bs4解析-html语法、xpath解析以及正则表达式。其中正则表达式我已经写过相关笔记,这里浅略叙述,如果不懂请看我笔记:https://blog.csdn.net/2403_88453964/article/details/147055211?spm=1001.2014.3001.5502
一.数据解析概述
在上一章中,我们基本上掌握了抓取整个网页的基本技能,但是呢,大多数情况下,我们并不需要整个网页的内容,只是
需要那么一小部分,怎么办呢?这就涉及到了数据提取的问题。
本章节中,提供三种解析方式:
1.re解析
2.bs4解析
3.xpath解析
这三种方式可以混合进行使用,完全以结果做导向,只要能拿到你想要的数据,用什么方案并不重要,当你掌握了这些之后.再考虑性能的问题。
二.re解析和正则表达式
Regular Expression,正则表达式,一种使用表达式的方式对字符串进行匹配的语法规则.
我们抓取到的网页源代码本质上就是一个超长的字符串,想从里面提取内容,用正则再合适不过了,
正则的优点: 速度快,效率高,准确性高
正则的缺点: 新手上手难度有点儿高.
不过只要掌握了正则编写的逻辑关系,写出一个提取页面内容的正则其实并不复杂
正则的语法: 使用元字符进行排列组合用来匹配字符串 在线测试正则表达式https:/tool.oschina.net/regex/
元字符: 具有固定含义的特殊符号
常用元字符:

量词:控制前面的元字符出现的次数

贪婪匹配和惰性匹配

这两个要着重的说一下.因为我们写爬虫用的最多的就是这个惰性匹配。
案例:
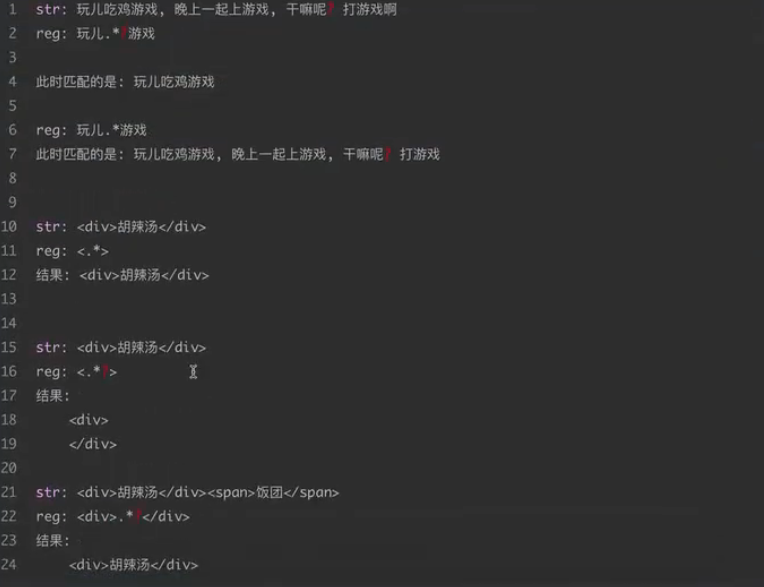
所以我们能发现这样一个规律:.?表示尽可能少的匹配.表示尽可能多的匹配,暂时先记住这个规律.后面写爬虫会用
到的哦
re解析和正则表达式的实战案例如下:
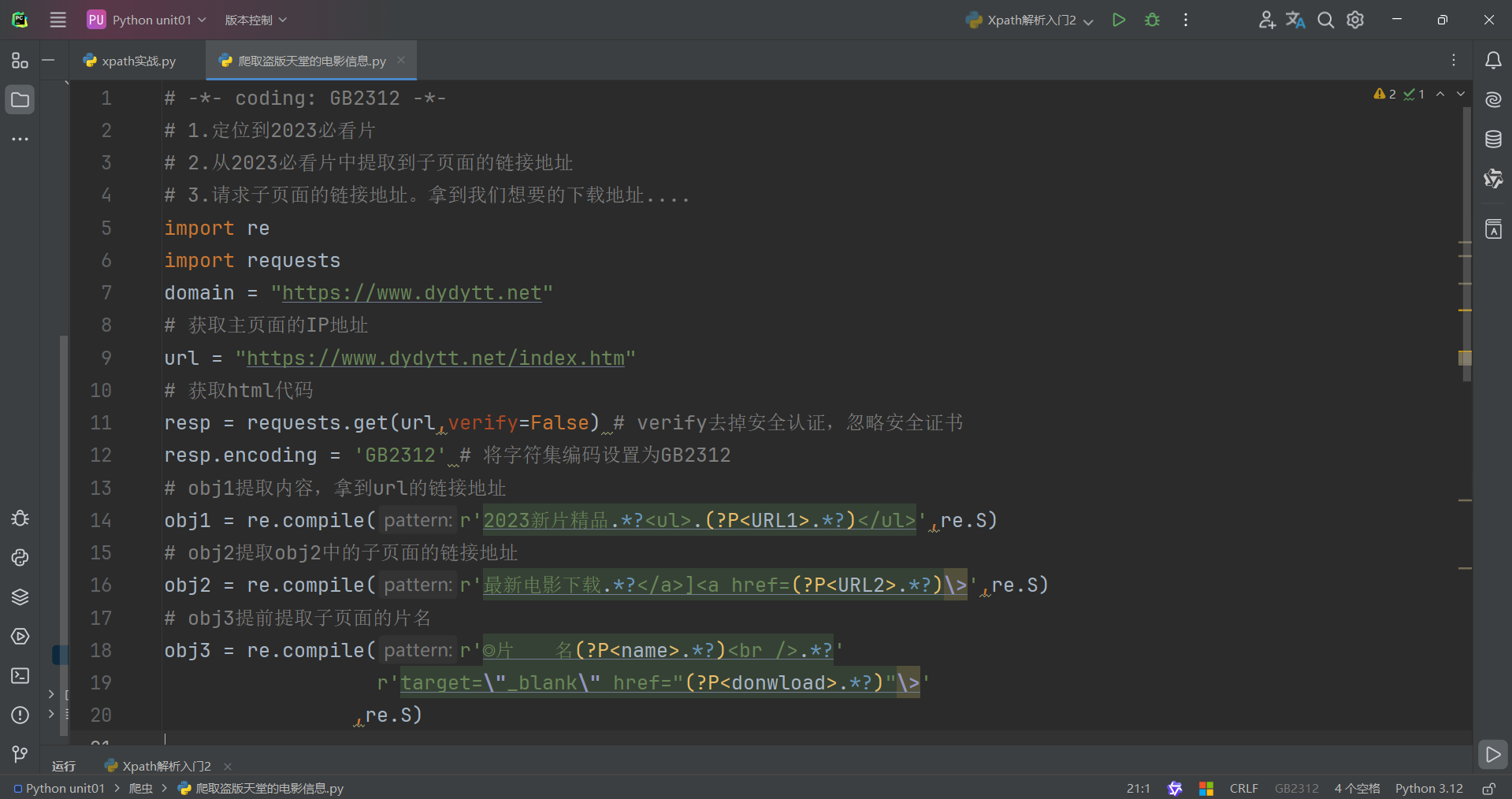
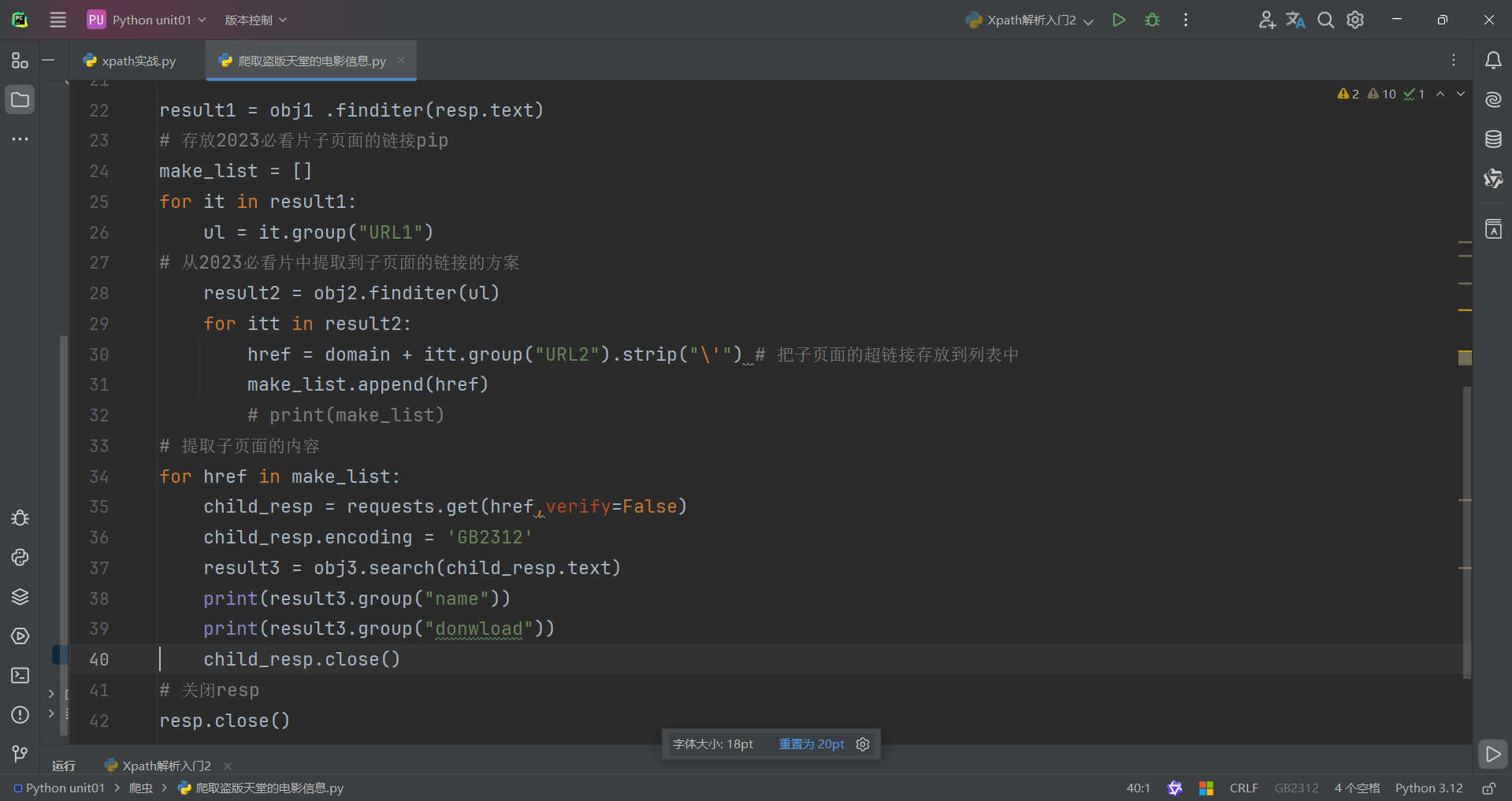
注:
利用re解析和正则解析的时候需要你去根据html的源代码去找他们规律,作为开头和结尾,常利用.*?作为最主要的爬取正则表达式。
若一个页面有https,我们可以将get方法中的verify的值赋False可以解决。
三.bs4解析-HTML语法
bs4解析比较简单,但是呢,首先你需要了解一丟丟的html知识,然后再去使用bs4去提取,逻辑和编写难度就会非常简
单和清晰。
HTML(Hyper Text Markup Language)超文本标记语言,是我们编写网页的最基本也是最核心的一种语言:其语法规则
就是用不同的标签对网页上的内容进行标记,从而使网页显示出不同的展示效果.

上述代码的含义是在页面中显示“我爱你“三个字,但是我爱你三个字被"<h1>"和"</h1>"标记了,白话就是被括起来了被H1这个标签括起来了,这个时候,浏览器在展示的时候就会让我爱你变粗变大,俗称标题,所以HTML的语法就是用类似这样的标签对页面内容进行标记,不同的标签表现出来的效果也是不一样的.
注:
- h1:一级标题
- h2:二级标题
- p:段落
- font:字体(被废弃了,但能用)
- body:主体
总结:
html语法:

bs4解析语法使用代码如下:
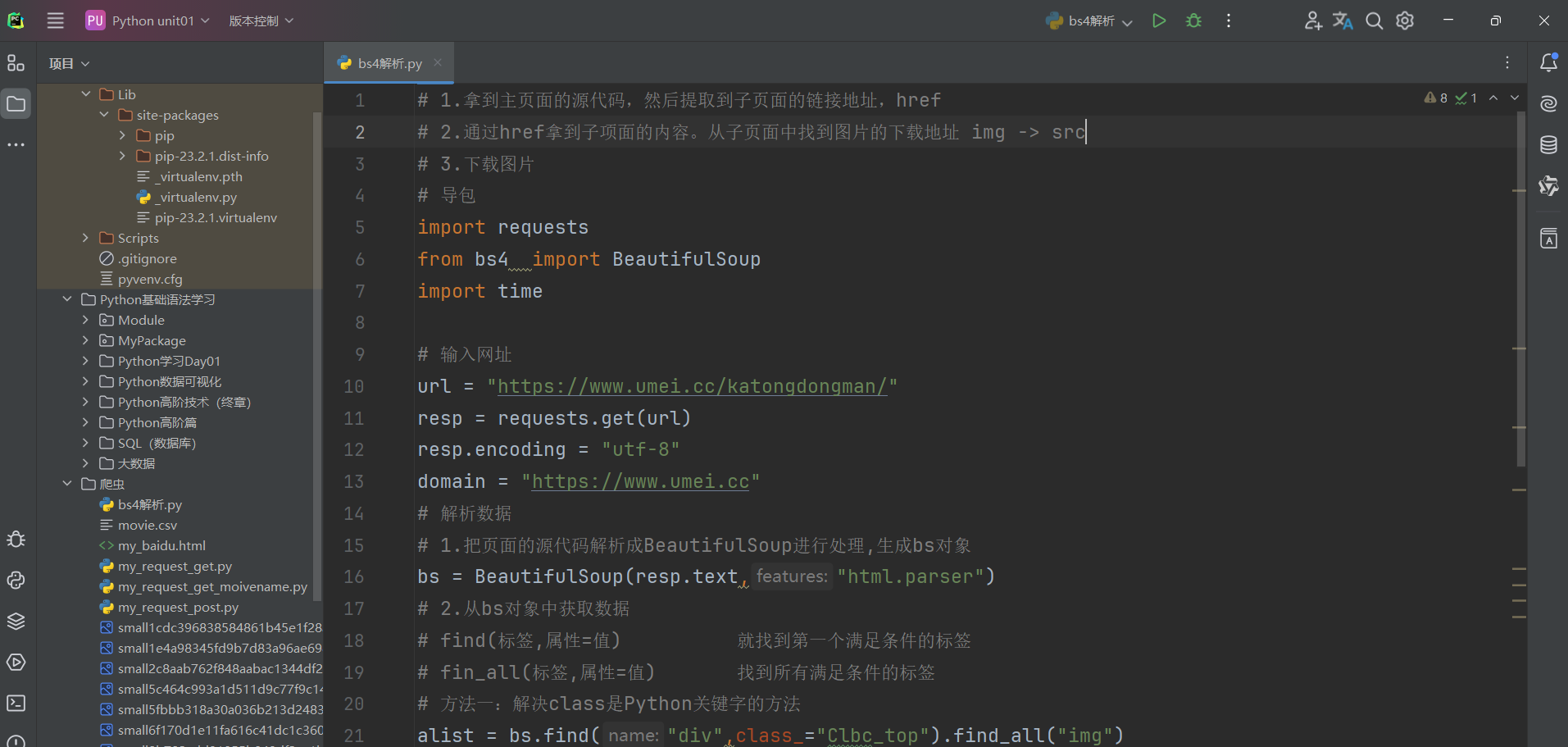
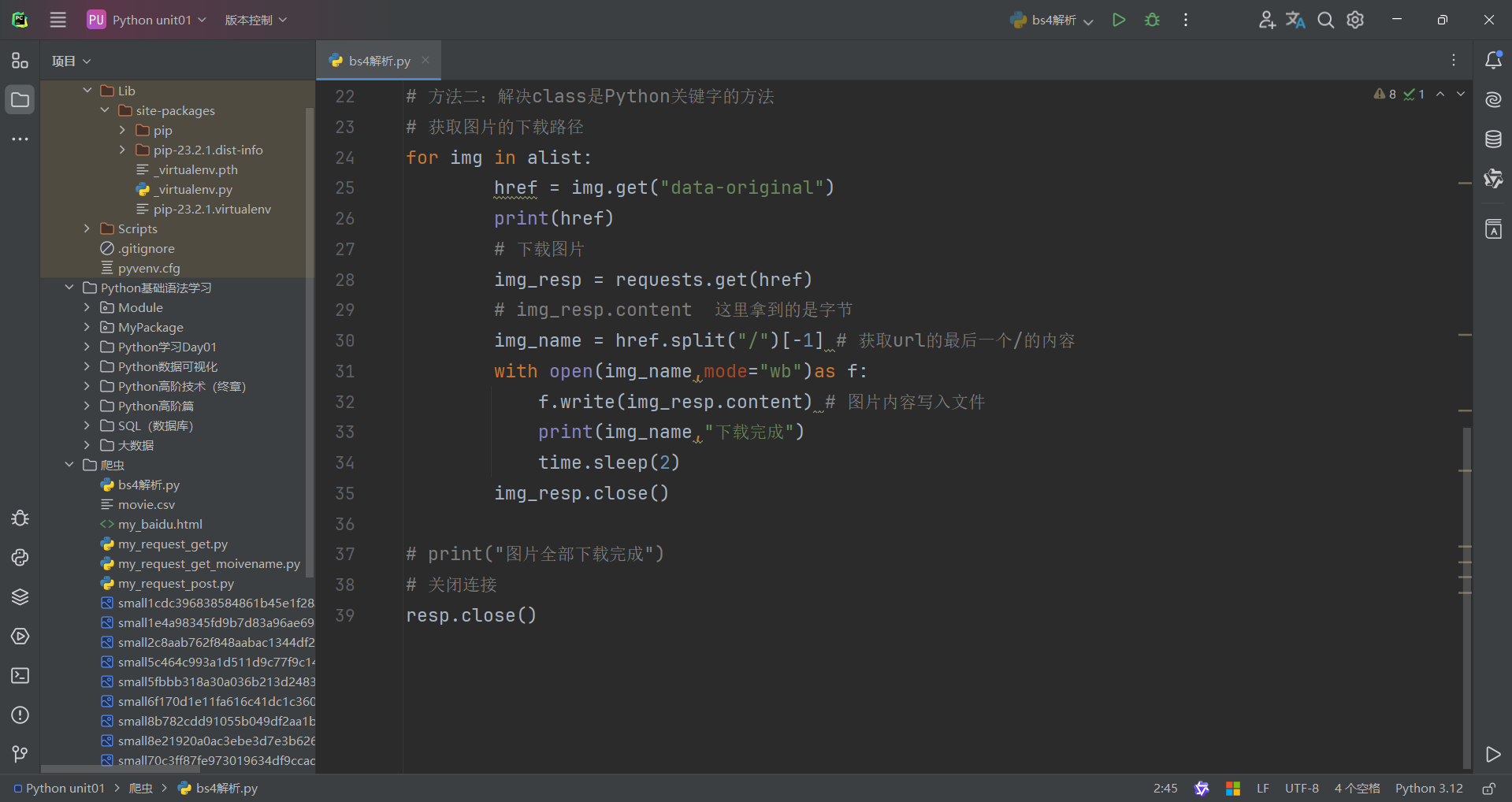
总结:
第一步:下载并导入bs4包
第二步:把页面的源代码解析成BeautifulSoup进行处理,生成bs对象
第三步:
爬取思路如下:
bs4解析的用法,主要还是需要一点html的知识,主要解析的方法过程,首先你需要去“查看网页源代码”,大部分网页源代码都是利用了安全手段,这里可能需要抓包,作者还未学这样的技术。但是解析的过程就是根据标签不同的地方去定位,需要查找解析的它所在的链接。然后根据这个链接去利用文件存入下载的图片即可完成。
四.Xpath解析
Xpath是XML文档中搜索内容的一门语言,html是XML的一个子集
在上述html中
1.book,id,name, price....都被称为节点
2.ld,name,price,author被称为book的子节点
3.book被称为id,name,price,author的父节点
4.id,name,price,author被称为同胞节点

有了这些基础知识后,我们就可以开始了解xpath的基本语法了在python中想要使用xpath,需要安装IxmI模块:
pip install –i https://pypi.tuna.tsinghua.edu.cn/simple lxml
用法:
1.将要解析的html内容构造出etree对象.
2.使用etree对象的xpath0方法配合xpath表达式来完成对数据的提取
xpath练习代码如下:
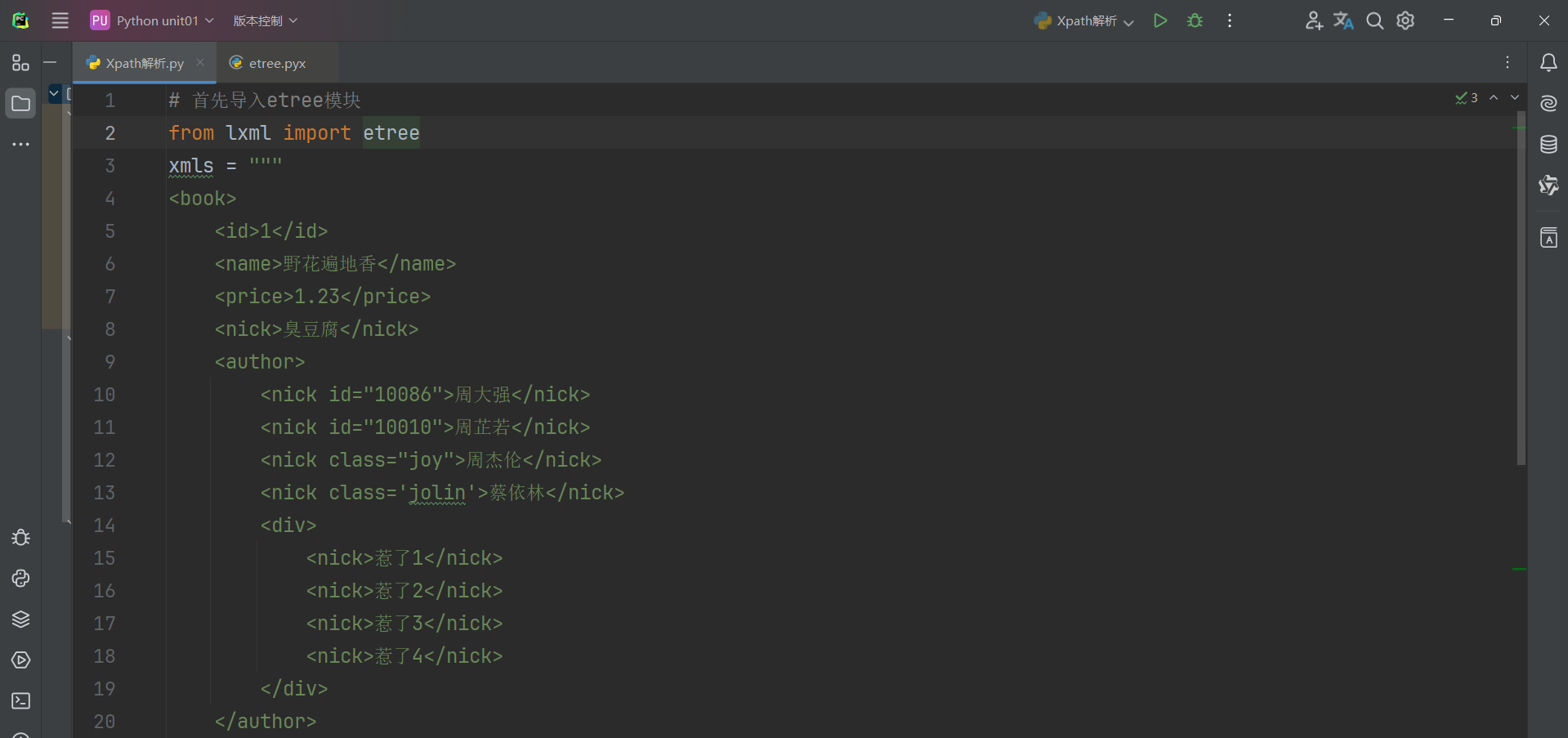
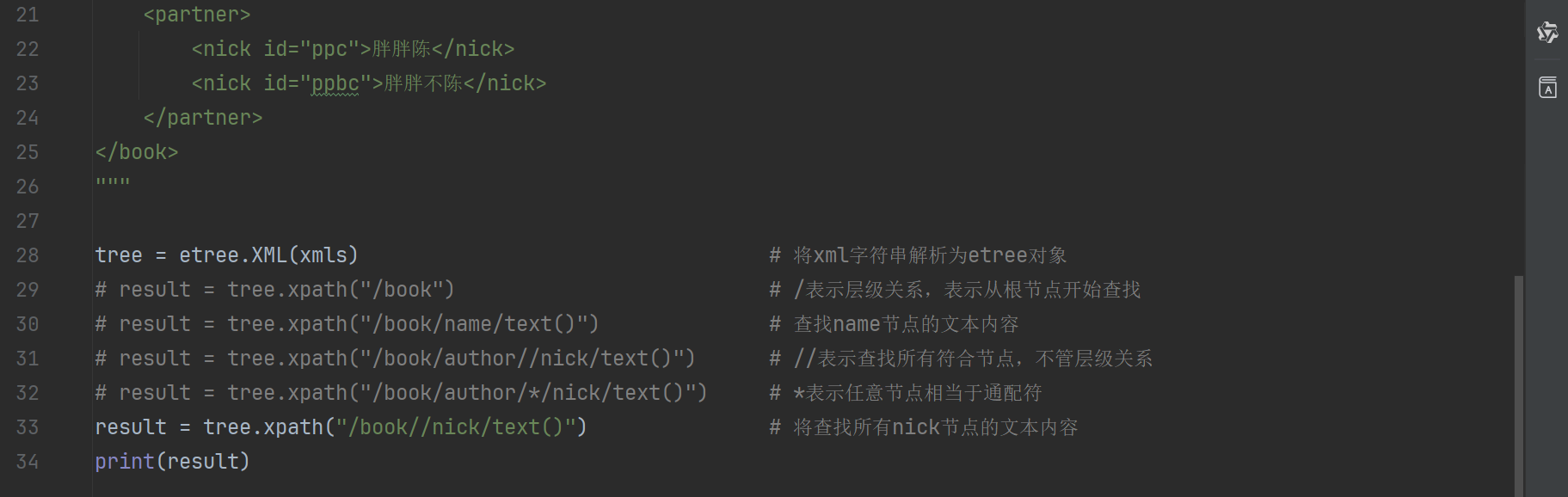
注:
/表示层级关系,表示从根节点开始查找
//表示查找所有符合节点,不管层级关系
*表示任意节点相当于通配符
xpath入门2代码示例如下:
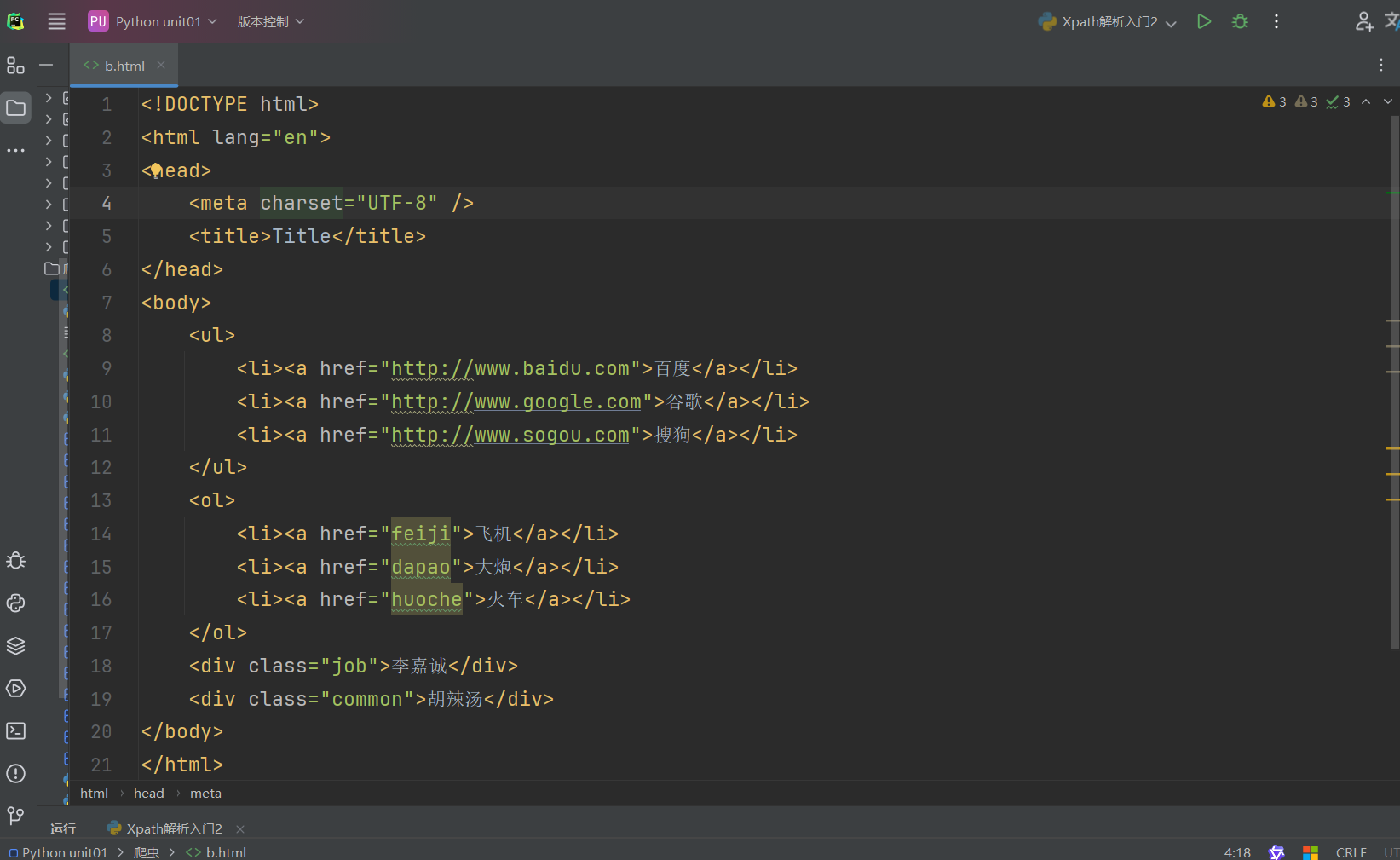
注:
@表示属性
xpath的索引从1开始,[]表示索引
[@***=***]表示属性的筛选
.表示相对查找在网页中可以按F12进入开发者模式,进入到elements然后可以右击选择“copy”->”copy xpath”这样及其方便。