深度学习总结(6)
随机梯度下降
给定一个可微函数,理论上可以用解析法找到它的最小值:函数的最小值就是导数为0的点,因此只需找到所有导数为0的点,然后比较函数在其中哪个点的取值最小。将这一方法应用于神经网络,就是用解析法求出损失函数最小值对应的所有权重值。可以通过对方程grad(f(W), W) = 0求解W来实现这一方法。这是一个包含N个变量的多项式方程,其中N是模型的系数个数。当N = 2或N = 3时,可以对这样的方程进行求解,但对于实际的神经网络是无法求解的,因为参数的个数不会少于几千个,而且经常有上千万个。
不过可以这么做:基于当前在随机数据批量上的损失值,一点一点地对参数进行调节。我们要处理的是一个可微函数,所以可以计算出它的梯度。沿着梯度的反方向更新权重,每次损失值都会减小一点。
(1)抽取训练样本x和对应目标y_true组成的一个数据批量。(2)在x上运行模型,得到预测值y_pred。这一步叫作前向传播。(3)计算模型在这批数据上的损失值,用于衡量y_pred和y_true之间的差距。(4)计算损失相对于模型参数的梯度。这一步叫作反向传播(backward pass)。(5)将参数沿着梯度的反方向移动一小步,比如W -= learning_rate * gradient,从而使这批数据上的损失值减小一些。学习率(learning_rate)是一个调节梯度下降“速度”的标量因子。这个方法叫作小批量随机梯度下降(mini-batch stochastic gradient descent,简称小批量SGD)。术语随机(stochastic)是指每批数据都是随机抽取的(stochastic在科学上是random的同义词)。下图给出了一维的例子,模型只有一个参数,并且只有一个训练样本。
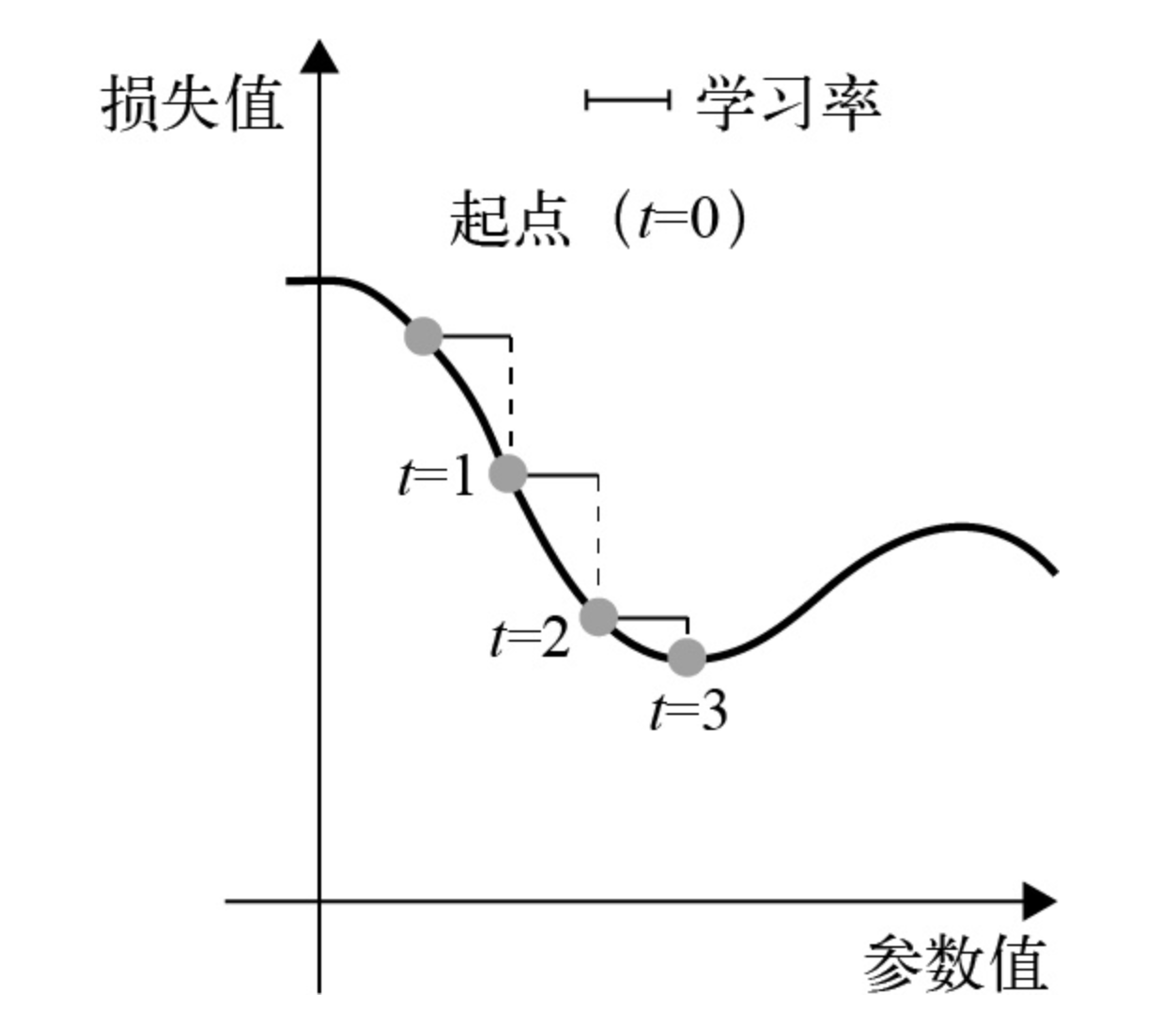
learning_rate因子的取值很重要。如果取值太小,那么沿着曲线下降需要很多次迭代,而且可能会陷入局部极小点。如果取值过大,那么更新权重值之后可能会出现在曲线上完全随机的位置。注意,小批量SGD算法的一个变体是每次迭代只抽取一个样本和目标,而不是抽取一批数据。这叫作真SGD(true SGD,有别于小批量SGD)。还可以走向另一个极端:每次迭代都在所有数据上运行,这叫作批量梯度下降(batch gradient descent)。这样做的话,每次更新权重都会更加准确,但计算成本也高得多。这两个极端之间有效的折中方法则是选择合理的小批量大小。
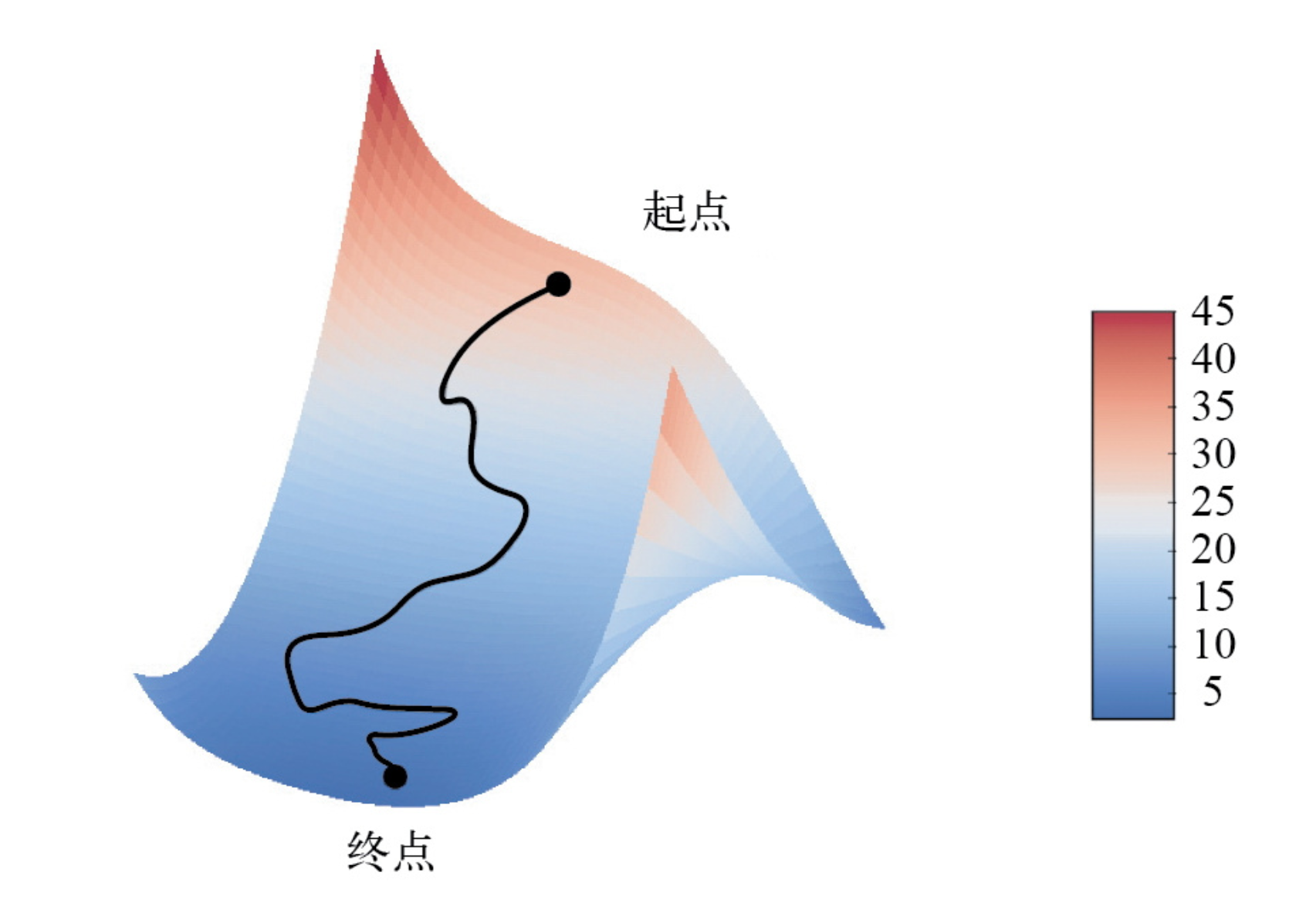
在实践中需要在高维空间中使用梯度下降。神经网络的每一个权重系数都是空间中的一个自由维度,神经网络则可能包含数万个甚至上百万个参数。为了对损失表面有更直观的认识,你还可以将沿着二维损失表面的梯度下降可视化,如下图所示。但你不可能将神经网络的真实训练过程可视化,因为无法用人类可以理解的方式来可视化1 000 000维空间。因此最好记住,在这些低维表示中建立的直觉,实践中不一定总是准确的。
SGD还有多种变体,比如带动量的SGD、Adagrad、RMSprop等。它们计算下一次权重更新时还要考虑上一次权重更新,而不是仅考虑当前的梯度值。这些变体被称为优化方法(optimization method)或优化器(optimizer)。动量的概念尤其值得关注,它被用于许多变体。动量解决了SGD的两个问题:收敛速度和局部极小值。下图给出了损失作为模型参数的函数的曲线。
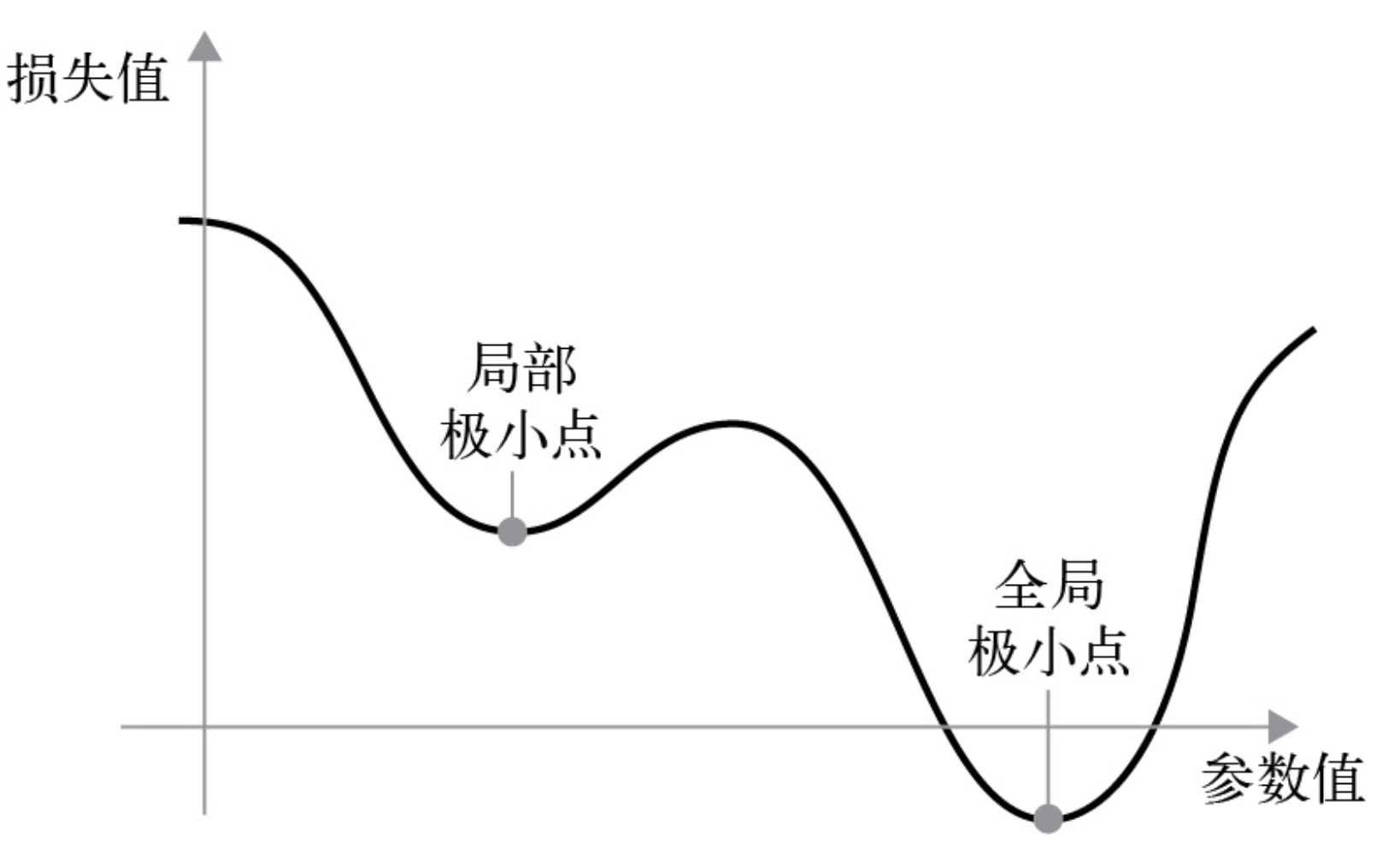
在某个参数值附近,有一个局部极小点(local minimum):在这个点附近,向左和向右移动都会导致损失值增大。如果使用学习率较小的SGD对参数进行优化,那么优化过程可能会陷入局部极小点,而无法找到全局极小点。使用动量方法可以避免这样的问题,这一方法的灵感来源于物理学。一个有用的思维模型是将优化过程想象成小球从损失函数曲线上滚下来。如果小球的动量足够大,那么它不会卡在峡谷里,最终会到达全局极小点。动量方法的实现过程是,每一步移动小球,不仅要考虑当前的斜率值(当前的加速度),还要考虑当前的速度(由之前的加速度产生)。这在实践中的含义是,更新参数w不仅要考虑当前梯度值,还要考虑上一次参数更新,其简单实现如下所示。
past_velocity = 0.
#不变的动量因子
momentum = 0.1
#优化循环
while loss > 0.01:
w, loss, gradient = get_current_parameters()
velocity = past_velocity * momentum - learning_rate * gradient
w = w + momentum * velocity - learning_rate * gradient
past_velocity = velocity
update_parameter(w)
链式求导:反向传播算法
反向传播是这样一种方法:利用简单运算(如加法、relu或张量积)的导数,可以轻松计算出这些基本运算的任意复杂组合的梯度。重要的是,神经网络由许多链接在一起的张量运算组成,每个张量运算的导数都是已知的,且都很简单。例如,代码清单2-2定义的模型可以表示为,一个由变量W1、b1、W2和b2(分别属于第1个和第2个Dense层)参数化的函数,其中用到的基本运算是dot、relu、softmax和+,以及损失函数loss。这些运算都是很容易求导的。