SQL优化技术分享:从 321 秒到 0.2 秒的性能飞跃 —— 基于 PawSQL 的 TPCH 查询优化实战
在数据库性能优化领域,TPC-H 测试集是一个经典的基准测试工具,常用于评估数据库系统的查询性能。本文将基于 TPCH 测试集中的第 20个查询,结合 PawSQL 自动化优化工具,详细分析如何通过 SQL 重写和索引设计,将查询性能从 321 秒提升到 0.2 秒,性能提升高达1541倍。
1. 背景介绍:一个典型的多表关联分析查询
TPC-H作为业界公认的数据库性能测试基准,其第20号查询(Q20)是一个极具挑战性的复杂分析查询。这个查询的业务场景是:识别阿尔及利亚('ALGERIA')地区库存充足的供应商,具体条件是这些供应商提供的绿色('green%')零件的库存量(ps_availqty)超过该零件在过去一年内订单总量的一半。
原始SQL语句如下:
select s_name, s_address
from supplier, nation
where s_suppkey in (
select ps_suppkey
from partsupp
where ps_partkey in (
select p_partkey
from part
where p_name like 'green%'
)
and ps_availqty > (
select 0.5 * sum(l_quantity)
from lineitem
where l_partkey = ps_partkey
and l_suppkey = ps_suppkey
and l_shipdate >= date '1997-01-01'
and l_shipdate < date '1997-01-01' + interval '1' YEAR
)
)
and s_nationkey = n_nationkey
and n_name = 'ALGERIA'
order by s_name在实际测试环境中,这个查询的执行时间达到了惊人的321秒,完全无法满足业务系统的要求。
2. 性能瓶颈分析:为什么这么慢?
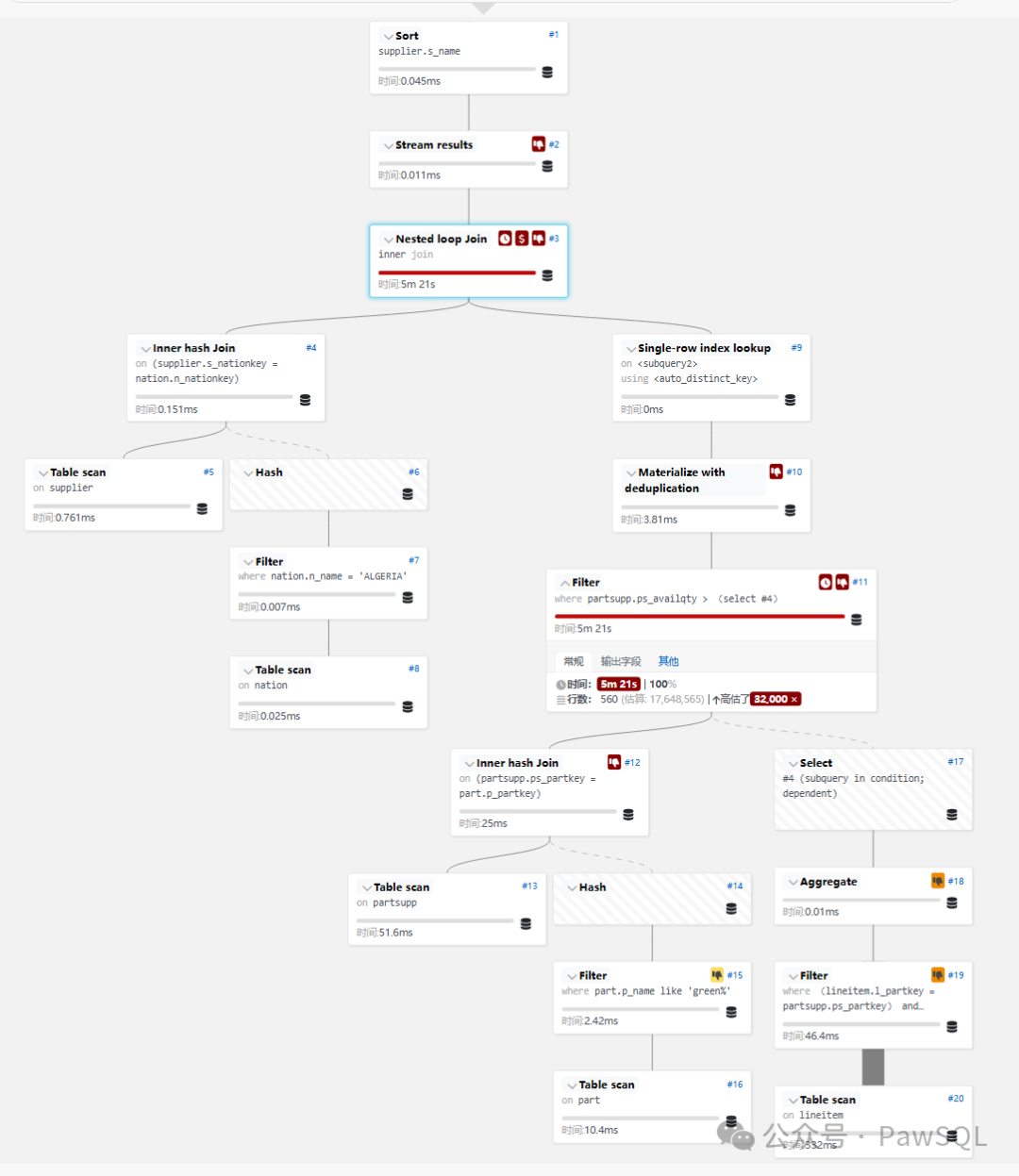
从执行计划可以看出主要性能问题:
-
子查询执行次数多:相关子查询被执行了848次,每次耗时约378ms
-
表扫描泛滥:对partsupp、part和lineitem表进行了全表扫描
-
嵌套循环效率低:对lineitem表的访问在嵌套循环最内层
-
排序操作代价高:最后需要对结果集进行排序
3. PawSQL的优化方案:系统性解决方案
PawSQL作为专业的SQL优化工具,针对上述问题提供了一套完整的优化方案:
3.1 SQL重写:从IN到EXISTS
将IN子查询转换为EXISTS形式,在有合适索引的情况下,这种改写通常能让优化器生成更高效的执行计划:
where exists (select /*QB_1*/ partsupp.ps_suppkey
from partsupp, (...)
where exists (select /*QB_4*/ part.p_partkey
from part
where part.p_name like 'green%' and part.p_partkey = partsupp.ps_partkey)
and partsupp.ps_availqty > SQ_1742975670803.null_
and partsupp.ps_suppkey = supplier.s_suppkey
and SQ_1742975670803.l_partkey = partsupp.ps_partkey
and SQ_1742975670803.l_suppkey = partsupp.ps_suppkey)
3.2 SQL重写:提前聚合计算
将lineitem的聚合计算从子查询中提取出来,预先计算每个(零件,供应商)组合的总量:
select 0.5 * sum(l_quantity) as null_, l_partkey,
l_suppkey
from lineitem
where l_shipdate >= date '1997-01-01'
and l_shipdate < date '1997-01-01' + interval '1' YEAR
group by l_partkey, l_suppkey3.3 智能索引设计
除了SQL重写外,PawSQL还为优化后的SQL推荐了一系列索引,这些索引的创建为查询性能的提升提供了有力支持。
-- 加速lineitem表的聚合计算
CREATE INDEX PAWSQL_IDX1406058528 ON lineitem(l_shipdate,l_quantity,l_partkey,l_suppkey);
-- 优化nation表查询
CREATE INDEX PAWSQL_IDX0006674720 ON nation(n_name,n_nationkey);
-- 支持supplier表的排序和连接
CREATE INDEX PAWSQL_IDX1461825654 ON supplier(s_name,s_address,s_nationkey);
CREATE INDEX PAWSQL_IDX1670284145 ON supplier(s_nationkey,s_name,s_address);
-- 加速part和partsupp表的连接
CREATE INDEX PAWSQL_IDX0450194419 ON part(p_partkey,p_name);
CREATE INDEX PAWSQL_IDX1262756509 ON partsupp(ps_partkey,ps_suppkey,ps_availqty);3.4 谓词下推
将过滤条件尽可能下推到数据访问层,减少中间结果集:
-
nation.n_name = 'ALGERIA' -
part.p_name like 'green%' -
lineitem.l_shipdate范围条件
3.5. 避免排序
通过创建包含s_name的索引,直接利用索引的有序性避免排序操作。
4. 优化效果:性能提升1541倍
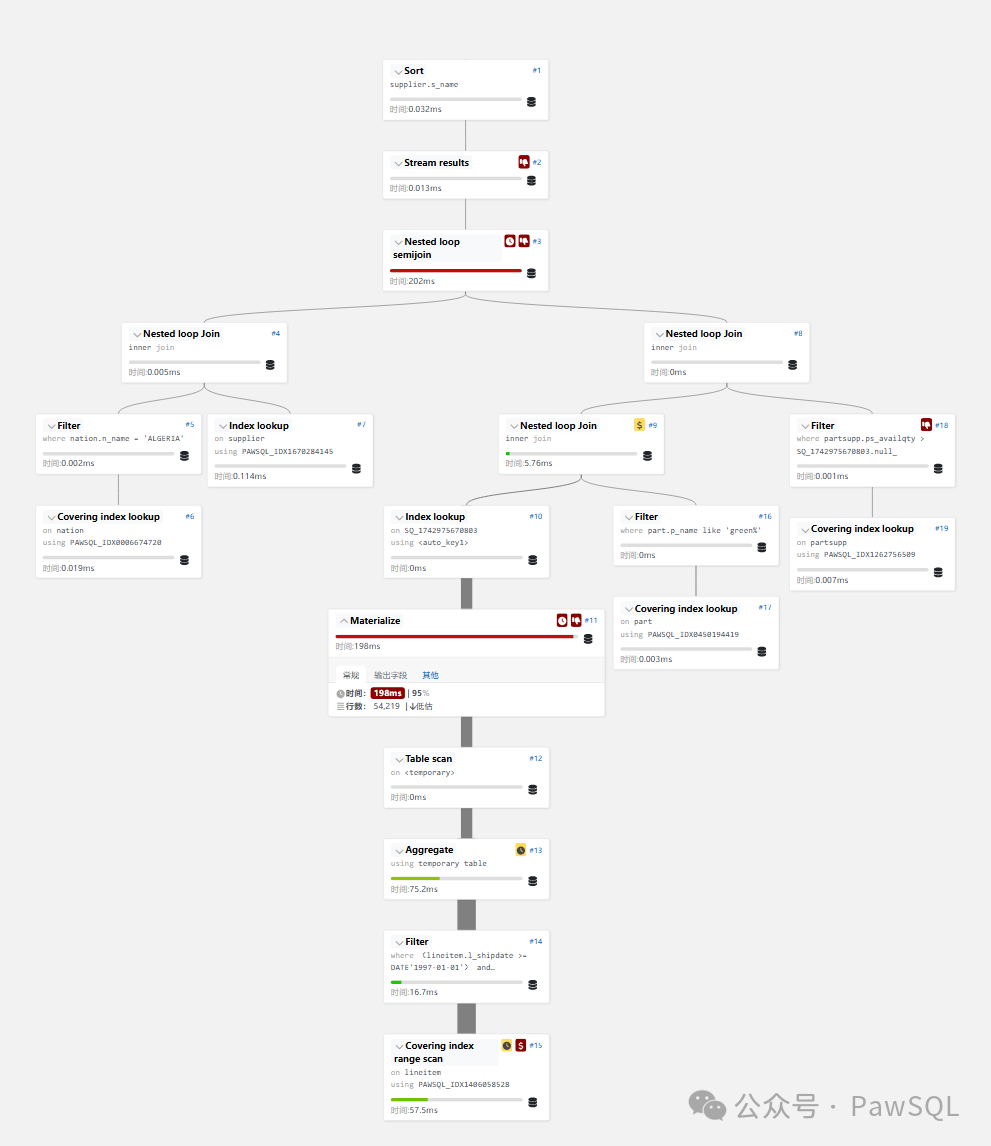
优化前后的对比令人震撼:
| 指标 | 优化前 | 优化后 | 提升幅度 |
|---|---|---|---|
| 执行时间 | 321秒 | 0.208秒 | 154,124% |
| lineitem表扫描次数 | 848次 | 1次 | - |
| lineitem表扫描行数 | 509,285,056行 | 90,514行 | - |
| 排序操作 | 需要显式排序 | 利用索引避免排序 | - |
执行计划对比:
-
优化前:全表扫描→嵌套循环→重复计算
-
优化后:索引查找→哈希连接→物化视图
5. 经验总结:SQL优化最佳实践
通过这个案例,我们可以总结出以下SQL优化经验:
-
避免关联子查询:特别是重复执行的关联子查询,考虑改写为JOIN或提前物化
-
索引设计:尽量减少表扫描,同时兼顾避免回表操作
-
利用索引有序性:让索引顺序与ORDER BY一致可以避免排序操作
-
聚合计算预优化:对于重复的聚合计算,考虑提前计算并存储
-
专业工具辅助:使用PawSQL等专业工具可以快速定位问题并提供优化方案
这个案例生动展示了:即使是极其复杂的分析查询,通过系统性的优化方法,也能实现从分钟级到亚秒级的性能飞跃。
🌐 关于PawSQL
PawSQL专注于数据库性能优化自动化和智能化,提供的解决方案覆盖SQL开发、测试、运维的整个流程,广泛支持包括MySQL/PostgreSQL/Oracle /openGauss/TDSQL/Oceanbase/达梦DM/金仓等各种主流商用和开源数据库,为开发者和企业提供一站式的创新SQL优化解决方案。