动手人形机器人(RL)
1 PPO的讲解
核心步骤,如策略网络和价值网络的定义、优势估计、策略更新、价值更新等基础功能的实现
2 代码构成
可能涉及
初始化,Behavior Clone
3 动手强化学习
import pytorch as torch
class actorcritic
##等待补充
4 PD Gains
在机器人学中,PD gains(比例 - 微分增益) 是指比例控制(Proportional control)和微分控制(Derivative control)中的增益参数,分别称为 P gain(比例增益) 和 D gain(微分增益),它们是 PD 控制算法的核心组成部分,对机器人的运动控制性能起着关键作用。具体如下:
1. P gain(比例增益)
- 作用:与机器人当前的误差(如位置误差、角度误差等)成正比,用于快速响应误差。例如,当机器人的机械臂需要移动到某个目标位置时,若实际位置与目标位置存在误差,比例增益会根据误差大小输出一个控制量,推动机械臂向减小误差的方向运动。
- 影响:比例增益越大,系统对误差的响应越迅速,但过大的比例增益可能导致系统超调(即运动超过目标位置),甚至产生震荡,使机器人运动不稳定。
2. D gain(微分增益)
- 作用:与误差的变化率成正比,用于预测误差的变化趋势。它能根据误差变化的快慢调整控制量,抑制超调,增加系统的稳定性。例如,当机械臂接近目标位置时,微分增益会检测到误差变化率减小,提前降低控制量,使机械臂平稳停止,避免冲过目标位置。
- 影响:合适的微分增益可以改善系统的动态特性,减少调整时间;但微分增益过大可能使系统对噪声过于敏感(如传感器噪声会被放大影响控制),过小则难以有效抑制超调。
机器人学中的应用示例
在机器人的关节控制中,PD 控制常用于调节电机的输出。例如,若机器人某关节需要从当前角度转动到目标角度:
- 当角度误差较大时,比例增益起主导作用,快速驱动关节向目标角度转动;
- 随着角度误差减小,微分增益根据误差变化率调整输出,使关节平稳地停在目标角度,避免来回晃动。
## 机器人关节电机控制模式及参数
class control:
## 控制类型:位置控制、速度控制、扭矩控制
control_type = 'P' # P: position, V: velocity, T: torques
## PD驱动的参数
## stiffness代表刚度系数k_p damping代表阻尼系数k_d
stiffness = {'joint_a': 10.0, 'joint_b': 15.} # [N*m/rad]
damping = {'joint_a': 1.0, 'joint_b': 1.5} # [N*m*s/rad]
## 公式如下,与action的转化为什么要有这样的比例因子暂未明白
# action scale: target angle = actionScale * action + defaultAngle
action_scale = 0.5
## decimation: Number of control action updates @ sim DT per policy DT
## 仿真环境的控制频率/decimation=实际环境中的控制频率
decimation = 4
5 相关研究分享
1 CMU的H2O
Learning Human-to-Humanoid Real-Time Whole-Body TeleoperationLearning Human-to-Humanoid Real-Time Whole-Body Teleoperation![]() https://human2humanoid.com/
https://human2humanoid.com/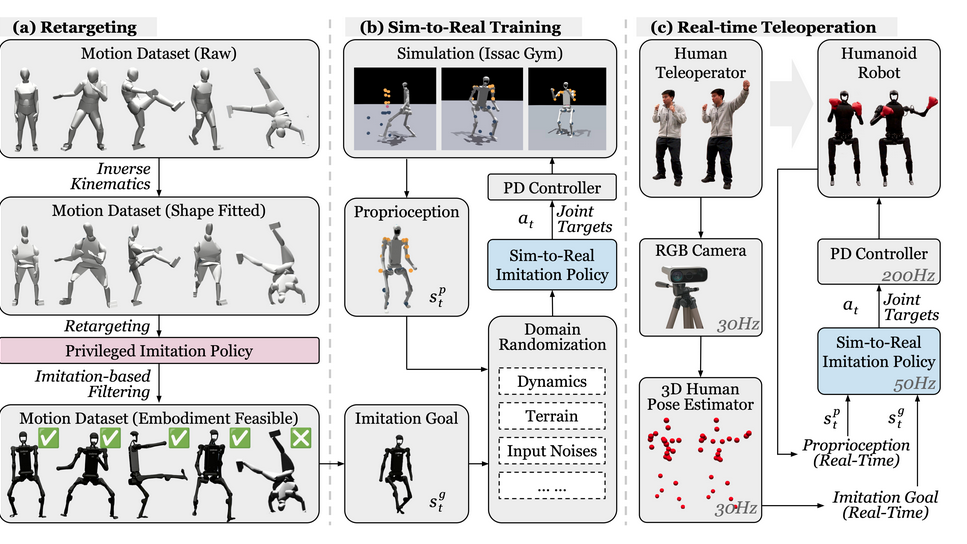
2 leggedgym
ETH开发的库函数
https://github.com/leggedrobotics/legged_gym![]() https://github.com/leggedrobotics/legged_gym
https://github.com/leggedrobotics/legged_gym
如何使用?:
- Train:
python legged_gym/scripts/train.py --task=anymal_c_flat
- To run on CPU add following arguments:
--sim_device=cpu,--rl_device=cpu(sim on CPU and rl on GPU is possible).- To run headless (no rendering) add
--headless.- Important: To improve performance, once the training starts press
vto stop the rendering. You can then enable it later to check the progress.- The trained policy is saved in
issacgym_anymal/logs/<experiment_name>/<date_time>_<run_name>/model_<iteration>.pt. Where<experiment_name>and<run_name>are defined in the train config.- The following command line arguments override the values set in the config files:
- --task TASK: Task name.
- --resume: Resume training from a checkpoint
- --experiment_name EXPERIMENT_NAME: Name of the experiment to run or load.
- --run_name RUN_NAME: Name of the run.
- --load_run LOAD_RUN: Name of the run to load when resume=True. If -1: will load the last run.
- --checkpoint CHECKPOINT: Saved model checkpoint number. If -1: will load the last checkpoint.
- --num_envs NUM_ENVS: Number of environments to create.
- --seed SEED: Random seed.
- --max_iterations MAX_ITERATIONS: Maximum number of training iterations.
- Play a trained policy:
python legged_gym/scripts/play.py --task=anymal_c_flat
- By default, the loaded policy is the last model of the last run of the experiment folder.
- Other runs/model iteration can be selected by setting
load_runandcheckpointin the train config.
3 RL_rsl
https://github.com/leggedrobotics/rsl_rl![]() https://github.com/leggedrobotics/rsl_rl
https://github.com/leggedrobotics/rsl_rl
快速、简单地实现RL算法,旨在在GPU上完全运行。 这段代码是一个进化过程。rl-pytorchNVIDIA 的 Isaac GYM 发布。
使用框架的环境存储库:
Isaac Lab(建立在NVIDIA Isaac Sim之上):https://github.com/isaac-sim/IsaacLabLegged-Gym(基于 NVIDIA Isaac Gym 构建):https://leggedrobotics.github.io/legged_gym/
PPO主要分支支持PPO和学生教师蒸馏,以及我们研究的其他功能。这些包括:
- 随机网络蒸馏(RND)
 https://proceedings.mlr.press/v229/schwarke23a.html - 通过添加来鼓励探索 好奇心驱动的内在奖励。
https://proceedings.mlr.press/v229/schwarke23a.html - 通过添加来鼓励探索 好奇心驱动的内在奖励。 - 基于对称性的增强https://arxiv.org/abs/2403.04359 - 使学习的行为更加对称。