力扣Hot100题,刷题
力扣HOT100 - 1. 两数之和
解题思路:
解法一:暴力
class Solution {
public int[] twoSum(int[] nums, int target) {
int n = nums.length;
for (int i = 0; i < n; i++)
for (int j = i + 1; j < n; j++) {
if (target == nums[i] + nums[j])
return new int[] { i, j };
}
return new int[0];
}
}
解法二:哈希表
class Solution {
public int[] twoSum(int[] nums, int target) {
Map<Integer, Integer> map = new HashMap<>();
for (int i = 0; i < nums.length; ++i) {
if (map.containsKey(target - nums[i])) {
//保证返回的下标由小到大
return new int[]{map.get(target - nums[i]), i};
}
map.put(nums[i], i);
}
return new int[0];
}
}
解析:
这段代码实现的是经典的 两数之和(Two Sum) 算法,通过使用哈希表(HashMap)来优化时间复杂度。以下是对代码的详细解析:
代码功能
- 输入:一个整数数组
nums和一个目标值target。 - 输出:返回数组中两个不同下标
i和j,使得nums[i] + nums[j] == target。- 如果存在解,保证返回的下标
i < j(按升序排列)。 - 如果无解,返回空数组
new int[0]。
- 如果存在解,保证返回的下标
算法思路
-
哈希表辅助:
- 使用
HashMap存储数组元素值 (nums[i]) 和对应的下标 (i)。 - 对于当前元素
nums[i],检查target - nums[i]是否已存在于哈希表中:- 如果存在,说明找到了这两个数,直接返回它们的下标。
- 如果不存在,将当前
nums[i]和i存入哈希表,继续遍历。
- 使用
-
时间复杂度:
- O(n):只需遍历数组一次,哈希表的插入和查询操作平均为 O(1)。
- 比暴力解法(O(n²))更高效。
-
空间复杂度:
- O(n):最坏情况下需要存储所有元素到哈希表。
代码逐行解析
public int[] twoSum(int[] nums, int target) {
Map<Integer, Integer> map = new HashMap<>(); // 键:数组元素值,值:下标
for (int i = 0; i < nums.length; ++i) {
if (map.containsKey(target - nums[i])) { // 检查是否已有互补数
return new int[]{map.get(target - nums[i]), i}; // 返回升序下标
}
map.put(nums[i], i); // 存入当前数和下标
}
return new int[0]; // 无解时返回空数组
}
关键点
-
为什么能保证下标升序?
- 当发现
target - nums[i]在哈希表中时,该数一定是在nums[i]之前被存入的(因为当前nums[i]还未存入)。 - 因此
map.get(target - nums[i])获取的下标一定小于i,直接返回{map.get(...), i}即满足升序。
- 当发现
-
如何处理重复元素?
- 例如
nums = [3, 3], target = 6:- 第一个
3存入哈希表(map = {3: 0})。 - 第二个
3时,target - 3 = 3已在哈希表中,直接返回[0, 1]。
- 第一个
- 注意:如果问题要求不能重复使用同一元素(如
nums = [3], target = 6),需额外判断(但本题约束保证解存在或唯一)。
- 例如
-
为什么返回
new int[0]而不是null?- 空数组更安全,调用方无需判空,可直接通过
result.length == 0判断无解。
- 空数组更安全,调用方无需判空,可直接通过
示例运行
-
输入:
nums = [2, 7, 11, 15], target = 9- 步骤:
i=0:2的互补数7不在哈希表 → 存入{2: 0}。i=1:7的互补数2在哈希表 → 返回[0, 1]。
- 步骤:
-
输入:
nums = [3, 2, 4], target = 6- 返回
[1, 2](因为2 + 4 = 6,且下标升序)。
- 返回
边界情况
- 无解时:如
nums = [1, 2], target = 4→ 返回[]。 - 重复元素:如
nums = [3, 3], target = 6→ 返回[0, 1]。 - 负数或零:如
nums = [-1, 0], target = -1→ 返回[0, 1]。
优化与变种
- 提前返回:一旦找到解立即返回,减少不必要的遍历。
- 处理重复元素:如果问题要求所有可能的解(不止一个),可以用
List存储结果。 - 排序+双指针:如果需返回数值而非下标,可先排序后用双指针(但会改变下标信息)。
总结
- 该实现是两数之和问题的最优解之一,兼顾了时间复杂度和代码简洁性。
- 核心思想:用空间换时间,通过哈希表避免嵌套循环。
如果有其他变种问题(如三数之和、允许重复使用元素等),可以进一步讨论!
力扣HOT100 - 49. 字母异位词分组

注意:
返回时不能用List,因为List是抽象类,return的必须是List的具体实现,如ArrayList
class Solution {
public List<List<String>> groupAnagrams(String[] strs) {
Map<String, List<String>> map = new HashMap<>();
for (String str : strs) {
char[] array = str.toCharArray();
Arrays.sort(array);
String key = new String(array);
List<String> list = map.getOrDefault(key, new ArrayList<String>());
list.add(str);
map.put(key, list);
}
//返回时不能用List,而必须是List的具体实现,如ArrayList
return new ArrayList<List<String>>(map.values());
}
}
解析:
这段代码实现的是 字母异位词分组(Group Anagrams) 问题,通过将每个字符串排序后的结果作为键,将字母异位词归类到同一个列表中。以下是详细解析:
问题描述
- 输入:一个字符串数组
strs(例如["eat","tea","tan","ate","nat","bat"])。 - 输出:将字母异位词(由相同字母重排列组成的字符串)分到同一组,返回分组后的列表(如
[["eat","tea","ate"], ["tan","nat"], ["bat"]])。
算法思路
-
哈希表分组:
- 使用
HashMap,键是 排序后的字符串(字母异位词排序后相同),值是对应的原始字符串列表。 - 遍历每个字符串,先排序其字符数组,生成统一的键,再将原始字符串加入对应的列表。
- 使用
-
关键操作:
- 排序字符数组:将字符串转换为
char[]并排序,使得字母异位词具有相同的键(如"eat"和"tea"均排序为"aet")。 - 哈希表管理:使用
map.getOrDefault()避免重复创建列表。
- 排序字符数组:将字符串转换为
-
复杂度分析:
- 时间复杂度:O(n * k log k),其中
n是数组长度,k是字符串最大长度(排序每个字符串的代价)。 - 空间复杂度:O(n * k),哈希表存储所有字符串。
- 时间复杂度:O(n * k log k),其中
代码逐行解析
public List<List<String>> groupAnagrams(String[] strs) {
Map<String, List<String>> map = new HashMap<>(); // 键:排序后的字符串,值:原始字符串列表
for (String str : strs) {
char[] array = str.toCharArray(); // 转为字符数组
Arrays.sort(array); // 排序(字母异位词排序后相同)
String key = new String(array); // 生成统一键
List<String> list = map.getOrDefault(key, new ArrayList<String>()); // 获取或新建列表
list.add(str); // 加入当前字符串
map.put(key, list); // 更新哈希表
}
return new ArrayList<List<String>>(map.values()); // 返回所有分组
}
关键点
-
为什么排序字符数组?
- 字母异位词排序后结果相同(如
"eat"→"aet","tea"→"aet"),可作为分组的唯一标识。
- 字母异位词排序后结果相同(如
-
map.getOrDefault()的作用:- 若键不存在,返回默认值(新建的
ArrayList);若存在,直接返回对应的列表。避免手动检查键是否存在。
- 若键不存在,返回默认值(新建的
-
返回值处理:
map.values()返回所有分组的集合,通过new ArrayList<>(...)包装成List<List<String>>类型。
示例运行
- 输入:
strs = ["eat","tea","tan","ate","nat","bat"]- 步骤:
"eat"→ 排序为"aet"→ 新建列表["eat"]。"tea"→ 排序为"aet"→ 加入列表["eat", "tea"]。"tan"→ 排序为"ant"→ 新建列表["tan"]。- 最终分组:
{"aet": ["eat","tea","ate"], "ant": ["tan","nat"], "abt": ["bat"]}。
- 输出:
[["eat","tea","ate"], ["tan","nat"], ["bat"]]。
- 步骤:
优化与变种
-
优化键的生成:
- 若字符串只含小写字母,可用 字符计数数组 作为键(如
"aab"表示为[2,1,0,...,0]),避免排序开销:int[] count = new int[26]; for (char c : str.toCharArray()) count[c - 'a']++; String key = Arrays.toString(count); // 将计数数组转为字符串作为键- 时间复杂度降至 O(n * k)。
- 若字符串只含小写字母,可用 字符计数数组 作为键(如
-
处理大写/特殊字符:
- 扩展字符计数数组的长度(如 ASCII 码范围)。
-
返回其他结构:
- 若需按组内字符串数量排序,可对
map.values()进行排序。
- 若需按组内字符串数量排序,可对
边界情况
- 空数组输入:
strs = []→ 返回[]。 - 所有字符串相同:
strs = ["a","a"]→ 返回[["a","a"]]。 - 无字母异位词:
strs = ["a","b"]→ 返回[["a"], ["b"]]。
总结
- 该解法通过 排序统一键 或 字符计数 高效分组,是字母异位词问题的标准解法。
- 选择排序还是计数取决于字符集大小(小写字母优先用计数)。
如果有其他需求(如按字典序输出分组),可以进一步调整!
力扣HOT100 - 128. 最长连续序列

解题思路:
注意:
1.Set不能直接排序,必须要转换成ArrayList或者LinkedList后用Collections.sort()方法进行排序。
(Queue也不能直接排序,排序方法同Set)
2.连续的序列不能只找第一个,因为不一定是最长的,需要全部遍历完才能找到最长序列。
class Solution {
public int longestConsecutive(int[] nums) {
if (nums.length == 0) return 0;
Set<Integer> set = new HashSet<>();
for (int i = 0; i < nums.length; i++) {
set.add(nums[i]);
}
List<Integer> list = new ArrayList<>(set);
Collections.sort(list);
//cnt的长度从1开始,本身长度为1
int cnt = 1;
int max = 0;
//减一是为了避免越界
for (int i = 0; i < list.size() - 1; i++) {
if (list.get(i) == list.get(i + 1) - 1) {
cnt++;
} else {
max = Math.max(cnt, max);
//重置cnt的值
cnt = 1;
}
}
max = Math.max(cnt, max);
return max;
}
}```
解析:
这段代码实现了 **最长连续序列(Longest Consecutive Sequence)** 问题,但存在一些可以优化的地方。以下是详细解析和改进建议:
---
### **原代码分析**
#### **思路**
1. **去重**:使用 `HashSet` 去除重复数字。
2. **排序**:将去重后的数字存入 `ArrayList` 并排序。
3. **遍历统计**:检查相邻数字是否连续,统计最长连续序列长度。
#### **复杂度**
- **时间复杂度**:O(n log n),主要由排序步骤决定(`Collections.sort()`)。
- **空间复杂度**:O(n),用于存储去重后的数字。
#### **问题**
- **排序不必要**:题目要求连续序列(如 `[1,2,3]`),但排序增加了时间复杂度。
- **边界处理冗余**:末尾需要额外 `Math.max(cnt, max)` 处理最后一个连续序列。
---
### **优化思路**
利用 **哈希集合** 直接寻找连续序列的起点,避免排序:
1. **将所有数字存入集合**(去重)。
2. **遍历集合**,仅当当前数字 `num` 是某个连续序列的起点(即 `num-1` 不在集合中)时,向后检查 `num+1, num+2,...` 是否存在,统计长度。
3. **更新最大值**。
#### **优化后复杂度**
- **时间复杂度**:O(n),每个数字最多被访问两次(一次在集合中,一次在连续序列检查中)。
- **空间复杂度**:O(n)。
---
### **优化后的代码**
```java
class Solution {
public int longestConsecutive(int[] nums) {
if (nums.length == 0) return 0;
Set<Integer> set = new HashSet<>();
for (int num : nums) {
set.add(num); // 去重
}
int maxLen = 1;
for (int num : set) {
// 只有当 num 是连续序列的起点时才检查(避免重复计算)
if (!set.contains(num - 1)) {
int currentNum = num;
int currentLen = 1;
// 向后查找连续的数字
while (set.contains(currentNum + 1)) {
currentNum++;
currentLen++;
}
maxLen = Math.max(maxLen, currentLen);
}
}
return maxLen;
}
}
关键改进点
- 避免排序:直接利用集合的 O(1) 查询特性。
- 高效检查连续序列:仅对可能的序列起点(
num-1不在集合中)进行检查。 - 边界处理简化:无需处理排序后的末尾特殊情况。
示例运行
- 输入:
nums = [100, 4, 200, 1, 3, 2]- 步骤:
- 集合:
{1, 2, 3, 4, 100, 200}。 - 检查起点:
1(0不在集合中)→ 连续序列1,2,3,4,长度 4。100(99不在集合中)→ 连续序列100,长度 1。200(199不在集合中)→ 连续序列200,长度 1。
- 集合:
- 输出:
4。
- 步骤:
边界情况
- 空数组:直接返回
0。 - 所有数字相同:如
[1,1,1]→ 去重后[1],返回1。 - 无连续序列:如
[5, 7, 9]→ 每个数字单独成组,返回1。
总结
- 原始代码:通过排序解决问题,但时间复杂度过高(O(n log n))。
- 优化后代码:利用哈希集合将时间复杂度降至 O(n),更高效。
- 适用场景:当输入规模较大时(如
n > 10^5),优化后的方法优势明显。
力扣HOT100 - 283. 移动零
解题思路:
双指针
指针 i 用于寻找不为零的位置
指针 j 用于寻找为零的位置
找到不为零时位置时与为零的位置进行交换,即nums[ i ]与nums[ j ]交换,使零向后移动,i 和 j 同时向下一个位置移动。
class Solution {
public void moveZeroes(int[] nums) {
if (nums == null) return;
int j = 0;
for (int i = 0; i < nums.length; i++) {
if (nums[i] != 0) {
int tmp = nums[i];
nums[i] = nums[j];
nums[j++] = tmp;//j++所到的位置还是零
}
}
}
}
力扣HOT100 - 11. 盛最多水的容器
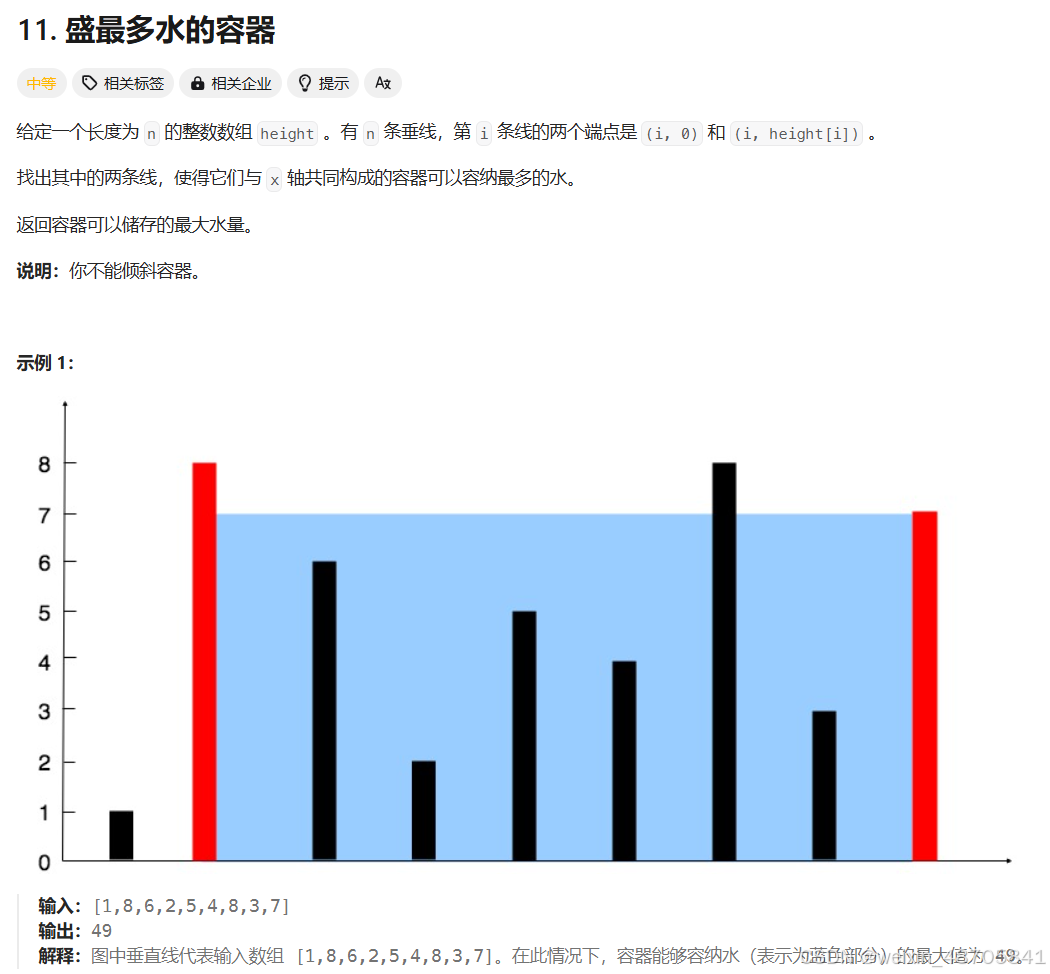
解析
class Solution {
public int maxArea(int[] height) {
int i = 0, j = height.length - 1, res = 0;
while(i < j) {
res = height[i] < height[j] ?
Math.max(res, (j - i) * height[i++]):
Math.max(res, (j - i) * height[j--]);
}
return res;
}
}
易错点:Math.max(res , (j - i) * height[i++])和Math.max(res , height[i++] * (j - i) )结果不同
这两个表达式的结果不同,是因为 i++ 的自增操作时机影响了 (j - i) 的计算结果。具体差异如下:
表达式 1:Math.max(res, (j - i) * height[i++])
-
执行顺序:
- 先计算
(j - i)(此时i未自增)。 - 再计算
height[i](此时i仍未自增)。 - 最后进行
i++(自增发生在整个表达式计算完成后)。
- 先计算
-
等效代码:
int old_i = i; // 保存当前i的值 int width = j - old_i; // 宽度计算使用旧的i int h = height[old_i]; // 高度使用旧的i i = old_i + 1; // i自增 res = Math.max(res, width * h);
表达式 2:Math.max(res, height[i++] * (j - i))
-
执行顺序:
- 先计算
height[i](此时i未自增)。 - 然后执行
i++(自增立即发生,影响后续的(j - i))。 - 最后计算
(j - i)(此时i已经自增,宽度比预期少1)。
- 先计算
-
等效代码:
int old_i = i; // 保存当前i的值 int h = height[old_i]; // 高度使用旧的i i = old_i + 1; // i自增(立即生效) int width = j - i; // 宽度计算使用新的i(比预期少1) res = Math.max(res, h * width);
关键区别
| 表达式 | (j - i) 的计算时机 | height[i] 的索引 | 实际效果 |
|---|---|---|---|
(j - i) * height[i++] | 在 i++ 之前 | 原 i | 宽度正确,高度正确 |
height[i++] * (j - i) | 在 i++ 之后 | 原 i | 高度正确,宽度少1 |
示例说明
假设 i = 2, j = 5, height = [1, 3, 2, 4]:
-
表达式 1:
(j - i)→5 - 2 = 3height[i]→height[2] = 2- 结果:
3 * 2 = 6(正确) - 执行后
i = 3。
-
表达式 2:
height[i]→height[2] = 2i++→i变为3(j - i)→5 - 3 = 2- 结果:
2 * 2 = 4(宽度少1,错误) - 执行后
i = 3。
如何避免问题?
- 分离自增操作:
int h = height[i]; i++; res = Math.max(res, (j - i + 1) * h); // 注意宽度补偿 - 使用
i+1显式计算:res = Math.max(res, (j - (i + 1)) * height[i]); i++;
总结
- 运算符优先级和求值顺序:
i++的副作用会影响同一表达式中其他部分的计算。 - 防御性编程:在复杂表达式中,避免混用自增操作和依赖变量值的计算。
这种差异常见于双指针或滑动窗口算法中(如盛水容器问题)。务必确保宽度和高度的计算基于正确的索引!