【C++ SIMD】第4篇:条件分支与掩码操作(Windows/VS2022版)——以AVX为例
一、SIMD编程中的条件分支问题
在传统标量代码中,我们习惯使用if-else进行条件判断:
void scalar_conditional(float* arr, int n) {
for (int i = 0; i < n; ++i) {
if (arr[i] > 0) {
arr[i] *= 2;
}
}
}
但在AVX向量化编程中,直接条件分支会引发两个关键问题:
- 分支预测失败惩罚:当条件模式不规则时,流水线频繁刷新
- SIMD并行性破坏:8个float元素(256位寄存器)可能同时包含满足和不满足条件的元素
二、AVX掩码操作原理
2.1 核心思想
通过向量比较生成掩码(mask),使用位操作混合计算结果:
寄存器A: [ 1.0, -2.0, 3.0, -4.0, 5.0, -6.0, 7.0, -8.0 ]
掩码 : [ 0xFF, 0x00, 0xFF, 0x00, 0xFF, 0x00, 0xFF, 0x00 ]
结果 = 原始值 * (掩码 ? 2.0 : 1.0)
2.3 AVX掩码操作指令集
| 指令类别 | 典型指令 | 操作描述 | 延迟周期 |
|---|---|---|---|
| 比较指令 | _mm256_cmp_ps | 生成全通道掩码 | 3 |
| 混合指令 | _mm256_blendv_ps | 根据掩码选择通道 | 2 |
| 位逻辑运算 | _mm256_and_ps/_mm256_or_ps | 掩码逻辑操作 | 1 |
| 条件加载 | _mm256_maskload_ps | 根据掩码加载内存 | 4 |
| 算术运算 | _mm256_mask_add_ps | 带掩码的加法(AVX-512) | N/A |
三、VS2022实现示例
3.1 向量化条件处理
#include <immintrin.h>
void avx_conditional(float* arr, int n) {
const __m256 zero = _mm256_setzero_ps();
const __m256 mul = _mm256_set1_ps(2.0f);
for (int i = 0; i < n; i += 8) {
__m256 data = _mm256_loadu_ps(arr + i);
// 生成比较掩码(arr[i] > 0)
__m256 mask = _mm256_cmp_ps(data, zero, _CMP_GT_OQ);
// 计算两种可能的结果
__m256 res_true = _mm256_mul_ps(data, mul);
__m256 res_false = data;
// 根据掩码混合结果
__m256 result = _mm256_blendv_ps(res_false, res_true, mask);
_mm256_storeu_ps(arr + i, result);
}
}
3.2 完整代码
#include <immintrin.h>
#include <chrono>
#include <iostream>
void scalar_conditional(float* arr, int n) {
for (int i = 0; i < n; ++i) {
if (arr[i] > 0) {
arr[i] *= 2;
}
}
}
void avx_conditional(float* arr, int n) {
const __m256 zero = _mm256_setzero_ps();
const __m256 mul = _mm256_set1_ps(2.0f);
for (int i = 0; i < n; i += 8) {
__m256 data = _mm256_loadu_ps(arr + i);
// 生成比较掩码(arr[i] > 0)
__m256 mask = _mm256_cmp_ps(data, zero, _CMP_GT_OQ);
// 计算两种可能的结果
__m256 res_true = _mm256_mul_ps(data, mul);
__m256 res_false = data;
// 根据掩码混合结果
__m256 result = _mm256_blendv_ps(res_false, res_true, mask);
_mm256_storeu_ps(arr + i, result);
}
}
void benchmark() {
const int SIZE = 10000000;
float* data = new float[SIZE];
// 初始化随机数据
for (int i = 0; i < SIZE; ++i) {
data[i] = (i % 2) ? i * 0.1f : -i * 0.1f;
}
auto t1 = std::chrono::high_resolution_clock::now();
scalar_conditional(data, SIZE);
auto t2 = std::chrono::high_resolution_clock::now();
avx_conditional(data, SIZE);
auto t3 = std::chrono::high_resolution_clock::now();
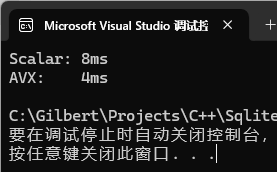
std::cout << "Scalar: "
<< std::chrono::duration_cast<std::chrono::milliseconds>(t2 - t1).count()
<< "ms\n";
std::cout << "AVX: "
<< std::chrono::duration_cast<std::chrono::milliseconds>(t3 - t2).count()
<< "ms\n";
delete[] data;
}
int main() {
benchmark();
return 0;
}
3.3 测试结果