Multi-class N-pair Loss论文理解
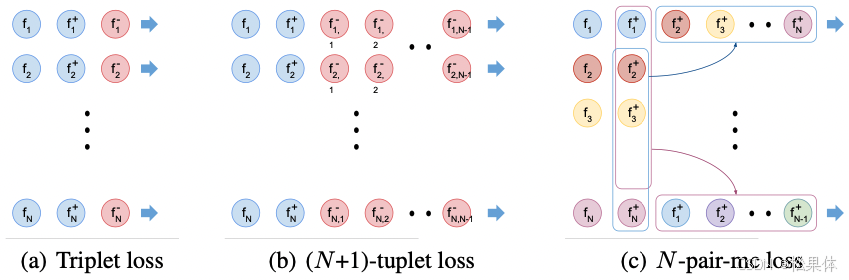
一、N-pair loss 对比 Triplet loss
对于N-pair loss来说,当N=2时,与triplet loss是很相似的。对anchor-positive pair,都只有一个negative sample。而且,N-pair loss(N=2时)为triplet loss的平滑近似Softplus函数(x趋向于负无穷时,y趋向于0;x趋向于正无穷时,y趋向于x)
基于简单假设,最小化N-pair loss(N=2时)等价于最小化triplet loss
二、N-pair loss的意义
对于一个理想的L-pair loss(每个negative class中只取一个sample)
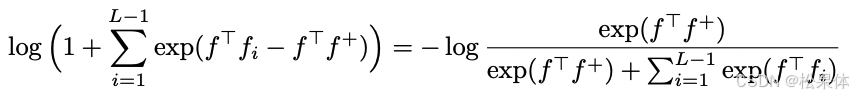 当把f看作feature vector,f+和fi看作weight vector,上述ln(y)函数中的y是一个multi-class logistic loss (softmax loss) 似然函数P(y=y+)。
当把f看作feature vector,f+和fi看作weight vector,上述ln(y)函数中的y是一个multi-class logistic loss (softmax loss) 似然函数P(y=y+)。
其中,当L的数值越大时,更近似似然函数softmax loss。
三、N-pair mc loss的计算优化
常规Triplet loss需要Nx3次pass
常规N-pair loss需要Nx(N+1)次pass
N-pair mc loss需要Nx2次pass
四、N-pair loss的Hard Mining方式:
加速收敛 & 提升分类效果
- 对于class数量较小的任务,hard mining必要性不大,因为大部分negative classes已经同时包含在N-pair loss内
- 对于class数量较大的任务,进行negative class mining,而非negative instance mining。在一个相对高效的方式下,greedily选择negative classes
具体方案: - 随机选择大批量的classes C,对于每个class,随机pass 1~2个examples生成embedding vectors
- Greedily添加一个,对于已选择的classes,破坏三元组约束的class,直到达到N个classes
- 选择好的classes中,每个随机取两个examples出来
五、N-pair loss的正则化
采用L2 norm,去清除embedding vector本身的direction影响。
不用normalization的原因:太过严格,使得|ft f+|的结果小于1,从而使得优化困难
六、实验结果
1.Fine-grained visual object recognition and verification:VRF(neg=71)的效果略优
2.Distance metric learning for unseen object recognition:Recall@k效果均略优
3.Face verification and identification: Rank-1效果大优,N越大,效果越好(N变小,效果劣化快)
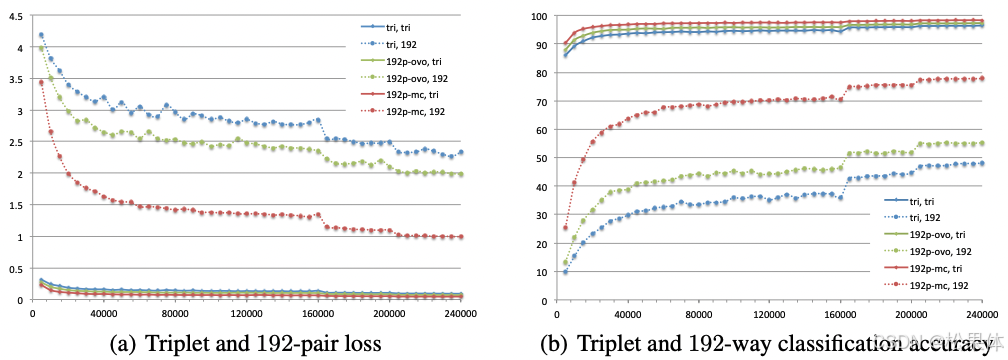
注:“,”左边为训练用的损失函数;“,”右边为评估用的损失(只评估,不作为back propagation的依据)