Python星球日记:第10天 - 模块与包
🌟引言:
上一篇:Python星球日记 - 第9天:高级函数
名人说:路漫漫其修远兮,吾将上下而求索。 —— 屈原《离骚》
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
目录
- 一、模块的概念与导入方式
- 1. 什么是模块?
- 2. 模块的导入方式
- 2.1 使用 `import` 导入整个模块
- 2.2 使用 `from ... import ...` 导入特定内容
- 2.3 使用别名简化导入
- 2.4 导入所有内容(谨慎使用)
- 二、标准库简介
- 1. `math` 模块 - 数学运算
- 2. `random` 模块 - 随机数生成
- 3. `datetime` 模块 - 日期和时间处理
- 三、创建自己的模块
- 1. 创建简单模块
- 2. 使用自定义模块
- 3. 模块搜索路径
- 4. 包(Package)的概念
- 四、实战练习:生成随机密码
- 2. 创建密码生成器模块
- 3. 使用密码生成器模块
- 五、模块与包的最佳实践
- 1. 模块命名规范
- 2. 模块内容组织
- 3. 导入方式选择
- 4. 包的组织结构
- 六、练习题(附参考解答)
- 练习1:创建并使用自定义模块
- 练习2:标准库模块应用
- 练习3:创建和使用包
- 七、总结
更多硬核知识,请关注我、订阅专栏《 Python星球日记》,内容持续更新中…
专栏介绍: Python星球日记专栏介绍(持续更新ing)
欢迎来到Python星球🪐的第10天!
今天我们将探索Python中模块与包的世界,这是Python代码组织和重用的核心机制。掌握模块与包的使用,是从Python初学者迈向进阶开发者的重要一步。
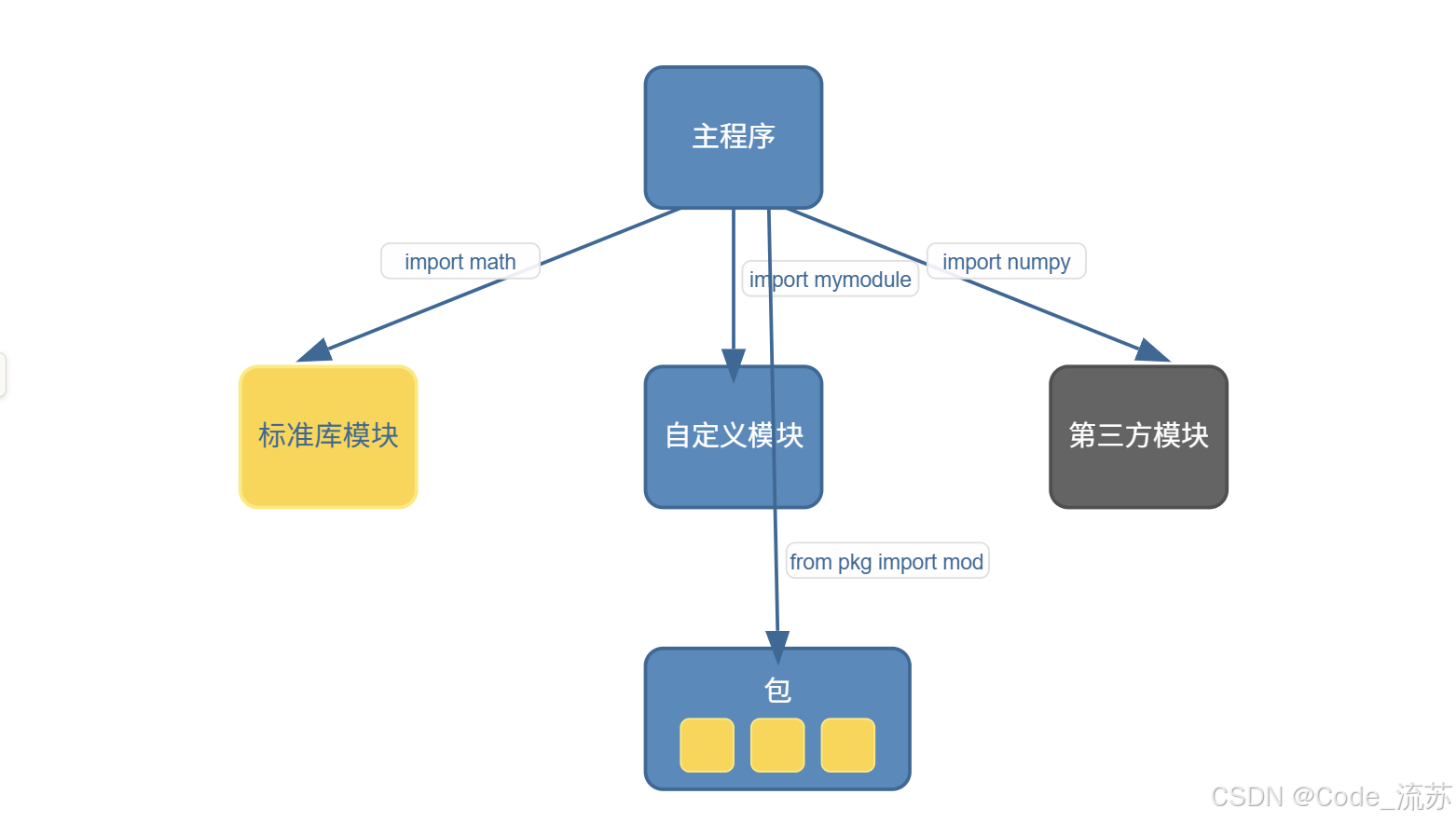
一、模块的概念与导入方式
当我们的Python程序逐渐变大,如何组织代码就变得至关重要。这时,模块(Module)这一概念就派上用场了。
1. 什么是模块?
模块简单来说就是一个Python文件(.py),包含了一组相关的函数、变量和类。使用模块有几个主要优点:
- 代码重用:一次编写,多次使用
- 命名空间管理:避免命名冲突
- 逻辑组织:相关功能放在一起
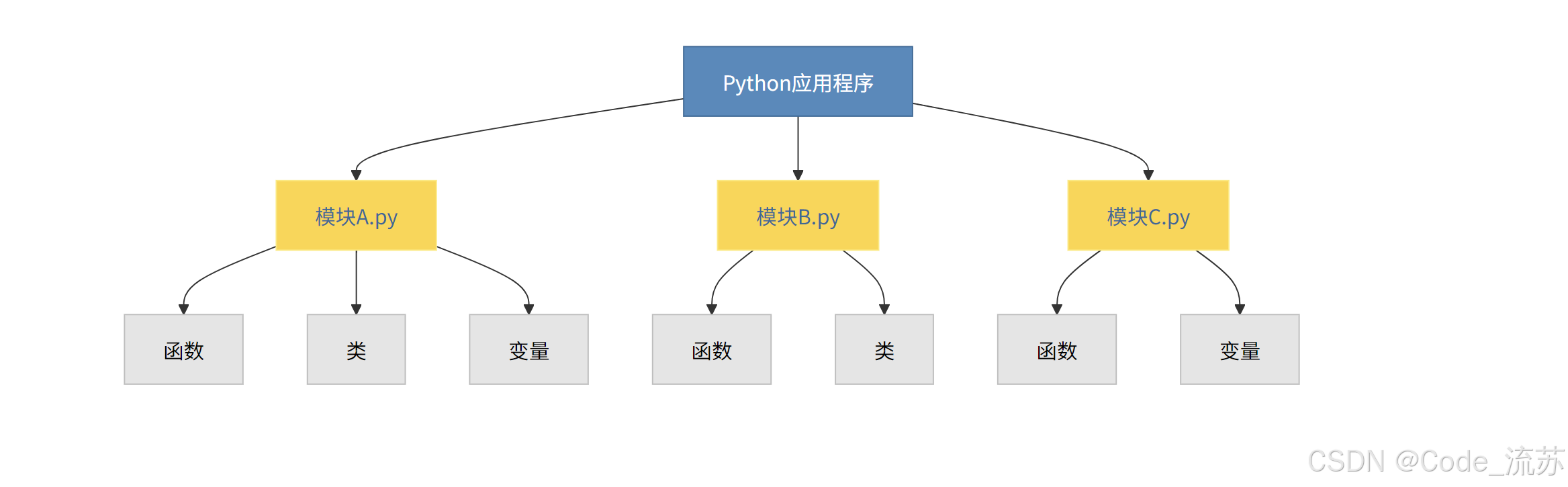
2. 模块的导入方式
Python提供了多种导入模块的方式,根据不同需求可以选择使用:
2.1 使用 import 导入整个模块
这是最基本的导入方式,导入后需要使用模块名作为前缀来访问其中的内容:
import math
# 使用math模块中的函数
radius = 5
area = math.pi * math.pow(radius, 2)
print(f"圆的面积是: {area}")
2.2 使用 from ... import ... 导入特定内容
当你只需要模块中的某些函数或变量时,可以这样导入:
from math import pi, sqrt
# 直接使用导入的函数和变量
radius = 5
area = pi * radius ** 2
print(f"圆的面积是: {area}")
print(f"5的平方根是: {sqrt(5)}")
2.3 使用别名简化导入
对于名称较长的模块,可以使用别名简化代码:
import matplotlib.pyplot as plt
import numpy as np
# 使用简化的别名
x = np.linspace(0, 10, 100)
y = np.sin(x)
plt.plot(x, y)
2.4 导入所有内容(谨慎使用)
可以导入模块中的所有内容,但这可能导致命名冲突,一般不推荐:
from math import * # 不推荐这种方式
radius = 5
area = pi * pow(radius, 2) # 直接使用,不需要模块名前缀
二、标准库简介
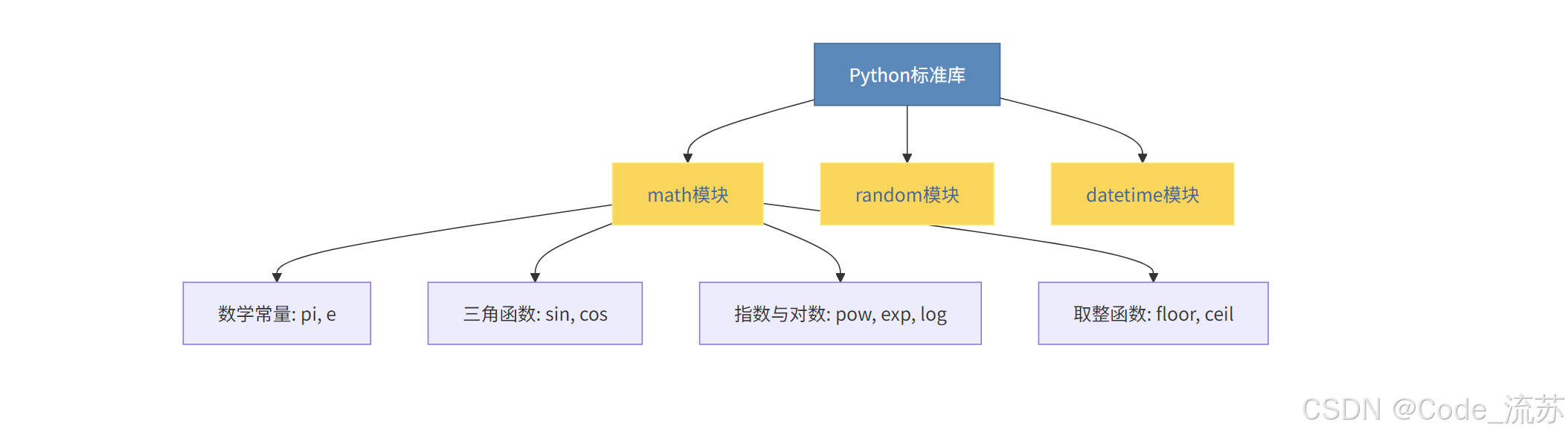
Python的强大之处在于其丰富的标准库,这些库随Python一起安装,无需额外下载。让我们看看几个常用的标准库:
1. math 模块 - 数学运算
math模块提供了各种数学函数和常量:
import math
# 数学常量
print(f"π值: {math.pi}")
print(f"自然对数的底e: {math.e}")
# 三角函数
print(f"sin(π/2): {math.sin(math.pi/2)}")
# 指数和对数
print(f"2的8次方: {math.pow(2, 8)}")
print(f"e的1次方: {math.exp(1)}")
print(f"log(100)以10为底: {math.log10(100)}")
# 取整函数
print(f"向上取整4.3: {math.ceil(4.3)}")
print(f"向下取整4.7: {math.floor(4.7)}")
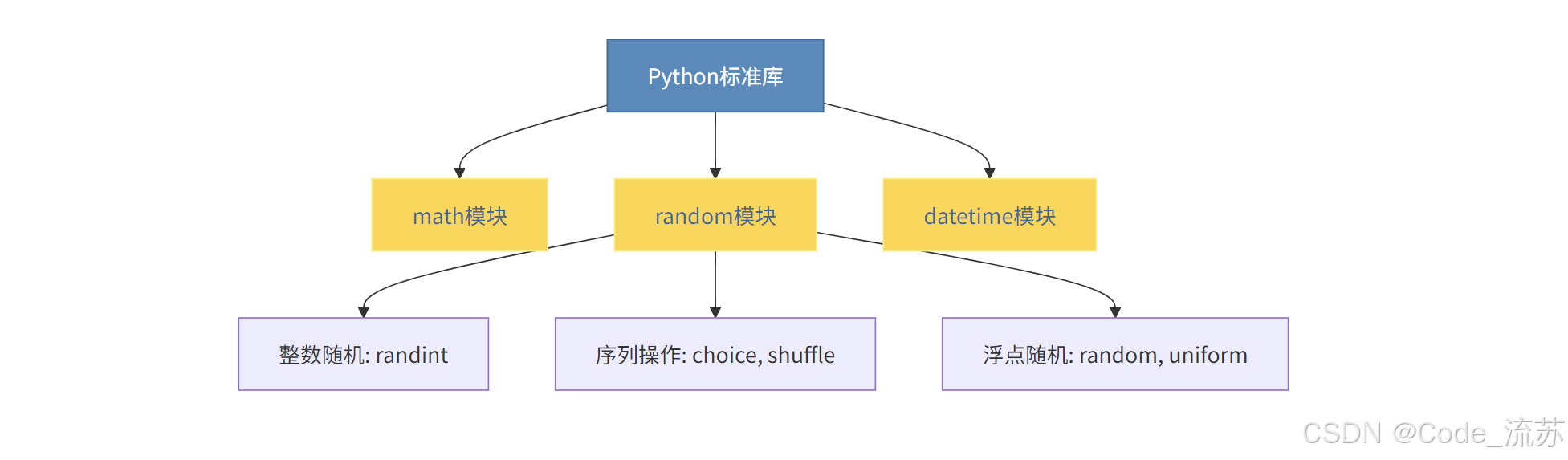
2. random 模块 - 随机数生成
random模块用于生成伪随机数,在游戏、模拟和测试中非常有用:
import random
# 生成随机整数
print(f"1-10之间的随机整数: {random.randint(1, 10)}")
# 从列表中随机选择
fruits = ["苹果", "香蕉", "橙子", "葡萄"]
print(f"随机选择一个水果: {random.choice(fruits)}")
# 打乱列表顺序
numbers = [1, 2, 3, 4, 5]
random.shuffle(numbers)
print(f"打乱后的列表: {numbers}")
# 生成随机浮点数
print(f"0-1之间的随机浮点数: {random.random()}")
print(f"5-10之间的随机浮点数: {random.uniform(5, 10)}")
3. datetime 模块 - 日期和时间处理
datetime模块提供了处理日期和时间的类和函数:
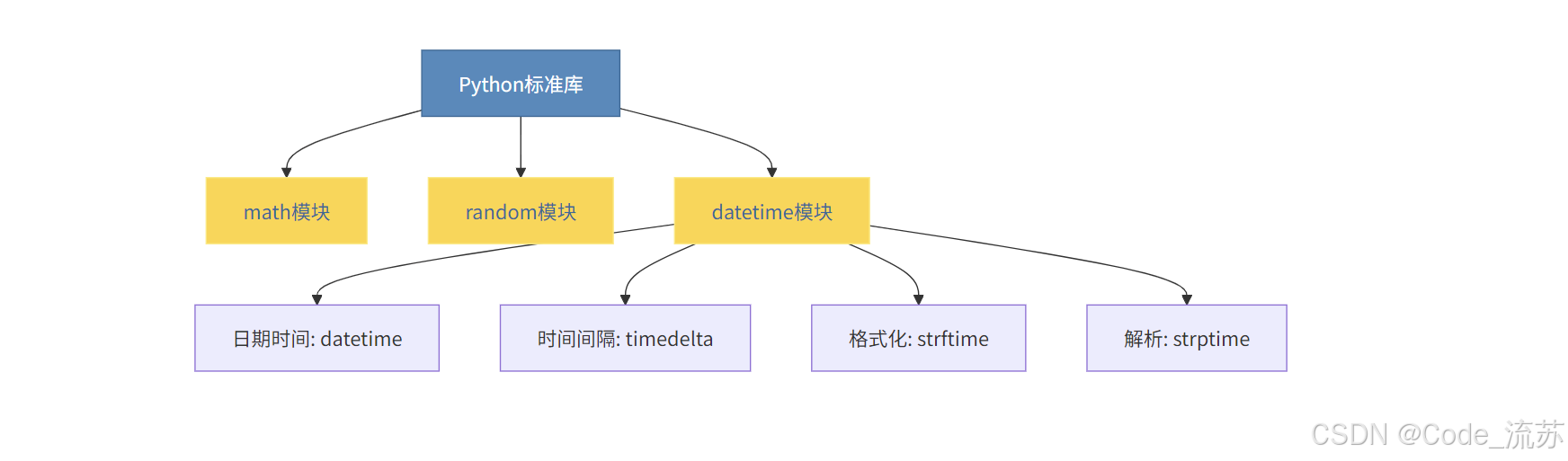
from datetime import datetime, timedelta
# 获取当前日期和时间
now = datetime.now()
print(f"当前日期和时间: {now}")
print(f"当前年份: {now.year}")
print(f"当前月份: {now.month}")
print(f"当前日: {now.day}")
# 格式化日期
formatted_date = now.strftime("%Y年%m月%d日 %H:%M:%S")
print(f"格式化后的日期: {formatted_date}")
# 日期计算
tomorrow = now + timedelta(days=1)
print(f"明天是: {tomorrow.strftime('%Y年%m月%d日')}")
# 解析字符串为日期
date_string = "2023-12-31"
parsed_date = datetime.strptime(date_string, "%Y-%m-%d")
print(f"解析后的日期: {parsed_date}")
三、创建自己的模块
掌握了如何使用现有模块后,让我们学习如何创建自己的模块,这将大大提高代码的可维护性和重用性。
1. 创建简单模块
创建模块非常简单 - 只需编写一个普通的Python文件,然后保存为.py文件即可。例如,创建一个名为calculator.py的文件:
# 文件名: calculator.py
# 定义一些简单的数学函数
def add(a, b):
"""返回两个数的和"""
return a + b
def subtract(a, b):
"""返回两个数的差"""
return a - b
def multiply(a, b):
"""返回两个数的积"""
return a * b
def divide(a, b):
"""返回两个数的商"""
if b == 0:
raise ValueError("除数不能为零")
return a / b
# 定义一个常量
PI = 3.14159
# 定义一个类
class Calculator:
"""一个简单的计算器类"""
def __init__(self):
self.result = 0
def add(self, value):
self.result += value
return self.result
2. 使用自定义模块
创建好模块后,就可以像使用标准库一样导入和使用它:
# 导入整个模块
import calculator
# 使用模块中的函数
print(calculator.add(5, 3)) # 输出: 8
print(calculator.multiply(4, 6)) # 输出: 24
# 使用模块中的常量
radius = 5
area = calculator.PI * radius ** 2
print(f"圆的面积: {area}")
# 使用模块中的类
calc = calculator.Calculator()
calc.add(10)
calc.add(5)
print(f"计算器结果: {calc.result}") # 输出: 15
也可以选择性地导入:
# 只导入需要的函数和常量
from calculator import add, subtract, PI
print(add(10, 5)) # 输出: 15
print(subtract(10, 5)) # 输出: 5
print(f"PI值: {PI}") # 输出: PI值: 3.14159
3. 模块搜索路径
Python在导入模块时会按照一定的顺序搜索模块:
- 当前目录
- 环境变量
PYTHONPATH中的目录 - Python标准安装目录
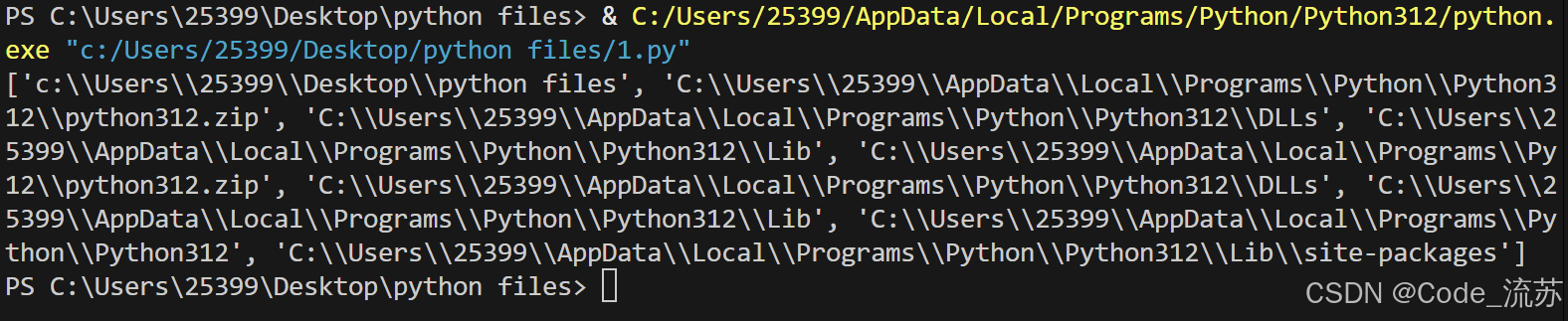
可以通过sys.path查看搜索路径:
import sys
print(sys.path)
4. 包(Package)的概念
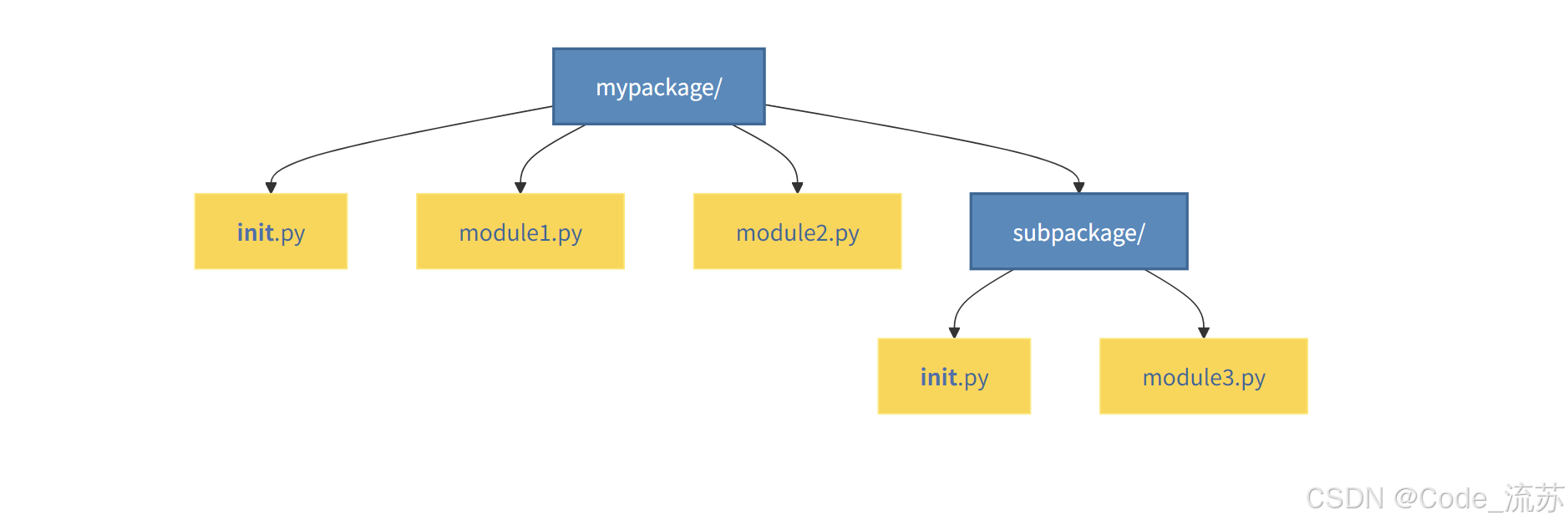
当模块变得更多时,我们可以使用包来组织它们。包本质上是一个包含多个模块和一个特殊文件__init__.py的目录。
假设我们有以下目录结构:
mypackage/
__init__.py
module1.py
module2.py
subpackage/
__init__.py
module3.py
使用包中的模块:
# 导入包中的模块
import mypackage.module1
from mypackage import module2
from mypackage.subpackage import module3
# 使用包中的功能
mypackage.module1.function1()
module2.function2()
module3.function3()
结构如下:
四、实战练习:生成随机密码
现在我们将运用所学知识,创建一个实用的随机密码生成器模块,并在主程序中使用它。
1.构思流程
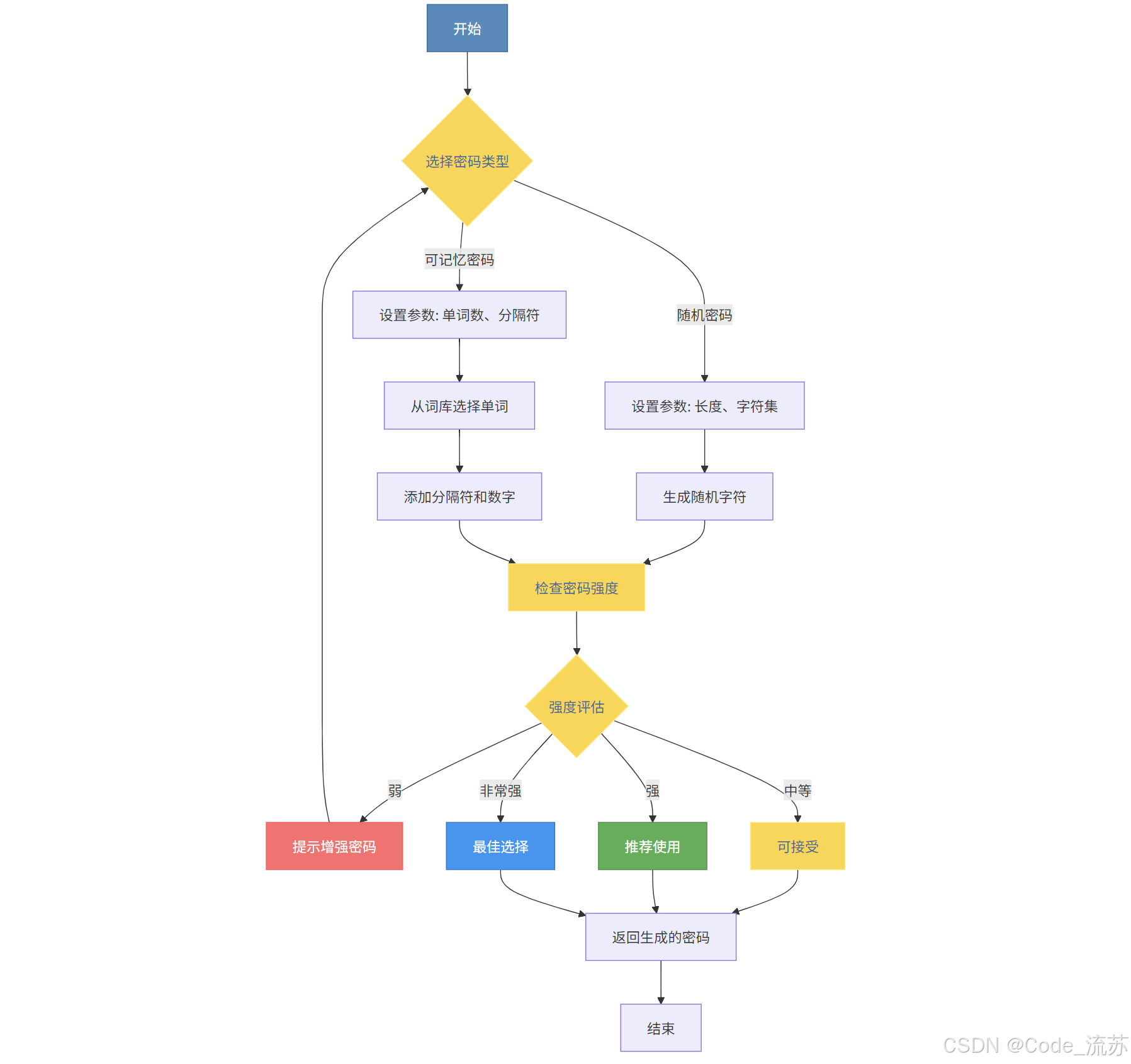
2. 创建密码生成器模块
首先,创建一个名为password_generator.py的文件:

# 文件名: password_generator.py
import random
import string
def generate_password(length=8, use_digits=True, use_special_chars=True):
"""
生成一个随机密码
参数:
length: 密码长度,默认为8
use_digits: 是否包含数字,默认为True
use_special_chars: 是否包含特殊字符,默认为True
返回:
生成的随机密码
"""
# 定义字符集
chars = string.ascii_letters # 包含所有大小写字母
if use_digits:
chars += string.digits # 添加数字
if use_special_chars:
chars += string.punctuation # 添加特殊字符
# 生成密码
password = ''.join(random.choice(chars) for _ in range(length))
return password
def generate_memorable_password(words=2, separator='-', digit=True):
"""
生成一个可记忆的密码(单词组合)
参数:
words: 使用的单词数量,默认为2
separator: 单词之间的分隔符,默认为'-'
digit: 是否在末尾添加数字,默认为True
返回:
生成的可记忆密码
"""
# 简单的单词列表(实际应用中可以使用更大的词库)
word_list = [
'apple', 'banana', 'orange', 'grape', 'lemon',
'python', 'java', 'ruby', 'swift', 'rust',
'happy', 'sunny', 'rainy', 'cloudy', 'windy',
'river', 'mountain', 'forest', 'desert', 'ocean'
]
# 随机选择单词
selected_words = [random.choice(word_list) for _ in range(words)]
# 将第一个字母大写使密码更安全
selected_words = [word.capitalize() for word in selected_words]
# 组合单词
password = separator.join(selected_words)
# 添加数字
if digit:
password += str(random.randint(10, 99))
return password
def check_password_strength(password):
"""
检查密码强度
参数:
password: 要检查的密码
返回:
密码强度评级: 'weak', 'medium', 'strong', 或 'very strong'
"""
score = 0
# 长度检查
if len(password) >= 8:
score += 1
if len(password) >= 12:
score += 1
# 复杂度检查
if any(c.islower() for c in password):
score += 1
if any(c.isupper() for c in password):
score += 1
if any(c.isdigit() for c in password):
score += 1
if any(c in string.punctuation for c in password):
score += 1
# 评级
if score < 3:
return 'weak'
elif score < 4:
return 'medium'
elif score < 6:
return 'strong'
else:
return 'very strong'
3. 使用密码生成器模块
现在创建一个主程序main.py来使用我们的密码生成器模块:

# 文件名: main.py
from password_generator import generate_password, generate_memorable_password, check_password_strength
def main():
print("===== 随机密码生成器 =====")
# 生成普通随机密码
password1 = generate_password(length=10)
strength1 = check_password_strength(password1)
print(f"随机密码: {password1} (强度: {strength1})")
# 生成仅包含字母和数字的密码
password2 = generate_password(length=12, use_special_chars=False)
strength2 = check_password_strength(password2)
print(f"无特殊字符密码: {password2} (强度: {strength2})")
# 生成超长强密码
password3 = generate_password(length=16, use_digits=True, use_special_chars=True)
strength3 = check_password_strength(password3)
print(f"超长强密码: {password3} (强度: {strength3})")
# 生成可记忆密码
password4 = generate_memorable_password(words=3, separator='.')
strength4 = check_password_strength(password4)
print(f"可记忆密码: {password4} (强度: {strength4})")
if __name__ == "__main__":
main()
运行main.py会产生类似下面的输出:
===== 随机密码生成器 =====
随机密码: F5#aB*q0$z (强度: very strong)
无特殊字符密码: AbC8dEfG5hI2 (强度: strong)
超长强密码: j7K*L@9m#F5pQ!r2 (强度: very strong)
可记忆密码: Mountain.Forest.Ocean27 (强度: strong)

五、模块与包的最佳实践
在实际开发中,合理使用模块与包可以显著提高代码质量。下面是一些最佳实践:
1. 模块命名规范
- 使用全小写字母
- 如果需要多个单词,用下划线连接(snake_case)
- 避免使用Python保留字 和 标准库模块名
- 名称应当简洁且表达明确意图
2. 模块内容组织
- 相关功能应放在同一模块中
- 每个模块应有明确的职责
- 使用文档字符串(docstring)说明模块用途
- 常量通常放在模块顶部
- 类和函数应有适当注释
3. 导入方式选择
根据不同情况选择合适的导入方式:
- 对于常用的标准库或第三方库,使用
import module - 对于频繁使用的特定函数,使用
from module import function - 当有命名冲突时,使用
import module as alias - 避免使用
from module import *,容易造成命名污染
4. 包的组织结构
大型项目应考虑使用包来组织代码:
- 相关模块放在同一包中
- 使用
__init__.py控制包的导出接口 - 考虑使用多级包结构组织复杂项目
- 提供清晰的包级文档
六、练习题(附参考解答)
下面是三个关于模块与包的练习题,帮助你巩固今天学到的知识:
练习1:创建并使用自定义模块
题目描述:
创建一个名为geometry.py的模块,其中包含计算不同几何图形(圆形、矩形、三角形)的面积和周长的函数。然后在主程序中导入并使用这个模块。
要求:
- 在
geometry.py中定义至少4个函数:计算圆的面积和周长,计算矩形的面积和周长 - 定义一个
PI常量 - 创建一个
main.py文件来测试你的模块
参考解答:
# geometry.py
"""几何图形计算模块 - 用于计算各种几何图形的面积和周长"""
# 常量定义
PI = 3.14159
# 圆形计算函数
def circle_area(radius):
"""计算圆的面积"""
return PI * radius ** 2
def circle_perimeter(radius):
"""计算圆的周长"""
return 2 * PI * radius
# 矩形计算函数
def rectangle_area(length, width):
"""计算矩形的面积"""
return length * width
def rectangle_perimeter(length, width):
"""计算矩形的周长"""
return 2 * (length + width)
# 三角形计算函数
def triangle_area(base, height):
"""计算三角形的面积"""
return 0.5 * base * height
def triangle_perimeter(a, b, c):
"""计算三角形的周长"""
return a + b + c
# main.py
"""几何模块测试程序"""
# 导入自定义模块
import geometry
def main():
# 测试圆形计算
radius = 5
print(f"圆形(半径 = {radius}):")
print(f"面积 = {geometry.circle_area(radius):.2f}")
print(f"周长 = {geometry.circle_perimeter(radius):.2f}")
# 测试矩形计算
length, width = 10, 6
print(f"\n矩形(长 = {length}, 宽 = {width}):")
print(f"面积 = {geometry.rectangle_area(length, width)}")
print(f"周长 = {geometry.rectangle_perimeter(length, width)}")
# 测试三角形计算
base, height = 8, 4
a, b, c = 5, 6, 7
print(f"\n三角形(底 = {base}, 高 = {height}, 三边 = {a}, {b}, {c}):")
print(f"面积 = {geometry.triangle_area(base, height)}")
print(f"周长 = {geometry.triangle_perimeter(a, b, c)}")
if __name__ == "__main__":
main()
运行结果:
圆形(半径 = 5):
面积 = 78.54
周长 = 31.42
矩形(长 = 10, 宽 = 6):
面积 = 60
周长 = 32
三角形(底 = 8, 高 = 4, 三边 = 5, 6, 7):
面积 = 16.0
周长 = 18
练习2:标准库模块应用
题目描述:
创建一个数据分析工具,使用Python标准库中的random、statistics和datetime模块,生成随机数据并进行简单的统计分析,同时记录分析的日期时间。
要求:
- 生成100个1到1000之间的随机整数
- 计算这些数据的均值、中位数、标准差
- 记录分析的日期和时间
- 将结果保存到文件中
参考解答:
"""数据分析工具 - 生成随机数据并进行统计分析"""
import random
import statistics
from datetime import datetime
def generate_data(count=100, min_value=1, max_value=1000):
"""生成指定数量和范围的随机整数"""
return [random.randint(min_value, max_value) for _ in range(count)]
def analyze_data(data):
"""对数据进行统计分析"""
results = {
"count": len(data),
"mean": statistics.mean(data),
"median": statistics.median(data),
"std_dev": statistics.stdev(data),
"min": min(data),
"max": max(data),
"timestamp": datetime.now().strftime("%Y-%m-%d %H:%M:%S")
}
return results
def save_results(results, filename="analysis_results.txt"):
"""将分析结果保存到文件"""
with open(filename, "w") as file:
file.write(f"数据分析结果\n")
file.write(f"分析时间: {results['timestamp']}\n")
file.write(f"数据量: {results['count']}\n")
file.write(f"最小值: {results['min']}\n")
file.write(f"最大值: {results['max']}\n")
file.write(f"均值: {results['mean']:.2f}\n")
file.write(f"中位数: {results['median']:.2f}\n")
file.write(f"标准差: {results['std_dev']:.2f}\n")
def main():
# 生成随机数据
data = generate_data()
# 分析数据
results = analyze_data(data)
# 打印结果
print(f"数据分析结果 (分析时间: {results['timestamp']})")
print(f"数据量: {results['count']}")
print(f"数值范围: {results['min']} - {results['max']}")
print(f"均值: {results['mean']:.2f}")
print(f"中位数: {results['median']:.2f}")
print(f"标准差: {results['std_dev']:.2f}")
# 保存结果
save_results(results)
print(f"\n结果已保存到 analysis_results.txt")
if __name__ == "__main__":
main()
运行结果示例:
数据分析结果 (分析时间: 2023-12-01 15:30:45)
数据量: 100
数值范围: 12 - 991
均值: 502.76
中位数: 507.50
标准差: 289.34
结果已保存到 analysis_results.txt
练习3:创建和使用包
题目描述:
创建一个名为texttools的包,用于文本处理,包含多个模块来处理不同类型的文本操作(统计、转换、搜索等)。然后创建一个应用程序使用这个包来分析一段文本。
要求:
- 创建包目录结构,包含
__init__.py - 至少创建3个模块:
counter.py(文本统计),converter.py(文本转换),finder.py(文本搜索) - 在主程序中演示如何使用这个包
参考解答:
首先,创建以下目录结构:
project/
│
├── texttools/
│ ├── __init__.py
│ ├── counter.py
│ ├── converter.py
│ └── finder.py
│
└── text_analyzer.py
然后实现各个文件:
# texttools/__init__.py
"""
texttools 包 - 文本处理工具集
提供文本统计、转换和搜索等功能
"""
# 导出主要功能,使它们可以直接从包导入
from .counter import count_words, count_chars, count_sentences
from .converter import to_uppercase, to_lowercase, capitalize_sentences
from .finder import find_all, contains_word, find_and_replace
# 包的版本信息
__version__ = '0.1.0'
# texttools/counter.py
"""文本统计模块 - 提供文本计数功能"""
import re
def count_words(text):
"""计算文本中的单词数量"""
words = text.split()
return len(words)
def count_chars(text, include_spaces=True):
"""计算文本中的字符数量"""
if include_spaces:
return len(text)
else:
return len(text.replace(" ", ""))
def count_sentences(text):
"""计算文本中的句子数量"""
# 简单方法:按照句号、问号、感叹号划分
sentences = re.split(r'[.!?]+', text)
# 过滤掉空字符串
sentences = [s for s in sentences if s.strip()]
return len(sentences)
# texttools/converter.py
"""文本转换模块 - 提供文本格式转换功能"""
import re
def to_uppercase(text):
"""将文本转换为大写"""
return text.upper()
def to_lowercase(text):
"""将文本转换为小写"""
return text.lower()
def capitalize_sentences(text):
"""将每个句子的首字母大写"""
# 分割句子
sentences = re.split(r'([.!?]+)', text)
result = ""
# 处理每个句子
for i in range(0, len(sentences)-1, 2):
if sentences[i].strip():
# 首字母大写,其余小写
capitalized = sentences[i].strip().capitalize()
result += capitalized
if i+1 < len(sentences):
result += sentences[i+1]
# 处理最后一个句子(如果有)
if len(sentences) % 2 == 1 and sentences[-1].strip():
result += sentences[-1].strip().capitalize()
return result
# texttools/finder.py
"""文本搜索模块 - 提供文本查找和替换功能"""
import re
def find_all(text, pattern, case_sensitive=True):
"""查找文本中所有匹配模式的位置"""
if not case_sensitive:
text = text.lower()
pattern = pattern.lower()
positions = []
start = 0
while True:
pos = text.find(pattern, start)
if pos == -1:
break
positions.append(pos)
start = pos + 1
return positions
def contains_word(text, word, case_sensitive=True):
"""检查文本是否包含指定单词"""
if not case_sensitive:
text = text.lower()
word = word.lower()
# 使用正则表达式匹配整个单词
pattern = r'\b' + re.escape(word) + r'\b'
match = re.search(pattern, text)
return match is not None
def find_and_replace(text, find_text, replace_text, case_sensitive=True):
"""在文本中查找并替换指定内容"""
if case_sensitive:
return text.replace(find_text, replace_text)
else:
# 不区分大小写的替换
pattern = re.compile(re.escape(find_text), re.IGNORECASE)
return pattern.sub(replace_text, text)
# text_analyzer.py
"""文本分析应用程序 - 使用texttools包来分析文本"""
# 导入texttools包
from texttools import count_words, count_sentences, count_chars
from texttools import to_uppercase, to_lowercase, capitalize_sentences
from texttools import find_all, contains_word, find_and_replace
def analyze_text(text):
"""对文本进行全面分析"""
print("===== 文本分析结果 =====")
# 文本基本信息
print("\n----- 基本统计 -----")
print(f"单词数: {count_words(text)}")
print(f"字符数 (含空格): {count_chars(text)}")
print(f"字符数 (不含空格): {count_chars(text, include_spaces=False)}")
print(f"句子数: {count_sentences(text)}")
# 文本转换示例
print("\n----- 文本转换 -----")
print(f"大写版本: {to_uppercase(text[:50])}...")
print(f"小写版本: {to_lowercase(text[:50])}...")
print(f"句首大写: {capitalize_sentences(text[:50])}...")
# 文本搜索示例
search_word = "Python"
print(f"\n----- 搜索词 '{search_word}' -----")
positions = find_all(text, search_word)
print(f"出现次数: {len(positions)}")
print(f"出现位置: {positions}")
print(f"包含单词 '{search_word}': {contains_word(text, search_word)}")
# 文本替换示例
old_word = "Python"
new_word = "Python编程语言"
print(f"\n----- 文本替换 -----")
modified_text = find_and_replace(text, old_word, new_word)
print(f"替换 '{old_word}' 为 '{new_word}':")
print(f"修改后的前100个字符: {modified_text[:100]}...")
def main():
# 示例文本
sample_text = """Python是一种广泛使用的解释型、高级编程语言。
Python的设计哲学强调代码的可读性和简洁的语法。
Python支持多种编程范式,包括面向对象、命令式、函数式和过程式编程。
Python拥有一个庞大而全面的标准库,这使得Python解决各种问题时非常便捷。
Python的简单易学是其最大的特点之一,许多人认为Python是初学者最好的编程语言。"""
# 分析文本
analyze_text(sample_text)
if __name__ == "__main__":
main()
运行结果示例:
===== 文本分析结果 =====
----- 基本统计 -----
单词数: 89
字符数 (含空格): 359
字符数 (不含空格): 270
句子数: 5
----- 文本转换 -----
大写版本: PYTHON是一种广泛使用的解释型、高级编程语言。...
小写版本: python是一种广泛使用的解释型、高级编程语言。...
句首大写: Python是一种广泛使用的解释型、高级编程语言。...
----- 搜索词 'Python' -----
出现次数: 5
出现位置: [0, 137, 177, 214, 298]
包含单词 'Python': True
----- 文本替换 -----
替换 'Python' 为 'Python编程语言':
修改后的前100个字符: Python编程语言是一种广泛使用的解释型、高级编程语言。
Python编程语言的设计哲学强调代码的可读性和简洁的语法。
Python编程...
以上三个练习分别覆盖了模块创建与使用、标准库模块应用、以及包的创建与使用,通过完成这些练习,你将能够更好地掌握Python模块与包的概念和实践技巧。
七、总结
在这一天的学习中,我们探索了Python中模块与包的世界:
- 了解了模块的概念及其在代码组织中的重要性
- 掌握了多种模块的导入方式:
import、from ... import、别名导入等 - 学习了常用标准库:
math、random、datetime等 - 创建了自己的模块并学习了如何组织包
- 通过实战练习,开发了一个实用的随机密码生成器
模块和包是Python代码组织的基础,掌握它们将帮助你更好地组织和管理代码,提高开发效率和代码质量。在未来的项目中,请记住模块化设计的原则,让你的代码更加清晰、可维护和可重用!
下一天预告:我们将探索Python中的文件操作,学习如何读写各种文件,让你的程序能够与外部世界交互!
如果你喜欢这篇文章,请点赞、收藏并关注我的专栏Python星球日记!每天都会有新的Python学习内容等着你!
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
如果你对今天的内容有任何问题,或者想分享你的学习心得,欢迎在评论区留言讨论!