【计网】TCP协议的拥塞控制与流量控制
拥塞控制与流量控制的区别
流量控制
流量控制主要是控制端到端(发送端和接收端)之间的数据传输量,是局部的机制。
- 目的:防止发送方发送数据过快导致接收方来不及处理
- 实现方式:通过滑动窗口机制,接收方通知发送方自己的接收窗口大小
- 工作层次:传输层(TCP协议)
- 控制范围:仅限于直接通信的两个端点
- 反馈机制:接收方通过TCP首部的窗口大小字段告知发送方
- 动态特性:接收窗口大小可以动态变化,甚至可以通告为0(零窗口)暂停发送
- 实现位置:在TCP头部保留16位的窗口字段,最大窗口大小为65535字节
滑动窗口机制详解
- 接收窗口:表示接收方还能接收多少字节的数据
- 发送窗口:表示发送方还能发送多少字节的数据
- 窗口左移:当接收方确认接收到数据后,窗口向右滑动
- 窗口大小:可动态调整,根据接收方的处理能力和网络状况变化
零窗口与窗口探测
- 当接收方缓冲区满时,会通告窗口大小为0
- 发送方收到零窗口通知后停止发送数据
- 发送方会定期发送窗口探测报文,询问接收方窗口是否变大
- 防止死锁:如果窗口更新的ACK丢失,可能导致双方永久等待
拥塞控制
拥塞控制是控制整个网络中每台主机的数据发送量,降低路由器的负载,是全局的机制。
- 目的:防止过多的数据注入网络中,避免网络拥塞崩溃
- 实现方式:通过拥塞窗口调整发送数据量
- 工作层次:传输层,但考虑了网络层的状况
- 控制范围:整个网络
- 反馈机制:通过丢包、超时、RTT变化等网络状况间接反馈
- 自适应特性:没有显式反馈,TCP必须自己推断网络状况
- 实现复杂度:由于网络状况难以准确测量,算法较为复杂
拥塞控制的重要性
- 网络资源有限:带宽、缓冲区、处理能力等
- 避免拥塞崩溃:过度拥塞会导致网络吞吐量急剧下降
- 公平性:确保各TCP连接能公平分享网络资源
- 效率:保持较高的网络资源利用率
二者关系
发送窗口 = min(接收窗口,拥塞窗口)
- 接收窗口由对方告知,取决于接收方的处理能力(流量控制)
- 拥塞窗口由发送方根据网络状况自行调整(拥塞控制)
相互作用
- 流量控制关注端到端通信效率,拥塞控制关注整个网络效率
- 两种控制机制相互独立又相互影响
- 实际发送量受到两者的共同约束,取较小值
- 一个侧重接收方利益,一个侧重网络整体利益
拥塞控制详解
拥塞判断机制
如何判断网络拥塞?
-
不拥塞:发出的报文都被顺利地收到ACK确认
- 表明网络通畅,传输正常
- RTT(往返时间)保持稳定
- 吞吐量高,丢包率低
-
严重拥塞:发出的报文未能按时收到ACK,引发超时重传
- 可能是由于网络中报文丢失或延迟过高
- 通常意味着路由器缓存溢出,丢弃了数据包
- 典型特征是RTO(重传超时)计时器到期
-
轻微拥塞:收到冗余的ACK,引发快重传
- 表明部分报文可能乱序或丢失
- 网络开始出现问题,但尚未完全拥塞
- 特征是收到多个重复的ACK(通常是3个)
拥塞的原因与表现
- 缓冲区溢出:路由器队列满导致丢包
- 高延迟:队列积压导致传输延迟增加
- 吞吐量下降:网络有效带宽利用率降低
- 丢包增加:拥塞严重时丢包率上升
- RTT抖动:网络延迟不稳定,波动增大
拥塞应对策略
拥塞了怎么办?
-
迅速减少发送量,避免加重拥塞
-
严重拥塞时(超时重传):
- 将拥塞窗口cwnd重置为1MSS(最大报文段大小)
- 进入慢开始阶段
- 设置慢开始门限ssthresh为当前cwnd的一半
- 指数回退RTO计时器,增加重传间隔
-
轻微拥塞时(快重传):
- 将拥塞窗口cwnd减半
- 设置慢开始门限ssthresh为当前cwnd的一半
- 直接进入拥塞避免阶段
- 不重置RTO计时器
拥塞处理的原则
- 保守性:宁可牺牲一些带宽利用率,也不要加剧网络拥塞
- 响应性:快速对网络状况变化做出反应
- 公平性:确保多个TCP连接能公平分享带宽
- 稳定性:避免发送速率剧烈波动
- 可扩展性:算法在各种网络规模下都能良好工作
拥塞控制的算法
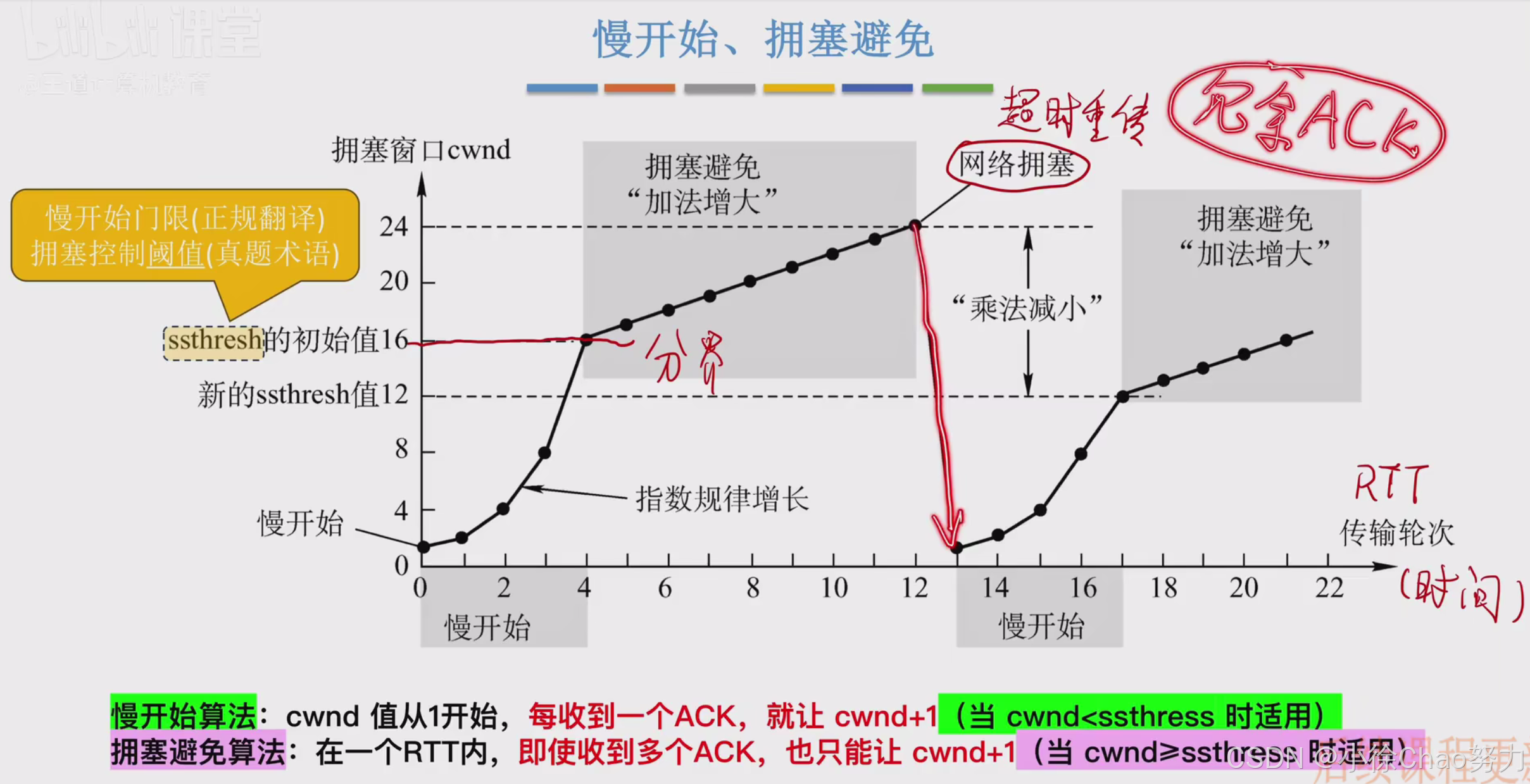
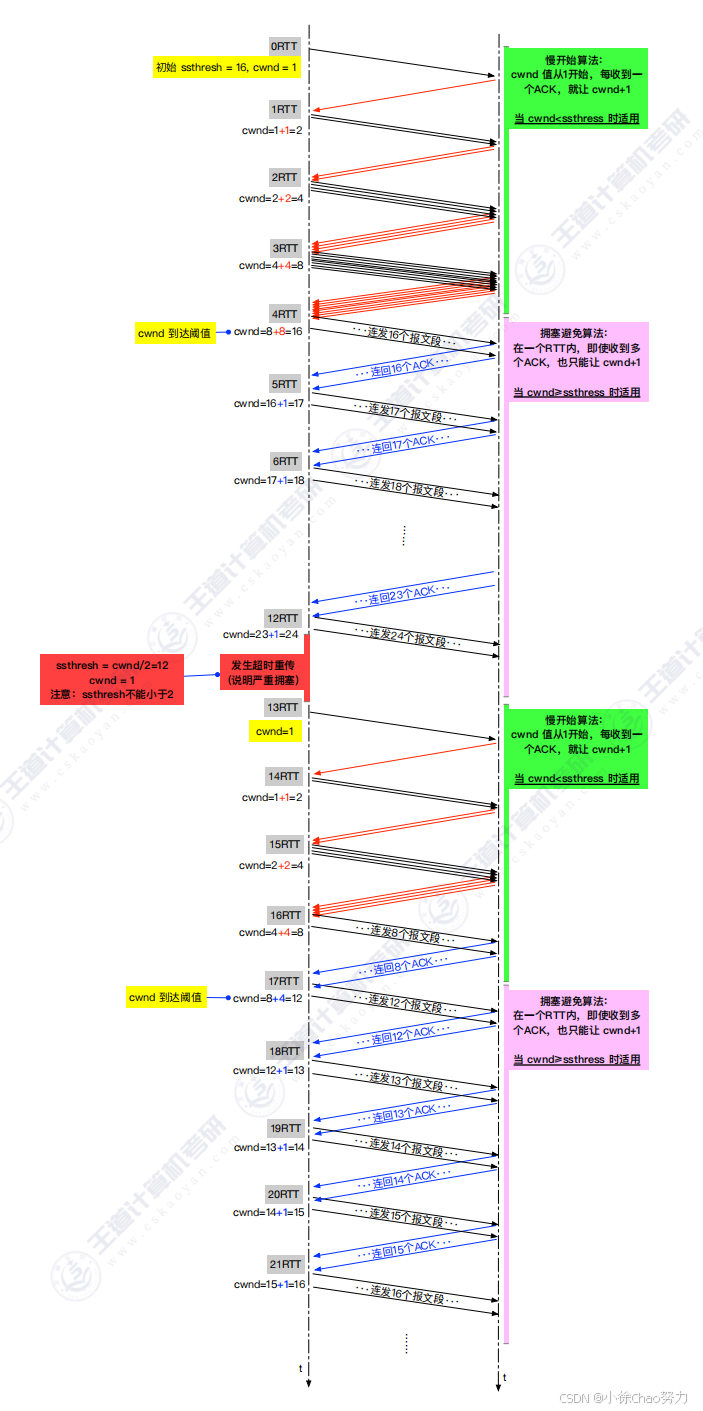
1. 慢开始算法(Slow Start)
- 原理:TCP连接初始或发生严重拥塞后,cwnd从1MSS开始,每收到一个ACK就将cwnd加1
- 特点:
- cwnd按指数级增长(每个RTT翻倍)
- 增长速度快,但起点低
- 直到cwnd达到慢开始门限ssthresh
- "慢"是相对于早期TCP的无控制发送而言
- 实现方式:
初始状态:cwnd = 1MSS 每收到一个ACK:cwnd = cwnd + 1MSS - 结束条件:
- cwnd ≥ ssthresh时,进入拥塞避免阶段
- 发生超时,重置cwnd为1MSS,ssthresh减半
- 接收到3个重复ACK,进入快恢复
2. 拥塞避免算法(Congestion Avoidance)
- 原理:在网络不拥塞时,谨慎地增加拥塞窗口
- 特点:
- cwnd按线性增长(每个RTT增加1MSS)
- 增长速度慢,避免突然增大流量导致拥塞
- 更平滑的网络利用率
- 渐进式探测可用带宽
- 实现方式:
实际效果:每个RTT内cwnd增加约1MSS每收到一个ACK:cwnd = cwnd + MSS*(MSS/cwnd) - 数学解释:
- 假设cwnd=4MSS,收到1个ACK时增加MSS*(MSS/cwnd)=MSS/4
- 一个窗口的所有报文确认后,增量累计为4*(MSS/4)=MSS
- 结束条件:
- 发生超时,进入慢开始阶段
- 收到三个重复ACK,进入快恢复阶段
3. 快重传机制(Fast Retransmit)
- 原理:不等超时计时器到期,提前重传丢失的报文段
- 触发条件:接收方收到失序的报文段后立即发送重复ACK,发送方收到3个重复ACK
- 特点:
- 减少等待时间,提高网络效率
- 对网络轻微拥塞有快速响应能力
- 不像超时重传那样大幅降低发送窗口
- 能区分报文丢失和乱序
- 执行过程:
- 接收方发现失序的报文段,立即发送已收到的最大序号的ACK
- 发送方收到3个重复的ACK,立即重传可能丢失的数据
- 不必等待超时计时器到期
- 为什么是3个重复ACK:
- 1-2个重复ACK可能只是网络乱序
- 3个以上重复ACK几乎肯定是报文丢失
- 平衡响应速度与误判概率
4. 快恢复算法(Fast Recovery)
- 原理:配合快重传使用,在检测到轻微拥塞时不直接回到慢开始状态
- 特点:
- 避免了网络利用率的大幅下降
- 适用于轻微拥塞的情况
- 认为网络仍能传输数据,不需要从1MSS重新开始
- 更高效地利用已有带宽
- 实现方式:
ssthresh = cwnd/2 cwnd = ssthresh + 3*MSS # 初始设置为新ssthresh加3个MSS 每收到一个重复ACK:cwnd = cwnd + MSS # 进一步膨胀窗口 收到新数据的ACK后:cwnd = ssthresh # 回到正常拥塞避免状态 - 执行过程:
- 收到3个重复ACK时,将ssthresh设为cwnd的一半
- 重传丢失的报文段
- 将cwnd设为ssthresh加3MSS(对应3个重复ACK)
- 每收到一个重复ACK,cwnd增加1MSS
- 当收到新数据的ACK时,将cwnd设为ssthresh
- 直接进入拥塞避免阶段,而不是慢开始
新型拥塞控制算法
1. TCP Vegas
- 基于延迟的拥塞控制,不依赖丢包来检测拥塞
- 通过监测RTT变化来预测网络拥塞
- 在拥塞发生前就开始减缓发送速率
- 更平滑的传输,减少了不必要的重传
- 能够在高带宽高延迟网络中保持较高吞吐量
2. TCP BIC 和 CUBIC
- 专为高带宽长延迟网络优化
- CUBIC是Linux系统默认的TCP拥塞控制算法
- 使用三次函数曲线调整拥塞窗口
- 在恢复期快速接近最优点,然后稳定探测
- 避免了传统TCP在高带宽网络中的低效率问题
3. BBR (Bottleneck Bandwidth and RTT)
- Google开发的新一代拥塞控制算法
- 直接建模网络的瓶颈带宽和RTT
- 不依赖丢包作为拥塞信号
- 能在高丢包率网络中保持良好吞吐量
- 关注网络带宽最大化和延迟最小化的平衡
TCP拥塞控制的完整过程
-
连接建立:
- 初始化cwnd = 1MSS,ssthresh通常设为较大值(如65535字节)
- 进入慢开始阶段
- 设置初始RTO(重传超时)
-
慢开始阶段:
- cwnd指数增长(每RTT翻倍)
- 发送方每收到一个ACK,cwnd += 1MSS
- 直到cwnd ≥ ssthresh
-
拥塞避免阶段:
- cwnd线性增长(每RTT增加1MSS)
- 发送方每收到一个ACK,cwnd += MSS*(MSS/cwnd)
- 直到发生超时或收到3个重复ACK
-
拥塞发生处理:
- 如果是超时事件(严重拥塞):
- ssthresh = cwnd/2
- cwnd = 1MSS
- 重新进入慢开始阶段
- 重传丢失的数据并应用指数回退
- 如果是3个重复ACK(轻微拥塞):
- ssthresh = cwnd/2
- 重传疑似丢失的数据包
- cwnd = ssthresh + 3MSS(初始快恢复窗口)
- 进入快恢复阶段
- 如果是超时事件(严重拥塞):
-
快恢复阶段:
- 每收到一个重复ACK:cwnd += 1MSS
- 当收到新数据的ACK时:cwnd = ssthresh
- 进入拥塞避免阶段
TCP拥塞控制的高级特性
1. 初始窗口大小演进
- 早期RFC2001:初始cwnd = 1MSS
- RFC2414:初始cwnd = min(4MSS, max(2MSS, 4380 bytes))
- 现代实现(RFC6928):初始cwnd = 10MSS
- 更大的初始窗口减少了慢开始阶段的延迟,加快小文件传输
2. 显式拥塞通知(ECN)
- 传统TCP拥塞控制把丢包视为拥塞信号
- ECN允许路由器直接标记数据包来指示拥塞
- 工作流程:
- 路由器队列即将溢出时不丢弃报文,而是标记ECN位
- 接收方收到标记的报文后,在ACK中设置ECE位
- 发送方收到ECE标记的ACK后,主动降低发送速率
- 优点:
- 减少不必要的重传和超时
- 降低延迟和抖动
- 更早检测到拥塞
3. 适应性RTT估计
- 精确的RTT估计对拥塞控制至关重要
- 自适应RTT算法(Jacobson算法):
SRTT = (1-α)*SRTT + α*R // 平滑RTT,α通常为1/8 RTTVAR = (1-β)*RTTVAR + β*|SRTT-R| // RTT变化,β通常为1/4 RTO = SRTT + 4*RTTVAR // 设置重传超时时间 - RTO下限通常为1秒,重传后进行指数回退
4. SACK (Selective Acknowledgment)
- 传统TCP只能确认连续的数据
- SACK允许接收方明确指出已收到的非连续数据块
- 好处:
- 更高效的重传,只重传实际丢失的数据
- 减少不必要的重传带宽浪费
- 更快恢复网络拥塞
5. 带宽时延乘积问题
- 高速网络环境下的挑战:大带宽×高延迟=大容量
- 传统TCP在高BDP (Bandwidth-Delay Product) 环境下表现不佳:
- 慢开始增长太慢,难以充分利用带宽
- 线性增长阶段需要很长时间达到最优窗口
- 乘性减少导致严重的带宽利用率下降
- 解决方案:
- 更大的初始窗口
- 更加激进的窗口增长算法
- 更小的乘性减少因子
各种版本的TCP拥塞控制对比
TCP Tahoe (最早版本)
- 包含慢开始、拥塞避免和快重传
- 任何丢包都导致回到慢开始
- 存在问题:过于保守,遇到轻微拥塞也会大幅降低速率
TCP Reno (常用版本)
- 加入了快恢复机制
- 区分对待超时和三重重复ACK
- 改进:快重传后不会回到慢开始,而是进入快恢复
- 仍存在的问题:多个包丢失时表现不佳
TCP NewReno
- 改进了Reno在多包丢失时的表现
- 引入"部分确认"概念,在快恢复期间可处理多个丢包
- 直到所有丢失的数据都被确认才退出快恢复
- 缺点:仍然不能处理太多乱序数据
TCP SACK
- 使用选择性确认明确指出哪些数据已收到
- 极大改进了多包丢失时的恢复速度
- 发送方可以精确知道哪些数据需要重传
- 缺点:增加了协议头部开销
TCP CUBIC (现代高性能版本)
- 为高带宽网络优化
- 使用三次函数的窗口增长算法
- 特点:
- 增长函数不依赖于RTT,各连接更公平
- 快速接近上次达到的最大窗口大小
- 窗口增长在最大点附近变缓
- 避免过度拥塞和窗口震荡
拥塞控制的实际应用考量
1. 移动网络中的拥塞控制
- 特点:
- 带宽变化剧烈
- 连接断续
- 高延迟波动
- 优化方向:
- 快速适应带宽变化
- 区分信号丢失和拥塞丢失
- 更积极的窗口增长
- 更保守的窗口减少
2. 数据中心网络拥塞控制
- 特点:
- 低延迟(微秒级)
- 高带宽(10Gbps以上)
- 短连接多
- 优化方向:
- DCTCP (Data Center TCP)
- 使用ECN早期标记拥塞
- 更小的队列和更快的响应速度
- 针对小文件传输优化启动过程
3. 公平性与网络中立性
- 拥塞控制算法影响不同流量的公平性
- 长连接vs短连接不平等问题
- 不同TCP变种之间的带宽竞争
- 网络中立性原则:
- 不同应用应获得公平对待
- 拥塞控制不应偏向特定类型流量
4. TCP与其他协议的交互
- TCP与UDP竞争
- TCP与基于应用层的拥塞控制(如QUIC)
- 多路径TCP (MPTCP):
- 同时使用多个网络路径
- 需要特殊的拥塞控制机制
- 适应路径间性能差异
总结与展望
传统TCP拥塞控制的局限性
- 依赖丢包作为拥塞信号,反应滞后
- 高带宽延迟网络中表现不佳
- 固定参数难以适应多变的网络环境
- 流量模型简单,不适应现代应用复杂的流量模式
未来发展趋势
-
基于学习的拥塞控制:
- 使用机器学习和神经网络模型
- 自适应网络环境变化
- 预测性拥塞控制
-
跨层优化:
- 结合应用层需求与网络层信息
- 更细粒度的资源分配
-
软件定义网络中的拥塞控制:
- 集中控制与决策
- 全局优化网络性能
- 根据流量类型定制控制策略
-
多路径传输优化:
- 同时利用多条网络路径
- 智能负载均衡
- 更高效利用异构网络资源