【DeepSeek原理学习1】MOE
MOE
混合专家模型,解决的问题是确定计算量的情况下如何训练更大的模型?即参数增加但是计算量不增加。
方法:将FFN层替换成MoE层,每个MoE层有一些专家网络和一个路由网络组成。
专家层:每一个专家就是一个前馈的网络。
路由层:根据输入token选择激活哪些专家。
负载均衡问题:避免token总是偏向选择某一个专家。
DeepSeek的MoE(专家混合模型)旨在通过智能分配计算资源来提升深度学习模型的效率和泛化能力。其核心作用是利用动态路由机制,智能地将输入数据分配到最匹配的专家网络,以实现更为精确的特征提取和任务处理。
其主要优化在于以下三方面:
专家划分:不同于传统 MoE 中专家都是独立的设计,DeepSeekMoE 引入了共享专家的概念。共享专家负责处理所有 token 的通用特征,而路由专家则根据 token 的具体特征进行动态分配。这种分工不仅减少了模型的冗余、提高了计算效率,还使得模型能够更好地处理不同领域的任务。稀疏激活机制:与传统的稠密模型不同,DeepSeekMoE 采用了稀疏激活机制,即每个 token 只会激活少数专家。这种机制不仅降低了计算开销,还使得模型能够更灵活地处理不同类型的输入,特别是在需要高度专业化知识的场景中。
负载均衡:为避免路由崩溃,即对专家的选择有明显的倾向,使用动态偏置来代替损失函数来动态负载均衡。动态偏置调整:在训练过程中,DeepSeekMoE 会监控每个专家的负载情况。如果某个专家的负载过高,系统会自动降低其偏置项,从而减少该专家的激活频率。为关注局部级的负载均衡(即针对单个 batch 或单个节点的专家分配情况)。
路由机制:路由机制的实现依赖于一个由参数化学习趋动的路由器。在代码中门控使用swiglu实现的。
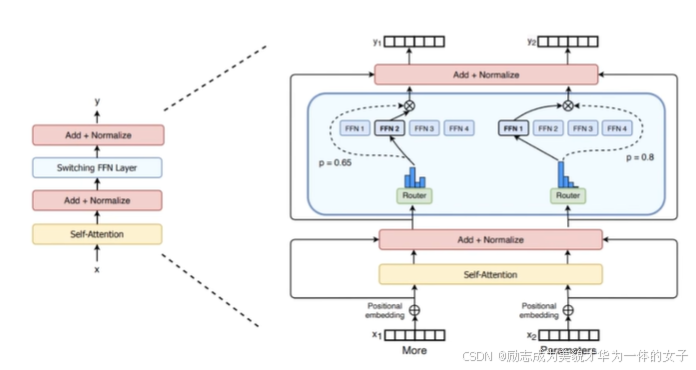
①. 门控网络/路由机制的完整工作流程:
首先计算路由概率p(如0.65和0.8),用于选择FFN专家
然后生成一个门控值(图中用虚线表示)
这个门控值会与选中的FFN专家的输出相乘
②. 门控值的作用:
用于调节FFN专家输出的强度
可以看作是对专家输出的一个加权因子
通过门控机制可以实现更平滑的输出
③. 门控网络/路由机制整体流程:
最终输出 = 选中的FFN专家的输出 × 门控值(虚线表示的值)
这种双重机制(路由概率 + 门控值)使得模型既能够选择合适的专家,又能够灵活地控制专家输出的影响程度。
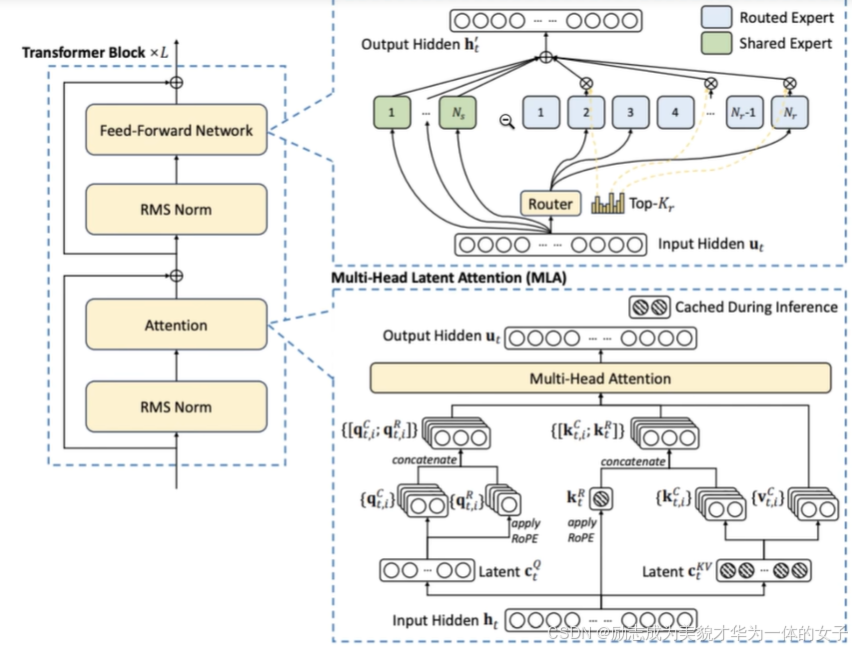
DeepSeek结构图


具体实现过程中,会将备选专家进行分组,然后选出前几组,然后再从前几组中选出指定激活专家的数量。这样做的主要目的也是为了更好的负载均衡同时增加随机性。

代码:基础函数(topk、scatter_、unsquence、gather、bincount、where) M
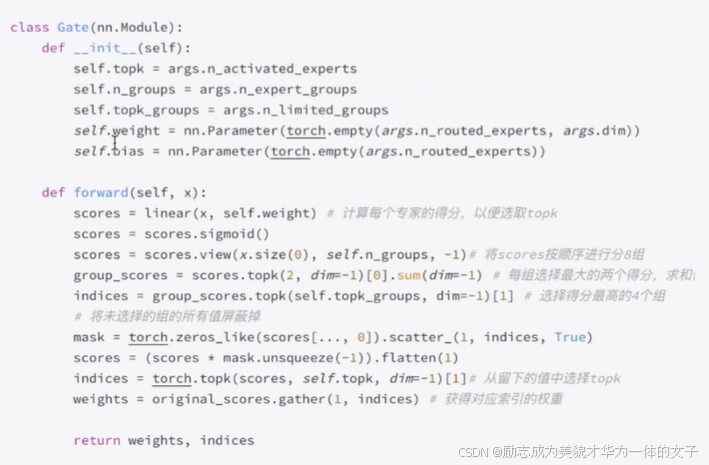
参考说明
全网最细!DeepSeekMoE:从算法原理到代码实现_哔哩哔哩_bilibili