第六章:框架实战:构建集成向量与图谱的 RAG 应用
引言
在前几章中,我们深入探讨了检索增强生成(RAG)的核心概念、不同的检索策略以及生成器的协同作用。现在,我们将把这些理论知识付诸实践。本章将重点介绍如何使用主流的 RAG 开发框架——LangChain 和 LlamaIndex,构建能够集成向量检索和图谱检索的实际应用程序。通过具体的代码案例和详细的步骤说明,您将能够掌握使用这些框架搭建强大的 RAG 系统的能力,并了解如何调试和评估其性能。本章旨在强调动手实践的重要性,并展示如何利用多种检索方式来提升 RAG 应用的智能水平。
6.1 主流 RAG 开发框架对比与核心组件
在众多的 RAG 开发工具中,LangChain 和 LlamaIndex 无疑是最受欢迎且功能最为强大的两个框架。它们都提供了丰富的模块和工具,帮助开发者快速构建和部署 RAG 应用程序。然而,它们在设计理念、核心优势和适用场景上存在一些差异。
6.1.1 LangChain 概览
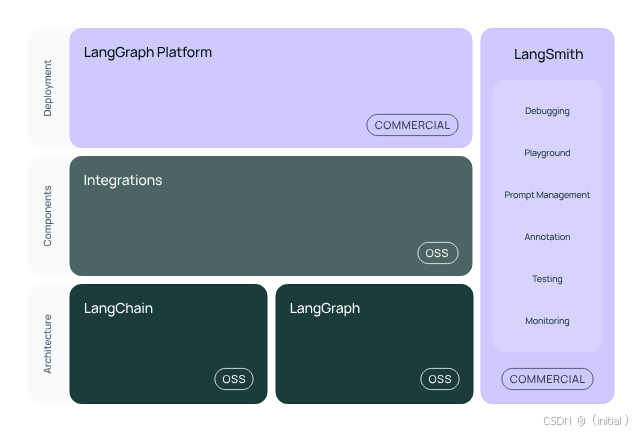
设计理念: LangChain 的核心理念是提供一个通用的框架,用于构建基于语言模型的各种应用。它强调灵活性和可组合性,允许开发者以“链”的方式将不同的组件连接起来,构建复杂的自然语言处理流程。
核心优势:
- 高度的灵活性和可定制性: LangChain 提供了大量的模块和集成,开发者可以根据自己的需求自由组合和定制。
- 广泛的 LLM 和工具集成: LangChain 支持与各种主流的 LLM 提供商(如 OpenAI、Cohere、Hugging Face)以及各种实用工具(如搜索引擎、数据库、API)进行集成。
- 强大的链式操作能力: 通过 Chains 和 Runnables,开发者可以轻松地构建复杂的处理流程,例如先进行检索,然后对检索结果进行总结,再根据总结生成最终答案。
- 活跃的社区和完善的文档: LangChain 拥有庞大的开发者社区和详细的文档,方便开发者学习和解决问题。
主要模块: - LLMs: 提供与各种语言模型交互的接口。
- Prompts: 用于管理和构建发送给 LLM 的提示。
- Chains: 将不同的组件(如 LLM、检索器、工具)连接起来形成工作流。
- Data Loaders: 用于从各种来源加载数据。
- Text Splitters: 用于将长文本分割成更小的块。
- Vector Stores: 用于存储和检索向量嵌入。
- Retrievers: 定义了从知识源检索相关文档的接口。
- Output Parsers: 用于解析 LLM 的输出。
6.1.2 LlamaIndex 概览
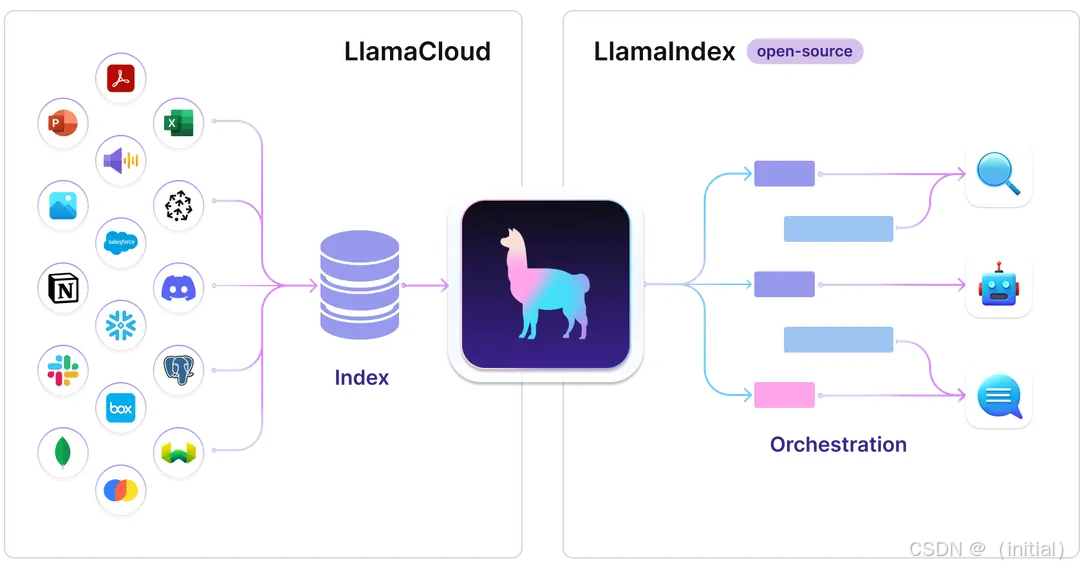
设计理念: LlamaIndex 的核心目标是使构建基于私有数据的 LLM 应用变得简单高效。它专注于数据索引和检索,提供了强大的数据连接器和索引结构,特别擅长处理各种类型的文档和数据源。
核心优势:
- 强大的数据连接和索引能力: LlamaIndex 提供了丰富的数据连接器,可以轻松地从各种来源(如本地文件、网站、数据库、云存储)加载数据,并支持多种索引类型(如向量索引、树索引、关键词索引、知识图谱索引)。
- 对知识图谱的良好支持: LlamaIndex 内置了对知识图谱的索引和检索功能,方便构建基于图谱的 RAG 应用。
- 易于上手和使用: LlamaIndex 的 API 设计简洁友好,使得开发者可以快速搭建基本的 RAG 应用。
- 专注于检索增强: LlamaIndex 的设计目标更侧重于解决检索增强问题,提供了许多针对性的工具和技术。
主要模块: - Data Loaders: 用于加载各种格式的数据。
- Document/Node: LlamaIndex 中的基本数据单元,可以是文档或文档的片段(节点)。
- Indices: 用于组织和索引数据的各种数据结构(如 VectorStoreIndex, KnowledgeGraphIndex)。
- Query Engines: 用于在索引上执行查询并返回答案。
- Retrievers: 定义了从索引中检索相关节点的方法。
- Node Parsers: 用于将文档解析成节点。
- Embeddings: 提供与各种 Embedding 模型集成的接口。
- LLM: 提供与各种语言模型交互的接口。
6.1.3 框架对比与选型

LangChain 和 LlamaIndex 都是优秀的 RAG 开发框架,选择哪个取决于具体的应用场景和开发者的偏好:
- 灵活性 vs. 专注于数据: LangChain 更加通用和灵活,适用于构建各种基于语言模型的应用,而 LlamaIndex 则更专注于数据索引和检索,尤其适合处理大量的文档数据。
- 图谱支持: LlamaIndex 对知识图谱的支持更为内置和便捷,提供了专门的索引和查询引擎。LangChain 虽然也可以集成图数据库,但可能需要更多的自定义开发。
- 易用性: LlamaIndex 在快速搭建基本 RAG 应用方面通常更容易上手,而 LangChain 的灵活性也意味着可能需要更多的配置和理解。
- 社区生态: LangChain 拥有更庞大和活跃的社区,提供了更多的集成和示例。
在实际应用中,有时也会将 LangChain 和 LlamaIndex 结合使用,例如使用 LlamaIndex 进行数据加载和索引,然后使用 LangChain 构建更复杂的处理链。
6.1.4 RAG 核心组件详解
无论是使用 LangChain 还是 LlamaIndex,构建 RAG 应用都离不开以下核心组件:
- 数据处理:
- Loaders (文档加载): 负责从各种数据源(如文件系统、Web 页面、数据库、API)加载原始数据。LangChain 和 LlamaIndex 都提供了丰富的数据加载器。选择合适的加载器取决于数据的来源和格式。值得注意的是,对于非文本数据,例如图片和音频,可能需要使用特定的加载器或预处理步骤,将其转化为可嵌入的表示。例如,可以使用图像特征提取模型(如 CLIP)或音频特征提取模型来获取其向量表示。
- Splitters (文本分割): 将加载的长文本分割成更小的、适合 Embedding 模型处理的文本块(chunks)。分割的策略(如按固定长度、按句子、按段落)以及块的大小和重叠度会影响检索效果。LangChain 和 LlamaIndex 都提供了多种文本分割器。
- 表示与存储:
- Embeddings (模型选择): 将文本块转化为低维向量表示,捕获其语义信息。选择合适的 Embedding 模型(如 OpenAI 的 text-embedding-ada-002、Hugging Face 的 Sentence Transformers)至关重要,它直接影响向量检索的质量。LangChain 和 LlamaIndex 都支持集成各种 Embedding 模型。对于非文本数据,可以使用专门的多模态 Embedding 模型。
- VectorStores (向量数据库): 用于存储和索引文本块的向量嵌入,并提供高效的相似度搜索功能。常见的向量数据库包括 Chroma、Pinecone、FAISS、Milvus 等。LangChain 和 LlamaIndex 都支持与这些向量数据库集成。
- Graph Databases (图数据库): 用于存储结构化的知识图谱数据,由节点(实体)和边(关系)组成。常见的图数据库包括 Neo4j、TigerGraph、Dgraph 等。LlamaIndex 对图数据库有较好的内置支持,而 LangChain 通常需要通过特定的集成或自定义实现。
- 检索:
- Retrievers (向量检索器, 图谱检索器, 混合检索器): 负责根据用户查询(通常也需要转化为 Embedding 向量)从向量数据库或图数据库中检索出最相关的文档或信息片段。
- 向量检索器: 基于向量相似度进行检索。
- 图谱检索器: 基于图查询语言(如 Cypher、SPARQL)或图算法进行检索。
- 混合检索器: 结合了向量检索和图谱检索的能力,可以根据查询的特点或通过特定的融合策略,利用两种检索方式的优势。LangChain 和 LlamaIndex 都提供了构建不同类型检索器的工具。
- Retrievers (向量检索器, 图谱检索器, 混合检索器): 负责根据用户查询(通常也需要转化为 Embedding 向量)从向量数据库或图数据库中检索出最相关的文档或信息片段。
- 生成与控制:
- LLMs (模型接口): 提供与各种大型语言模型进行交互的接口,用于生成最终的答案。LangChain 和 LlamaIndex 都支持主流的 LLM。
- Prompts (模板工程): 用于构建发送给 LLM 的提示,包括用户查询和检索到的上下文信息。精心设计的 Prompt 可以指导 LLM 生成更准确、更相关的答案。LangChain 和 LlamaIndex 都提供了 Prompt 模板管理的功能。
- Output Parsers (输出解析): 用于解析 LLM 的输出,将其转化为结构化的数据或特定的格式。LangChain 提供了更丰富的输出解析器。
- Chains/QueryEngines (流程编排): 用于将上述各个组件连接起来,形成一个完整的 RAG 工作流程。LangChain 中的 Chains 和 LlamaIndex 中的 Query Engines 都提供了这种流程编排的能力。
6.2 实战案例一:基于 LangChain 构建本地文档(向量)问答系统
本节将演示如何使用 LangChain 构建一个简单的 RAG 应用,该应用能够根据本地的文本文件回答用户提出的问题。
6.2.1 环境准备
首先,需要安装必要的 Python 包:
pip install langchain openai chromadb
确保您已经安装了 OpenAI 的 Python 库,并且拥有 OpenAI API 的密钥。您需要将 API 密钥配置为环境变量或者在代码中直接设置。
6.2.2 核心流程代码实现
以下是构建向量问答系统的核心代码流程:
import os
from langchain.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
# 设置 OpenAI API 密钥
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"
try:
# 1. 加载文档
loader = TextLoader("./your_document.txt") # 替换为您的文档路径
documents = loader.load()
# 2. 分割文本
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
# 3. 创建 Embedding 模型
embeddings = OpenAIEmbeddings()
# 4. 存储到向量数据库
db = Chroma.from_documents(texts, embeddings, persist_directory="./chroma_db")
db.persist()
# 5. 构建检索器
retriever = db.as_retriever(search_kwargs={"k": 3}) # 设置检索Top K个文档
# 6. 创建问答链
qa = RetrievalQA.from_chain_type(llm=OpenAI(),
chain_type="stuff",
retriever=retriever,
return_source_documents=True)
# 7. 提问
query = "请问文档中提到了什么关键信息?"
result = qa({"query": query})
print("问题:", query)
print("答案:", result["result"])
print("来源文档:", result["source_documents"])
except Exception as e:
print(f"发生错误: {e}")
代码解释:
- 加载文档: 使用 TextLoader 加载本地的文本文件。您可以根据实际的文件类型选择不同的加载器。
- 分割文本: 使用 CharacterTextSplitter 将加载的文档分割成大小为 1000 字符的文本块,没有重叠。
- 创建 Embedding 模型: 初始化 OpenAI 的 Embedding 模型,用于将文本块转化为向量。
- 存储到向量数据库: 使用 Chroma 向量数据库存储文本块的 Embedding 向量。persist_directory 参数指定了数据库的存储路径。
- 构建检索器: 从 Chroma 数据库创建一个检索器,设置 search_kwargs 指定每次检索返回最相关的 3 个文档。
- 创建问答链: 使用 RetrievalQA.from_chain_type 创建一个问答链。chain_type=“stuff” 表示将所有检索到的文档都放入 LLM 的 Prompt 中。return_source_documents=True 表示返回用于生成答案的源文档。
- 提问: 定义用户的问题,并将其传递给问答链的 run 方法。
- 错误处理: 使用
try-except块捕获可能发生的异常,例如 API 连接错误或文件读取错误。
6.2.3 运行与测试
将上述代码保存为一个 Python 文件(例如 langchain_qa.py),并将您的本地文本文件命名为 your_document.txt 并放在同一目录下。运行脚本后,您将看到问题的答案以及用于生成答案的源文档。您可以尝试不同的问题,观察系统的表现。
6.3 实战案例二:基于 LlamaIndex 集成图谱增强的 RAG (Graph RAG)
本节将演示如何使用 LlamaIndex 构建一个集成图谱增强的 RAG 应用。我们将连接到一个 Neo4j 图数据库,并使用 LlamaIndex 的 KnowledgeGraphIndex 和混合检索功能。
6.3.1 Graph RAG 概念
Graph RAG 指的是在 RAG 流程中利用知识图谱来增强检索效果。知识图谱以结构化的方式存储实体及其之间的关系,可以提供更丰富的上下文信息和进行关系推理,从而提高检索的准确性和相关性。
6.3.2 环境准备与图数据库连接
首先,确保您已经安装了 LlamaIndex 和 Neo4j 的驱动:
pip install llama-index neo4j
您需要一个正在运行的 Neo4j 数据库实例,并准备一些包含实体和关系的数据。您还需要配置 Neo4j 的连接信息。
准备 Neo4j 数据:
准备 Neo4j 数据的方式有很多种。您可以直接在 Neo4j 浏览器中使用 Cypher 语句创建节点和关系。例如:
CREATE (n:Person {name: "史蒂夫·乔布斯"})
CREATE (c:Company {name: "苹果公司"})
CREATE (n)-[:FOUNDED]->(c);
CREATE (c2:Company {name: "皮克斯"})
CREATE (n)-[:CO_FOUNDED]->(c2);
或者,您可以使用 CSV 文件批量导入数据。Neo4j 提供了 neo4j-admin import 工具和 LOAD CSV 命令来实现这一点。CSV 文件需要包含节点和关系的定义,包括属性和连接信息。更复杂的数据导入可以使用 APOC 库提供的函数。
从文本数据提取三元组:
如果您希望从文本数据中构建知识图谱,可以使用自然语言处理技术来提取实体和关系。这通常涉及以下步骤:
- 命名实体识别 (NER): 识别文本中的实体,例如人名、地名、组织机构等。
- 关系抽取 (RE): 识别实体之间的关系。
一些工具和库可以帮助完成这些任务,例如 spaCy、Stanford CoreNLP 和 Hugging Face Transformers。您还可以使用 LLM 本身来提取三元组。例如,您可以设计一个 Prompt,要求 LLM 从给定的文本中提取所有 (主体, 关系, 客体) 三元组。
为了更直观地展示如何从文本数据中提取三元组以构建知识图谱,以下是一个使用 spaCy 库进行简单实体识别和关系提取的示例代码片段:
import spacy
# 加载英文模型 (如果处理中文,请加载对应的中文模型)
nlp = spacy.load("en_core_web_sm")
def extract_triplets(text):
doc = nlp(text)
triplets = []
for token in doc:
# 寻找主体 (通常是名词或名词短语)
if token.dep_ in ["nsubj", "nsubjpass"]:
subject = token.text
# 寻找谓语 (通常是动词)
head = token.head
if head.pos_ == "VERB":
predicate = head.text
# 寻找宾语 (直接宾语或介词宾语)
for child in head.children:
if child.dep_ in ["dobj", "pobj"]:
obj = child.text
triplets.append((subject, predicate, obj))
return triplets
# 示例文本
text = "Steve Jobs founded Apple company and also co-founded Pixar."
triplets = extract_triplets(text)
print(triplets)
代码解释:
- 我们使用
spaCy加载了一个英文的语言模型。 extract_triplets函数接收一段文本作为输入。- 它遍历文本中的每个词语,寻找作为主语的名词性词语。
- 然后,它找到这些主语的谓语动词。
- 接着,它在谓语动词的子节点中寻找直接宾语或介词宾语作为客体。
- 最后,将提取到的 (主体, 谓语, 宾语) 三元组存储在列表中并返回。
请注意,这只是一个基础示例,实际应用中可能需要更复杂的规则或模型来准确地提取知识图谱中的信息。
6.3.3 使用 LlamaIndex 构建 Graph RAG
以下代码演示了如何使用 LlamaIndex 连接到 Neo4j 数据库并构建 KnowledgeGraphIndex:
import os
from llama_index import KnowledgeGraphIndex, SimpleDirectoryReader, LLMPredictor, ServiceContext
from llama_index.storage.storage_context import StorageContext
from llama_index.graph_stores import Neo4jGraphStore
from llama_index.llms import OpenAI
# 设置 OpenAI API 密钥
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"
# Neo4j 连接信息
NEO4J_URI = "bolt://localhost:7687"
NEO4J_USER = "neo4j"
NEO4J_PASSWORD = "your_neo4j_password" # 替换为您的密码
try:
# 定义 LLM
llm_predictor = LLMPredictor(llm=OpenAI(temperature=0, model_name="gpt-3.5-turbo"))
service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor)
# 设置图存储
graph_store = Neo4jGraphStore(
url=NEO4J_URI, username=NEO4J_USER, password=NEO4J_PASSWORD, database="neo4j"
)
storage_context = StorageContext.from_defaults(graph_store=graph_store)
# 从现有图存储构建索引 (如果图数据库中已有数据)
kg_index = KnowledgeGraphIndex.from_graph_store(
graph_store=graph_store,
storage_context=storage_context,
service_context=service_context,
max_triplets_per_chunk=10,
include_embeddings=True # 可选,如果需要对图谱中的节点进行向量检索
)
# 如果需要从文本数据构建图谱并索引
# documents = SimpleDirectoryReader("./data").load_data()
# kg_index = KnowledgeGraphIndex.from_documents(
# documents,
# max_triplets_per_chunk=10,
# include_embeddings=True,
# service_context=service_context,
# )
except Exception as e:
print(f"连接或构建图谱索引时发生错误: {e}")
代码解释:
- 导入必要的模块。
- 设置 OpenAI API 密钥和 Neo4j 连接信息。
- 定义 LLM 和服务上下文。
- 创建 Neo4jGraphStore 对象,用于连接到 Neo4j 数据库。
- 创建 StorageContext。
- 从现有的图存储构建 KnowledgeGraphIndex。 如果您的图数据库中已经有数据,可以使用这种方式。
- (可选)从文本数据构建图谱并索引。 如果您希望从文本数据中提取知识并构建图谱,可以使用这种方式。max_triplets_per_chunk 参数控制每个文本块提取的最大三元组数量。include_embeddings=True 表示为图谱中的节点生成 Embedding 向量,以便进行基于语义的图谱检索。
- 错误处理: 使用
try-except块捕获连接 Neo4j 或构建图谱索引时可能发生的错误。
6.3.4 构建混合检索查询引擎
以下代码演示了如何结合向量检索器和图谱检索器构建一个混合检索查询引擎:
from llama_index.retrievers import VectorIndexRetriever, KGIndexRetriever
from llama_index.query_engine import RetrieverQueryEngine
from llama_index.postprocessor import KeywordExtractor
from llama_index.vector_stores import ChromaVectorStore
from llama_index import VectorStoreIndex, QueryBundle
from llama_index.retrievers import BaseRetriever
from typing import List
from llama_index.indices.query.query_transform.base import QueryTransform
from llama_index.query_engine.utils import retrieve_response_from_empty_query
# 假设我们已经有了向量索引 (vector_index) 和图谱索引 (kg_index)
# 为了演示,我们创建一个临时的向量索引
# (在实际应用中,您可能已经通过加载和分割文本创建了它)
# 这里假设 texts 列表已经存在 (来自 6.2.2 的步骤)
if 'texts' in locals():
embeddings = OpenAIEmbeddings()
chroma_collection = Chroma.from_documents(texts, embeddings, persist_directory="./temp_chroma_db").get()
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
vector_index = VectorStoreIndex(vector_store=vector_store)
else:
print("请先运行 6.2.2 的代码以创建文本数据和向量索引。")
exit()
# 创建向量检索器
vector_retriever = VectorIndexRetriever(index=vector_index, similarity_top_k=3)
# 创建图谱关键词检索器
kg_keyword_retriever = KGIndexRetriever(
index=kg_index, similarity_top_k=5, search_type="keyword"
)
# 创建混合检索器 (简单地将两个检索器的结果合并)
class HybridRetriever(BaseRetriever):
def __init__(self, vector_retriever, kg_retriever, query_transform: QueryTransform = None):
self._vector_retriever = vector_retriever
self._kg_retriever = kg_retriever
self._query_transform = query_transform or KeywordExtractor(keywords_only=True)
def _retrieve(self, query_bundle: QueryBundle) -> List[llama_index.schema.NodeWithScore]:
transformed_query = self._query_transform(query_bundle)
vector_nodes = self._vector_retriever.retrieve(query_bundle)
keyword_nodes = self._kg_retriever.retrieve(transformed_query)
return vector_nodes + keyword_nodes
# 假设 vector_index 已经创建 (例如,基于文本数据)
hybrid_retriever = HybridRetriever(vector_retriever=vector_retriever, kg_retriever=kg_keyword_retriever)
query_engine_hybrid = RetrieverQueryEngine.from_args(retriever=hybrid_retriever)
response_hybrid = query_engine_hybrid.query("请问史蒂夫·乔布斯创立了什么公司?")
print("混合检索结果:", response_hybrid)
# 更复杂的混合策略:基于问题类型的路由器
from llama_index.query_engine import RouterQueryEngine
from llama_index.selectors import PydanticSingleSelector
query_engine_router = RouterQueryEngine(
selector=PydanticSingleSelector.from_defaults(),
query_engine_dict={
"vector": RetrieverQueryEngine.from_args(retriever=vector_retriever),
"graph": RetrieverQueryEngine.from_args(retriever=kg_keyword_retriever),
},
)
response_vector = query_engine_router.query("请问苹果公司的总部在哪里?") # 向量检索更适合
print("路由查询 (向量):", response_vector)
response_graph = query_engine_router.query("史蒂夫·乔布斯创立了什么公司?") # 图谱检索更适合
print("路由查询 (图谱):", response_graph)
# 其他混合检索策略:
# 1. 加权融合:可以为不同检索器的结果分配不同的权重,然后根据加权后的分数进行排序。
# 以下是一个简单的加权融合的示例:
def weighted_fusion(vector_results: List[NodeWithScore], graph_results: List[NodeWithScore], vector_weight=0.6, graph_weight=0.4, top_k=5):
"""对向量检索和图谱检索的结果进行加权融合。"""
fused_results = {}
for res in vector_results:
fused_results[res.node.node_id] = fused_results.get(res.node.node_id, 0) + res.score * vector_weight
for res in graph_results:
fused_results[res.node.node_id] = fused_results.get(res.node.node_id, 0) + res.score * graph_weight
sorted_results = sorted(fused_results.items(), key=lambda item: item[1], reverse=True)
top_fused_results = []
for node_id, score in sorted_results[:top_k]:
vector_node = next((r.node for r in vector_results if r.node.node_id == node_id), None)
graph_node = next((r.node for r in graph_results if r.node.node_id == node_id), None)
node = vector_node if vector_node else graph_node
if node:
top_fused_results.append(NodeWithScore(node=node, score=score))
return top_fused_results
query_fusion = QueryBundle("请问史蒂夫·乔布斯创立了什么公司?")
vector_results_fusion = vector_retriever.retrieve(query_fusion)
graph_results_fusion = kg_keyword_retriever.retrieve(query_fusion)
fused_results = weighted_fusion(vector_results_fusion, graph_results_fusion)
print("加权融合结果:", fused_results)
# 2. 基于元数据的路由:可以根据查询中或文档中的元数据信息,选择特定的检索器。
# 以下是一个基于查询关键词进行路由的简单示例:
def metadata_based_routing(query_str, vector_retriever, kg_retriever):
"""基于查询关键词选择检索器。"""
if "总部" in query_str:
print("使用向量检索器...")
return RetrieverQueryEngine.from_args(retriever=vector_retriever).query(query_str)
elif "创立" in query_str:
print("使用图谱检索器...")
return RetrieverQueryEngine.from_args(retriever=kg_retriever).query(query_str)
else:
print("使用混合检索器...")
return RetrieverQueryEngine.from_args(retriever=HybridRetriever(vector_retriever, kg_retriever)).query(query_str)
query_headquarters_route = "请问苹果公司的总部在哪里?"
response_headquarters_route = metadata_based_routing(query_headquarters_route, vector_retriever, kg_keyword_retriever)
print("基于元数据的路由 (总部):", response_headquarters_route)
query_founded_route = "史蒂夫·乔布斯创立了什么公司?"
response_founded_route = metadata_based_routing(query_founded_route, vector_retriever, kg_keyword_retriever)
print("基于元数据的路由 (创立):", response_founded_route)
代码解释:
- 创建向量检索器: 基于之前创建的向量索引。
- 创建图谱关键词检索器: 基于 KnowledgeGraphIndex,使用关键词匹配进行检索。LlamaIndex 还支持其他图谱检索方式,如基于 Embedding 相似度的图谱检索(如果 include_embeddings=True)。
- 构建简单的混合检索器: HybridRetriever 类简单地将向量检索和关键词检索的结果合并。
- 构建基于问题类型的路由器: RouterQueryEngine 可以根据用户提出的问题,选择使用哪个检索器(向量或图谱)。这里使用了 PydanticSingleSelector 进行选择,您可以根据需要自定义选择逻辑。
- 加权融合:
weighted_fusion函数演示了如何对来自不同检索器的结果进行加权,并返回加权分数最高的 top-k 个结果。 - 基于元数据的路由:
metadata_based_routing函数演示了如何根据查询字符串中的关键词来选择使用哪个检索器。
6.4 RAG 应用调试与评估技巧
构建 RAG 应用后,调试和评估其性能至关重要。以下是一些常用的技巧:
6.4.1 数据流调试
- 检查数据加载与切分效果: 打印加载的文档数量和分割后的文本块数量,检查文本块的大小和重叠度是否符合预期。
- 验证 Embedding 质量: 对于一些已知的相关文本块,计算它们的 Embedding 向量之间的相似度,判断 Embedding 模型是否有效地捕获了语义信息。也可以将 Embedding 向量降维后可视化,观察其分布。
- 检查向量/图谱存储内容: 查看向量数据库中存储的向量数量,或者查询图数据库中的节点和关系,确保数据正确地存储。
6.4.2 检索过程调试
- 使用 verbose 或日志输出: LangChain 和 LlamaIndex 通常提供 verbose 模式或日志记录功能,可以查看检索过程中的详细信息,例如发送给向量数据库的查询、召回的文档及其相似度分数。在 LangChain 中,可以在创建链时设置 verbose=True。在 LlamaIndex 中,可以调整日志级别。
- 分析召回的上下文: 打印检索器召回的文本块或图谱节点的内容,判断它们是否与用户查询相关。
- 检查相似度分数或其他检索指标: 分析检索器返回的相似度分数或其他相关性指标,判断检索结果的质量。
- 调整检索参数: 根据调试结果,调整检索器的参数,例如 top_k(返回的文档数量)、相似度阈值等。
6.4.3 生成过程调试
- 检查最终传递给 LLM 的 Prompt: 打印最终发送给 LLM 的 Prompt,确保其中包含了正确的用户查询和检索到的上下文信息。
- 分析 LLM 输出: 观察 LLM 生成的答案是否基于提供的上下文,是否存在幻觉(生成了上下文中没有的信息),是否遵循了 Prompt 中的指令。
- 对比有无 RAG 的输出差异: 可以尝试直接使用 LLM 回答相同的问题,对比其结果与 RAG 系统的输出,判断 RAG 是否有效地提升了答案的质量。
6.4.4 初识 RAG 评估
评估 RAG 系统的性能是一个复杂但重要的任务。以下是一些基本的评估维度和方法:
-
答案相关性 (Relevance): 评估生成的答案是否与用户提出的问题相关。这通常需要人工判断。
-
知识忠实度 (Faithfulness): 评估生成的答案是否完全基于提供的上下文信息,避免出现幻觉。可以使用自动化方法(例如,基于 NLI 的模型)或人工评估来判断。
-
上下文召回率 (Context Recall): 评估检索器是否能够召回所有与用户问题相关的上下文信息。这通常需要一个包含正确答案和相关上下文的评估数据集。
-
Ragas 简介: Ragas 是一个专门为评估 RAG 系统而设计的开源框架。它提供了一系列基于 LLM 的无人工干预的评估指标,例如:
- Faithfulness (忠实度): 衡量生成答案与检索到的上下文之间的一致性。
- Answer Relevancy (答案相关性): 衡量生成答案与用户查询的相关性。
- Context Recall (上下文召回率): 衡量检索到的上下文包含回答查询所需的所有相关信息的程度。
- Context Precision (上下文精确度): 衡量检索到的上下文与回答查询的相关性,排除不相关的信息。
Ragas 的基本使用流程通常如下:
- 准备一个包含用户查询、检索到的上下文和生成的答案的评估数据集。
- 安装 Ragas 库:
pip install ragas - 使用 Ragas 提供的评估函数和指标对数据集进行评估。
例如,假设我们有以下的评估数据,存储在一个 Pandas DataFrame 中:
import pandas as pd evaluation_data = pd.DataFrame({ 'query': ["苹果公司的总部在哪里?", "史蒂夫·乔布斯创立了什么公司?"], 'contexts': [ ["苹果公司(Apple Inc.)的总部位于美国加利福尼亚州库比蒂诺市。"], ["史蒂夫·乔布斯是苹果公司的联合创始人之一。", "史蒂夫·乔布斯还与他人共同创立了皮克斯动画工作室。"] ], 'answer': ["苹果公司的总部位于库比蒂诺市。", "史蒂夫·乔布斯创立了苹果公司和皮克斯。"] })现在,我们可以使用 Ragas 对这些数据进行评估:
from ragas import evaluate from datasets import Dataset # 将 Pandas DataFrame 转换为 Hugging Face Dataset eval_dataset = Dataset.from_pandas(evaluation_data) results = evaluate( eval_dataset, metrics=[ "faithfulness", "answer_relevancy", "context_recall", "context_precision", ], ) print(results)解读评估结果:
results对象会包含每个评估指标的得分。例如,您可能会看到类似以下的输出:{'faithfulness': 0.95, 'answer_relevancy': 0.98, 'context_recall': 1.0, 'context_precision': 0.85}- Faithfulness (忠实度): 得分接近 1 表明生成的答案与提供的上下文信息高度一致,没有出现幻觉。
- Answer Relevancy (答案相关性): 得分接近 1 表明生成的答案能够很好地回答用户提出的问题。
- Context Recall (上下文召回率): 得分接近 1 表明检索到的上下文包含了回答问题所需的所有相关信息。
- Context Precision (上下文精确度): 得分接近 1 表明检索到的上下文大部分是与回答问题相关的,没有包含太多无关信息。
通过分析这些指标,您可以了解 RAG 系统的优势和不足,并针对性地进行优化。例如,如果上下文精确度较低,可能需要调整检索策略以减少无关信息的召回。
6.5 本章小结
本章通过两个实战案例,演示了如何使用 LangChain 和 LlamaIndex 构建集成向量检索和图谱检索的 RAG 应用。我们学习了如何加载和处理数据、创建 Embedding 向量并存储到向量数据库、连接到图数据库并构建知识图谱索引,以及如何构建混合检索查询引擎,并深入探讨了加权融合和基于元数据的路由等策略。最后,我们还介绍了一些常用的 RAG 应用调试和评估技巧,并提供了使用 spaCy 进行简单三元组提取以及使用 Ragas 进行 RAG 评估的示例。
构建强大的 RAG 系统是一个不断学习和迭代的过程。希望本章的内容能够为您提供一个良好的起点,鼓励您继续探索不同的 RAG 策略和框架,并根据您的具体应用场景进行创新和优化。
内容同步在gzh:智语Bot