互联网三高架构设计
1 业务架构
1.1 功能分离
目标:确保核心功能的高可用和高并发
① 区别核心功能和非核心功能
② 流量突发性(秒杀)和流量平缓型
③ 功能隔离和功能降级
1.2 业务分层
(1)分层设计
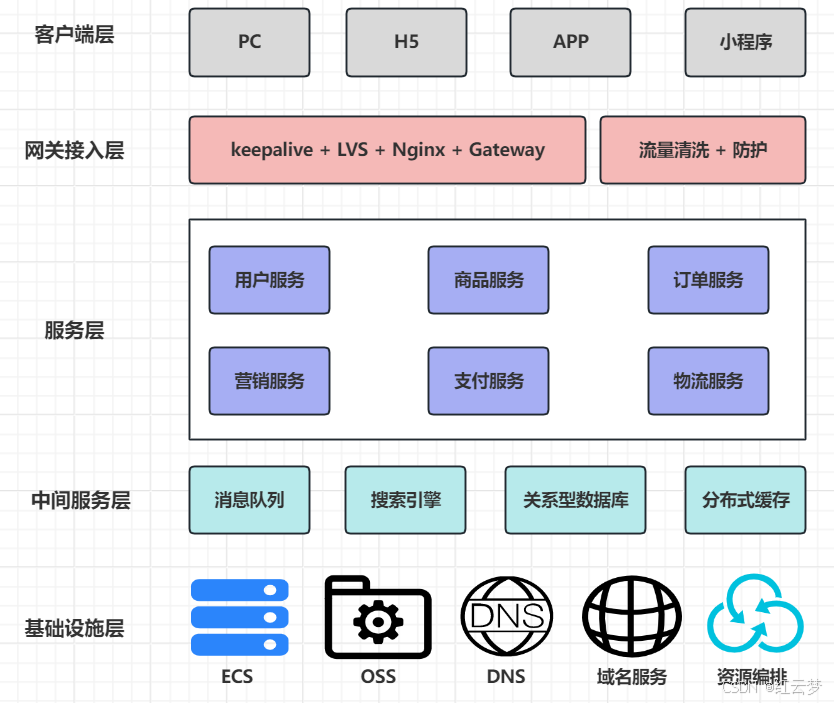
(2)分层过滤模型
① 直筒型:用户请求1:1洞穿到DB层
传统的低并发、低性能、低可用的项目
② 漏斗型
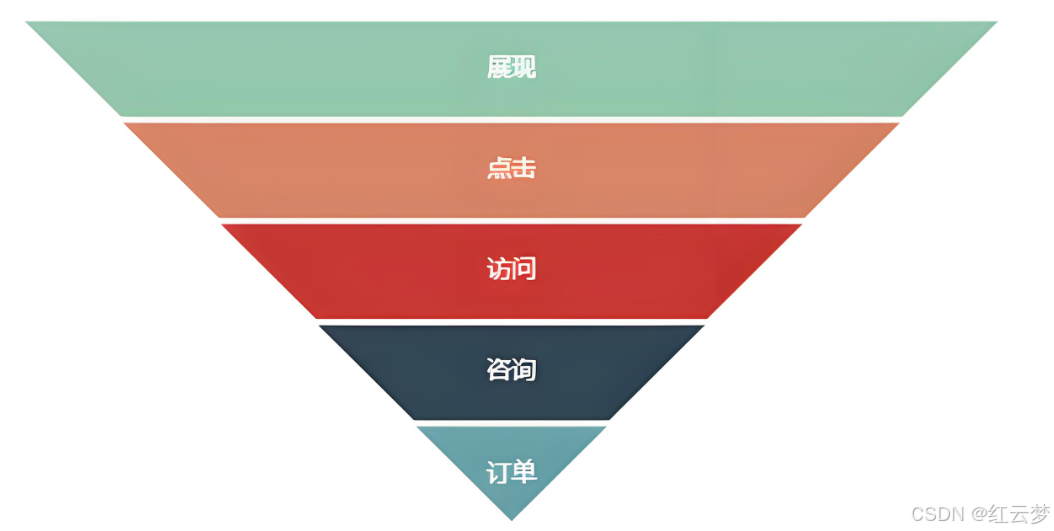
互联网应用
请求峰值和平均值相差巨大
请求峰值远远超过最后一层(数据层)处理能力
(3)幂等性原则
一次请求和多次请求同一个资源产生相同的结果
需要幂等的场景
① 网络波动
② 消息队列消费
③ 用户重复操作
④ 未关闭的重试机制
幂等性解决方案
① 全局唯一ID
② 唯一索引
③ 多版本控制
④ 状态机控制
2 流量架构
按照未来一段时间(2年)的用户规模,做系统流量的预估。再按照流量预估和系统各层组件的性能参考值,做各层组件的部署架构。
2.1 二八定律
核心原则:关注重要部分,忽略次要部分
利用二八定律来计算预估值
① 通过用户量来推算PV
公式:(总用户量 * 20%) * 每天大致点击次数(淘宝经验值30-50次) = PV值
比如:总用户量为100万
PV值 = 100w * 0.2 * 30 = 600w
② 通过PV推算QPS
公式:(PV数 * 80%)/ (每天秒数 * 20%) = 峰值QPS
峰值QPS = (600w * 0.8) / (24*60*60*0.2)= 277
③ 加上冗余系数
行业经验一般是2-5之间
QPS = 峰值QPS * 冗余系数
QPS= 277 * 4 = 1108
所以100w用户,QPS大概为1000左右
二八定律算法:80%的请求 / 20%时间 * 冗余系数
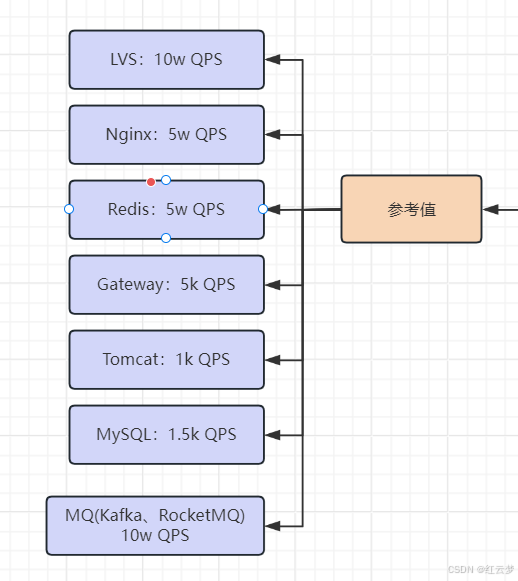
2.2 中间件规划(根据不同的用户、QPS)
3 数据存储架构
3.1 数据库服务器参考能力
内在因素
① 确认数据库:MySQL
② 机器性能:CPU核数、内存大小、磁盘IO能力、网络带宽等
外在因素
② 应用服务:是复杂查询还是简单查询
② 单表容量:500w正常、800w警戒线、1000w必须分库分表
3.2 分库分表架构
(1) 为什么要分库分表
IO瓶颈:磁盘读写IO瓶颈
CPU瓶颈:SQL问题,单表数据量太大
(2)库表数量规划
可以按照两年规划,一天100w数据量
100w * 365 * 2 = 7亿数据量
① 表的数量规划(单表标准值:500w)
7亿 / 500w = 146 ==>换成2的次幂,128张表
7亿 / 128 = 546w ,没有超过警戒线800w
② 库的数量规划(根据QPS计算,1wQPS,MySQL QPS参考值为1500)
1w / 1500 = 7 ==>换成2的次幂,8个库
128 / 8 = 16,所以最终规划为 8 * 16(8个库,每个库16张表)
(3)分库分表技术选型
推荐:ShardingJDBC,比较成熟的技术方案。基于JDBC协议的轻量级框架,支持分库分表、读写分离、分布式事务,适用于复杂业务场景(如电商订单系统)
3.3 冗余双写架构
根据不同的维度,聚合异构数据(用户维度,商家维度),比如电商系统,订单就应该做冗余双写方案,客户和商家不同维度。
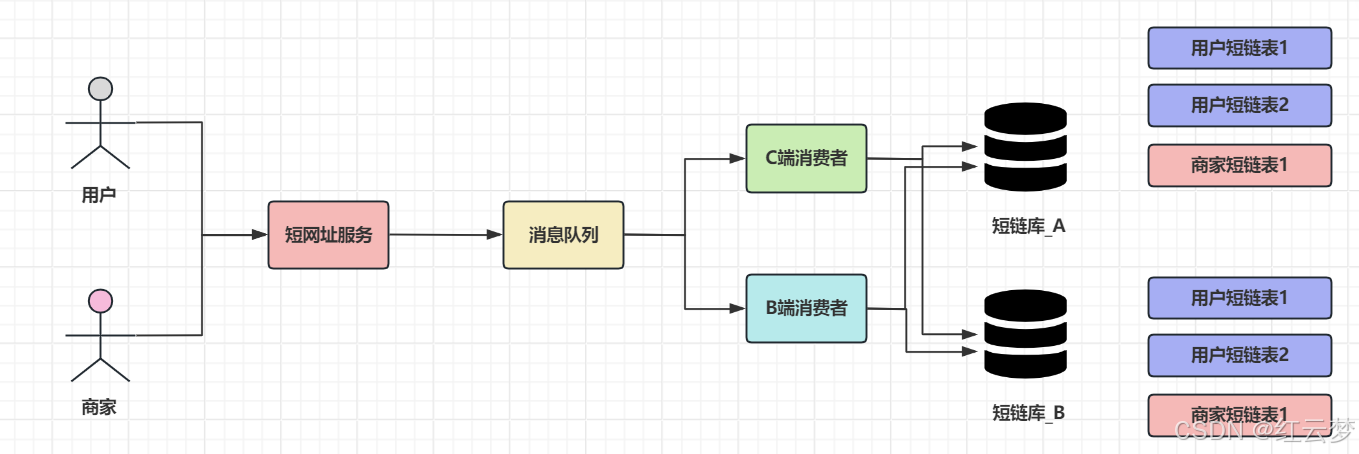
① MQ + MySQL异构方案:我之前带着团队完整的短网址平台就是使用这种方式。消费端生成短网址根据不同的分库分表策略异冗余双写到不同的库表中。
② 直接RPC调用+Seata分布式事务框架
② ES + Hbase异构方案