关于AI大模型的一些理解
大模型本身并没有那么邪乎的分析能力,他只是在一味地模仿人类。不然所有的大模型都可以在模型评测中拿100分了。
大模型的基本原理是生成下一个token,他是根据自己的训练数据集和用户的当前上下文来输出下一个词。 大家没有了解过大模型的基本原理的可以去仔细体会一下这句话。
大模型首先要经过预训练,理解词语之间的微妙联系,它能够注意到某些个词语之间经常一起出现,某句话中某个词语可能是重点,这就是大模型基础架构Transformer的注意力机制。预训练过后,大模型就有了基本的语言理解能力。
下一阶段就到了监督微调阶段,这一阶段使用高质量的数据集进行训练,让大模型能更好地理解某些特定的知识。
最后,经过基于人类反馈的强化学习,让大模型的回答朝着符合人类需求的方向,此时,一个能够比较精准回答人类问题的模型就这样诞生了。
让大模型具备推理能力的方法有很多,其中一种就是让大模型继续接受基于人类反馈的强化学习,强行训练模型在输出Token之前先输出思考过程。

所以,大家仔细地去理解这段话,模型是被训练出来的,**跟咱们教育自家孩子一样。孩子的一切行为,包含说的话,都是在模仿父母。大模型的一切思维、话语都是在模仿它的训练集。**它并没有真正的思维能力,只是看过的东西多了。有一种,读书破万卷,下笔如有神的意思。
这就是大模型的核心原理,这是大家要有的基本认识。同时也要明确,大模型的基本原理说明了大模型中暂时还没有真正的像人一样的完整思维,只是越练越聪明。当前阶段的大模型,都是这样的一个状态,说不定在不久的将来,真的能够实现通用人工智能,大模型真正地有了智能能力。


大模型的参数量越大,细节的理解能力越强,同样的词语,参数量大的模型理解的更深刻。但是大参数模型对于GPU的要求更高,需要的显存大小更大,普通的家用级别的显卡可能满足不了。但是,随着技术的进步,越来越多30B大小的模型能力能够接近671B这种大参数的模型。计算机行业里面,存在着摩尔定律这样经典的定律,计算机技术每隔几个月都能翻一番。模型训练技术也是这样,大家要保持着这样的期待。**在未来的一两年内,大模型的硬件要求会越来越低,参数量越来越小,性能却越来越强。到那时,家用电脑也能拥有更高的人工智能智慧,**就好比每个人都给你配备了一个知识渊博,什么都会的专家。有的人可能觉得我在天方夜谭,但大多数人还是非常认同我这个想法,因为它已经开始照进现实了。
这是我要说的第一个趋势,模型越来越小,越来越智能,人人都能够使用自己部署的大模型。
大模型的研发是模型研发人才的事情,咱们普通人是没有能力,也没有设备去训练这么高要求的东西。而且,即使你有条件,也没有时间,也没有那么多的精力去搞,更搞不过谷歌、OpenAI的大厂。普通人去训练大模型纯属自娱自乐,因为你的专业水平和硬件水平都不够。普通人好一点的可以去做做微调,微调不需要那么多的资料,并且还能让别人训练好的模型,能够理解你专业领域中的东西。但是,微调也是需要技术的,有些人微调别人的大模型,最终模型就跟智障似的。去问问人工智能专业的同学,认不认同我的说法。
第二个趋势:大模型的多模态能力会有重大突破,通用人工智能有望。
最近OpenAI的gpt-4o图像生成很火,生成吉卜力等风格的图片效果非常棒,完全能够理解图片和文字,最终生成的结果也是非常喜人。
根据以往的规律,2025年内,一定会有开源的多模态能力的大模型登场。同时我们通过gpt-4o的理解能力可以看到,模型在生成图像时,对于图像描述的理解非常到位,图像复刻的能力也很强。这说明,模型在开始理解图像了,就像我们人类看到图像时的理解一样,这说明我们当前的算力和算法,已经能够让模型去理解图像中的每个部分。图像基本上已经能够涵盖我们所使用的大部分文件了,也能够涵盖我们平时理解世界、理解社会的途径,再加上未来,模型还能够去理解视频。所以,很多推特上的大佬对于gpt-4o的赞叹不仅仅是因为他的图像生成效果,更是因为它有了像人类一样了解这个世界的能力–它能够理解他所看到的东西。这不就是通用人工智能吗!
所以,大家在做AI相关的事情,一定要注意大模型多模态能力的提升,这在未来,会是一个重大的科技变革,将会影响我们生活工作的方方面面。
咱们普通人、普通开发者的机会在于,等待着模型能力的提升。这期间,我们要储备一些知识和工具,等到模型更聪明了,它能够更好地去理解这些知识和使用这些工具。
这是我要给大家的第一条建议:为大模型提供高质量的知识和好用的工具。
如果有的朋友没听说过工具,我这里简单的解释一下。
大模型只会说,但是不能做事,但是可以让大模型输出工具调用,我们写一段程序帮他完成这个事,再把事情完成的结果再告诉大模型,这就可以让大模型去真正的做事。也可以通过这种方式,让大模型去网上搜索一些实时的资料来更好地理解用户的问题。
这个能力是大模型模仿人类的有一大进步。我们平时上班,用到很多软件:word、表格、ppt、编程软件,剪视频的,画图的,所有的软件都是我们自己去学习使用的。我们能够完成某些工作,是因为我们前期看过很多教程,学会了使用这些办公软件。对于大模型也是这样,大模型的聪明程度后期会远远超越普通人,学过的东西也是普通人几辈子也学不过来的。那么,如果我们给大模型提供这样五花八门的工具或者软件,简单地说明一下这些工具有哪些操作,怎么使用。那么大模型一定能够替我们干活。大模型的理解能力绝对是咱们大家都要强的,这一点大家可以放心。
在最近的一两年内,给大模型提供教程、工具一定会成为热点。最近爆火的MCP,所谓模型上下文协议,其核心就是把工具、资源等东西规范化的提供给大模型,集中式地管理。MCP解决了一个非常重要的问题,那就是**过去我们很多人都在针对于同一个操作进行方法调用的封装。这工作量是M*N的,大家都在做这个M的工作,有N个软件需要我们去接入。这工作量非常大。但是MCP把这一切都给标准化了,比如说,我做了个关于数据库操作的MCP Server,那么别人就可以直接用我的,而不需要去重复开发。这工作量立马就变成M+N,节省了多少工作量。**MCP也不是什么厉害的协议,充其量算是一个规范,只不过这个规范生对了时候,正是大家都需要一个标准来节省工作量,来共享工作成功的时候,它有了用武之地。即使没有MCP也会有其他协议来做这样的事情,大家可以对MCP去魅了。
但是,MCP仍然是非常重要的,现在OpenAI全家桶都宣布支持MCP了。MCP由Claude母公司Anthropic提出,再加上有OpenAI这样的大公司支持,MCP的生态日渐丰富,一定成为事实标准的。大家可以把自己的业务做成MCP Server供客户使用,或者将自己的家的客户端支持MCP协议,支持接入MCP生态也可以。总之,大模型需要更多更好用的工具来增强大模型的能力,赋予大模型更多的操作。而这部分工作就得由我们来做。


我们发展AI的目的,其实就是希望有朝一日,AI能够代替人类去工作,进而去解放生产力。大家不要害怕,也不要惊慌,担心自己会不会被AI淘汰,被AI所替代,新的时代,一定会有一些岗位被AI基本取代,但是,只要你会使用AI,去驾驭AI,那AI只会让你更强大。AI的理解能力越强,我们使用AI就越轻松。未来,很多事情,只要你描述清楚了,AI一定会做的符合你的预期,做的非常出色。
在这之前,希望大家多多去写一些提示词,写一些教程,甚至是编排一些工作流程,这些东西都是指导AI去帮助你工作的核心组件。大家也不要害怕去写这些东西,AI的训练需要一定的知识背景,但是AI的使用和AI应用的开发调教,基本上没有任何门槛。等你把这些东西给准备好,用不了多久,AI就会更加聪明,到时候让AI使用你积累的东西,就如行云流水一般流程。
到时候,AI可以帮你发邮件,做报告,生成PPT等等,领导给你安排的事情,你可以完全地交给AI去做。
面向大模型去提供服务,例如:提供资源(文件)、工具、经验(提示词),工作流与基础架构,一定会成为几年内的热点。
**如果你是某个单位的领导或者经理,或者你要负责智能化的事情,请你一定要把大模型看作是一个聪明能干的人。**把他用你的制度,你的规范,你的管理经验进行管控,让大模型完成工作流程上的某一个节点,这些统称为“机制”,用机制来来管理。一架飞机,一艘航母,一台光刻机,多么大的制造难度,但是我们人类却能制造出来,靠的就是机制,有设计、有规范、有流程、有监控、有审核,滴水不漏。
所谓的智能化,已经不是传统意义上,用AI去增强什么,而是让AI成为你本身机制的一部分。AI可以取代某些人工操作的部分。或许,你可以在这个过程中,发现机制中存在的可优化点,接着AI智能化的过程,重新进行设计,让AI可以更好的融入。这一些,都是企业内部的事情,别人可能只能给你提提建议,真正的操作权和未来实现的效果,确确实实地掌握在你手里。永远要比AI多思考一步。
切记不要再做出一个Dify出来了,不要再做智能体平台了,没人会关心智能体,大家只想着用好AI,让AI服务,而不是费劲吧地去使用你搭建的四不像的平台,做出一个不智能的东西来。

再给大家提一个建议:提高文档质量,保证文档的准确性和完整性。
大家可能或多或少听过RAG和DeepResearch这两个词。我给大家讲一下这是怎么回事。
RAG是检索增强生成,意思是说,大模型训练完成后,学到的知识就固定了,没有办法去额外的获取知识。但是我们可以通过检索一些与问题相关的内容,提供给大模型,让大模型进行分析。这就是所谓的利用检索来增强大模型的生成内容。DeepResearch也是类似,让大模型先生成报告目录,基于目录中的每一个问题进行网页搜索,把搜索到的知识进行分析,来生成每一章节的内容。这个搜索过程是一个循环,直到大模型觉得满意为止,大模型才会继续下一个章节的生成,否则就会持续地搜索、分析、决策。
因此,搜索的内容如果质量很差,驴唇不对马嘴,将会严重的影响大模型的最终输出结果。谷歌的DeepResearch很好用,推特的Grok也很好用,非常重要的一个原因就是,它们的搜索引擎收录的内容质量很高,大模型能够分析出来的结论自然也高。
因此,如果各位读者中,有做企业ERP智能化的或者其他垂直行业的,请你一定要重视文档质量,文档写的差,规则和制度写的差,大模型根本理解不了的话,再强的模型也是白搭。有的企业的开发规范、制度规范写得不行,就不要想着让大模型做智能客服。首先你得先用大模型帮你把文档规范一下。
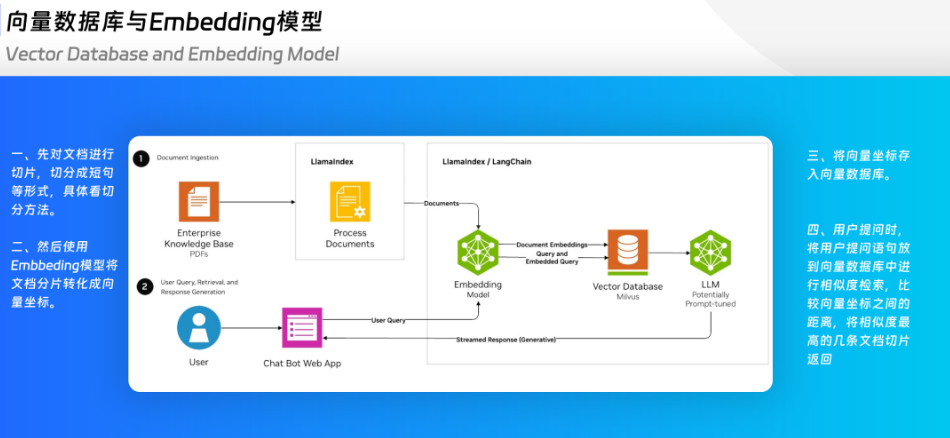


大家如果有做过AI应用,调试过提示词,又或者使用过AI进行报告生成的,能够很明显地感受到文档质量所带来的回答提升,是显而易见的。
再给大家一个建议:好的提示词比微调更有效。
大家可能前期提过提示词工程师这个词,说的就是需要一些专门的人来调整提示词,对提示词进行反复修改来进行优化。当然,也有很多人一听说推理模型出来之后,模型有了思考能力之后,就像真的人一样进行思考,完全不需要提示词了,问什么就能够精准地回答什么。但,实际上,这些人都不太懂大模型。
前期我们说过,大模型的核心原理依然是根据上下文,根据学过的知识,来模仿人类,生成token。他生成token的过程离不开上下文,好的上下文,好的提示词能够大模型准确地知道你想要问的是什么,而不是囫囵吞枣似的,说几句话就期盼着大模型能够精准地理解你的意思。这也是很多普通人使用大模型的一个非常高的门槛,大家往往在生活中都很难表达清楚自己的意图,还妄想着大模型能够读懂你的想法。
所以,**尝试着去转换一下自己的表达,给大模型提供更多的背景、条件、和你的目的,你的状态等客观存在的东西,描述清楚你的问题是什么,你要解决什么,你最终想让大模型干什么。**这个非常重要,大模型并不是什么都不需要就能够生成token的,他需要你的上下文,去自己学过的知识里面找到这样的上下文,才能够匹配到你所说的这种情况,对症下药。
用大模型就像在看医生,你光说你哪疼肯定不行,你得说说发作规律,持续时间,当然这些东西,医生都会追问你的,医生正是靠着这些细节,再加上一些医学设备的客观观察结果,最终才能诊断疾病。
**使用大模型又好像是一位老师在教一位学生做题。你作为老师,首先你自己得总结出一套做题方法和解题模版出来,学生照着你的思考,你的模版,照葫芦画瓢,一步一步地才能学会,学生才能真正地理解你的意思,学到你方法的精髓,才能在考试中拿到高分。**大模型也像是学生,你是老师,他认为你说的都对,那么你起码都保证自己得有个百分之八九十的正确吧。
所以,提示词在大模型使用和AI应用开发中相当重要,就好比沟通在人与人协作当中相当重要一样。会说话、会提问,永远是一门艺术。如果你正在调试提示词,去找一些资料来学习怎么跟大模型沟通。如果你没有编写过提示词,那就赶快开始吧。我前期出过一篇DeepSeek的提示词相关的文章,大家可以去看看。
注:大家一定要知道,推理模型并不是万能的,也并不是无敌的,它只是进行了推理,核心问题不在于模型的思考深度,而是在于你怎么去引导模型朝着你的方向进行思考。

前面,咱们说到提高文档质量和给大模型提供工具。
有没有一个指导思想去完成这项工作呢。
我的思考是这样的:要梳理业务概念,理清边界,明确定义与流程。要把资源做更高层的抽象,就像增删改查一样让AI去管理资源。
如果读者中有过运维经验,学习过K8s,你一定曾经为K8s的完美抽象和资源管理所折服。在K8s中所有的资源都有对应的资源抽象,把服务、数据库、网络、存储都做了更高层次的抽象,普通人上手k8s非常容易,使得运维工作更加轻松和自动化,新手理解起来很快。这就是梳理业务概念,明确定义与流程的魅力。当你把你的一切需要管理的东西做抽象,做分类,对于操作也进行分类,简单至上。好的东西一定是简单易用的。把这些工具做的足够简单,足够好用,轻松上手,这是一个核心思想。如果普通人都能分分钟学会,那么对于AI来讲,就是小菜一碟。
当然,简单的核心在于抽象,在于设计者本身对于这个系统理解很深。这也是一个技术活,可以发挥团体的作用,但是总要有一个人保持清醒。并且,没有人一开始就能做到完美,k8s也是迭代了好多版本之后,也是谷歌在虚拟机运维这么多年的经验积累。我们也可以靠迭代更多版本之后,能够真正地做到简单易用。那个时候,就能够感受到AI真的强大到难以置信。
最后,再给大家一个建议:做智能能力的领域化。
未来,通用人工智能一定会实现,当前还是达不到。但是,这并不妨碍我们用AI的真正目的。
我们用AI是想解决问题,解放生产力。每个行业都有自己行业独有的知识、流程和技术,通用人工智能是指模型能力的提升,智能水平的提升。而不是直接能够帮你解决行业内问题。行业的发展,公司的命运,完全掌握在各位手中,而不是AI的手中。
目前,大家都在各自的领域搞一些智能能力的嵌入,试图从一些局部做一些AI的优化。我非常赞同和支持大家这样的做法,**通过各种花活、调教,来把各自的智能场景做到极致好用。**其实,这是一种很正确的做法。
在AI运用这个领域,大家都是小白,都是未知数,这是一个新兴的东西。没有人能够说出来一套范式,一套规定,来告诉你,你必须这样做才算发挥AI的最大功力。 AI就是人力,一个企业,一个部门如果管理人力,如果配置资源,如何去解决问题,这都是你们内部的事情,你们可以效仿一些大企业的制度和流程。
但我想说的是,这依旧是一个行业的做法,大模型本身没有办法对针对各行各业进行定制化的能力增强。但是你可以把你企业中已有的知识储备、技术、流程,和管理经验,来让AI替你工作,管理好AI。
可能很多人在期待着Manus有朝一日能够开源,这样我就可以不费力气的搞智能场景了。但是,你要知道,Manus本身并不是什么厉害的东西,它的原理也就是提示词+工具。它的工具有ComputerUse和BroswerUse,能够让大模型操作计算机和浏览器。这两样东西都是开源的。Manus不是通用的解决方案,Manus只是在撰写分析报告这块,做到了极致,做了它自己的优化,他们把自己的想法付诸实现了而已。AI领域没有通用的解决方案,Manus也不会帮助你去做你的解决方案。
我希望搞AI的大家不要坐以待毙,没有人会给你一个智能化方案,智能化一定是亲力亲为,最终目的是要把AI作为你机制的一部分。而不是让AI去增强什么。