从数据流程梳理简单GPT模型各部分结构
本文的流程梳理基于该参考文章的代码:这里
规定红色为每部分的输入,蓝色为输出,各个维度的大小如边长所示
-
自注意力模块
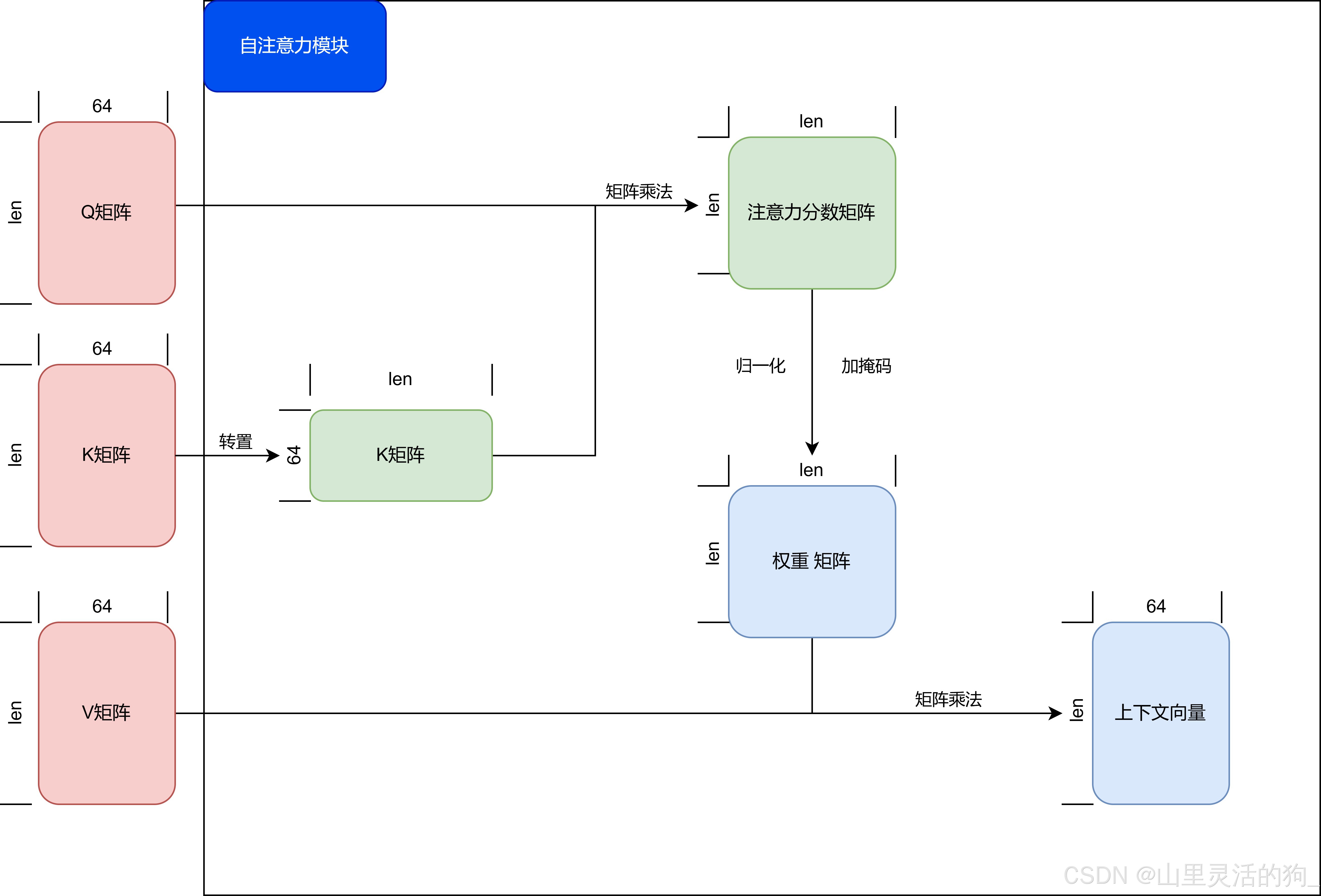
-
前馈神经网络模块
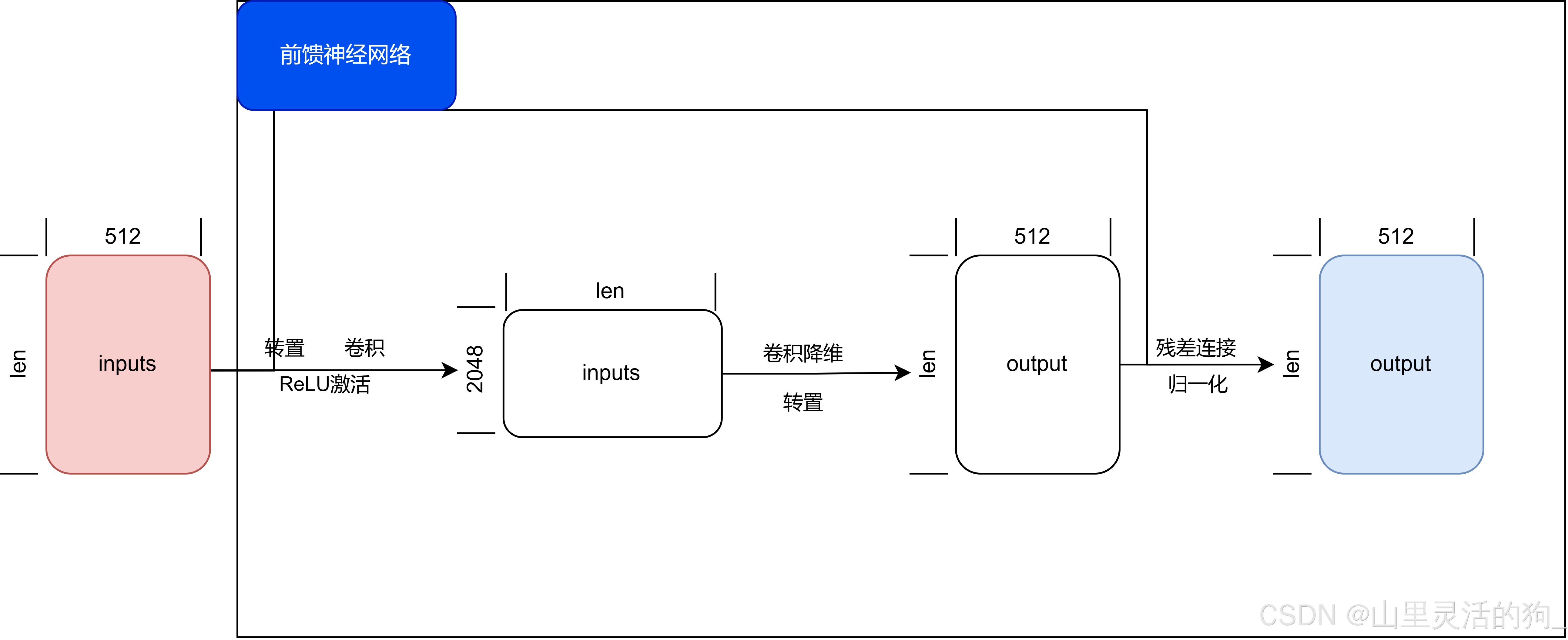
-
解码器层——解码器的组成单位
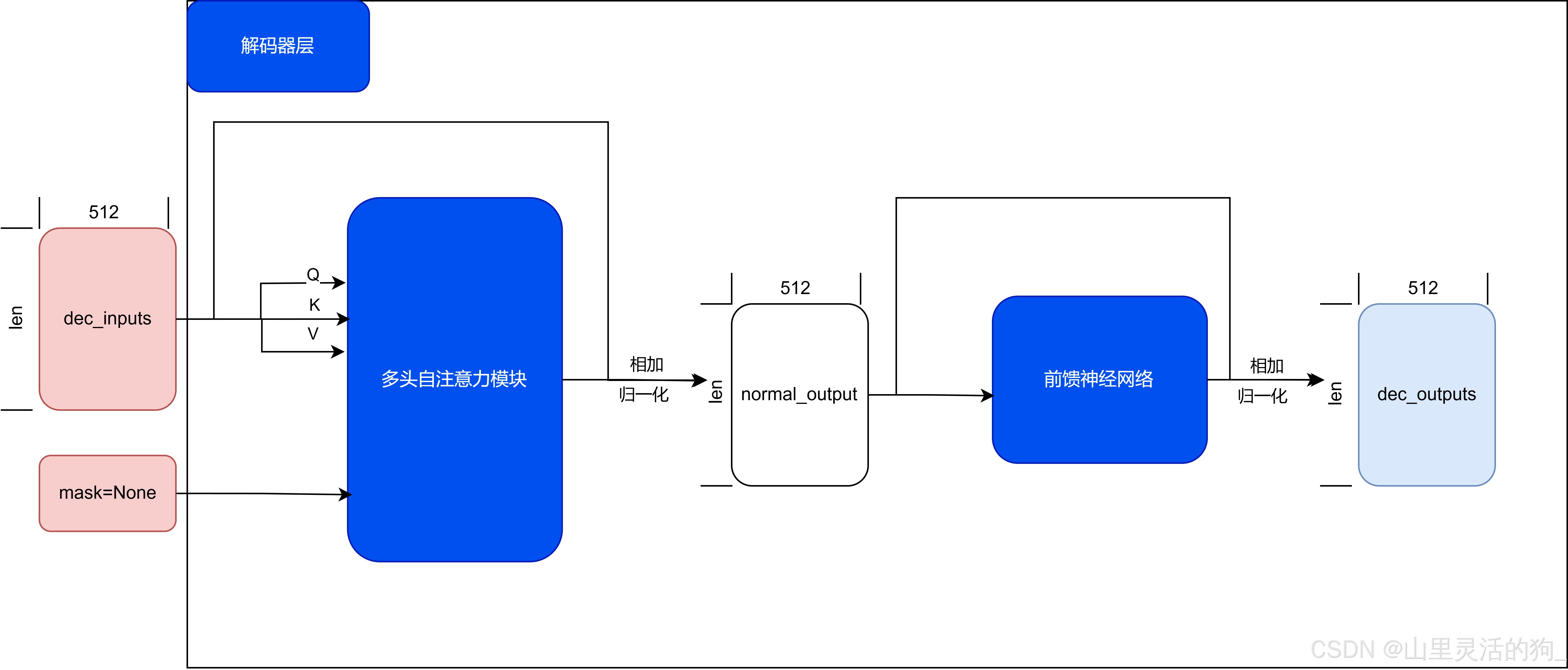
-
解码器
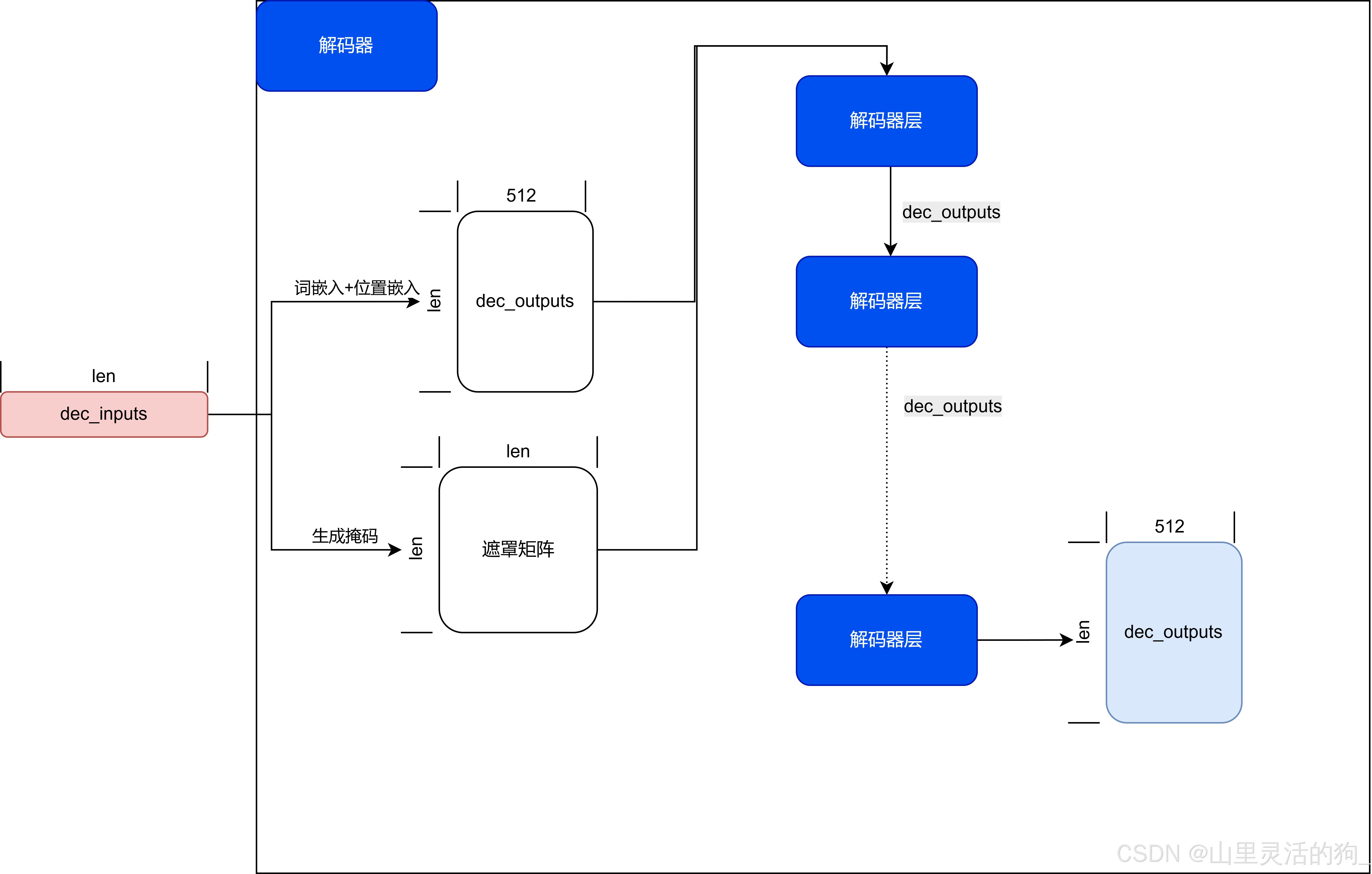
-
多头自注意力模块
-
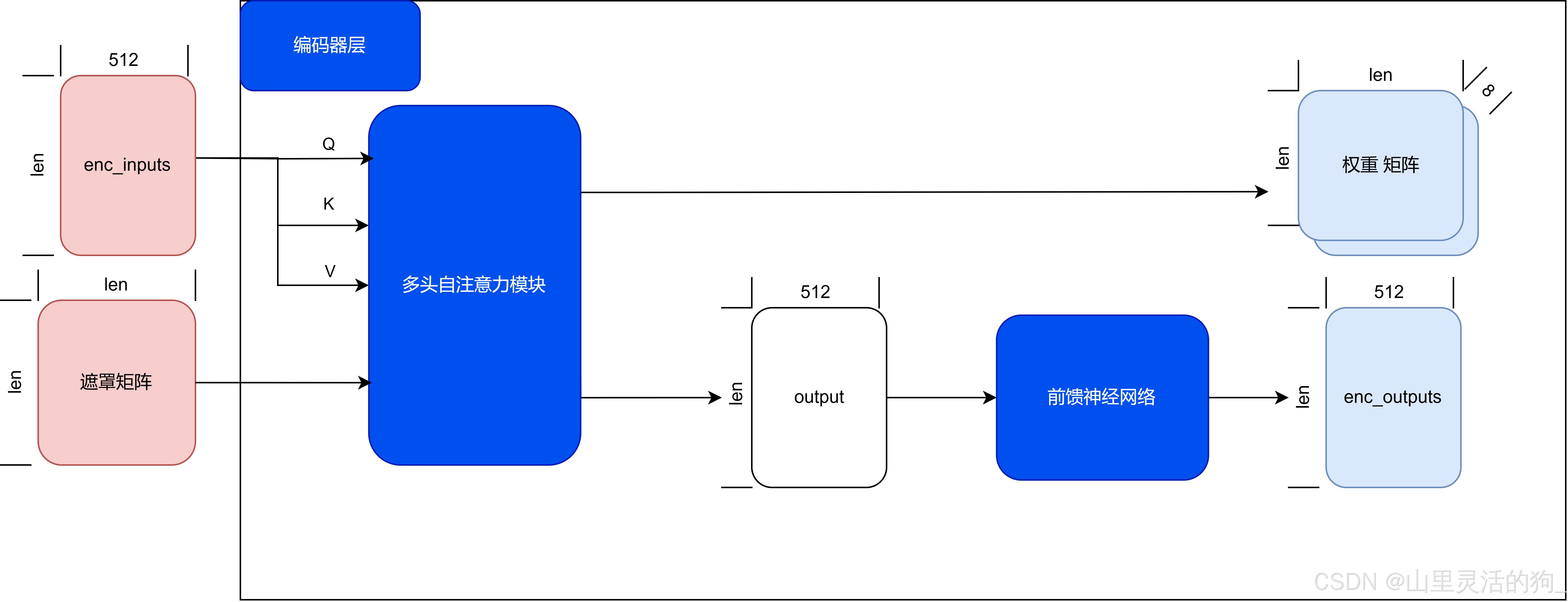
编码器层——编码器模块组成单位
-
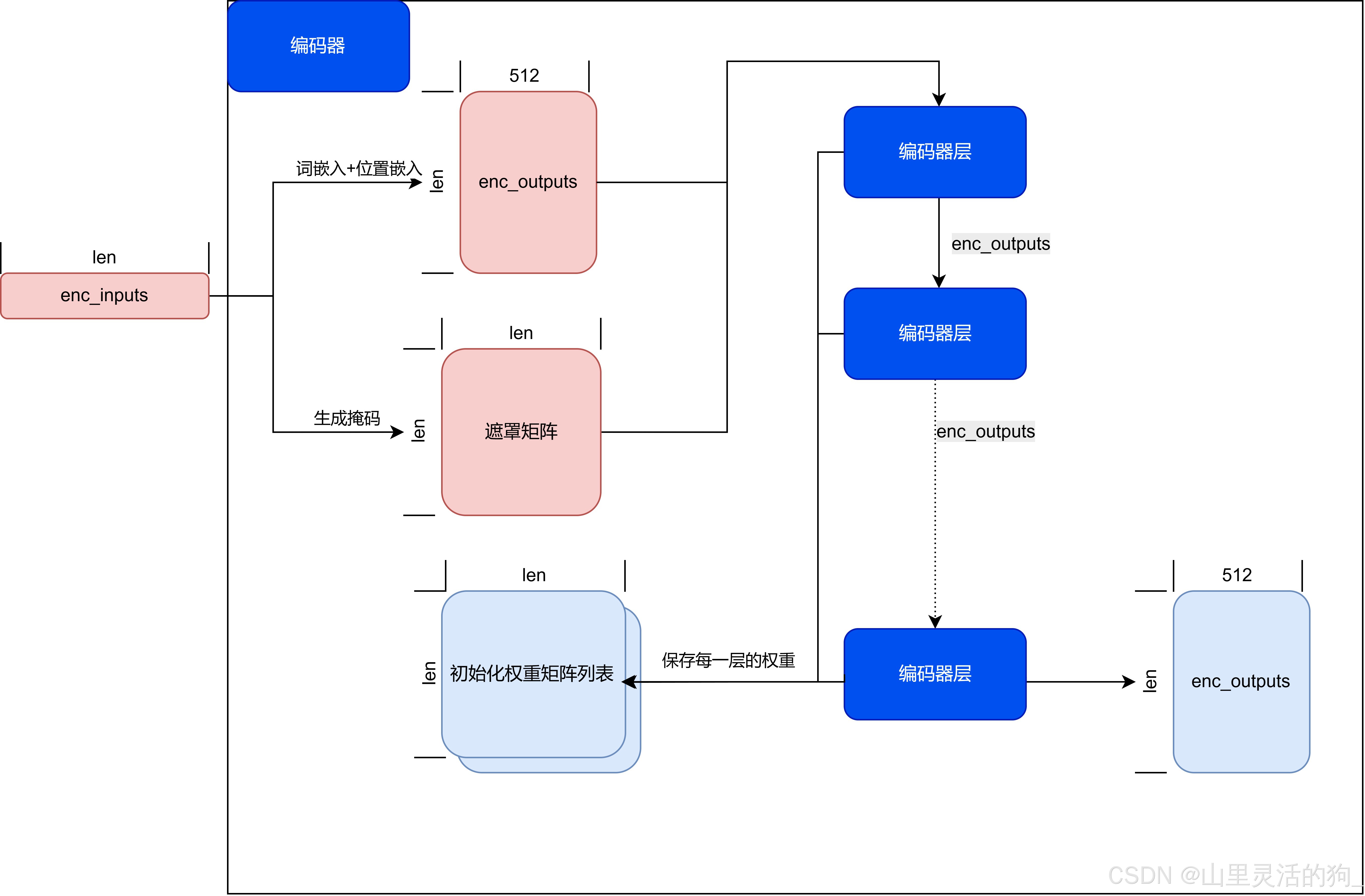
编码器
-
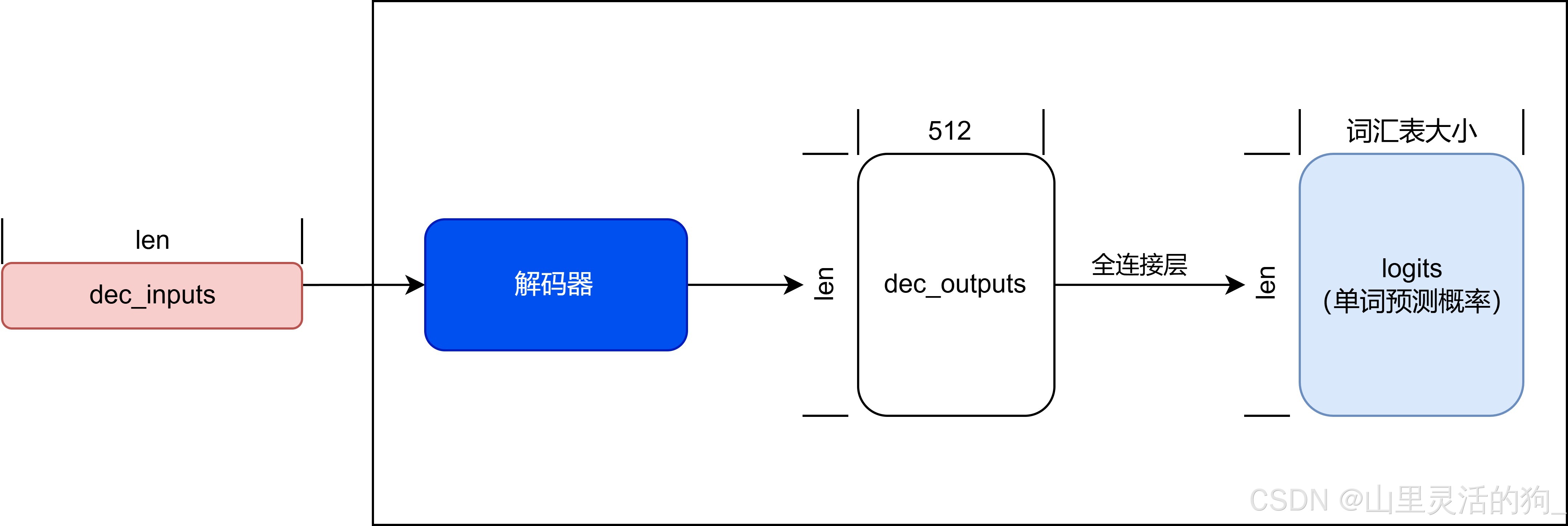
GPT的简单构成
本文的流程梳理基于该参考文章的代码:这里
规定红色为每部分的输入,蓝色为输出,各个维度的大小如边长所示
自注意力模块
前馈神经网络模块
解码器层——解码器的组成单位
解码器
多头自注意力模块
编码器层——编码器模块组成单位
编码器
GPT的简单构成