python爬虫爬取淘宝热销(热门)男装商品信息(课程设计;提供源码、使用说明文档及相关文档;售后可联系博主)
@TOC
本文仅为记录学习轨迹,如有侵权,联系删除
一、环境说明
使用前必须检查以下环境
(1)python编译环境
(2)python脚本执行所需要的库,具体看代码(main.py)import导入的部分库
(3)确保电脑可以正常连接网络,可以正常访问淘宝链接
备注:博主测试的python环境是3.8.8,尽量用python3版本
二、代码说明
代码请查看main.py,先看需要引入的库的部分,使用前需要保证这些库的正确引入,重点需要注意的是DrissionPage库的引入,该库用于爬取数据
共分为两个主要方法,一个是get_data方法,用于爬取数据,另一个是save_to_csv方法,用于保存数据

_main_是主函数入口,这里默认爬取30页的数据,可以根据实际情况修改要爬取的页数,不过需要注意的是,淘宝有很严格的反爬机制,如果爬取太多页的数据,可能会触发淘宝的相关反爬机制,例如限流、返回异常数据、或者弹窗验证码等操作。
三、代码执行
(1)前期准备
先打开谷歌浏览器,访问淘宝页面,然后先进行登录,这是为了绕过淘宝的登录验证机制,以前好像不用登录就可以搜索商品数据,现在好像有限制,而且为了避免引起不必要的麻烦,所以干脆先登录淘宝
(2)执行代码
博主测试时用的pycharm执行的代码,不过用python自带的编译器也可以,执行的时候代码会自动打开谷歌浏览器,然后自动在输入框输入商品名称,爬取数据后,会自动在页面点击下一页按钮进行换页,然后再爬取数据,直到代码设置的页数都爬取完成,以下截图来自博主亲测截图如下
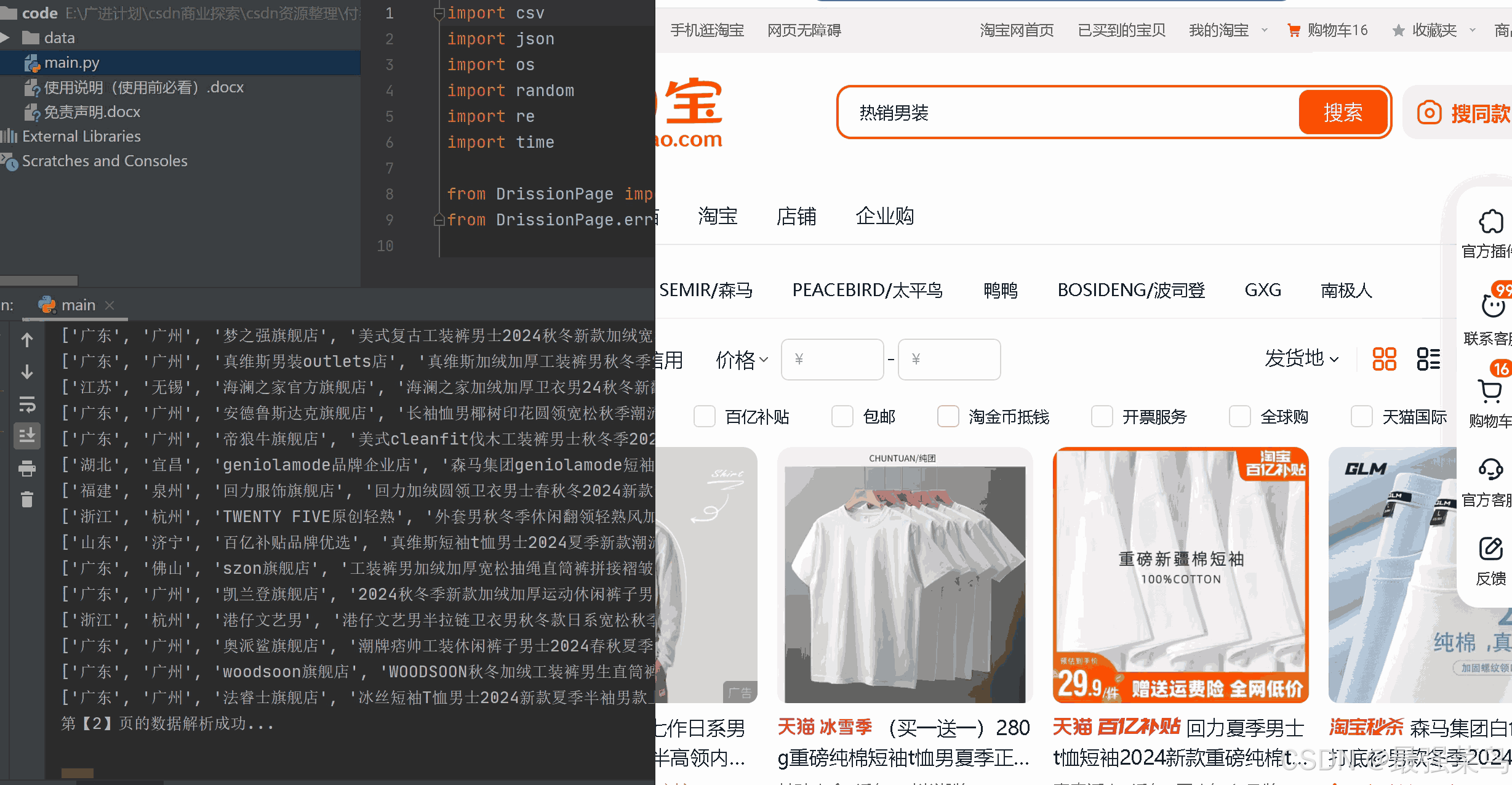
数据爬取完成后,会在main.py同级目录下生成一个data目录,里面存放爬取的数据,格式为csv
注意,如果出现以下截图,例如卡在爬取某一页的日志,请耐心等待,代码设置了最长两分钟的监听时长,如果超时系统会有日志打印