LlamaIndex实现RAG增强:上下文增强检索/重排序

面向文档检索的上下文增强技术
文章目录
- 面向文档检索的上下文增强技术
- 概述
- 技术背景
- 核心组件
- 方法详解
- 文档预处理
- 向量存储创建
- 上下文增强检索
- 检索对比
- 技术优势
- 结论
- 导入库和环境变量
- 读取文档
- 创建向量存储和检索器
- 数据摄取管道
- 使用句子分割器的摄取管道
- 使用句子窗口的摄取管道
- 查询处理
- 不使用元数据替换的查询
- 打印检索节点的元数据
- 使用元数据替换的查询
- 打印检索节点的元数据
- RAG系统中的重排序方法
- 概述
- 动机
- 核心组件
- 方法详解
- 技术优势
- 结论
- 导入相关库
- 文档读取
- 创建向量存储
- 数据预处理管道
- 查询处理
- 方法1:基于LLM的文档重排序
- 重排序必要性示例
- 方法2:交叉编码器模型
概述
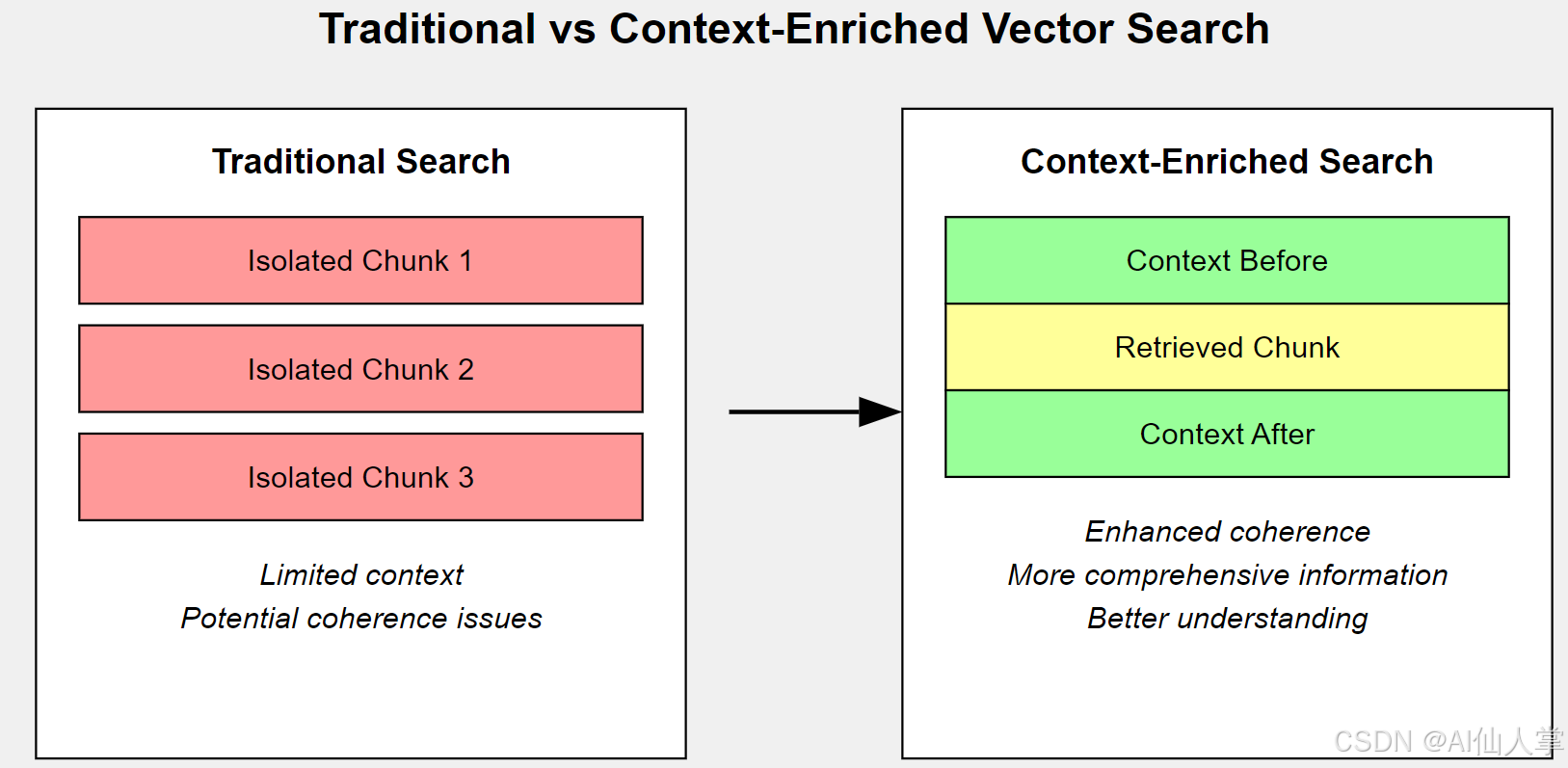
本代码实现了一种用于向量数据库文档检索的上下文丰富窗口技术。它通过为每个检索到的文本块添加周边上下文,增强了标准检索过程,从而提升返回信息的连贯性和完整性。
技术背景
传统向量搜索通常返回孤立的文本片段,这些片段可能缺乏完整理解所需的上下文。本方法通过包含相邻文本块,为检索信息提供更全面的视角。
核心组件
- PDF处理与文本分块
- 使用FAISS和OpenAI嵌入创建向量存储
- 带上下文窗口的自定义检索函数
- 标准检索与上下文增强检索的对比
方法详解
文档预处理
- 读取PDF文件并转换为字符串
- 将文本分割为包含周边句子的文本块
向量存储创建
- 使用OpenAI嵌入创建文本块的向量表示
- 基于这些嵌入创建FAISS向量存储
上下文增强检索
LlamaIndex为此类任务提供了专用解析器。SentenceWindowNodeParser 该解析器将文档分割为句子,但生成的节点会包含相关结构的周边句子。在查询时,MetadataReplacementPostProcessor 帮助重新连接这些相关句子。
检索对比
包含对比标准检索与上下文增强方法。
技术优势
- 提供更连贯且上下文丰富的检索结果
- 在保持向量搜索优势的同时,缓解其返回孤立文本片段的倾向
- 允许灵活调整上下文窗口大小
结论
这种上下文丰富窗口技术为改进基于向量的文档搜索系统中的信息质量提供了有前景的方法。通过提供周边上下文,它有助于保持检索信息的连贯性和完整性,从而可能在问答等下游任务中获得更好的理解和更准确的响应。
导入库和环境变量
from llama_index.core import Settings
from llama_index.llms.openai import OpenAI
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.core.readers import SimpleDirectoryReader
from llama_index.vector_stores.faiss import FaissVectorStore
from llama_index.core.ingestion import IngestionPipeline
from llama_index.core.node_parser import SentenceWindowNodeParser, SentenceSplitter
from llama_index.core import VectorStoreIndex
from llama_index.core.postprocessor import MetadataReplacementPostProcessor
import faiss
import os
import sys
from dotenv import load_dotenv
from pprint import pprint
sys.path.append(os.path.abspath(os.path.join(os.getcwd(), '..'))) # 将父目录添加到路径中(因为我们在notebook中工作)
# 从.env文件加载环境变量
load_dotenv()
# 设置OpenAI API密钥环境变量
os.environ["OPENAI_API_KEY"] = os.getenv('OPENAI_API_KEY')
# Llamaindex全局设置(LLM和嵌入模型)
EMBED_DIMENSION=512
Settings.llm = OpenAI(model="gpt-3.5-turbo")
Settings.embed_model = OpenAIEmbedding(model="text-embedding-3-small", dimensions=EMBED_DIMENSION)
读取文档
path = "../data/"
reader = SimpleDirectoryReader(input_dir=path, required_exts=['.pdf'])
documents = reader.load_data()
print(documents[0])
创建向量存储和检索器
# 创建FaisVectorStore存储嵌入向量
fais_index = faiss.IndexFlatL2(EMBED_DIMENSION)
vector_store = FaissVectorStore(faiss_index=fais_index)
数据摄取管道
使用句子分割器的摄取管道
base_pipeline = IngestionPipeline(
transformations=[SentenceSplitter()],
vector_store=vector_store
)
base_nodes = base_pipeline.run(documents=documents)
使用句子窗口的摄取管道
node_parser = SentenceWindowNodeParser(
# 捕获两侧的句子数量
# 设置为3将得到7个句子(中心句+左右各3句)
window_size=3,
# 在MetadataReplacementPostProcessor中使用的元数据键
window_metadata_key="window",
# 存储原始句子的元数据键
original_text_metadata_key="original_sentence"
)
# 创建包含定义文档转换和向量存储的管道
pipeline = IngestionPipeline(
transformations=[node_parser],
vector_store=vector_store,
)
windowed_nodes = pipeline.run(documents=documents)
查询处理
query = "解释森林砍伐和化石燃料在气候变化中的作用"
不使用元数据替换的查询
# 从基础节点创建向量索引
base_index = VectorStoreIndex(base_nodes)
# 从向量索引实例化查询引擎
base_query_engine = base_index.as_query_engine(
similarity_top_k=1,
)
# 向引擎发送查询以获取相关节点
base_response = base_query_engine.query(query)
print(base_response)
打印检索节点的元数据
pprint(base_response.source_nodes[0].node.metadata)
使用元数据替换的查询
"元数据替换"听起来可能与基础句子处理不太相关,但LlamaIndex将这些"前后句子"存储在节点的元数据中。因此,要重建这些句子窗口,我们需要元数据替换后处理器。
# 从SentenceWindowNodeParser创建的节点创建窗口索引
windowed_index = VectorStoreIndex(windowed_nodes)
# 使用MetadataReplacementPostProcessor实例化查询引擎
windowed_query_engine = windowed_index.as_query_engine(
similarity_top_k=1,
node_postprocessors=[
MetadataReplacementPostProcessor(
target_metadata_key="window" # SentenceWindowNodeParser中定义的`window_metadata_key`
)
],
)
# 向引擎发送查询以获取相关节点
windowed_response = windowed_query_engine.query(query)
print(windowed_response)
打印检索节点的元数据
# 窗口和原始句子已添加到元数据中
pprint(windowed_response.source_nodes[0].node.metadata)
RAG系统中的重排序方法
概述
重排序是检索增强生成(RAG)系统中的关键步骤,旨在提升检索文档的相关性和质量。该过程通过重新评估和排序初始检索结果,确保后续处理或展示时优先使用最相关的信息。
动机
RAG系统中引入重排序的主要动机是为了克服初始检索方法的局限性——这些方法通常依赖简单的相似度指标。重排序能进行更复杂的相关性评估,捕捉传统检索技术可能忽略的查询与文档之间的微妙关系,从而通过确保生成阶段使用最相关信息来提升系统整体表现。
核心组件
典型的重排序系统包含以下组件:
- 初始检索器:通常使用基于嵌入的向量数据库进行相似度搜索
- 重排序模型:可选择:
- 用于相关性评分的大语言模型(LLM)
- 专门训练用于相关性评估的交叉编码器(Cross-Encoder)模型
- 评分机制:为文档分配相关性分数的方法
- 排序与选择逻辑:根据新分数重新排序文档
方法详解
重排序流程一般遵循以下步骤:
- 初始检索:获取一组潜在相关文档
- 配对创建:为每个文档生成查询-文档对
- 评分:
- LLM方法:通过提示要求LLM评估文档相关性
- 交叉编码器方法:直接将查询-文档对输入模型
- 分数解析:对相关性分数进行解析和标准化
- 重新排序:根据新分数对文档排序
- 选择:从排序后的列表中选取前K个文档
技术优势
重排序方法具有多重优势:
- 相关性提升:通过复杂模型捕捉细微的相关性特征
- 灵活适配:可根据需求和资源选择不同重排序方法
- 上下文优化:为RAG系统提供更相关的文档,提升生成质量
- 噪声过滤:有效筛除低相关性信息,聚焦核心内容
结论
重排序是RAG系统中显著提升检索质量的核心技术。无论是基于LLM的评分还是专用交叉编码器模型,都能实现比基础检索方法更精细的相关性评估。这种改进直接转化为下游任务的性能提升,使重排序成为高级RAG实现的必备组件。
在LLM基与交叉编码器方法之间的选择,取决于所需精度、计算资源和具体应用场景。两种方法相较基础检索都能带来显著提升,共同增强RAG系统的整体效能。



导入相关库
import os
import sys
from dotenv import load_dotenv
from typing import List
from llama_index.core import Document
from llama_index.core import Settings
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.llms.openai import OpenAI
from llama_index.core.readers import SimpleDirectoryReader
from llama_index.vector_stores.faiss import FaissVectorStore
from llama_index.core.ingestion import IngestionPipeline
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core import VectorStoreIndex
from llama_index.core.postprocessor import SentenceTransformerRerank, LLMRerank
from llama_index.core import QueryBundle
import faiss
sys.path.append(os.path.abspath(os.path.join(os.getcwd(), '..'))) # 将父目录加入路径(适用于notebook环境)
# 从.env文件加载环境变量
load_dotenv()
# 设置OpenAI API密钥环境变量
os.environ["OPENAI_API_KEY"] = os.getenv('OPENAI_API_KEY')
# Llamaindex全局设置(LLM和嵌入模型)
EMBED_DIMENSION=512
Settings.llm = OpenAI(model="gpt-3.5-turbo")
Settings.embed_model = OpenAIEmbedding(model="text-embedding-3-small", dimensions=EMBED_DIMENSION)
文档读取
path = "../data/"
reader = SimpleDirectoryReader(input_dir=path, required_exts=['.pdf'])
documents = reader.load_data()
创建向量存储
# 创建用于存储嵌入向量的FaissVectorStore
fais_index = faiss.IndexFlatL2(EMBED_DIMENSION)
vector_store = FaissVectorStore(faiss_index=fais_index)
数据预处理管道
base_pipeline = IngestionPipeline(
transformations=[SentenceSplitter()],
vector_store=vector_store,
documents=documents
)
nodes = base_pipeline.run()
查询处理
方法1:基于LLM的文档重排序

# 从基础节点创建向量索引
index = VectorStoreIndex(nodes)
query_engine_w_llm_rerank = index.as_query_engine(
similarity_top_k=10,
node_postprocessors=[
LLMRerank(
top_n=5
)
],
)
resp = query_engine_w_llm_rerank.query("What are the impacts of climate change on biodiversity?")
print(resp)
重排序必要性示例
chunks = [
"The capital of France is great.",
"The capital of France is huge.",
"The capital of France is beautiful.",
"""Have you ever visited Paris? It is a beautiful city where you can eat delicious food and see the Eiffel Tower. I really enjoyed all the cities in france, but its capital with the Eiffel Tower is my favorite city.""",
"I really enjoyed my trip to Paris, France. The city is beautiful and the food is delicious. I would love to visit again. Such a great capital city."
]
docs = [Document(page_content=sentence) for sentence in chunks]
def compare_rag_techniques(query: str, docs: List[Document] = docs) -> None:
docs = [Document(text=sentence) for sentence in chunks]
index = VectorStoreIndex.from_documents(docs)
print("检索技术对比")
print("==================================")
print(f"查询内容: {query}\n")
print("基础检索结果:")
baseline_docs = index.as_retriever(similarity_top_k=5).retrieve(query)
for i, doc in enumerate(baseline_docs[:2]): # 仅显示前两个检索文档
print(f"\n文档 {i+1}:")
print(doc.text)
print("\n高级检索结果:")
reranker = LLMRerank(
top_n=2,
)
advanced_docs = reranker.postprocess_nodes(
baseline_docs,
QueryBundle(query)
)
for i, doc in enumerate(advanced_docs):
print(f"\n文档 {i+1}:")
print(doc.text)
query = "what is the capital of france?"
compare_rag_techniques(query, docs)
检索技术对比
==================================
查询内容: what is the capital of france?
基础检索结果:
文档 1:
The capital of France is great.
文档 2:
The capital of France is huge.
高级检索结果:
文档 1:
Have you ever visited Paris? It is a beautiful city where you can eat delicious food and see the Eiffel Tower. I really enjoyed all the cities in france, but its capital with the Eiffel Tower is my favorite city.
文档 2:
I really enjoyed my trip to Paris, France. The city is beautiful and the food is delicious. I would love to visit again. Such a great capital city.
方法2:交叉编码器模型
LlamaIndex内置支持直接作为节点后处理器的SBERT模型。
query_engine_w_cross_encoder = index.as_query_engine(
similarity_top_k=10,
node_postprocessors=[
SentenceTransformerRerank(
model='cross-encoder/ms-marco-MiniLM-L-6-v2',
top_n=5
)
],
)
resp = query_engine_w_cross_encoder.query("What are the impacts of climate change on biodiversity?")
print(resp)